파이프라인 스테이지
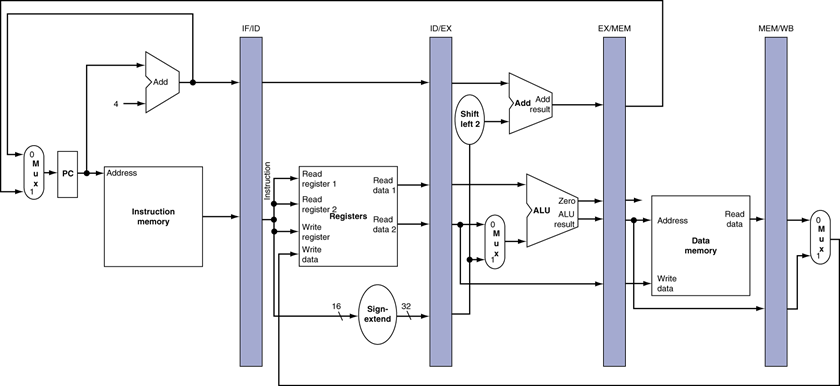
파이프라인의 5단계 Stage
IF : 명령어 인출
ID : 명령어 해독 및 레지스터 파일 읽기
EX : 실행 및 계산
MEM : 메모리 접근(읽기)
WB : 레지스터에 쓰기 저장
Stage 사이에 파이프라인 레지스터 추가
(후속 파이프라인 단계에서 필요한 정보를 필요단계까지 전달)
클럭 당 한 Stage씩 전진
(ID : Stage 이름, ID/EX가 파이프라인 레이저스터 이름)
IF/ID register: PC+4 와 명령어 저장
ID/EX register: PC+4, rs, rt로 읽은 데이터들, 명령어 하위 16bits를 sign-extend한 32 bit data 저장
파이프라인 제어신호
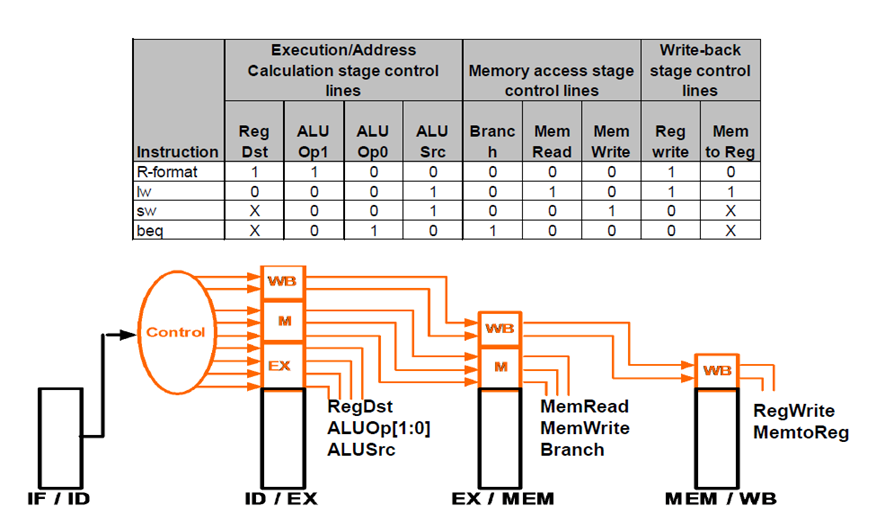
파이프라인 도입으로 이제는 스테이지별로 제어신호를 수신한다.
