분류 알고리즘
앙상블
앙상블이란?
여러개의 분류기(Classifier)를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측을 도출하는 기법을 말합니다.
앙상블의 유형으로는 일반적으로
- 보팅(Voting)
- 배깅(Bagging)
- 부스팅(Boosting)
으로 구분할 수 있습니다.
넓은 의미로는 서로 다른 모델을 결합한 것들을 앙상블로 지칭하기도 합니다.
앙상블의 특징
앙상블의 특징으로는
- 단일 모델의 약점을 다수의 모델들을 결합하여 보완
- 성능이 떨어지더라도 서로다른 유형의 모델을 섞는 것이 오히려 전체 성능에 도움이 될 수 있음
- 랜덤포레스트 및 뛰어난 알고리즘들은 모두 결정 트리 알고리즘 기반 알고리즘으로 적용함
- 결정트리의 단점인 과적합을 수십~수천개의 많은 분류기를 결합해 보완하고 장점인 직관적인 분류 기준은 강화됨
으로 보실 수 있습니다.
그럼 각 앙상블 유형을 파헤쳐 보도록 하겠습니다.
보팅(Voting)과 배깅(Bagging)
보팅과 배경은 여러 개의 분류기가 투표를 통해 최종 예측 결과를 결정하는 방식입니다.
그럼 보팅과 배깅의 차이점은 무엇일까요?

보팅과 배깅의 다른점은 보팅의 경우 일반적으로 서로 다른 알고리즘을 가진 분류기를 결합하는 것이고, 배깅의 경우 각각의 분류기가 모두 같은 유형의 알고리즘 기반이지만, 데이터 샘플링을 서로 다르게 가져가면서 학습을 수행에 보팅을 수행하는 것입니다.
보팅의 유형(Voting)
보팅은 하드 보팅과 소프트 보팅으로 나누어 집니다.
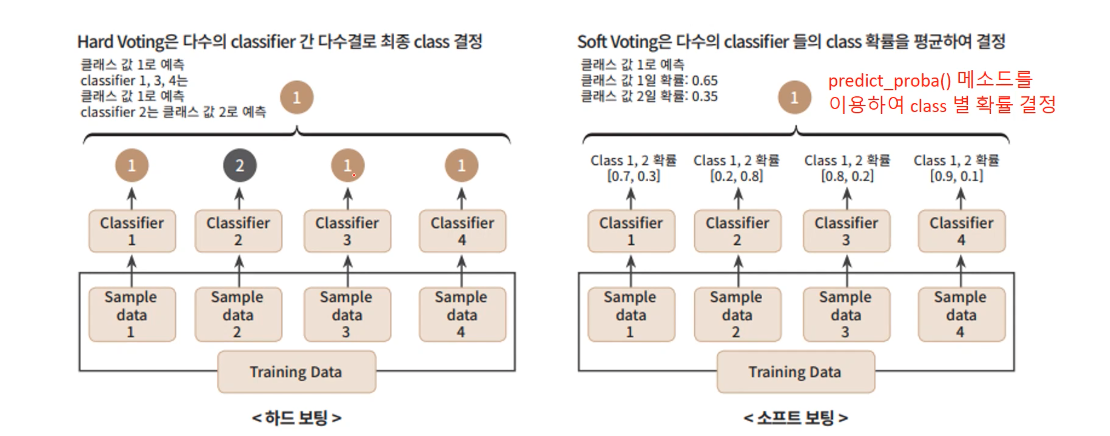
하드 보팅(Hard Voting) 과 소프트 보팅(Soft Voting)
하드 보팅의 경우 각 분류기가 예측한 결과를 다수결로 최종 class로 결정하는 방식이고, 소프트 보팅의 경우 각 분류기가 예측한 확률을 평균하여 결정하는 방식입니다.
일반적으로는 하드 보팅보다는 소프트 보팅이 예측 성능이 상대적으로 우수하여 주로 사용됩니다. 사이킷런은 VotingClassifier 클래스를 통해 보팅을 지원합니다.
다음은 VotingClassfier 사용 예제입니다.
# 개별 모델은 로지스틱 회귀와 KNN 임.
lr_clf = LogisticRegression()
knn_clf = KNeighborsClassifier(n_neighbors=8)
# 개별 모델을 소프트 보팅 기반의 앙상블 모델로 구현한 분류기
vo_clf = VotingClassifier( estimators=[('LR',lr_clf),('KNN',knn_clf)] , voting='soft' )
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target,
test_size=0.2 , random_state= 156)
# VotingClassifier 학습/예측/평가.
vo_clf.fit(X_train , y_train)
pred = vo_clf.predict(X_test)
print('Voting 분류기 정확도: {0:.4f}'.format(accuracy_score(y_test , pred)))
여기서는 로지스틱 회귀와 KNN 서로 다른 모델을 결합하여 소프트 보팅의 방식으로 학습을 하였습니다.
