
OVERVIEW
논문 출간 날짜 - 21.12
- VIT 구조를 이용한 Video Classification 모델
- 입력 영상을 Tublet(작은튜브)로 쪼갠 후, token으로 변환하여 Transformer에 입력하는 방식
- Factorise(분해)라는 개념을 사용한 모델 3개와 사용하지 않은 모델 1개, 총 4가지 구조를 제안
- Spatial과 Temporal Space를 Factorise하고자 함.
(Tublet)
-> h x w x Time
Introducing
VIT에 video를 입력으로 사용할 경우의 문제에 대해 설명하고 있음.
(1) VIT의 Inductive bias 문제
-> 이는 데이터 양을 늘리면 해결할 수 있음. (BUT)
(2) 이미지 학습 데이터는 많지만, 영상 학습데이터는 해당 문제를
해결하기에 데이터가 부족함
-> VIT의 가중치를 사용해 해결할 수 있음.
(3) 기존의 VIT와 VIVIT의 구조가 달라 가중치 값을 사용하는데 문제 발생
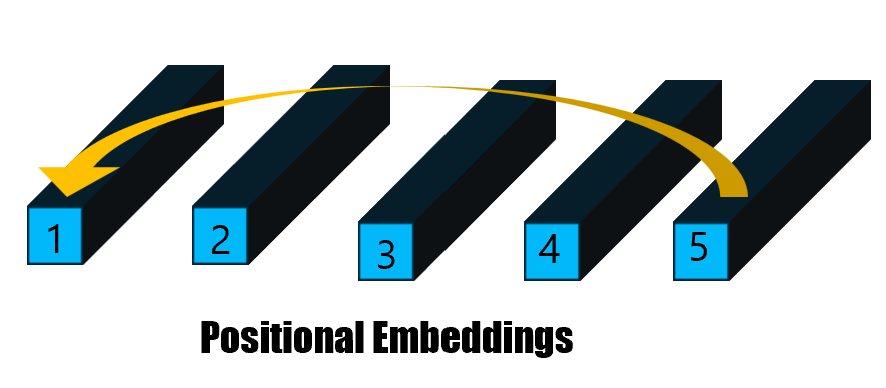
-> [1]. Positional Embedding값은 기존의 VIT에서의 Postional Embedding값을 프레임 마다 반복적으로 사용.
-> [2]. Tokenization Embedding weight(tubelet) 값은 1. Inflate 2. Central Frame Initialization
(여러 이미지의 평균 또는 이미지의 중간 값)
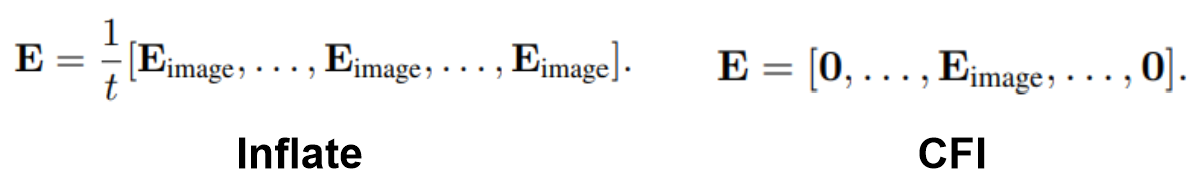
Method
1. Embedding
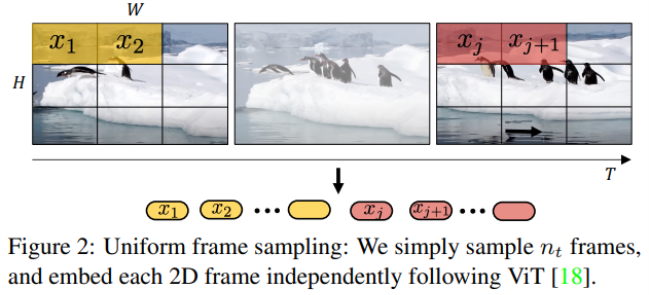
(1) Uniform frmae sampling
- VIT에 video를 입력으로 주고자 할 때 생각할 수 있는 가장 간단한 방법
- 일정시간 t마다의 프레임을 얻어 입력으로 사용
- 토큰의 수 Nt Nh Nw
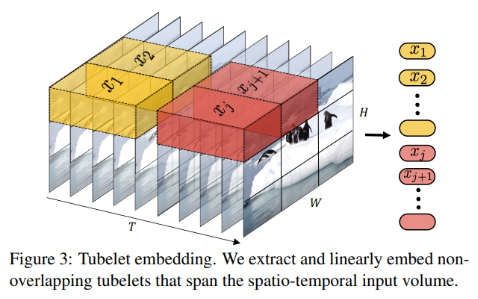
(2) Tubelet Embedding
- HxWxT의 단위로 토큰을 생성하는 방법
- 토큰의 수 N(T/t) Nh Nw
- Introducing에서 설명했듯, VIT의 임베딩 가중치를 사용하기 위해 Inflate(프레임의 평균) 또는 Central Frame Initialization(중앙 프레임) 방법을 사용한다.
