
프롬프트 엔지니어 자격증이란?
프롬프트 엔지니어 자격증을 회득하기로 했다. AI-Test라는 기관에서 주관하는 시험인데 프롬프트 엔지니어링을 공부하면서 가볍게 따기 괜찮은 자격증인 것 같아 접수하였다. 해당 시험은 7.6(토) 10시에 3급 시험이 있으니 관심이 있는 사람은 위의 링크에 가서 접수하면 된다.
한 가지 불안한 점은 공부할 소스가 없다는 것이다. 후기도 인터넷에서 찾아볼 수 없고, 해당 사이트 블로그에 가면 전자책을 준비중이라 하는데 아직 출시가 되지 않아 직접 찾아가며 공부해야한다. 대신 시험에 나오는 주제는 나와있어 직접 리서치 해가며 공부해 보았다. 해당 시험을 준비하는 사람은 밑의 글을 참고하면 좋을 것이다. 중요하다고 생각하는 용어는 빨간색을 입혀주었다.
프롬프트의 개념 및 정의
'프롬프트'는 컴퓨터, 특히 언어 기반의 인공지능 모델에게 특정한 반응이나 정보를 요구하기 위해 주어지는 입력값을 의미한다. 이를 간단히 예로 들면, 검색 엔진에 '프롬프트 엔지니어링이란?'이라고 입력하는 행위도 프롬프트의 하나이다. 프롬프트는 명령, 질문, 제안 등 다양한 형태로 제공될 수 있다.
프롬프트 엔지니어링의 개념 및 정의
프롬프트 엔지니어링은 언어 모델에 특정한 반응을 유도하기 위해 사용되는 질문이나 명령, 즉 '프롬프트'의 최적화 과정이다. 예를 들어, 사용자의 질문에 최적화된 답변을 얻기 위해서는 어떻게 질문을 구성해야 하는지 연구하는 것이 포함된다.
품질 향상: 올바른 프롬프트 엔지니어링은 언어 모델의 출력 품질을 크게 향상시킨다. 이로 인해 사용자 경험이 향상되고, 기업은 더 나은 서비스를 제공할 수 있게 된다.
비용 절감: 효과적인 프롬프트 설계는 불필요한 연산 비용을 줄이고, 모델의 응답 시간을 개선한다.
사용자와의 소통: 사용자의 요구와 의도를 더 잘 이해하고 반영하기 위해 필수적이다.
바이어스 제거: 특히 언어 모델에서 바이어스를 최소화하고, 더 공정하고 중립적인 결과를 도출하는 것을 목표로 한다.
인공지능/딥러닝의 개념 및 정의
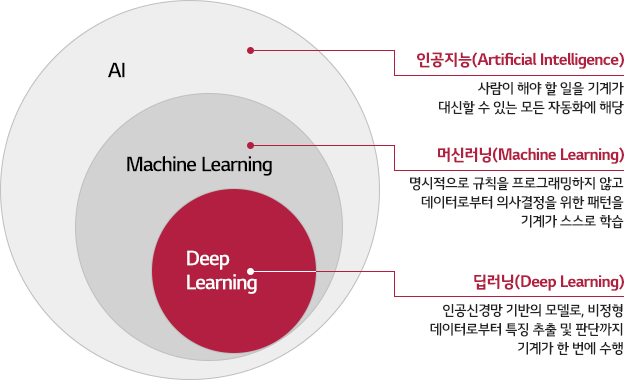
인공지능 (Artificial Intelligence, AI):
인공지능은 컴퓨터 시스템이 인간의 지능을 모방하여 학습, 추론, 문제 해결 및 의사 결정을 수행할 수 있게 하는 기술이다. AI는 기계 학습(ML), 딥러닝(DL) 등의 다양한 하위 분야로 나뉘며, 자연어 처리, 이미지 인식, 자율 주행 등 다양한 응용 분야에 사용된다.
딥러닝 (Deep Learning):
딥러닝은 인공 신경망(Artificial Neural Networks)을 기반으로 하는 기계 학습의 한 분야로, 다층 구조를 통해 데이터로부터 복잡한 패턴을 학습한다. 딥러닝 모델은 입력 데이터의 특징을 자동으로 추출하고, 이를 바탕으로 예측, 분류, 생성 등의 다양한 작업을 수행할 수 있다. 딥러닝은 지도 학습과 비지도 학습으로 나누어진다.
