Feature Engineering
이번에는 좋은 머신러닝 모델을 만들기 위한 피쳐 엔지니어링에 대해 리뷰 해보겠습니다.
좋은 알고리즘을 사용한 모델일 수록 하이퍼 파라미터 튜닝보다는 피쳐 엔지니어링을 건드려 보는 것이 더 효율적이라고 합니다.
피쳐 엔지니어링의 방법으로 다음과 같은 방법을 사용할 수 있습니다.
중요 Feature의 데이터 분포도 변경
Log 변환
Log 변환은 왜곡된 분포도를 가진 데이터 세트를 비교적 정규 분포에 가깝게 변환해주는 훌륭한 Feature Engineering 방식입니다.
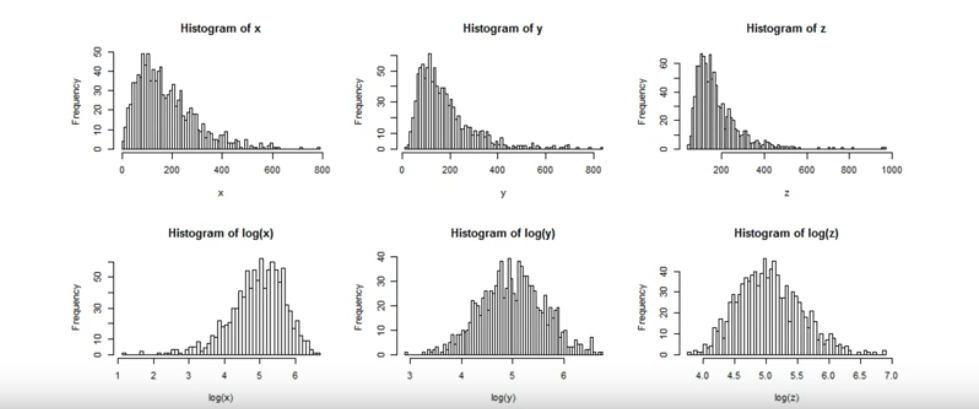
[출처: inflearn 파이썬 머신러닝 완벽가이드 강의]
로그변환은 다음과 같이 넘파이의 log1p()를 이용하여 변환합니다.
아래의 예제는 모두 '신용카드 사기 검출 데이터'를 기반으로 작성되었습니다.
def get_preprocessed_df(df=None):
df_copy = df.copy()
# 넘파이의 log1p( )를 이용하여 Amount를 로그 변환
amount_n = np.log1p(df_copy['Amount'])
df_copy.insert(0, 'Amount_Scaled', amount_n)
df_copy.drop(['Time','Amount'], axis=1, inplace=True)
return df_copy이상치 제거(Outlier Removal)
이상치 제거는 간혹 데이터에서 비정상적으로 크거나 작은 수치를 학습에서 제외시키므로서 성능향상을 기대할 수 있습니다.
대표적인 방법으로 IQR(Inter Quantile Range)를 이용한 방법으로서 다음과 같은 원리를 이용합니다.
[출처: inflearn 파이썬 머신러닝 완벽가이드 강의]
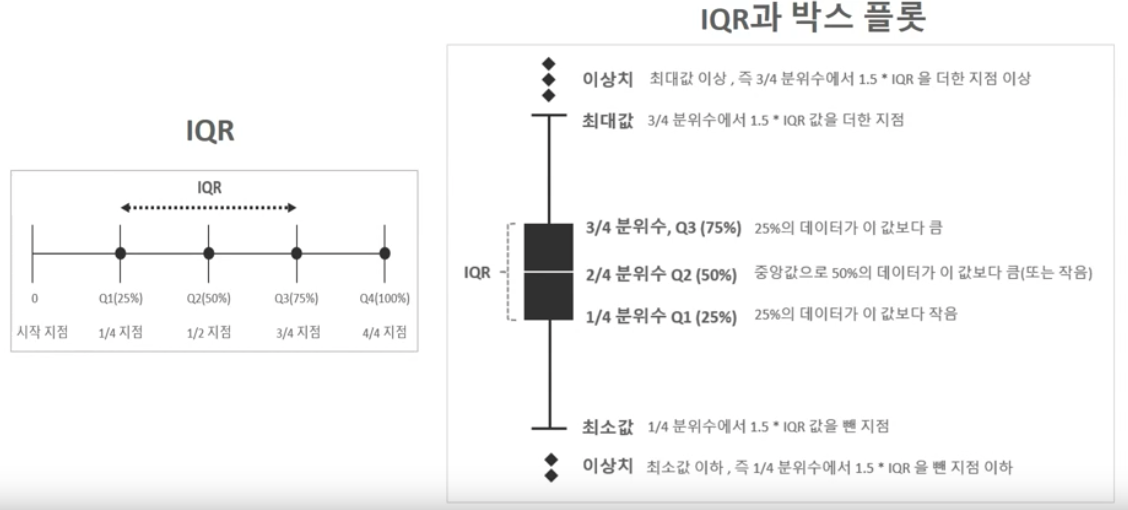
이는 다음 예시코드와 같이 시각화를 통해 class 값과 가장 상관도가 높은 피처를 추출하고, 그 피처에 대해 이상치를 제거하는 방식으로 진행할 수 있습니다.