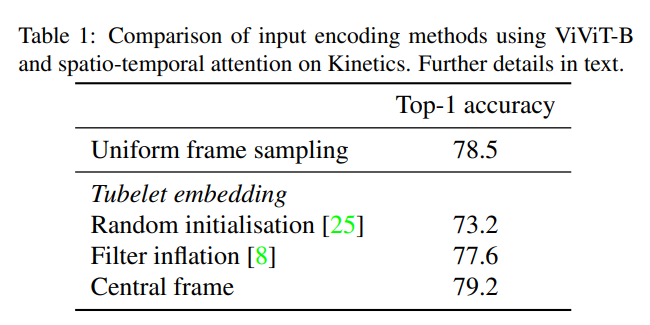
임베딩 방법 간의 성능 비교
- Spatio-temporal attention(Factorise를 적용하지 않은 구조)에 대해서 근소하게 Central frame 방법이 좋다.
- 기존 VIT의 가중치를 사용하지 않고, 학습을 from scratch부터 할 경우 성능이 떨어진다.
2. Model 비교
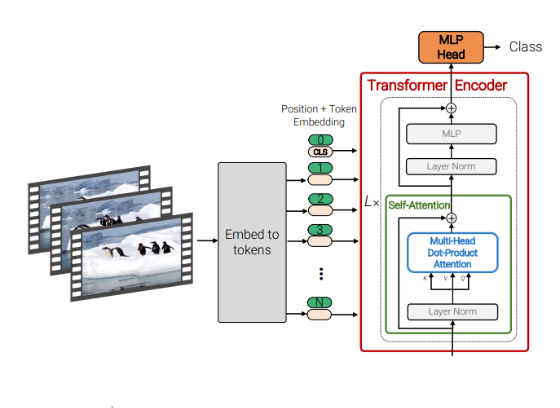
1. Spatio-temporal Attention
- 기본 VIT와 동일한 구조
- 영상에서 일정한 간격으로 토큰 생성 후 임베딩하여, 모든 토큰이 VIT의 입력으로 들어간다.