Control 신호를 사용하는 해당 stage에 소모하도록 pipeline register도 확장됨
제어신호가 EX --> MEM --> WB 거치면서 각자 필요한 정보를 쓰고 나머지 비트를 다음꺼에 전달하는 방식
각 단계별 제어 신호
IF/ID : 제어신호 필요 없음
EX 단계: RegDst (rt, rd 구분), ALUOP(수행연산종류), ALUSrc (Read data2, extended 16bit)
MEM 단계: Branch(beq), MemRead(lw), MemWrite(sw)
WB 단계: MemtoReg, RegWrite (rw.lw 일 때만 활성화)
완성된 MIPS 파이프라인
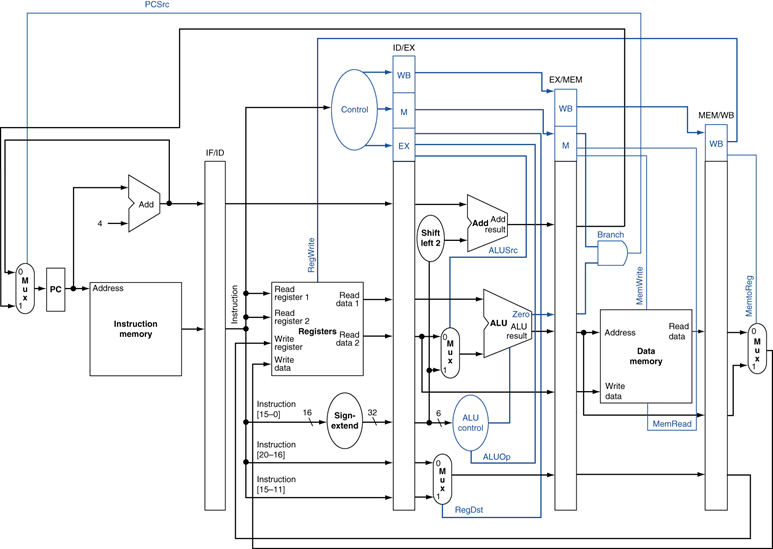
파이프라인 해저드
지속적인 명령어 실행이 불가능하여 지정된 클럭에서 수행되는 파이프라인이 지연 및 중지되는 현상
구조적 해저드
다른 단계에 있는 명령어들이 동시에 같은 지원을 사용하려고 하는 상황
(하드웨어적인 문제라서 회로를 더 늘려야지만 해결 가능)
데이터 해저드
데이터 종속성으로 인해 앞 명령어의 결과를 사용해야 하는데 앞 부분이 안끝나서 파이프라인이 지연되는 상황 (버블, 포워딩 등으로 해결)
지연(버블)
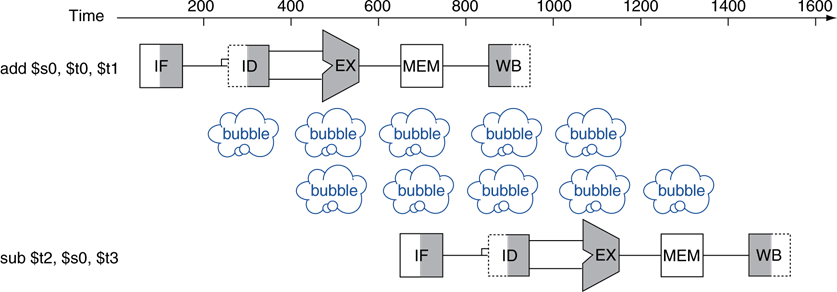
sub 명령어는 $s0의 값을 미리 알아야하는데 그 전 add 명령어의 $s0 값이 아직 파이프라인 상에서 계산되고 있기에 해저드가 발생했다(ID Stage에서).
솔루션으론 두 명령어 사이에 bubble(=nop)을 삽입한다. 파이프라인 레지스터가 없는 경우는 WB Stage에서 레지스터에 write한 후에 읽어야 하므로 3cycle이 지연되지만, 위 그림과 같이 한 클럭에 write와 read가 동시에 일어날 수 있는 파이프라인 레지스터를 사용할 경우, IF/ID 레지스터 대신 MEM/WB 레지스터 값을 통해 $s0 레지스터 값을 불러오면 되므로 2cycle만 지연된다.
Forwarding(전방전달)
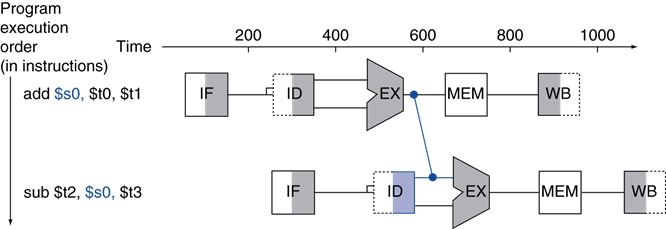
sub 명령어는 $s0의 값을 알아내야 하기에 전 명령어가 EX에서 계산된 결과를 파이프라인 레지스터(EX/MEM)에 저장하고 뒤의 sub 명령어가 EX연산을 할 때 ID/EX 레지스터가 아닌, EX/MEM 레지스터로부터 저장된 값을 활용하여 계산함으로써 해저드를 해결할 수 있다.