import seaborn as sns
plt.figure(figsize=(9, 9))
corr = card_df.corr()
sns.heatmap(corr, cmap='RdBu')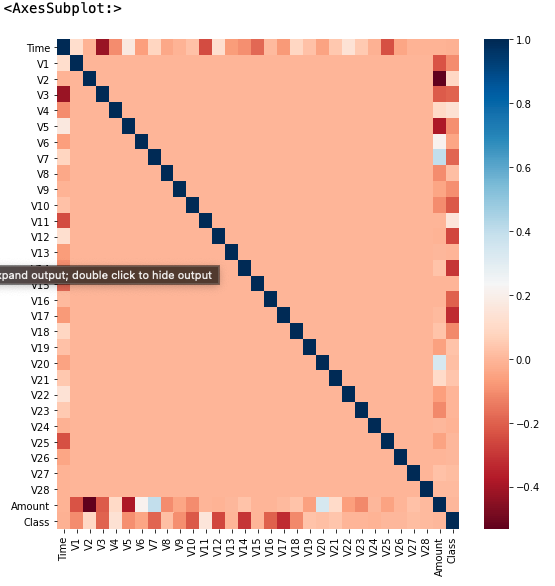
시각화된 상관도를 보면 v12, v14, v17 변수들이 비교적 상관도가 높은 모습을 보실 수 있는데요, 이중 v14의 이상치를 제거하는 코드를 살펴보겠습니다.
import numpy as np
def get_outlier(df=None, column=None, weight=1.5):
# fraud에 해당하는 column 데이터만 추출, 1/4 분위와 3/4 분위 지점을 np.percentile로 구함.
fraud = df[df['Class']==1][column]
quantile_25 = np.percentile(fraud.values, 25)
quantile_75 = np.percentile(fraud.values, 75)
# IQR을 구하고, IQR에 1.5를 곱하여 최대값과 최소값 지점 구함.
iqr = quantile_75 - quantile_25
iqr_weight = iqr * weight
lowest_val = quantile_25 - iqr_weight
highest_val = quantile_75 + iqr_weight
# 최대값 보다 크거나, 최소값 보다 작은 값을 아웃라이어로 설정하고 DataFrame index 반환.
outlier_index = fraud[(fraud < lowest_val) | (fraud > highest_val)].index
return outlier_index그 후, 함수를 호출하여 v14 변수에 적용합니다.
outlier_index = get_outlier(df=card_df, column='V14', weight=1.5)
SMOTE 오버 샘플링
SMOTE를 사용하기 전에 앞서 언더 샘플링과 오버샘플링에 대해 알아봅시다.
레이블이 불균형한 분포를 가진 데이터 세트를 학습 시, 이상 레이블을 가지는 데이터 건수가 매우 적어 제대로 된 유형의 학습이 어려운 경우가 있습니다. 반면에 정상 레이블을 가지는 데이터 건수는 매우 많아 일방적으로 정상 레이블로 치우친 학습을 수행하여, 제대로 된 이상 데이터 검출이 어렵게 됩니다.
이를 해결하기 위해 시도해 볼만한 방법 중 하나가 언더 샘플리와 오버샘플링입니다.
[출처: inflearn 파이썬 머신러닝 완벽가이드 강의]

여기서는 SMOTE(Synthetic Minority Over-Sampling Technique)에 대해 알아보겠습니다.
[출처: inflearn 파이썬 머신러닝 완벽가이드 강의]
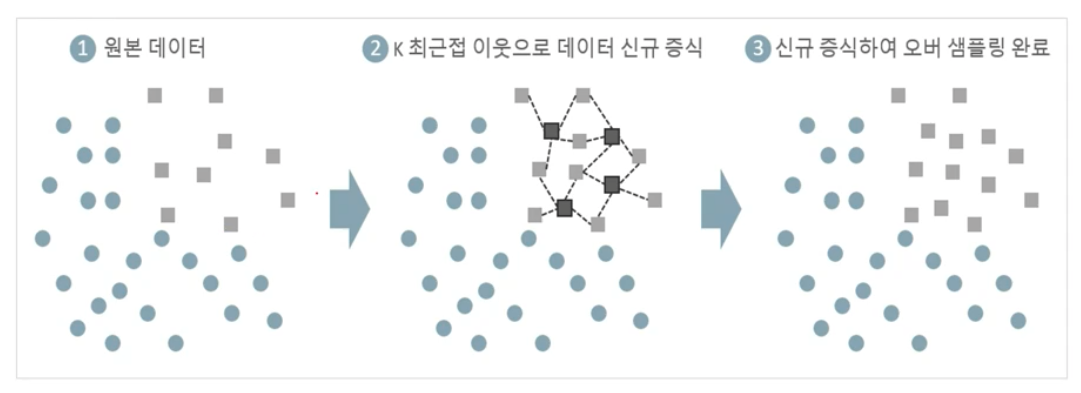
SMOTE는 원본 데이터에서 오버샘플링할 데이터들을 K 최근접 이웃으로 오버샘플링할 데이터와 유사한 데이터를 만들어 증식 시킵니다.
SMOTE는 imbmearn라이브러리의 SMOTE모듈을 이용하여 편리하게 이용할 수 있습니다.
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=0)
X_train_over, y_train_over = smote.fit_sample(X_train, y_train)