- Time Complexity : O((nt⋅nh⋅nw)^2) (t개의 이미지가 attention연산을 진행)
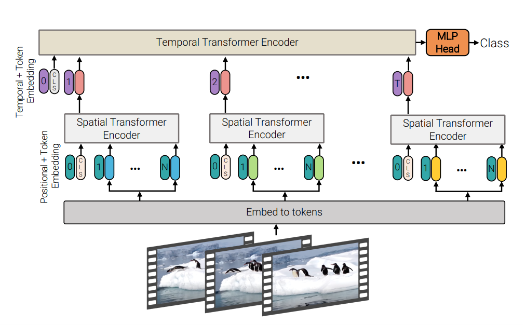
2. Factorised Encoder
- 영상 데이터에서 공간적 정보를 먼저 처리하고, 그 후에 시간적 정보를 처리하는 모델 (이러한 방식은 Late Fusion이라고 지칭)
- (1) 동일한 시간 단위 내의 프레임들을 각각의 Spatial Encoder에 입력으로 제공
- (2) 각 프레임의 정보를 대표하는 cls_s 토큰을 추출하여, 이를 Temporal Encoder의 입력으로 사용
- (3) 시간 정보를 요약하는 cls_t 토큰을 이용해 최종적으로 MLP Head를 통해 클래스를 예측
- (Model 1에 비해) 트랜스포머 레이어가 2배이고, Parameter의 개수가 더 많지만,
더 적은 계산량(Floating Point Operations per Second)을 요구한다. - Time Complexity : O((nh*nw)^2+nt^2)
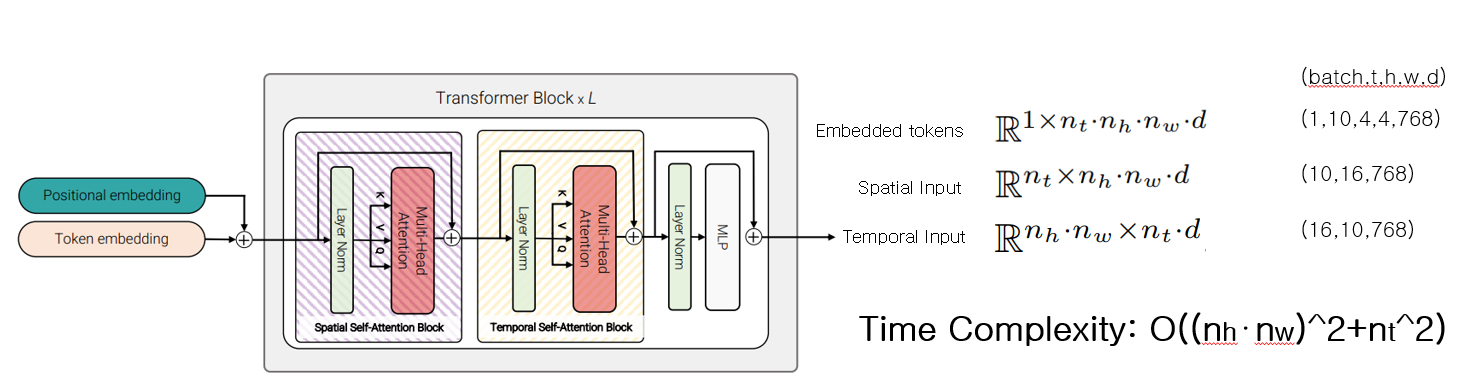
3. Factorised self-attention
- 시간 차원(t)을 배치 차원으로 permute 한 후 Attention 계산
- 공간차원(h,w)을 배치 차원으로 permute 한 후 attention 계산
- 두 순서를 바꾸어도 성능의 차이는 없다.
- reshaping으로 차원이 계속 뒤바껴 CLS토큰의 의미가 없어진다. 그래서 Average Pooling을 적용한다.
- (Model 1에 비해) 두 번의 Attention으로 인해 파라미터 수가 많으나 더 적은 계산량을 요구
- 위에서 이야기 했듯, VIVIT는 VIT의 가중치를 이용하는데, 해당 구조에서는 한 개의 Transformer블록에 두 개의 attention이 있어 문제가 된다.