지도 학습 (Supervised Learning)
지도학습은 입력 데이터와 그에 대응하는 정답(레이블)이 주어진 상태에서 모델을 학습시키는 기계 학습 방법이다. 모델은 입력 데이터와 정답 간의 관계를 학습하여 새로운 데이터에 대해 예측할 수 있게 된다. 예를 들어, 강아지와 고양이 사진을 분류할 수 있는 모델을 학습시킬 때 들어가는 각 사진은 모두 강아지 또는 고양이로 레이블이 되어있다.
비지도 학습 (Unsupervised Learning)
비지도 학습은 입력 데이터만 주어지고, 정답(레이블)이 없는 상태에서 모델을 학습시키는 방법이다. 모델은 데이터의 구조나 패턴을 발견하는 데 중점을 둔다.
언어모델의 개념 및 정의
언어모델 (Language Model):
언어모델은 주어진 텍스트의 다음 단어나 단어 시퀀스를 예측하거나, 텍스트의 의미를 이해하고 생성할 수 있도록 설계된 기계 학습 모델이다. 언어모델은 문법, 의미, 문맥 등의 언어적 요소를 학습하여 자연어 처리 작업을 수행한다. 대표적인 언어모델로는 GPT-3, BERT, T5 등이 있다.
언어 모델의 주 기능은 다음과 같다.
텍스트 생성: 주어진 주제에 대해 자연스러운 텍스트 작성
번역: 한 언어에서 다른 언어로의 번역
질의응답: 질문에 대한 정확한 답변 제공
감정 분석: 텍스트의 감정 상태 분석
언어모델을 이해하기 위한 주요 용어들
토큰 (Token): 토큰은 자연어 처리(NLP)와 같은 언어 모델에서 사용되는 기본 단위이다. 텍스트를 분석하거나 처리할 때, 문장을 작은 단위로 나누어 처리하는데 이 작은 단위를 토큰이라 부른다. 토큰은 단어, 부분 단어, 구두점 또는 숫자와 같은 텍스트의 일부분일 수 있다.
토큰화 (Tokenization): 토큰화는 텍스트를 토큰 단위로 분할하는 과정이다. 이는 NLP 모델이 텍스트를 이해하고 처리할 수 있도록 하는 필수적인 전처리 단계이다. 토큰화 방법에는 여러 가지가 있다.
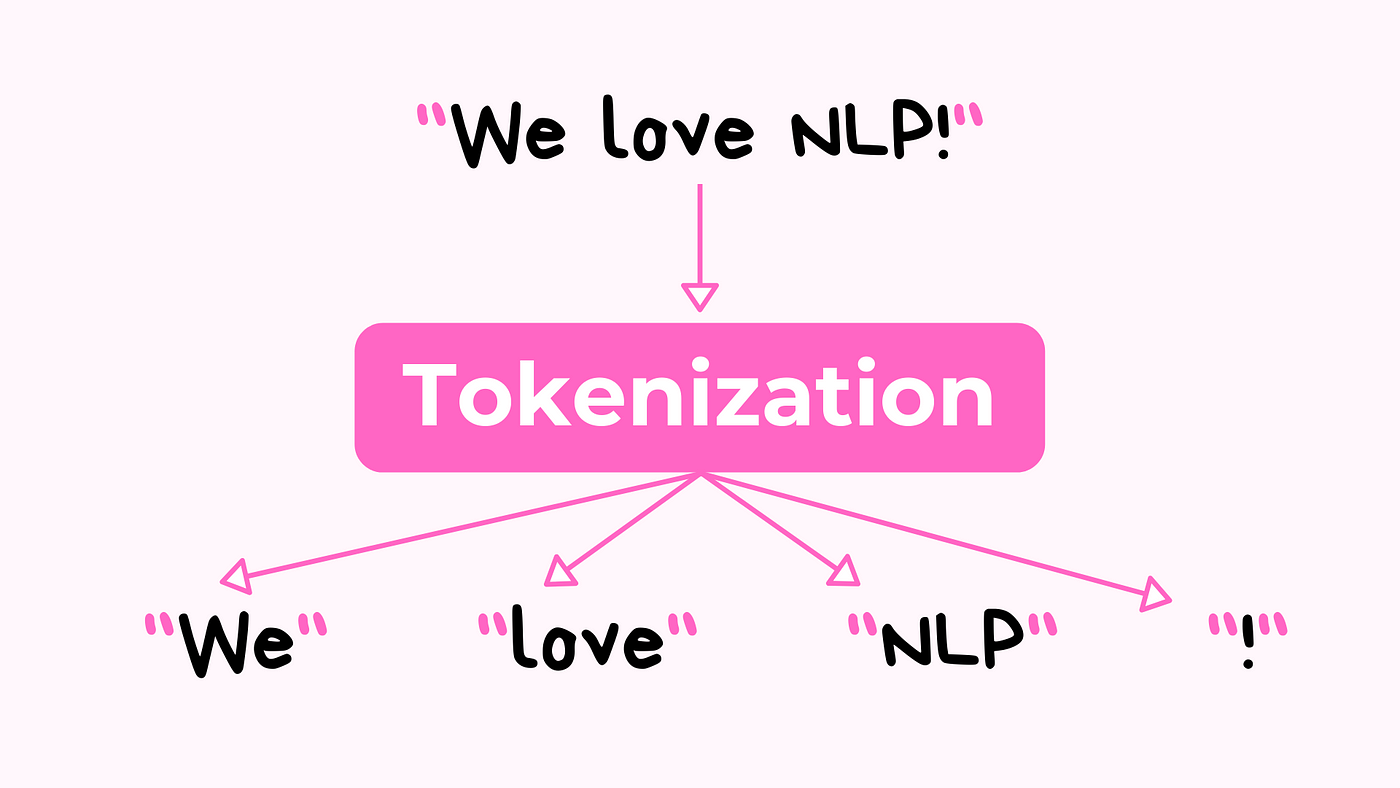
단어 단위 토큰화 (Word Tokenization):
텍스트를 단어 단위로 나눈다. 이 방법은 공백과 구두점을 기준으로 문장을 분할한다.
