
Background
사전 학습 (Pre-training) : 모델을 일반적인 대규모 데이터로 미리 학습시키는 것, 레이블 없는 자가 지도 학습이 가능하다. / 데이터의 이해도를 높일 수 있다. / 레이블이 적은 데이터의 과적합을 막을 수 있다.
전이 학습(Transfer Learning) : 사전 학습 모델을 다른 작업에 적용
파인 튜닝(Fine-Tuning) : 전이 학습 중 일부 또는 전부를 미세 조정
BERT 사전 학습
Bert는 MLM(Masked Language Modeling)과 NSP(Next Sentence Prediction)과 같은 사전 학습을 통해 문장의 이해 능력을 습득한 후 파인 튜닝을 통해 용도에 맞게 학습한다. (문장 분류,QA 등)
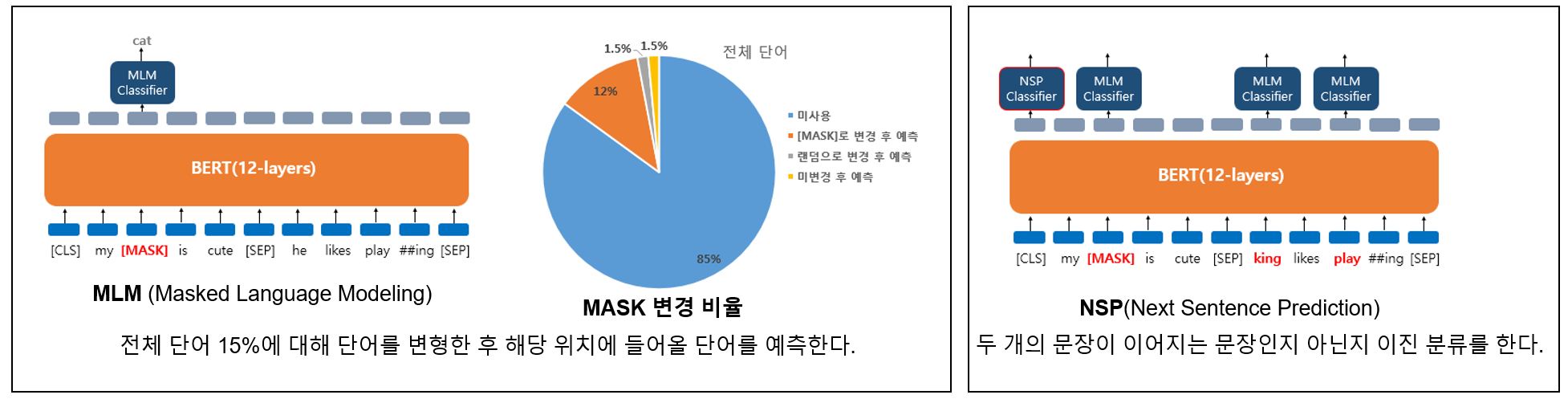
Motivation
(VIT와 같은) 이미지 모델도 Bert의 MLM 방식과 같이 사전 학습을 통해, 이미지 이해력을 높인 후 학습시키고자 등장했다.
what makes masked autoencoding different between vision and language?
- 모델이 달랐다. (CNN 기준)
VIT는 MASK 토큰을 출력에서 그대로 추출할 수 있지만, CNN의 경우 그렇지 않았다.
-> VIT를 사용한다. - 언어와 이미지의 밀도가 다르다, 언어는 사람이 만든 신호로 의미의 밀도가 깊고, 이미지는 공간적 중복이 많아 의미의 밀도가 낮고, 복잡한 이해가 필요치 않다.
-> 많은 비율을 Masking해서 학습한다. - 디코더의 역할이 다르다.
-> 언어는 예측 단어가, 의미를 담고 있기 때문에 MLP의 단순한 구조도 괜찮으나, 이미지는 의미가 적어 디코더의 설계가 중요하다.