Load-Use 데이터 해저드
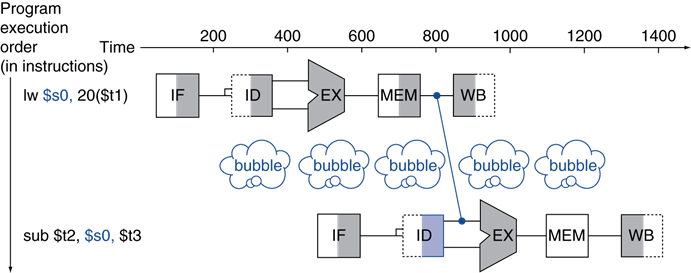
앞의 명령어가 R-type이 아닌 I-type lw(로드) 명령어이고, 다음 명령어와 종속성이 존재하는 경우 lw의 결과값을 MEM에서 받은 후 MEM/WB 레지스터에 넣은 후 다음 명령어의 EX 스테이지에서 ID/EX 대신 MEM/WB 레지스터의 값을 활용하여 계산할 수 있다.
하지만 lw 명령어 특성상 MEM 스테이지까지 진행해야하므로 바로 다음 명령어가 종속성이 있을 땐 어쩔 수 없이 1cycle 지연이 불가피하다.
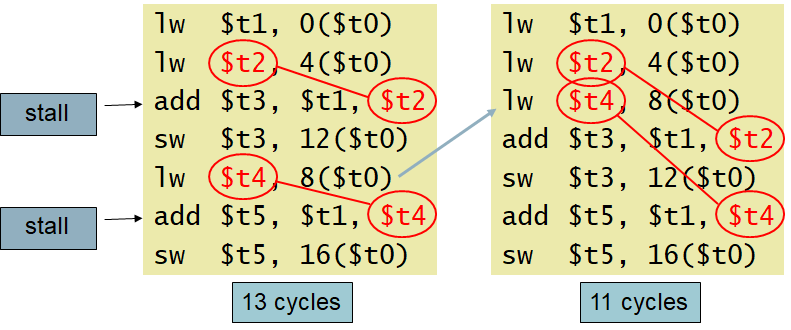
또는 컴파일러가 코드의 재정렬을 통해 개선할 수 있다.
5번줄의 lw를 3번줄로 이동시키면 lw-add 종속관계의 거리가 생겨 포워딩만으로 해결할 수 있다.
(버블을 사용하지 않아도 된다.)

데이터 해저드 조건
(fwd=forward), 위와 같은 상태가 되었을 때 데이터 해저드가 발생한 것이며, 해당 데이터는 포워딩을 통해 해결되어야 한다.
주의사항
data dependency(데이터 종속성)가 있다고해서 무조건적으로 data hazard가 발생하는 것이 아니다. 데이터 해저드와 데이터 종속성을 동의어로 이해하지 말라.
데이터 의존성이 있어도, 각 명령어간에 거리가 충분하다면 데이터 해저드는 발생하지 않는다. 종속성이 존재해도 3cycle 이상 차이나는 명령어와는 해저드가 일어나지 않는다.