배깅과 랜덤포레스트
배깅의 대표적인 알고리즘 랜덤 포레스트에 대해서 알아봅시다.
랜덤 포레스트는 여러개의 결정 트리 분류기가 전체 데이터에서 배깅 방식으로 각자의 데이터를 샘플링해 개별적으로 학습을 수행한 뒤 최종적으로 모든 분류기가 보팅을 통해 예측결정을 하는 모델입니다.
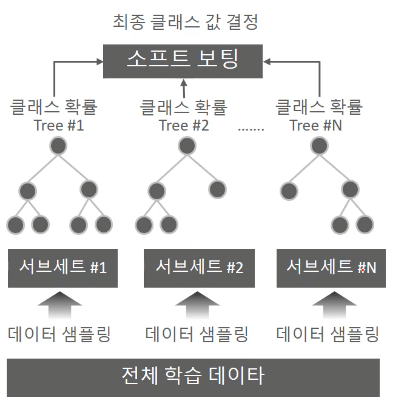
랜덤 포레스트의 부트스트래핑 분할
랜덤 포레스트는 여러개의 결정트리 분류기가 각자의 데이터를 샘플링 하여 학습한다고 하였습니다. 그 때 여러 개의 데이터 세트를 중첩되게 분리하는 것을 부트스트래핑(bootstrappintg) 분할 방식이라고 합니다. 배깅(Bagging) 의 뜻도 bootstrap aggregating에서 온 말입니다.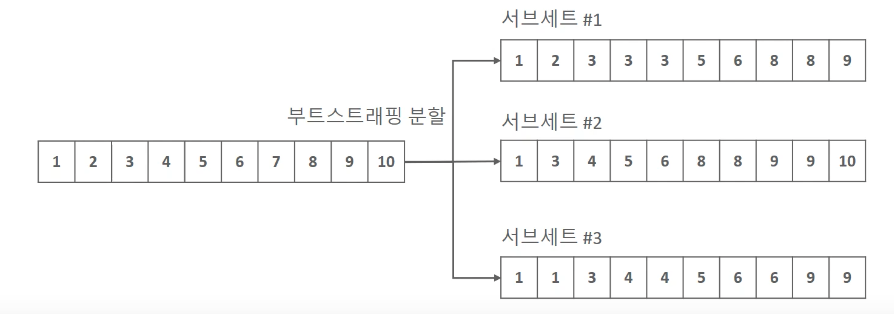
부스팅(Boosting)
이번엔 부스팅이라는 앙상블의 유형을 알아보겠습니다.
부스팅 알고리즘은 여러 개의 약한 학습기(week learner)를 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치 부여를 통해 오류를 개선해 나가면서 학습하는 방식입니다.
부스팅의 대표적인 구현으로는 AdaBoost와 그래디언트 부스트 (Gradient Boost)가 있습니다.
에이다 부스팅의 학습/예측 프로세스 그림을 보며 부스팅 방식이 어떻게 학습하는지 대략적으로 살펴봅시다.
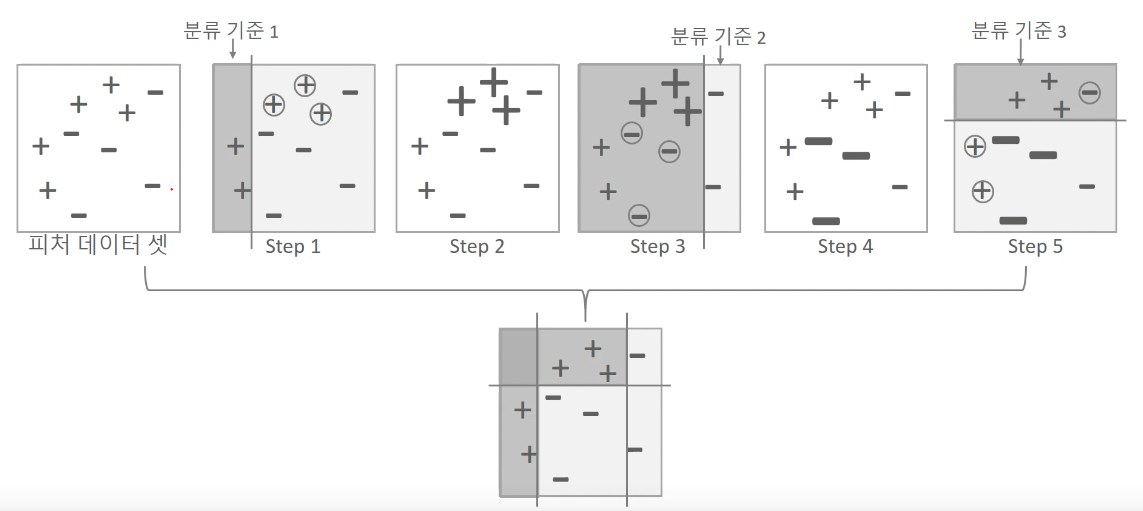
다음과 같이 하나의 약한 학습기가 학습-예측을 마치면 잘못 예근한 데이터에 가중치를 부여하면서 다음 약한 학습기가 이를 토대로 학습을 진행합니다. 그리고 이 분류 1,2,3 을 예측한 결과는 약한 학습기 하나가 예측한 결과보다 훨씬 정교하게 예측되었음을 알 수 있습니다.