Method
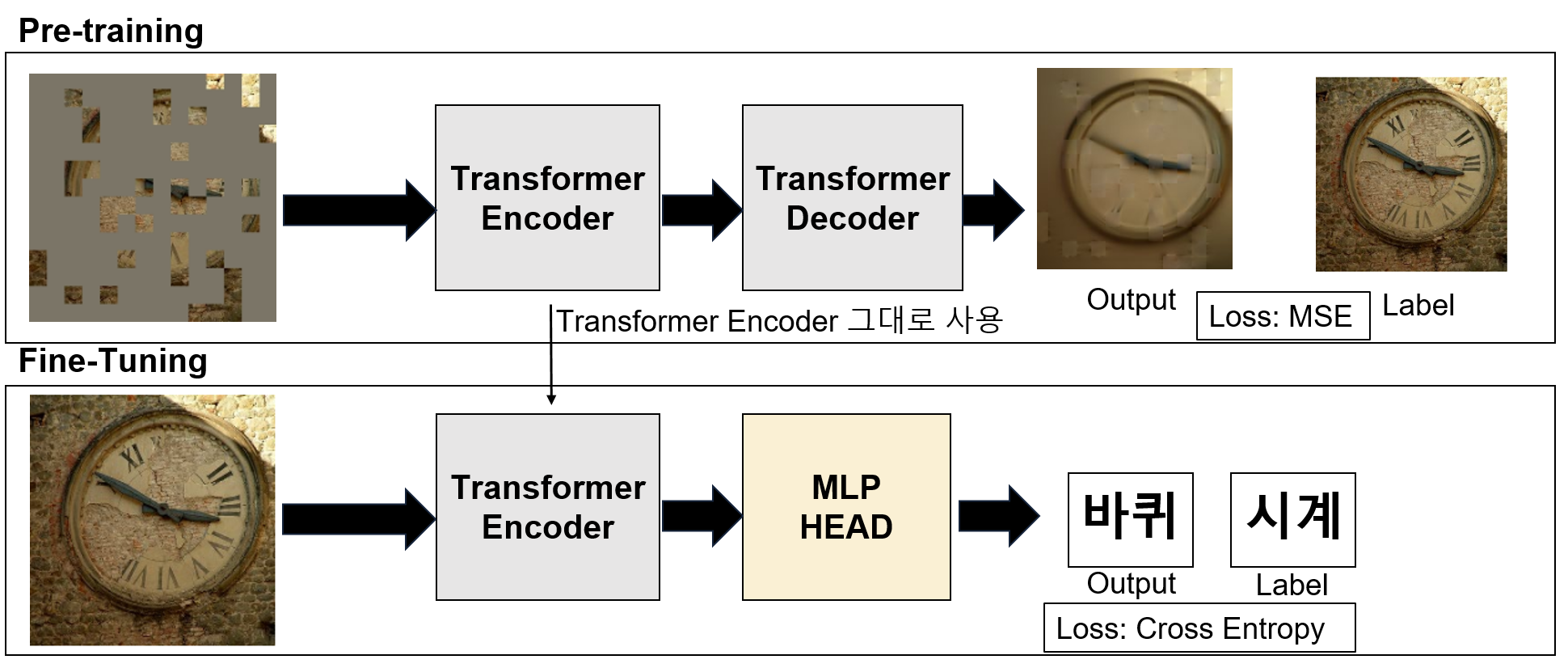
1. 전체적인 학습 구조
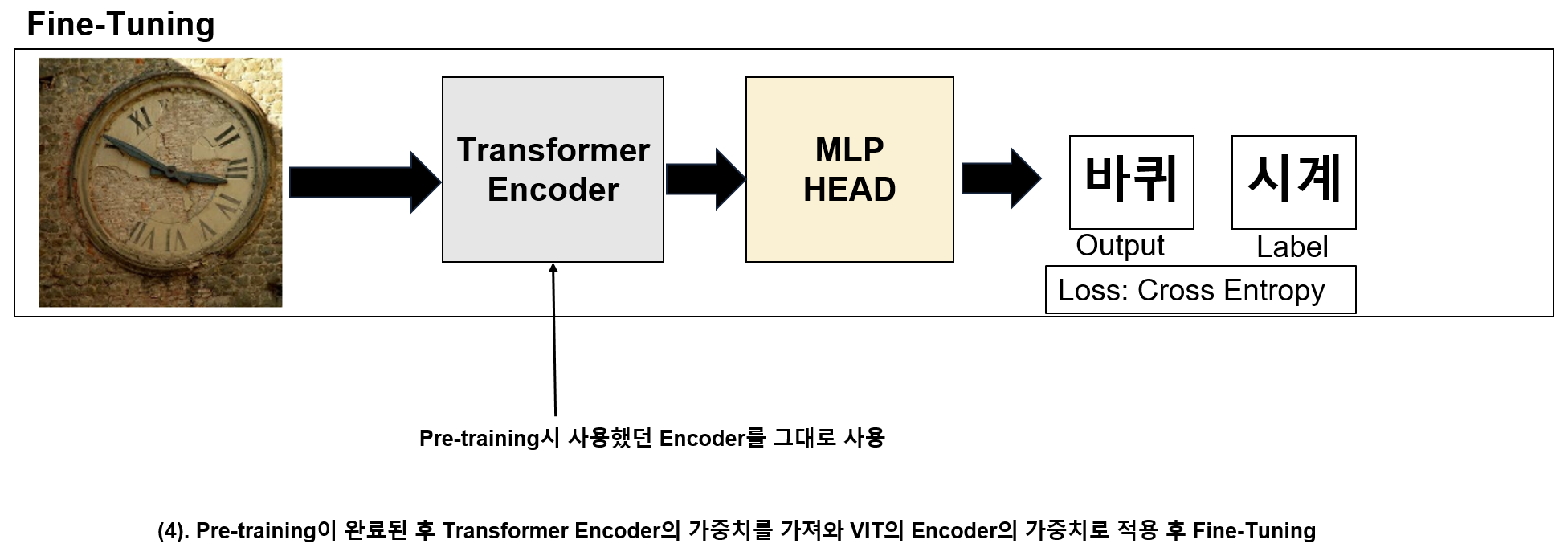
- Pre-training시 사용한 Transformer Encoder를 Fine-Tuning시 그대로 사용한다.
2. Pre-training시 과정
1). 이미지의 75%를 Random으로 마스킹을 씌운다.
2). UnMasking된 패치들만 Transformer Enoder의 입력으로 사용한다.