예시: "Hello, world!" -> ["Hello", ",", "world", "!"]
부분 단어 단위 토큰화 (Subword Tokenization):
단어를 더 작은 단위로 나누어 처리한다. 이는 신조어, 복합어 및 미지의 단어를 처리하는 데 유용하다. BPE(Byte Pair Encoding)나 WordPiece 알고리즘이 주로 사용된다.
예시: "unhappiness" -> ["un", "##happiness"]
문자 단위 토큰화 (Character Tokenization):
텍스트를 문자 단위로 나눈다. 이는 매우 세밀한 토큰화를 제공하지만, 일반적으로 더 긴 시퀀스를 생성한다.
예시: "Hello" -> ["H", "e", "l", "l", "o"]
워드 임베딩 (Word Embedding):
각 단어를 고정된 크기의 실수 벡터로 표현하는 기법. 유사한 의미를 가진 단어가 서로 더 가깝게 위치하는 고차원 공간에서 단어를 벡터에 매핑한다.
워드 임베딩 이전에는 one-hot encoding vector를 사용하였는데
예를 들어 10000개의 단어가 있는 LLM에서
"cat"의 벡터는 [0,0,0,1,......]가 된다. (차원 10000)
이 방식은 단어의 의미나 문맥을 고려하지 않고 공간 낭비가 심하다.
워드 임베딩 기법은 단어의 수와 상관없이 고정된 크기의 실수 벡터로 변환한다.
예를 들어 "cat"은 [0.23, -.21, 0.63, -.04,....]가 된다.
이러한 벡터는 단어간 유사도를 반영하기 때문에 모델이 단어의 의미와 문맥을 이해하는데 사용된다.
어텐션 (Attention): 입력 시퀀스의 각 요소가 출력 시퀀스의 각 요소에 미치는 영향을 동적으로 가중치를 부여하여 학습하는 메커니즘이다.
가중치를 조정함으로써 AI가 출력을 생성할 때 입력 텍스트의 특정 부분에 집중할 수 있도록 한다. 이를 통해 LLM은 주어진 입력의 맥락이나 감정을 고려하여 보다 일관되고 정확한 응답을 얻을 수 있다.
사전 학습 (Pre-training): 대규모 데이터셋에서 일반적인 언어 패턴을 학습하는 과정으로, 이후 특정 작업에 맞게 미세 조정된다.
미세 조정 (Fine-tuning): 사전 학습된 모델을 특정 작업에 맞게 추가로 학습시키는 과정이다.
언어모델 발전의 주요 흐름
n-그램 모델 (n-gram Models):
초기 언어모델은 n-그램 통계를 사용하여 단어 시퀀스를 예측하였다. 이는 단어의 연속성을 기반으로 다음 단어를 예측하는 방식이다.
기계 학습 기반 모델:
이후, 기계 학습 알고리즘을 사용하여 단어의 연관성을 학습하고 예측하는 모델이 등장했다. 이러한 모델은 특정 작업을 위해 특화된 피처(feature)를 사용했다.
워드 임베딩 (Word Embeddings):
앞서 설명한 워드 인베딩 기법이 개발되어 워드2벡(Word2Vec), 글로브(GloVe) 등이 개발되었다.
딥러닝 기반 모델:
RNN, LSTM, GRU 등의 순환 신경망(Recurrent Neural Networks)이 도입되어 문맥을 더 잘 반영하는 언어모델이 개발됐다.