이를 해결하기 위해, Spatial을 처리하는 부분은 VIT의 가중치를 사용하지만 Temporal은 사용하지 않도록 한다. - Time Complexity : O((nh*nw)^2+nt^2)
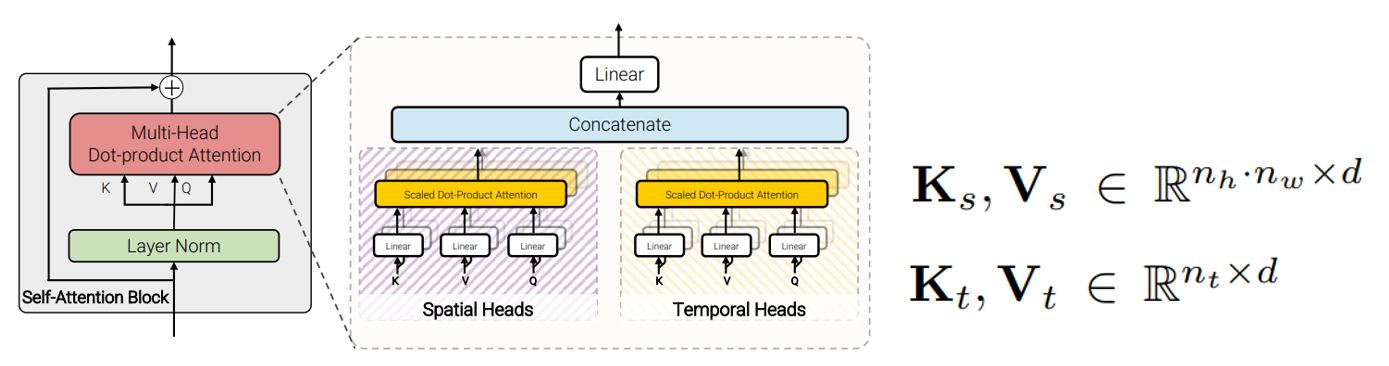
4. Factorised dot-product attention
- Q,K,V 생성 후 Self-Attention시 head를 반으로 나눠 한쪽은 Spatial만 한쪽은 Temporal만 처리
(만일 head가 12개고 차원이 768일시,Spatial, Temporal 각각 6개는
각각 128차원씩 Self attention 진행) - reshaping을 통해 변환
- Model2,3와 같은 Time Complexity를 가지고 있고, 파라미터 수는 Model 1과 동일
Experiment
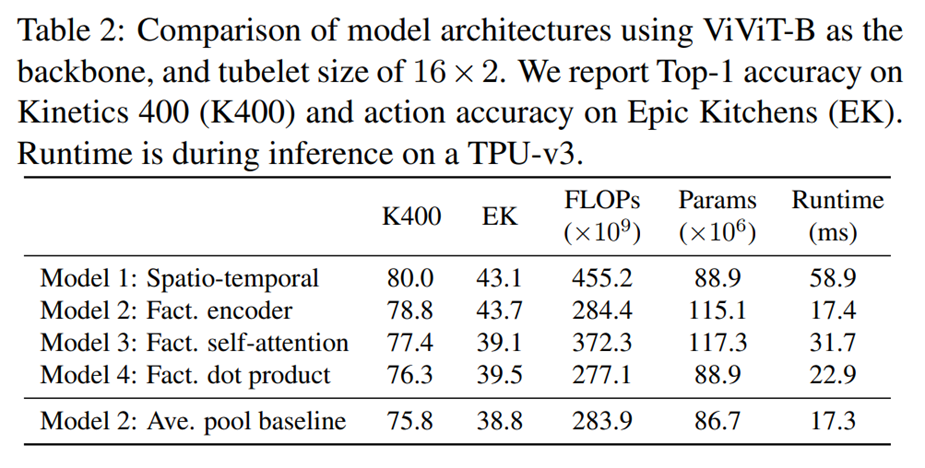
각각의 모델에 대한 성능
Model 1의 성능이 제일 좋으나, FLOPs와 실행속도가 2배 가량 느림.
전체적인 성능을 평가하면 Model 2가 가장 좋아보인다.
(맨 아래 Model 2는 CLS 토큰을 AVG Pooling으로 변환한 것)
Model 2에서 Temporal transformer의 개수에 따른 성능 차이
12개일 때 가장 좋은 성능을 보인다.


흘러가는대로 살자