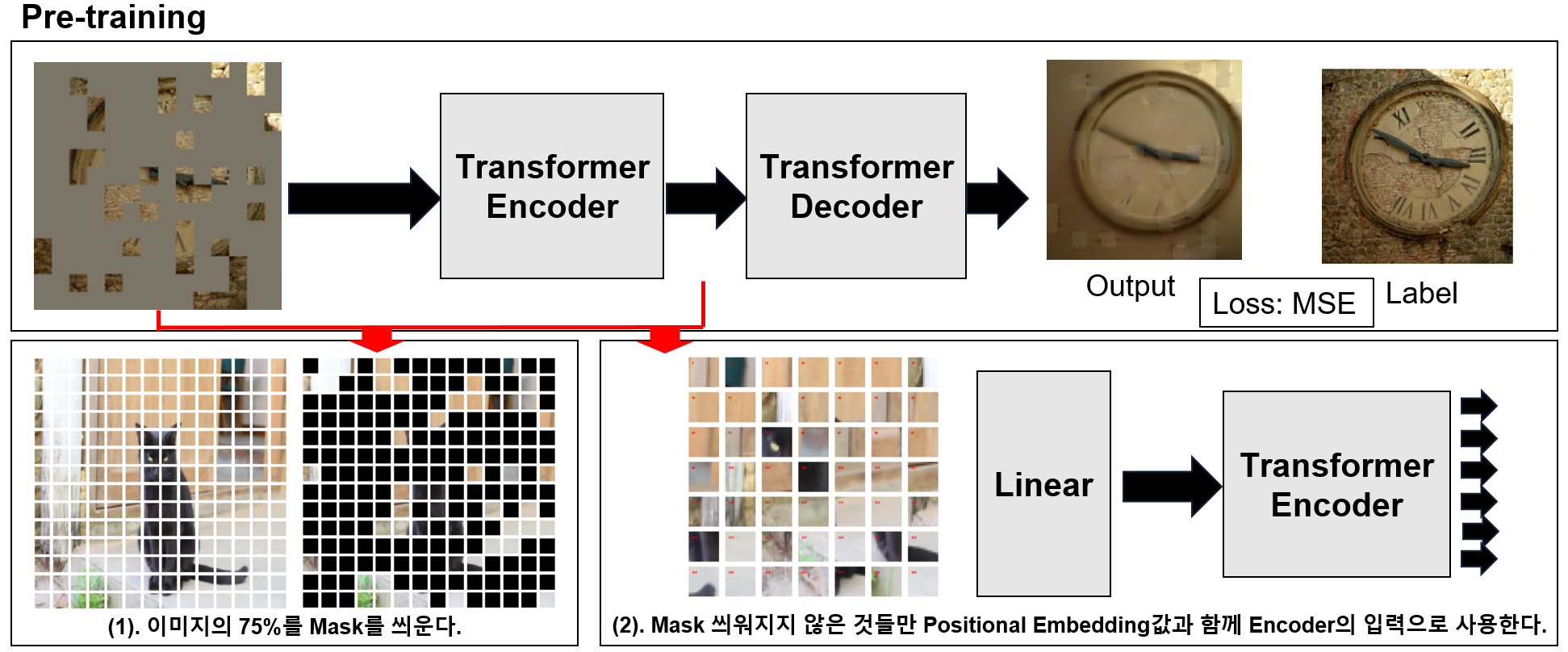
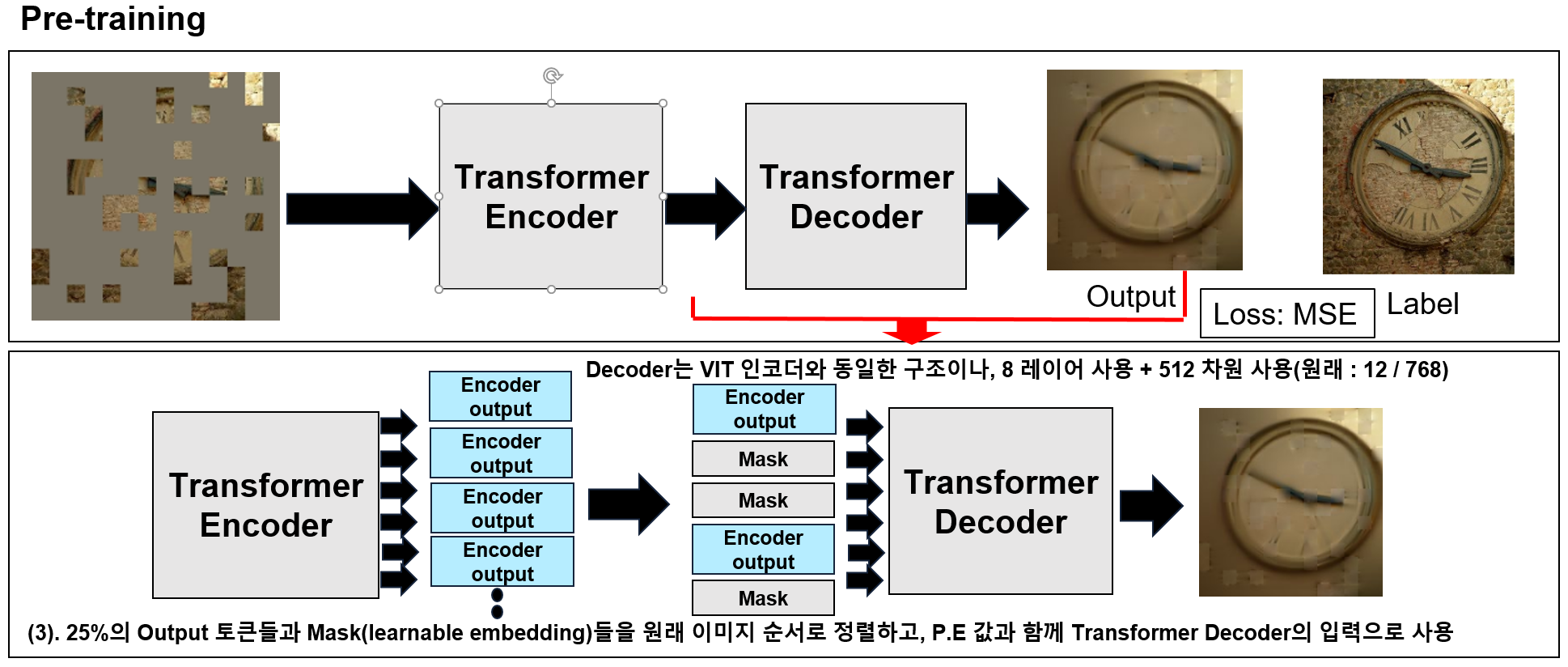
3). Transformer Encoder의 출력과 Mask들의 순서를 원래 이미지의 순서대로 재정렬한 후 Transformer Decoder의 입력으로 사용한다.
4).Transformer Decoder의 구조는 인코더와 같은 구조이나, 낮은 레이어층(8층)+낮은 차원을 사용한다.(512차원)