제어 해저드
앞 분기의 결과를 몰라서 다음 명령어 인출을 못하는 상황 또는 분기 명령에 의해 발생하여 처리된 명령이 무효화된 상황을 뜻한다. (분기 예측, 지연 분기 등으로 해결 가능)
분기 예측이 성공했을 경우 성능 저하 없이 해저드 해결이 가능하며, 예측에 실패했을 경우 flush가 발생한다. (flush는 예측 후 파이프라인에 진입한 명령어들을 모두를 삭제하고 nop로 변경하는 것을 뜻함)
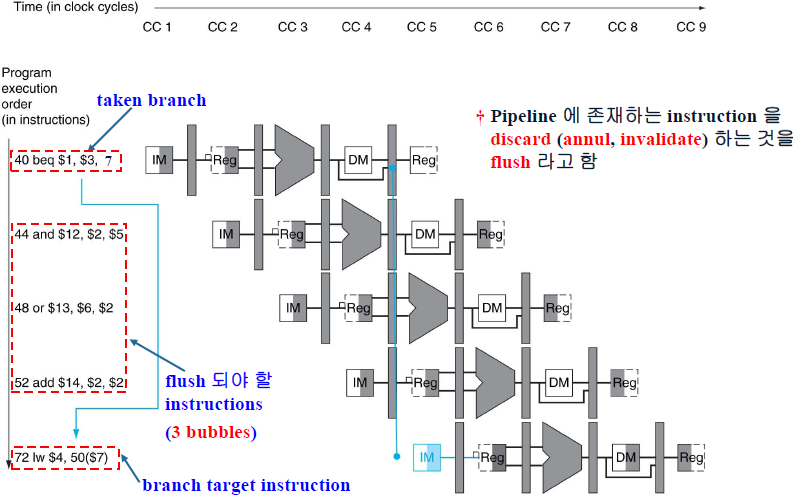
앞의 40번지 PC의 명령어가 참이라면 72번지로 분기되는데(40+(7*4)+4=72) 이런 경우 그 사이에 실행된 3개의 명령어는 실행되선 안됐는 명령어기에 모두 flush 해줘야 한다.
(삭제된 명령어 수만큼 손해 발생)
P.S 왜 40+28(7*4)인 68번지로 점프안하고 4를 더한 72번지로 점프되는가?
J-type인 Jump 명령어는 주소 부분에 적혀있는 주소값과 현재 PC를 조합하여 점프되지만 I-type인 beq나 bne 등은 immediate(목표) 값에다 추가로 4를 더한 번지로 점프된다.
J-type에 대해 정확히 설명하자면 현재 PC가 아니라 목표 주소의 상위 4비트만 PC+4 값이 들어오고 나머지 비트는 명령어에 들어있는 TGT address와 합쳐서 32비트 주소가 도출된다.
따라서 PC+4로 인해 상위 4비트가 변동되지 않는 이상 Fetch 시의 PC 값을 그대로 사용하게 된다. (PC+4 값을 쓰지만 주소를 구할 때 PC의 상위 4비트만을 사용해서 +4가 되어봤자 PC의 상위 비트에 영향을 미치진 않는다.)
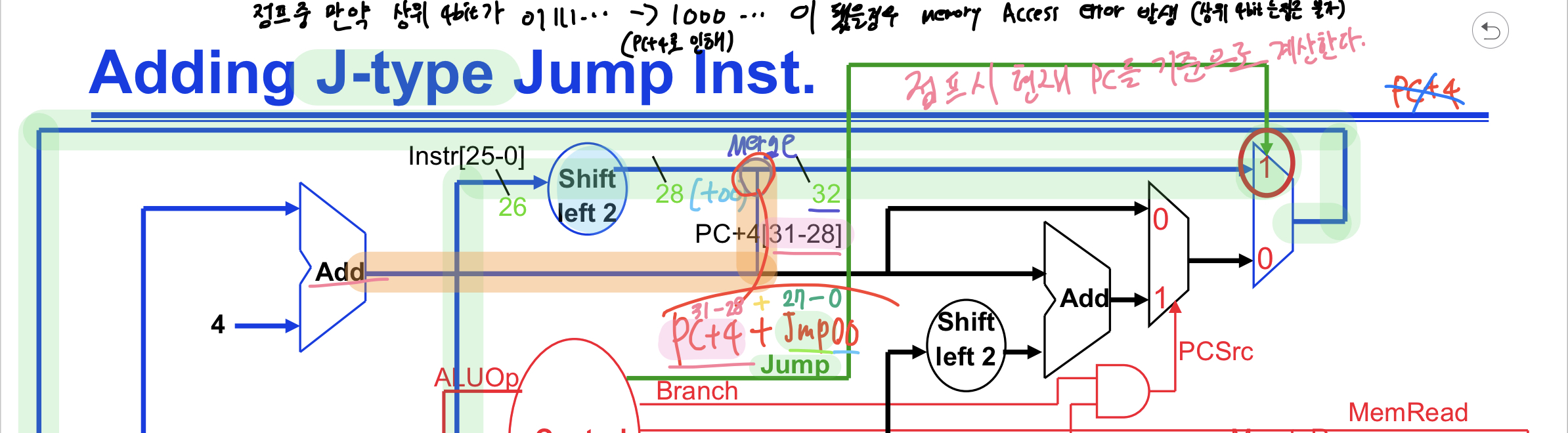
위에 상위 4비트가 변동되지 않는 이상 PC+4가 주소에 영향을 미치지 않는다고 했는데 사실 Jump 명령도 한계 범위가 존재한다. 32비트의 주소공간 중에 어느 임의적인 주소로 마음껏 jump 할 수는 없는데 Jump 명령은 항상 다음 범위 내에 있는 주소로만 jump해야만 한다. (범위 끝부분이 00인 이유는 shift 연산을 위해 2bit를 남겨뒀기 때문이다.) 하위 비트가 1111...로 정렬됐을 때 하필 PC+4로 인해 상위 4비트(wxyz)가 1000(11111...) -> 1001(00000...)으로 변경됐을 경우 점프 범위를 초과하게 되어 점프할 수 없게 된다.

