캐시 메모리 쓰기 정책
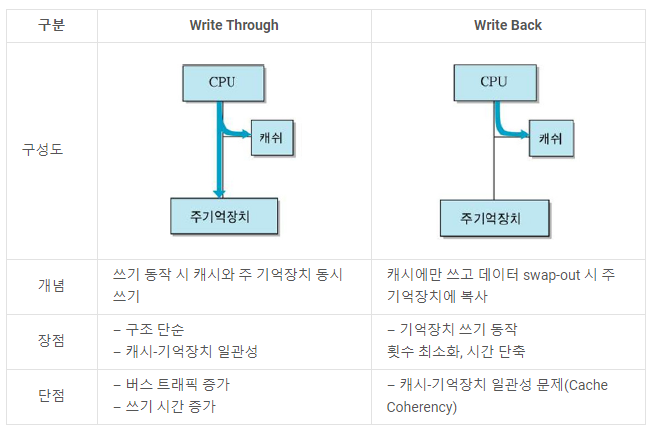
캐시 Hit시 쓰기 정책
Write Through
쓰기 동작 시 캐시와 메모리 동시에 쓴다.
구조가 단순하고 일관성이 유지하지만 시간이 더 걸림
Write Back
쓰기 동작 시 캐시에만 쓰고 해당 데이터가 캐시에서 swap-out(교체될 때) 시 메모리에 복사
(dirty bit 등으로 캐시 기록 유무 판별), 시간이 단축 되지만 일관성 문제 발생
캐시 Miss시 캐시 쓰기 정책
No write-allocate
메모리에만 기록하고 캐시에는 기록 안한다. write를 두 번(캐시/메모리 각각) 할 껄 한 번으로 대체할 수 있다. (이 방법은 데이터를 한 번만 쓰고 더 이상 엑세스하지 않을 때 효율적이다.)
write-allocate
미스 시 캐시에만 기록한다. 메모리는 캐시와 매핑만하고 데이터를 넣진 않는다.
해당 캐시가 swap-out 될 때 매핑 된 메모리에 해당 데이터를 swap 한다.
(매핑 된 메모리의 Victim page를 스왑 영역으로 보냄)
캐시 정책 조합
Write Through - No Write allcoate
Write Through 자체가 결국 hit 시에도 Memory에 접근하는 과정이므로 중간에 따로
Cache에만 할당될 필요가 없으니 캐시 miss 시에 memory에만 기록하여도 효율적이다.
Write Back - Write allocate
캐시 hit나 miss시에도 무조건 캐시에만 기록하고 스왑될 때 메모리에 보내지는 방식이라 언제나 높은 속도를 유지할 수 있다.
Write Back - No write-allocate
캐시와 메모리 중 무조건 한 곳에만 데이터를 기록하기에 보다 많은 저장 공간을 확보할 수 있다.
Write Through - Write allcoate
miss 시 데이터 기록 후 바로 read 시에 캐시에 저장했으므로 빨라지지만 read를 하지 않는 경우 괜히 저장해놓은 캐시 공간이 낭비된다는 단점이 있다.
Cache Hierarchies
캐시는 효율성을 계층 구조를 이루는데 L1~L3로 계층 구조가 이루어져있다.
이 계층 구조에서도 정책에 따라 계층 별로 데이터를 어떻게 저장할지 선택할 수 있다.
Inclusive 방식
Inclusive 방식은 상위 계층의 내용물이 하위 계층에 반드시 포함되어야하는 방식이다.
L1(상위 계층)의 데이터는 L2(하위 계층)에 반드시 존재해야 하며, L2와 L3의 관계도 그러하다.
Inclusive 방식의 장점은 캐시에 담긴 자료를 참조하고 싶을 때 가장 낮은 계층의 캐시만 둘러봐도 된다. 그리고 각 계층의 캐시 용량에 따라 개별적인 크기의 최소 단위를 설정할 수 있어 각 계층마다 최적화된 검색 시간을 가질 수 있게 된다. (왜 이런지는 Exclusive에서 설명한다.)