5). Transformer Decoder의 output과 label을 MSE를 사용해 Loss를 계산한다.
3. Fine-Tuning
- Pre-training시 사용했던 Encoder를 그대로 사용한 후 원래의 목적(Classification)에 맞게 Fine-Tuning을 한다.
Experiment
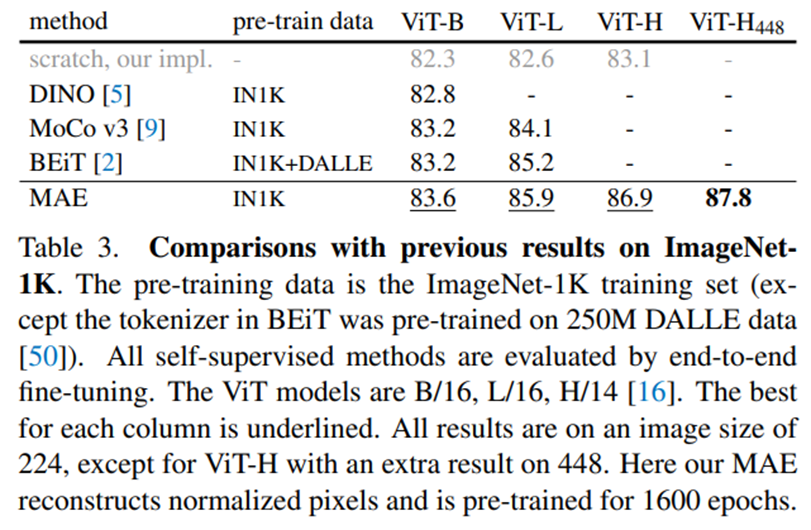
1. Imagenet 성능비교