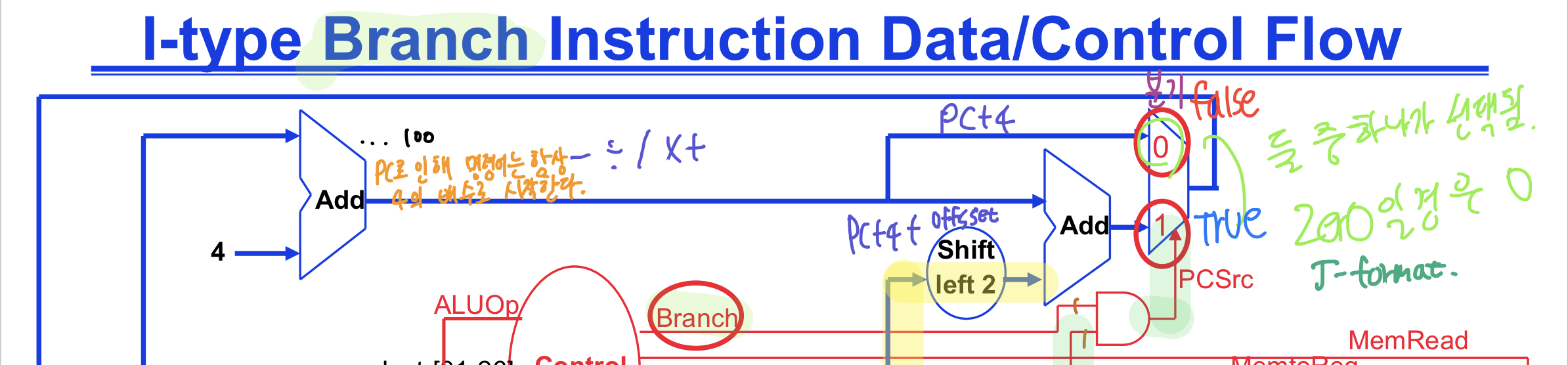
다시 돌아가서 I-type의 이유를 설명하자면 프로그램 카운터의 특성 때문인데 분기할 주소의 기반 주소가 되는 프로그램 카운터 주소가 매 클럭마다 4 씩 더해지기 때문이다. (PC+4+TGT_Offset)
그리고 I-type은 회로 구조상 PC+4가 된 프로그램 카운터를 기반 주소로 사용하며 (분기용으로 이미 사용한 PC를 따로 남겨두기엔 아까우니 PC+4와 같은 패스를 쓰는 것 같다)
PC+4와 분기 오프셋 값인 immediate 값이 더해져 (J-type은 주소 값이 merge로 합쳐지는 방식이지만 I-type의 분기는 PC+4를 기반으로 immediate*4 와 더해져 주소를 구하는 방식이다) 실제 점프할 주소가 합산되는 방식의 명령어기 때문이다.
제어 해저드의 솔루션은 다음과 같다.