트랜스포머 (Transformer) 모델:
입력 데이터를 처리하기 위해 셀프 어텐션 메커니즘 (Self Attention Mechanism)을 사용하는 LLM 연구에서 널리 사용되는 신경망 아키텍처 유형이다. 2017년 트랜스포머 아키텍처가 도입되면서 언어모델의 성능이 획기적으로 향상되었다. 트랜스포머는 병렬 처리가 가능하고 긴 문맥을 효과적으로 처리할 수 있다.
사전 학습된 모델 (Pre-trained Models):
BERT, GPT 등의 사전 학습된 모델이 개발되어, 대규모 데이터셋에서 사전 학습된 후 특정 작업에 맞게 미세 조정(Fine-tuning)되는 방식이 일반환되었다.
최신 언어모델 동향
최근 언어모델 분야에서는 대규모 모델의 개발과 활용이 활발하게 이루어지고 있다. GPT-3, T5, BERT 등과 같은 모델들이 자연어 처리의 다양한 작업에서 뛰어난 성능을 보이고 있으며, 특히 GPT-3은 대규모 파라미터(175B)를 통해 매우 자연스러운 텍스트 생성 능력을 보여주고 있다. 또한, 멀티모달 모델(Multimodal Models)과 같은 새로운 접근 방식이 등장하여, 텍스트 외에도 이미지, 음성 등 다양한 데이터 유형을 함께 처리할 수 있는 모델이 개발되고 있다.
언어모델 파라미터 설정
언어모델의 성능은 파라미터의 수와 설정에 크게 의존한다.
레이어 수 (Number of Layers): 모델의 깊이를 결정하며, 일반적으로 더 많은 레이어가 더 복잡한 패턴을 학습할 수 있다.
히든 유닛 수 (Number of Hidden Units): 각 레이어의 뉴런 수를 의미하며, 이는 모델의 용량과 표현 능력에 영향을 미친다.
드롭아웃 비율 (Dropout Rate): 과적합(overfitting)을 방지하기 위해 뉴런의 출력을 무작위로 제외하는 비율이다.
배치 크기 (Batch Size): 한 번에 학습하는 데이터 샘플의 수로, 큰 배치 크기는 더 안정적인 학습을 가능하게 한다.
학습률 (Learning Rate): 모델이 학습하는 속도를 조절하며, 너무 높으면 발산하고, 너무 낮으면 학습이 느려진다.
온도 (Temperature): 언어모델의 출력에서 확률 분포의 평탄화를 조절한다.
낮은 Temperature: “The quick brown fox jumps over the lazy dog.”처럼 일관된 문장을 생성.
높은 Temperature: “The quick azure fox leaps above the sleepy feline.”처럼 더 창의적인 문장을 생성.
프롬트 엔지니어링 기법
Zero Shot, Few Shot, Chain of Thought 등이 있으며 이 부분은 실제로 적용해보고 블로그 글을 새로 작성하였다. 글 링크
프롬프트 설계
프롬프트 설계는 AI 모델이 주어진 작업을 정확하게 수행하도록 하는 중요한 과정이다.
사용자의 의도 파악: 사용자가 원하는 결과를 명확히 이해하고, 이에 맞는 프롬프트를 설계한다.
간결하고 명확한 표현: 불필요한 정보를 배제하고, 명확한 언어를 사용한다.
예시와 패턴 제공: 모델이 따라할 수 있는 예시와 패턴을 제공한다.
피드백 반영: 테스트 결과를 바탕으로 프롬프트를 수정하고 최적화한다.
AI 윤리, 저작권
윤리적 고려 사항
공정성: AI 시스템이 편향되지 않고 공정하게 작동하도록 보장해야 한다.
투명성: AI의 작동 원리와 의사 결정 과정이 투명하게 공개되어야 한다.
책임성: AI 시스템의 결과에 대해 명확한 책임을 지는 체계가 마련되어야 한다.
프라이버시: 사용자의 개인정보를 보호하고, 데이터 사용에 대한 명확한 동의가 필요하다.
저작권
AI가 생성한 콘텐츠의 저작권 문제는 복잡한 법적 쟁점이 포함되어 있다.
창작자 권리: AI가 생성한 콘텐츠의 저작권이 누구에게 있는지 명확히 해야 한다
데이터 사용 허가: AI 모델 학습에 사용된 데이터의 저작권 및 사용 허가를 확인해야 한다
공정 사용: AI가 생성한 콘텐츠가 저작권을 침해하지 않도록 공정 사용 원칙을 준수해야 한다.