- scratch, original은 이전 VIT 논문의 성능, scratch, our impl는 MAE 저자들이 직접 VIT를 학습시켜본 결과, baseline MAE는 해당 논문의 결과

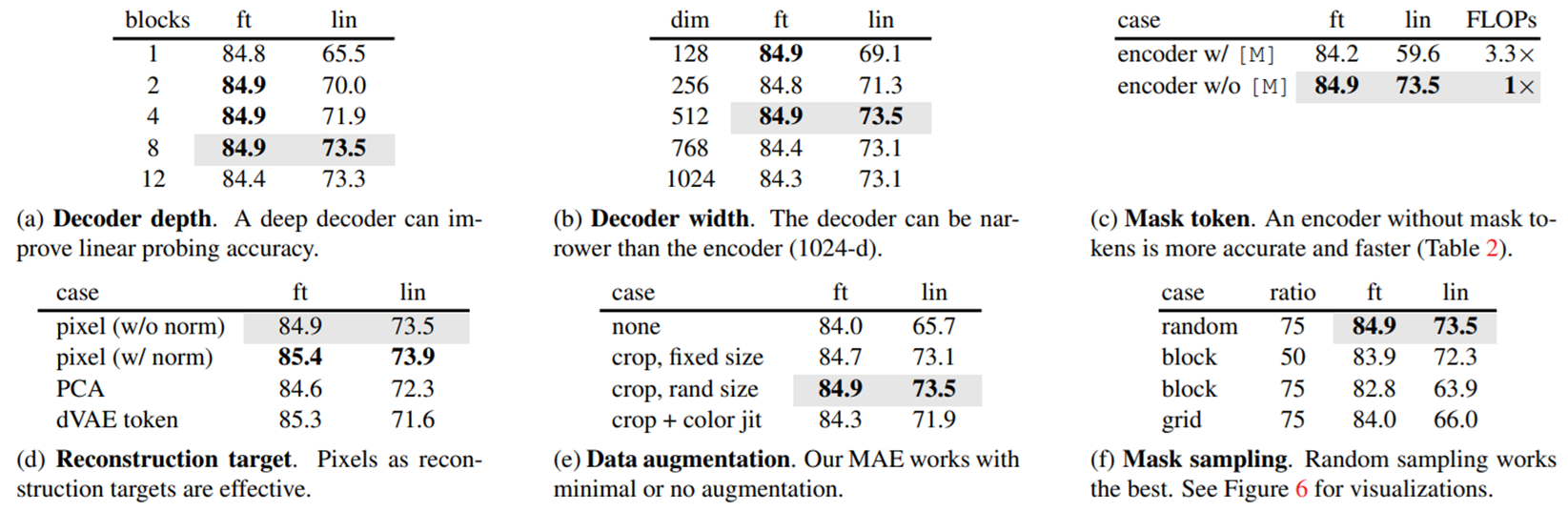
2. Ablation experiment 결과
- ft : Fine-Tuning
- lin : 인코더 뒤에 Linear층만 사용
(Bert 스타일을 따랐으므로 Linear층도 사용해보았다고 이야기한다.)
a. Decoder의 깊이에 따른 성능 : fine-tuning시 Decoder의 층에 상관없이 거의 일정한 성능을 보여준다. 이 점에서 Decoder를 얕게 설계해도 된다고 생각한 것 같다.
b. Decoder의 채널 : 이것 역시 큰 차이를 보이지 않았다.
c. Encoder에 Mask 입력 사용 여부 (w: with w/o : without) : 사용하지 않았을 때 오히려 성능은 증가했고, 계산량 역시 3배 가까이 줄었다.