Delayed
첫 번째 방법은 지연으로, 분기 명령어가 나오면 그냥 분기 결과가 나올 때까지 버블을 넣어 다음 명령어를 계속 지연시키는 방법이다. 해당 방법은 단순하지만, 매우 큰 손실과 속도 저하를 초래하기에 사용되지 않는다.
Prediction
다음 방법인 예측은 분기가 항상 실패하거나 또는 성공한다고 예측하는 것이다. 이 방법 역시 분기가 예측과 다르게 자주 진행될 경우 손해가 극심하여 사용되지 않는다.
Dynamic Prediction
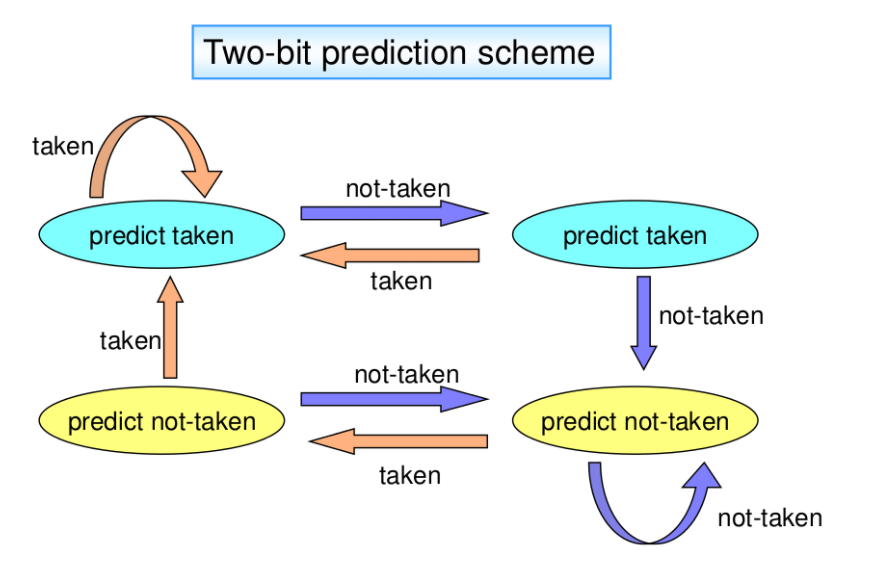
dynamic prediction는 분기 결과에 따른 history를 기반으로 분기를 동적으로 예측하는 모델이다. 이 방법은 정적 예측에 비해 훨씬 동적으로 대응할 수 있다.
동적 분기 예측은 1-bit prediction과 2-bit prediction로 나뉘는데 보통 2bit 예측을 사용한다. 1bit prediction는 taken(분기성공)/not-taken(분기실패)로 구성되며 예측이 연속으로 맞으면 계속 그 상태를 유지하고 예측이 틀리면 즉시 상태를 변경한다.
이와 달리, 2bit prediction는 상태마다 한 번씩 기회를 주며, 예측이 두 번 역속으로 틀릴 경우에만 State가 변경된다. 이 방법은 분기가 참,거짓,참,거짓과 같은 핑퐁 사태가 연속적으로 발생했을 때 1bit prediction에 비해 한번 더 기존의 예측을 믿기에 큰 도움이 된다.