Inclusive 방식의 단점으로는 각 계층 캐시 용량의 총 합보다 적은 양의 자료만을 담을 수 있다는 것이다. (L3-(L2+L1)가 사용 가능한 최대 용량이 된다.) 해당 구조는 주로 인텔 CPU에서 사용된다.
Exclusive 방식
Exclusive 방식은 반대로 상위 계층과 하위 계층 캐시가 저장한 내용이 서로 배타적이어야 한다. 상위 계층에 이미 데이터가 있으면 하위 계층은 다른 데이터들로 채워야 된다는 소리다.
그래서 이 구조의 장점은 각 캐시 계층을 하나의 거대한 캐시처럼 활용 가능한 것이며 캐시의 총 용량을 모두 활용할 수 있게 된다. 그래서 L2 캐시가 L1 캐시보다 무조건 클 필요도 없기에 AMD 애슬론의 경우 L1 캐시 크기인 256KB에 비해 L2 캐시를 64KB로 줄여도 아무 문제가 없으며 성능 저하를 최소화하면서 다이 사이즈를 줄여 단가를 절감하는데 도움이 됐다.
반면 Exclusive 방식의 단점은 모든 계층의 캐시가 거대한 단일 캐시구조로 동작하기에 모든 계층의 캐시에 걸쳐 같은 크기의 최소 단위를 사용해야 한다는 점이다.
캐시의 최소 단위는 CPU가 어떤 자료를 찾기 위해 캐시를 '둘러보는' 시간에 직결되어 성능에 큰 영향을 미치는데 일반적으로 캐시의 용량이 커지면 최소 단위도 적정 수준까지 커지는 것이 검색 시간 단축에 유리하기 때문이다. (용량에 비해 적은 단위면 전체 스캔까지 오래 걸리니 + 오버헤드 누적)
하지만 Exclusive 방식은 각 계층이 개별적인 최소 단위를 가지지 못하고 크기가 가장 작은 계층(L1)을 기준으로 최소 단위를 가져야 하므로 (데이터가 있을 수 있는 L1~L3 모두를 신경써야 하니) 작은 최소 단위로 인해 상대적으로 불이익이 발생할 수 있다.
캐시 메모리 매핑
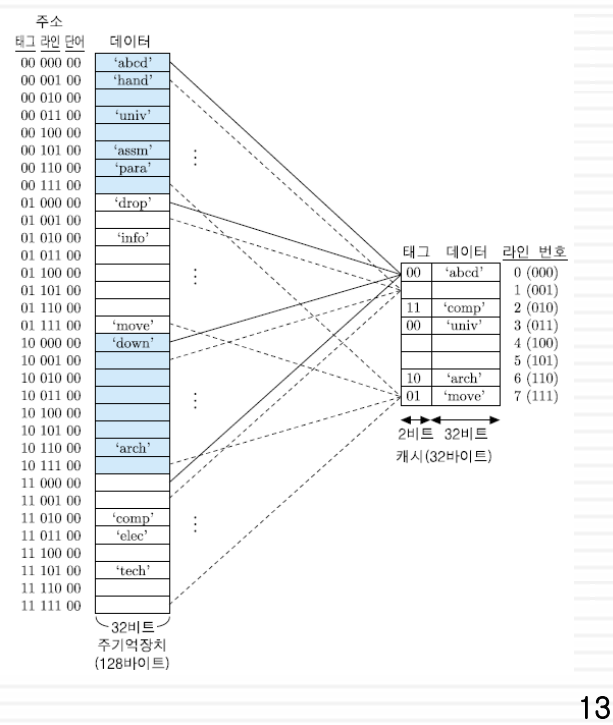
전송 단위
워드 : CPU의 기본 처리 단위이며, 블록/라인을 구성하는 기본 단위이다.