f. 마스크 크기에 따른 성능 : random : 랜덤, block : 하나의 큰 덩어리로 grid: 일정한 규칙으로
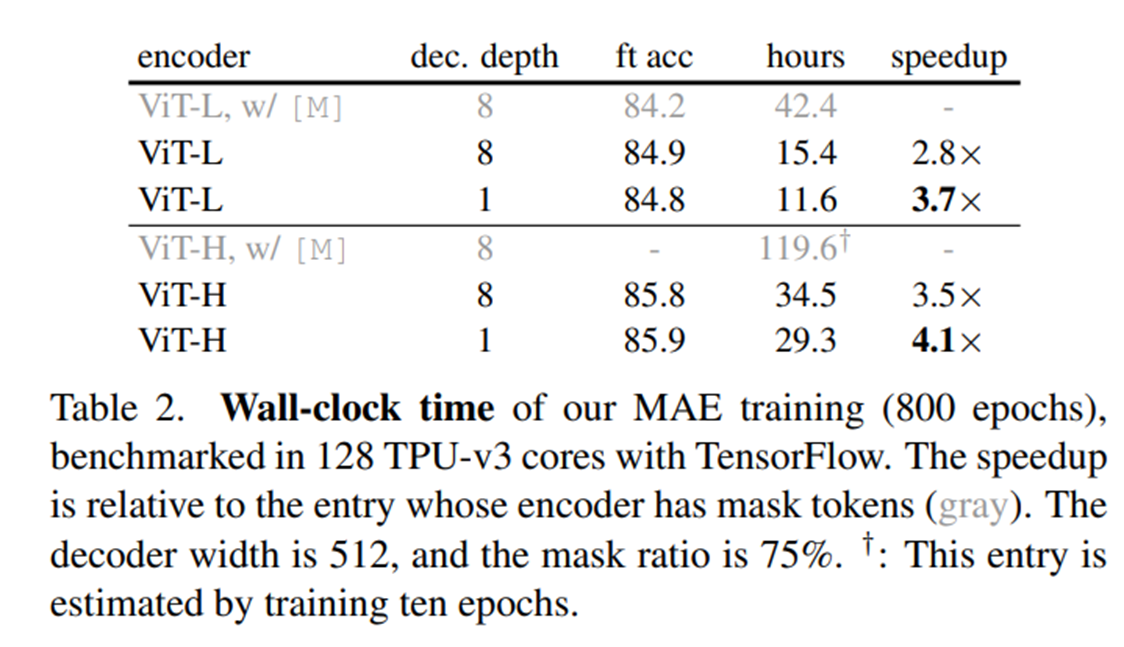
3. Decoder experiment 결과
- 마스크를 인코더에 넣었을 때
- 마스크를 인코더에 넣지 않았을 때
- 마스크를 인코더에 넣지 않고 디코더 블록을 얕게 넣었을 때
- 마스크를 인코더에 넣지 않았을 때 성능이 좋았고, Pre-training시간이 2.8배가 빨랐다.
- 디코더 레이어가 얕아도 성능차이는 거의 없다.
4. Masking portion experiment 결과
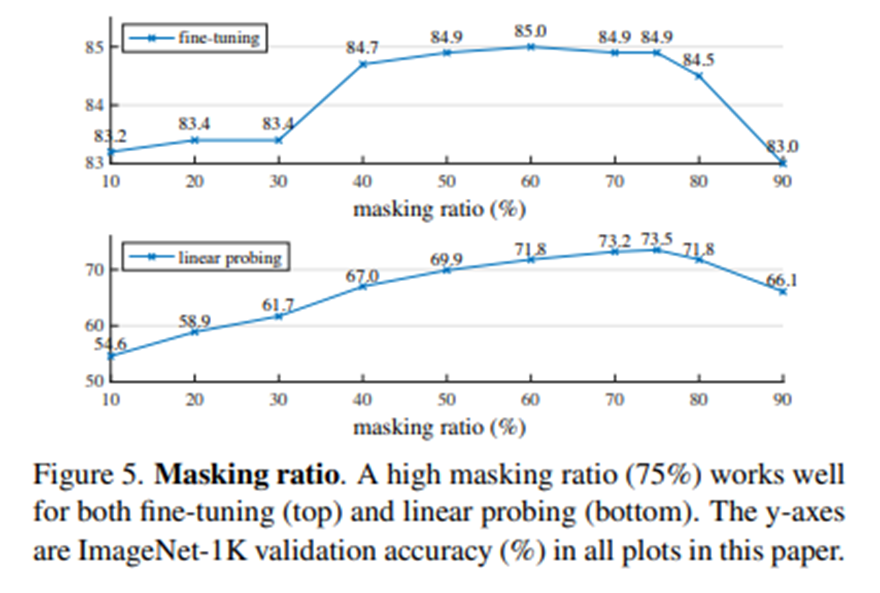
5. Masking portion experiment 결과
- Distillation 방식
- Constrastive 방식
- BERT MLM 방식

흘러가는대로 살자