Delayed Branch
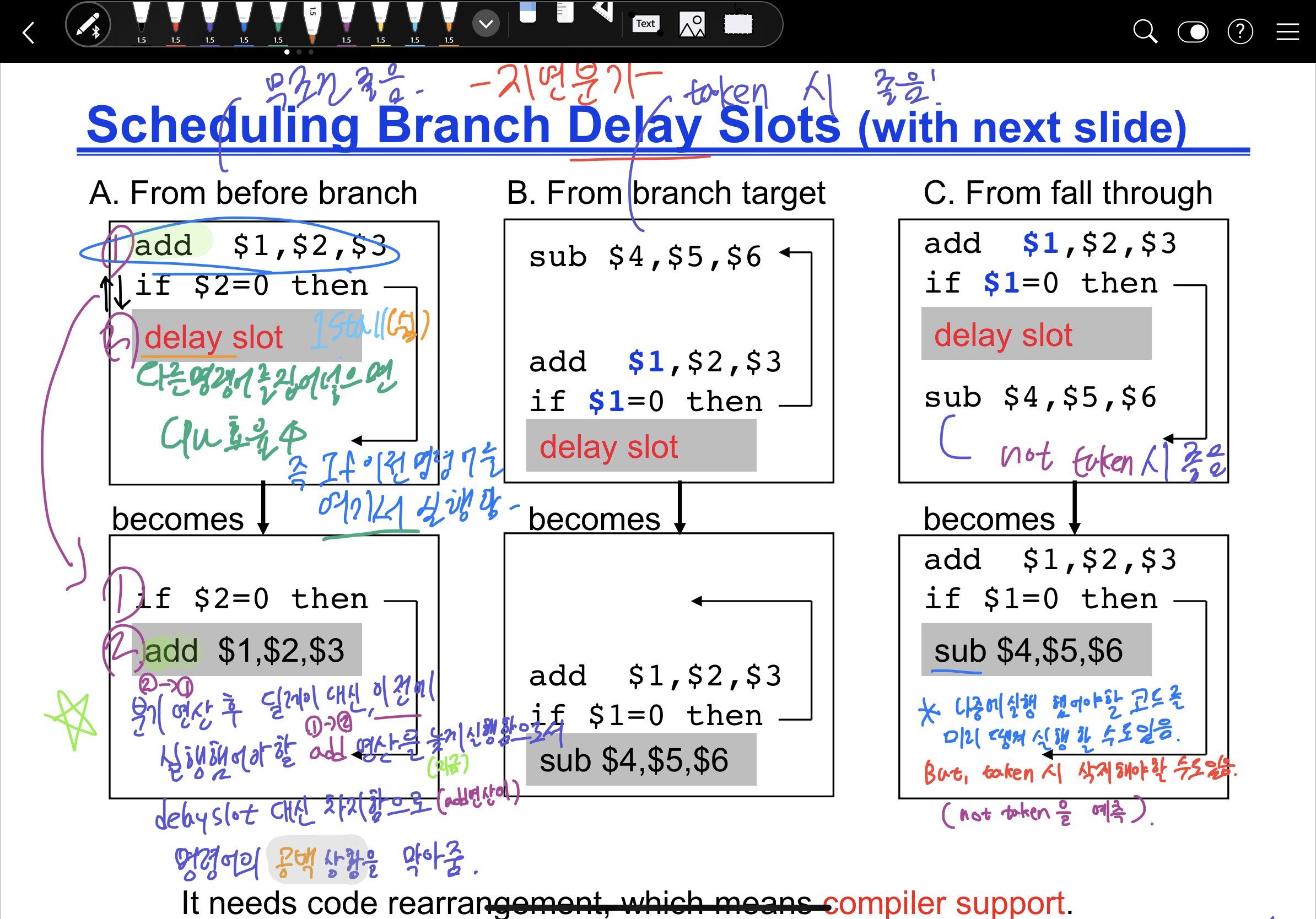
이 방법은 분기가 필요한 명령어의 결과값이 나오는 동안 해당 분기와 관련이 없는 명령어를 먼저 실행하여 파이프라인을 효율적으로 쓰는 방법이다. 이 작업을 위해선 해당 명령어가 먼저 실행되어도 안전하다는 증명이 필요하며 컴파일러의 최적화 능력에 따라 다양하게 이루어질 수 있다.
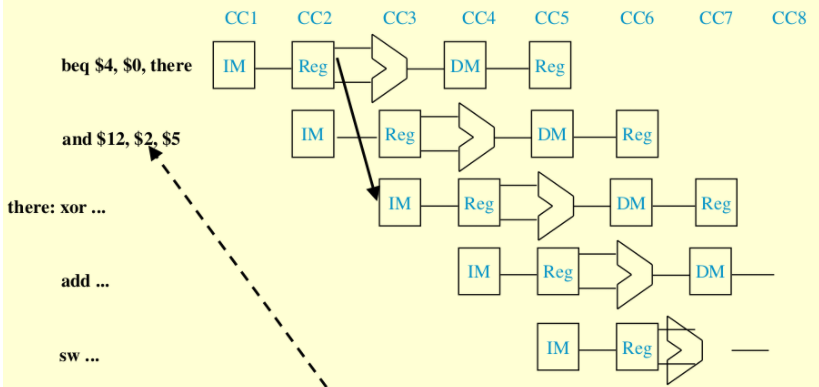
또는 그냥 beq 바로 뒤에 있는 명령어를 실행하다가 beq가 참으로 나와 점프해야할 경우 beq뒤에 실행 중인 and 명령어를 NOP로 밀이버리는 것이다. beq가 거짓으로 나왔다면 and 명령어는 어차피 실행됐어야 했으니 이득을 볼 수 있지만, beq가 참인 경우 and 명령어가 거쳐온 스테이지와 레지스터를 NOP로 밀어버려서 처음부터 없었던 경우로 만들어야 한다.
