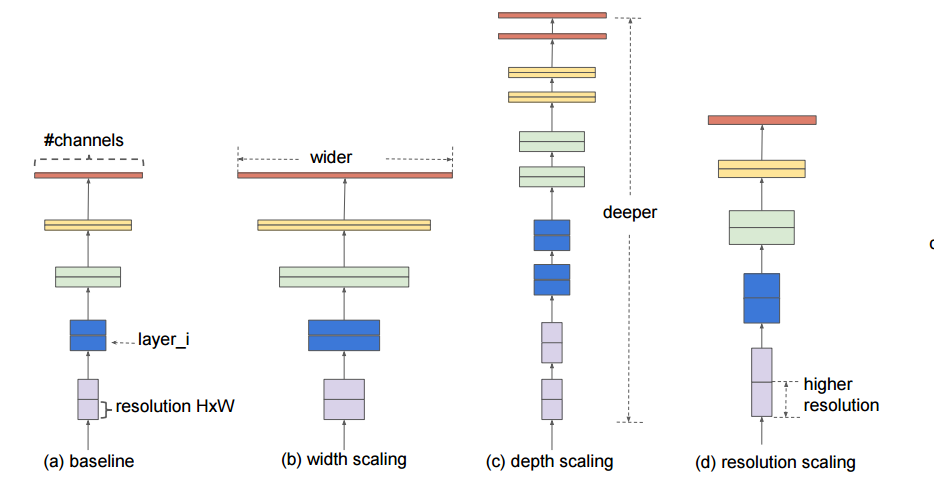
EfficientNet의 핵심적인 접근 방식은 Depth, Width, Resolution 세가지의 factor를 일종의 Grid Search 방식을 이용하여 최적값을 찾아내고 이를 기반으로 학습하는 것이다.
왜 필요한가?
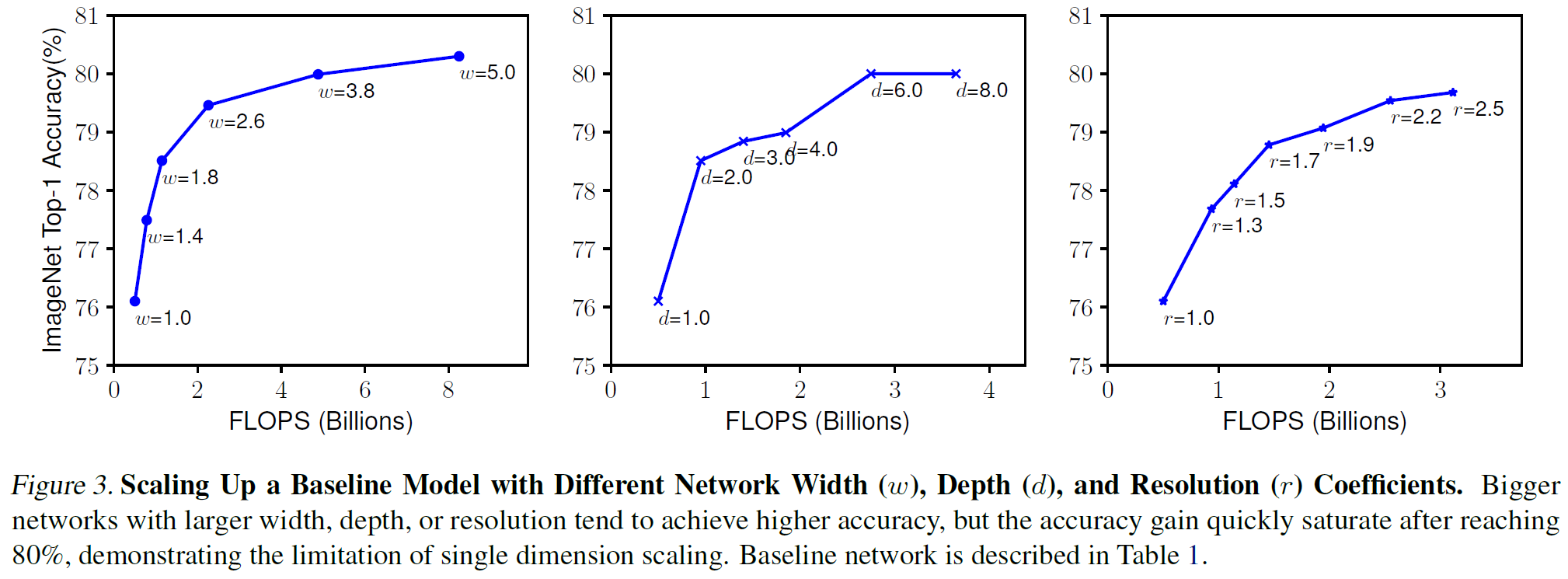
depth, width, resolution을 무한정 키울 수 있다면 좋겠지만, 연산량도 무한히 늘어날 것이고 특히 어떤 경우에는 오히려 너무 큰 값이 모델의 성능을 저해할 수 있다. 쉽게 말하면 결국 3개의 factor에 대한 가장 가성비 좋은 조합을 찾는 것이다.