메모리 블록 : 메모리를 기준으로 잡은 캐시와의 전송 단위다.
캐시 라인과 크기가 같으며, 메모리 블록은 여러 개의 워드로 구성되어있다.
메모리 블록의 개수는 메모리 크기 / 캐시 라인 크기 로 구해진다.
캐시 라인 : 메모리 블록과 동일한 크기의 캐시 관점의 캐시-메모리 간의 전송 단위다.
캐시는 여러 개의 캐시 라인으로 이어져있으며 각 라인은 여러개의 워드로 구성되어있다.
전체 캐시 라인 개수는 캐시 크기 / 메모리 블록 크기 로 구해진다.
캐시 라인 개수와 메모리 블록의 개수는 차이가 날 수 있으며 이를 극복하기 위해 매핑 기법이 사용된다.
Set : 캐시 라인을 묶어서 세트 집합으로 만든 것 (집합-연관 매핑에서 사용됨)
(Set Associative Mapping 방법은 기본적으로 direct mapping과 같으나,
Cache의 Line을 몇개씩 묶어서 Set로 둔다는 점에서 다르다.)
direct mapping은 1-way set와 같아서 라인당 세트가 하나씩 존재한다.
full associative는 모든 라인을 묶어서 하나의 큰 세트로 만들고
n-way associative는 모든 라인을 n개로 나눠서 n개의 세트를 만든다.
(n-way 세트의 크기는 (line count / n) 크기다.)
Directed Mapping
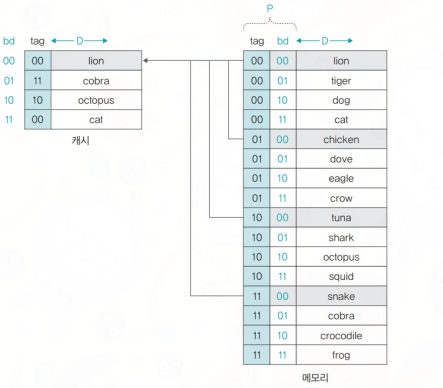
Direct mapping은 Main memory의 Block들을 정해진 Cache line과 하나씩 직접 지정하는 방식이다. 캐시 라인에는 같은 인덱스의 다른 태그가 들어올 수 없다.
위 자료로는 혼돈이 올 수 있으니 사진만 보고 넘어가고 밑에서 기법에 대해 자세히 설명하겠다.
해당 매핑의 장점으로는 캐시 적중 시간이 빠르며 (같은 인덱스에서 태그 비교로 찾으면 되니)
구현이 간단하지만, 같은 인덱스로의 접근이 잦은 경우 스와핑으로 인한 Miss Rate가 높다는 단점이 있다.
Directed Mapping의 캐시 주소 형식
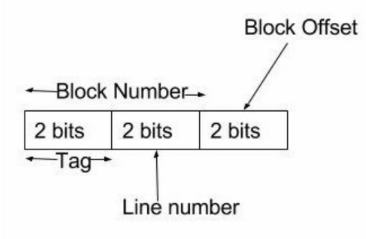
주소 형식은 크게 2가지로 나눠질 수 있다. 블록 식별용 Block Number와 Block Offset이다.
먼저 수 많은 블록 중 어떤 블록에 관심이 있는지를 알려주는 비트를 Block Number라고 한다.
그리고 한 블록에서 특정 데이터(word)를 찾을 위치를 알려주는 비트를 Block Offset이라 한다.
Block Number는 Tag와 Line으로 나눠지는데, Line는 메모리 상의 블록 번호를 알려주는 역할을 한다.
Tag는 캐시 메모리를 위해 존재하는데 같은 라인을 사용하는 블록들을 식별하기 위해 태그를 부여한다.