하지만 이 순차적으로 학습한다는 것에서 알 수 있듯이 다른 앙상블 기법에 비해 부스팅은 학습시간이 오래걸린다는 단점이 있습니다.
GBM(Gradient Boosting Machine)
GBM은 에이다부스트와 윳하나, 가중치 업데이트를 경사 하강법(Gradient Descent)을 이용하는 것이 큰 차이입니다. 분류의 결과값을 피처를 그리고 피처에 기반한 예측함수를 라고 하면 오류식 가 됩니다.
이 오류식을 최소화하는 방향성을 가지고 반복적으로 가중치 값을 업데이트하는 것이 경사하강법입니다.
경사 하강법은 회귀에서 자세히 다룰 예정이나 궁금하신분들, 경사하강법에 대한 자세한 내용은 구글링 또는 여기블로그를 참조하면 좋을 것 같습니다.
GBM의 하이퍼 파라미터
사이킷런은 GBM 분류를 위해 GradientBoostingClassifier 클래스를 제공합니다.
| 하이퍼 파라미터 | 설명 |
|---|---|
| loss | 경사 하강법에서 사용할 비용함수를 지정합니다. 기본값은 'deviance'입니다. |
| learning_rate | GBM이 학습을 진행할 때 마다 적용하는 학습률입니다. |
| n_estimators | weak learner 의 개수입니다. |
| subsample | weak learner가 학습에 사용하는 데이터 샘플링 비율입니다. |
learning rate는 0~1사이의 값으로 지정하며 디폴트 값은 0.1입니다. 이 값을 너무 작게 설정하면 모든 Weak learner가 반복이 완료되어도 최소 오류값을 찾지 못할수도 있습니다. 또 큰 값을 설정하면 최소 오류값을 찾지 못하고 지나쳐 버려서 예측 성능이 떨어지지만 빠른 수행이 가능합니다. 그렇기 때문에 n_estimators 값과 조합하여 보완해 나가며 사용합니다.
XGBoost와 LightGBM
XGBoost와 LightGBM 모두 GBM기반의 모델로서 GBM의 단점을 개선하기 위해 등장한 모델입니다.
XGBoost의 경우 GBM대비 빠른 속도와 규제기능과 Tree Pruning 기능을 가지고 있어 성능 향상을 기대할 수 있고 조기중단, 자체 내장된 교차검증, 결손값 자체 처리등 다양한 편의 기능을 가지고 있습니다.
LightGBM의 경우 마이크로소프에서 개발한 모델로서 XGBoost보다 더 빠른 학습과 예측 수행 시간을 가지고 있고 더 작은 메모리 사용량을 가집니다. 또한 카테고리형 피처의 자동 변환과 최적 분할 즉, 원-핫 인코딩 등을 사용하지 않고도 카테고리형 피처를 최적으로 변환하고 이에 따른 노드 분할을 수행합니다.
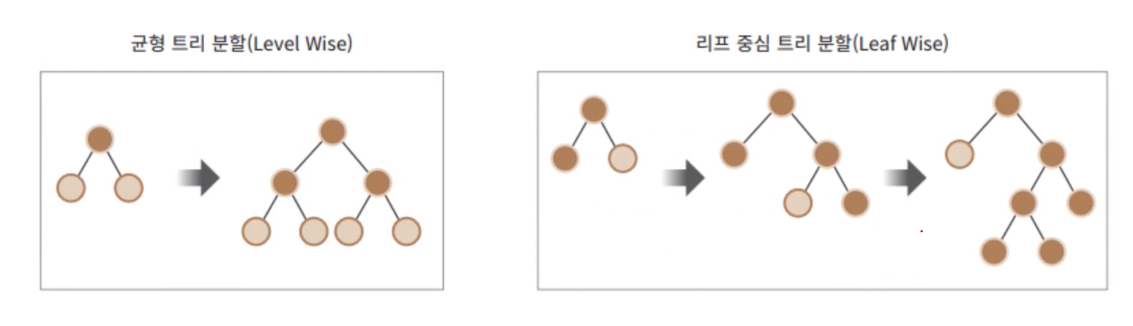
LightGBM의 경우 트리 분할 방식이 기존 XGBoost를 포함한 트리 생성 방식과 다르게 리프 중심 트리 분할을 통해 빠르고 정확한 학습,예측이 가능하다고 합니다.