Depth, Width, Resolution
-
Depth (깊이): 모델의 깊이를 조정하는 것은
신경망의 층(layer)수를 조정하는 것을 의미합니다. 깊이를 늘리면 모델이 더 복잡한 패턴을 학습할 수 있지만, 너무 많이 늘리면 오버피팅(overfitting)이 발생할 위험이 있으며, 계산 비용이 증가합니다. -
Width (너비): 모델의 너비를 조정하는 것은
각 층에서의 유닛(뉴런)의 수 또는 채널의 수를 조정하는 것을 의미합니다. 너비를 늘리면 각 층에서 더 많은 특징을 학습할 수 있지만, 마찬가지로 계산 비용이 증가하고 오버피팅의 위험이 커질 수 있습니다. -
Resolution (해상도):
입력 이미지의 해상도를 조정하는 것입니다. 해상도를 높이면 더 세밀한 정보를 모델이 학습할 수 있지만, 이미지의 크기가 커져서 처리해야 할 데이터 양이 증가하므로 계산 비용이 높아집니다.
Compound Scaling
depth, width, resolution 세개의 요소를 compound scaling 이라는 방식으로 최적화한다.

주어진 자원 하에서 최대의 accuracy 성능을 산출하는 d, w, r 파라미터 튜닝을 의미한다.
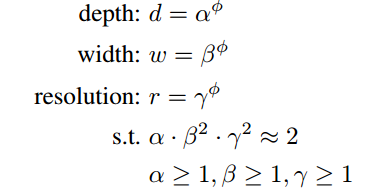
EfficientNet에서는 d,w,r에 대한 상관계수 ϕ가 존재하는데, 이 값은 연산량에 따라 조절할 수 있다. 실제로 사용할 때에는 이 값을 커스텀으로 조절하는건 아니다.
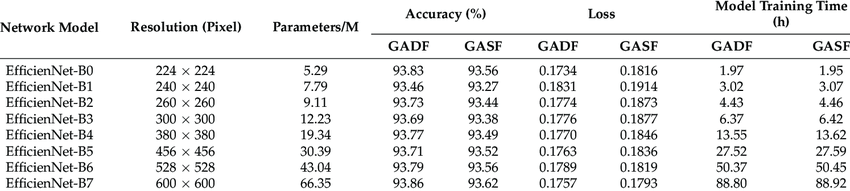
이미 ϕ를 적절히 조절해가면서 여러 모델에 대한 preset을 만들어두었다. realtime이 필요한 추론일때에는 B0를 학습하고, 반대로 처리 속도보다 정확성이 중요할때는 B7을 사용하면 된다. B7으로 갈수록 더 큰 해상도(r)를 사용할수 있고, 더 많은 파라미터(d, w)를 가지고 학습할 수 있다.
성능
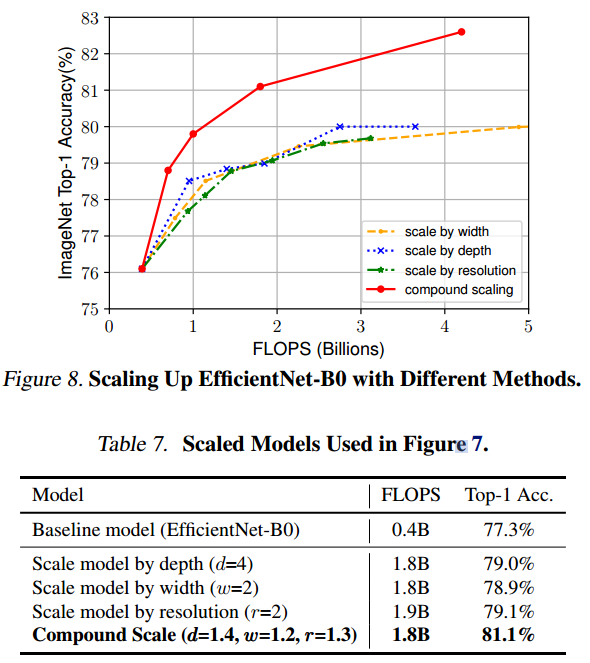
단일 factor를 바꾸는 것보다는 여러 factor를 동시에 조절하는 compound scaling이 더 효율적이라는 결과이다.