직접 매핑에선 같은 캐시 라인을 여러 블록들이 공유해서 사용해야 하는데 이 문제로 인해 같은 라인을 사용하는 블록을 구분하기 위해 서로 다른 태그를 가지는게 바로 태그 필드의 목적이다.

사실 Block Offset 안에는 Byte 오프셋이 들어갈 수 있다.
Byte 오프셋은 한 워드의 Byte 단위별 구분을 위해 사용되는 2bit Offset이다.
1 Word는 보통 4Byte로 구성되어 있는데, 1Byte 만큼의 데이터만을 사용하려고 하려면
Byte Offset을 통해 바이트 단위로 데이터(Word)를 구분해서 활용할 수 있게 해준다.
주소 형식 예시 ★
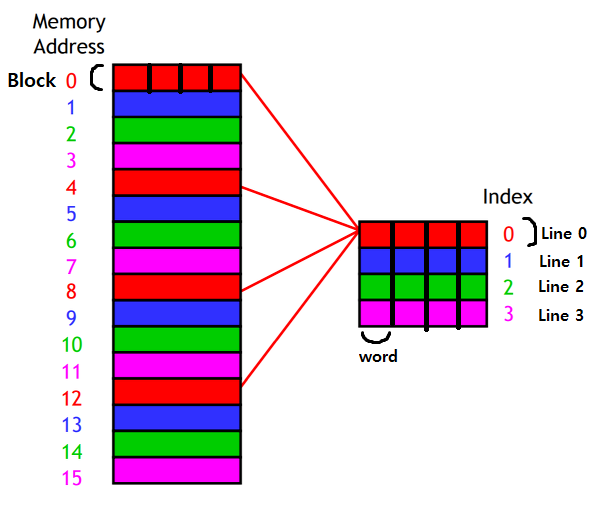
다이렉트 매핑은 순서대로 블럭과 캐시를 하나씩 매치한 매핑이다. 캐시 하나의 라인은 n개의 워드를 가질 수 있다. 캐시 0번 라인에는 0번째 블럭을 1번 라인에는 1번째 블럭을 1:1씩 블럭 대 라인식으로 매핑하는 방식이다. 블록의 크기가 4워드라고 가정했을 때, 캐시의 1라인은 4워드의 크기를 가진다.
자, 그럼 예시로 메모리 주소 25워드는 어디에 매핑되는지 직접 구해보자.
25 워드는 011001이므로 (Tag)01 / (Line)10 / (Offset)01로 구분할 수 있다.
맨 뒤의 Block Offset은 01이다. 즉, 한 라인(블록)에서 2번째에 위치한 word를 필요로 한다.
그 다음 중간의 라인 비트는 10이므로 캐시 라인(블록)에서 3번째 위치한 초록색 라인을 나타낸다. 즉, 해당 주소는 교체가 일어난다면 캐시 안의 2번 라인에 들어가게 된다. (=초록색 블록 중 하나)
맨 앞의 태그는 01라서 2번째 태그를 의미하는데, 직접 매핑에선 같은 라인을 공유하는 블록들을 식별하기 위해 서로 다른 태그를 가진다. 즉 맨 처음 빨강 블록과 4번째 블록은 같은 캐시 라인(슬롯)을 사용하기에 이를 구분하기 위해 서로 다른 태그(00, 01)을 가진다.
지금 주소의 Tag는 01이라서 2번째로 반복되는 블록을 의미하고
이는 2번째 초록 라인 블록인 6번 블록인 것을 알 수 있다.