Branch Target Buffer (BTB)
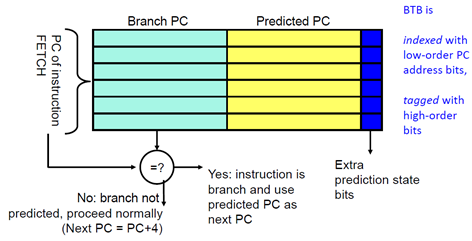
BTB는 instruction address(브랜치 명령어 주소) + predicted PC(점프한 주소)를 결합한 값을 보유하는 Cache 다. (While, For문에서 효과적)
BTB는 특별히 coprocessor에 의해 (main processor에서 떨어져) 따로 Cache처럼 관리된다.
기존 Branch의 문제점으로 분기가 안된다고 예측 때 만약 분기해야 한다는 결과가 나온다면, 현재 Fetch단계에서 실행되고 있는 명령어를 버려야 하는 낭비가 발생한다.
따라서 pipleline구조에서 Branch명령어에 따른 손실을 최소화하기 위한 대안이 필요한데 그 중 하나가 BTB(Branch Target Buffer)를 이용하는 방법이다.
BTB를 간단히 설명하자면 Branch 명령어가 나올 경우 더 갈것 없이 Fetch 단계에서 BTB 값을 이용하여 분기 여부를 결정하는 것이다. 이러한 방법은 실제로 명령어의 15~20%를 차지하는 Branch 명령어를 잘처리해줘서 전체적으로 상당한 성능을 보여 주고 있다.
BTB의 원리
BTB는 반복문에서 매우 유리하게 작용하는데, 만약 분기가 실행됐다면 BTB에 해당 PC(+점프주소)를 추가한다. (처음 분기시엔 BTB에 해당 주소가 없으니)
그리고 다음 분기 명령어가 인출 됐을 때 Fetch 단계에서 BTB를 참조하여, Fetch된 PC 값과 BTB의 엔트리(Branch PC) 값을 비교하여 (BTB 테이블은 해시 테이블 형태로 되어있어서 즉시 비교가 가능하다)
두 값(PC)이 일치할 경우(이 명령어가 이전에 분기된 적이 있는 경우) BTB의 해당 엔트리의 predicted PC(분기 주소)값을 기준으로 분기를 예측하고 다음 명령어를 진행한다.
이렇게 분기를 예측하여 다음 명령어를 파이프라인에 넣다가 기존 분기 명령어가 EX 단계에서 실제로 분기 연산이 일어난다면 그 결과를 토대로 전 단계 pipeline을 모두 비울지(예측실패), 그대로 파이프라인을 진행할지(예측성공) 선택하게 된다. 추가로 BTB를 통한 예측이 실패했다면 BTB의 해당 엔트리(주소)도 비워지게 된다.
100 do {
101 statement 1;
102 statement 2;
...
103 } while(condition);경우의 수는 다음과 같다.
-
BTB에 일치하는 값이 없는데 분기가 일어나지 않은 경우 : 그대로 진행(BTB에 넣지 않음)
-
BTB에 값이 없는데 분기가 일어난 경우 : BTB에 해당 PC와 predicted PC를 적어준다.
-
BTB에 값이 있는데 분기가 일어날 경우 : 성공적으로 분기 예측이 된다.
-
BTB에 값이 있는데 분기가 일어나지 않은 경우 : 예측이 실패하여 예측했던 동안 사용했던 Pipeline을 비우고, BTB의 해당 값을 삭제한다.