결론으로 25워드는 6번 블록의 2번째 워드로서 캐시 2번 라인의 2번째 word 공간에 매핑된다.
https://jhnyang.tistory.com/114
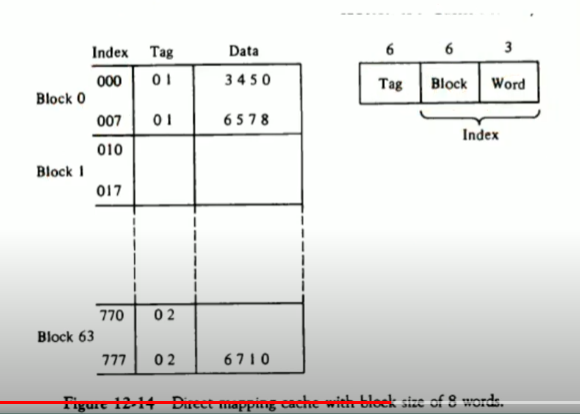
메모리 주소 명칭에서 같은 뜻이지만 여러 말로 불리는 단어가 많으니 주의하도록 하자.
Fully Associative Mapping
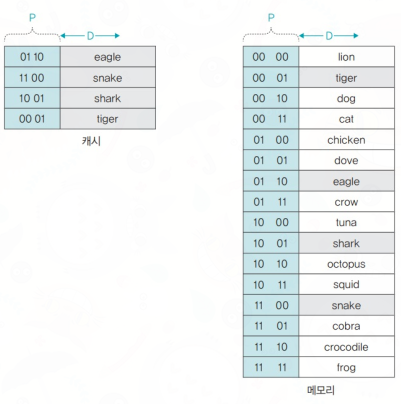
직접 사상의 단점을 보완한 것으로 주기억장치의 블록을 캐시의 어느 라인에든 적재할 수 있다.
캐시에 저장된 데이터들은 메인 메모리의 순서와는 아무런 관련이 없다. 메모리 블록이 캐시의 정해진 슬롯이 아니라 임의적으로 저장되기 때문.
이 같은 방식으로 인해 캐시에 접근할 때 라인을 모두 뒤져서 태그가 같은(일치하는) 데이터가 있는지 일일이 확인해야 한다. (시간이 오래 걸린다)
또한 모든 캐시 슬롯의 태그 번호들을 고속으로 검색하기 위해서는 복잡한 회로가 필요하다.
해당 매핑의 특징으로는 모든 메모리 블록에 접근하기 위해 복잡한 회로를 가지고 있는 단점이 있지만 적중률이 높다는 장점이 있다. (인덱스를 사용하지 않아 영역을 두고 다툴 일이 없기에)
Fully Associative의 캐시 주소 형식

연관 매핑의 캐시 구조는 훨씬 간략화된 Tag / Offset(Word) 구조를 지니며 Line 부분이 삭제된다.
메모리의 블록 식별은 Tag 비트가 맡아서 진행하며 (Tag 부분이 길어짐) 메모리 블록안의 각 word를 구분하기 위해 Word 비트가 블록내에 존재하는 word를 선택하는데 사용된다.
-
태그는 주기억장치의 블록번호를 나타내며 블록이 캐시의 정해진 슬롯(라인)에 저장되는 것이 아니라 임의적으로 저장된다.
-
슬롯(Line) 번호를 위한 필드는 존재하지 않으며 (특정 라인에 블록을 안맞춰도 되니)
단어 필드(Word)는 블록내에 존재하는 단어를 선택하는데 사용된다.
(만약 블록 구성이 하나의 단어(1 word)로만 존재한다면 단어 필드의 모든 비트는 0이 됨)
이제 위 사진의 주소를 구성하자면
태그 필드는 상위 3비트(000,001)이며 단어 필드는 2비트라서 한 블록내에 4개의 단어가 존재함
태그 필드로 블록 번호를 구분하고 Offset을 통해 블록 안의 word(00~11)를 구분함
해당 매핑의 특징으로는 직접 사상처럼 블록간의 배타적 영역이 없기 때문에 캐시 미스율이 적고 빈 공간에 아무 블록이나 들어가면 되니 적중률과 공간적 효율성이 높다는 장점이 있다.
그러나 특정 블록이 모든 라인에 올 수 있기에 캐시 접근 시 모든 라인 뒤져야 하기에 접근 시간이 오래 걸린다. (모든 라인을 검색하고 나서야 원하는 데이터가 존재하지 않을 때 캐시 미스가 일어남)
Set Associative Mapping (N-way)
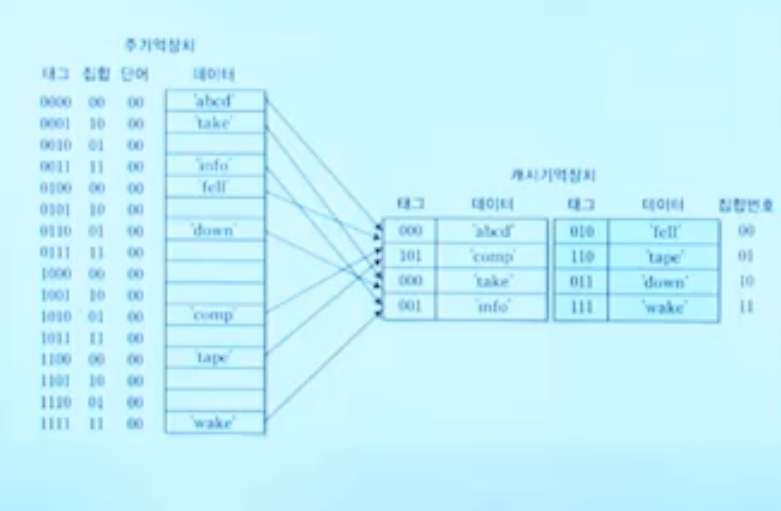
집적 연관 매핑은 직접 매핑과 연관 매핑의 장점을 합쳐서 만들어진 오늘날 사용되는 방식이다.
직접 사상과 연관 사상을 혼합한 방식으로 캐시를 N개의 세트로 나누고 각 집합에 직접 매핑을 사용한다. 집합(Set) 선택은 연관 매핑을 사용하여 비어있는 집합이 있을 경우 바로 들어갈 수 있다.
Set(집합)의 크기는 캐시 라인 수 / N-way 가 된다. Way가 클 수록 캐시는 잘개 쪼개진다.
또한 메모리도 세트 크기씩으로 잘라내고 SET 비트를 추가하여 세트의 특정 라인에만 들어가도록 매핑한다. (블록이 같은 라인에 위치한다면 어떤 SET라도 들어갈 수 있다.)
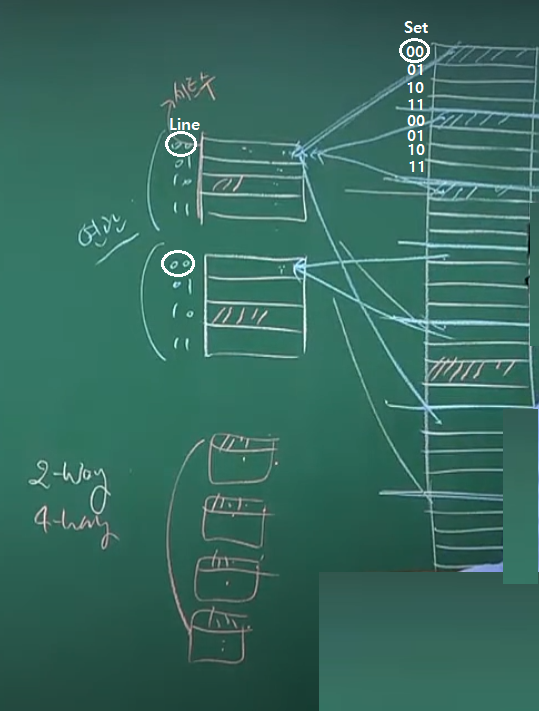
핵심 내용
각 Set내의 Line(슬롯)은 동일한 집합번호(Set bit)를 가진 블록만 올 수 있지만 (직접사상)
집합번호만 같다면 어떠한 세트(way)에도 들어갈 수 있는 연관사상의 개념을 적용받았다.
집합-연관 매핑의 특징으로는 다이렉트 매핑인 1-Way Set 매핑에 비해 Set 수를 늘림으로써 같은 라인을 사용하는 블록 간의 경쟁율을 1 / N-Way 만큼 낮출 수 있어서 적중율이 N배 만큼 늘었지만
똑같이 탐색 시간도 N배 만큼 늘어났는(모든 Way의 특정 라인을 뒤져야 하기에) 하이브리드 방식의 매핑이다.
Set Associative Mapping의 캐시 주소 형식
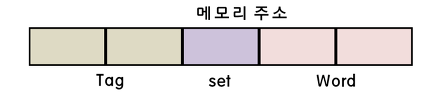
집합 연관 사상의 주소 형식은 Tag, Set, Word 비트로 나뉘어져 있다.
블록의 주소는 태그필드와 집합필드(Set)을 합한 비트로 이루어지며, 워드비트는 기존처럼 블록안의 워드를 구분해준다.
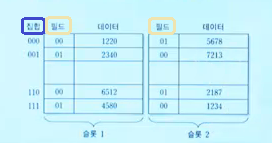
Set 비트를 통해 해당 블록이 집합(Set) 내에 들어갈 수 있는 라인을 구할 수 있게 되며,
같은 집합에서는 way의 개수(n)가 허용되는 한에서 서로 다른 태그(00, 01)로 구분되는 같은 집합의 두 개의 데이터가 동시에 저장될 수 있다.
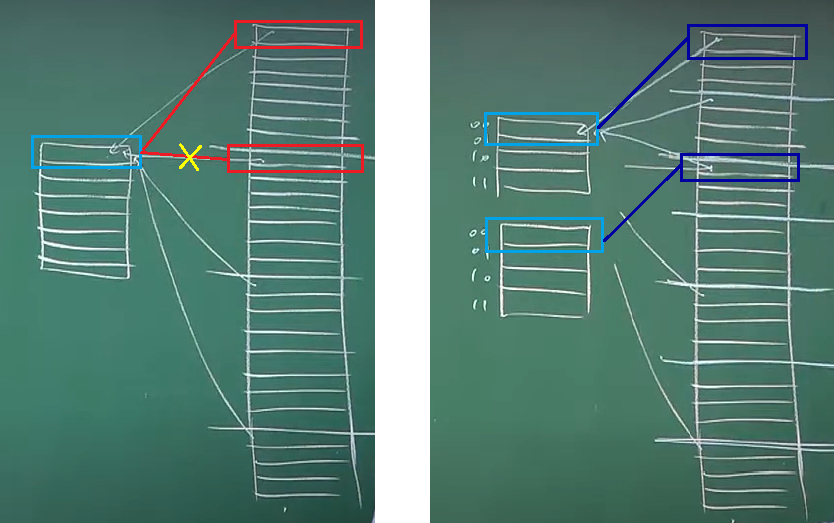
직접 매핑과의 가장 큰 차이점으로 직접 매핑은 1번째 태그의 레드 블록이 캐시를 점유하면 2번째 태그의 레드 블록은 기다리거나 1번과 교체되어야 하는데 (두 블록이 동시에 캐시에 존재할 수 없다)
집합-연관 매핑으로 인해 캐시 라인을 집합으로 나눠서 같은 라인이었던 1번과 2번 블록이 동시에 캐시에 존재할 수 있게 됐다. (같은 라인의 블록을 담을 수 있는 세트가 N배로 분할됐다)
매핑별 Set 정리
Direct Mapping의 Set(집합) 개수는 1개이고 (1-Way Set = 직접 사상)
Fully associative Set의 Set 개수는 캐시 라인의 수와 동일하며, (모든 메모리에서 접근이 가능하니)
N-way associative의 Set 개수는 N개 이다. (Set Size는 Cache line_count / N or 메모리 블록 수 / N)
