Reference
https://jins-sw.tistory.com/59
https://www.youtube.com/watch?v=t509sv5MT0w
https://www.sktenterprise.com/bizInsight/blogDetail/dev/4222
https://littlefoxdiary.tistory.com/120
필요한 이유
일반적으로 머신러닝 모델을 학습할때 가장 큰 장벽은 데이터와 학습 인프라이다. 물론 이 두가지가 없더라도 적은 데이터와 작은 크기의 모델로 학습할 수 있겠으나 당연히 원하는 성능에 도달하기도 어려울 것이다. 이를 해결하기 위해 한참전에 나온 방법이 Fine Tuning 이라고 해서 이는 모델의 핵심적인 부분(backbone)을 frozen하고 그 외 layer의 파라미터만 업데이트시키는 것을 말한다.
이 방법을 사용하면 이미 수많은 데이터와 인프라로 학습이 된 Pretrained 모델이 하나 나왔을때 수많은 기업에서 그 모델과 Weight를 가져다가 자기들의 도메인(Down Stream Task) 에서 추가 데이터로 조금만 더 학습해도 좋은 결과물이 나온다.
그런데 LLM의 경우, 다루는 모델이 너무 커서 Fine Tuning 조차도 어려워지는 상황이 발생했고 이를 극복하기 위해서 PEFT(Parameter Efficient Fine-Tuning)가 등장했으며, 여기에서 사용되는 기법 중 하나가 LoRA(Low-Rank Adaptation) 이다.
LoRA 동작 방식
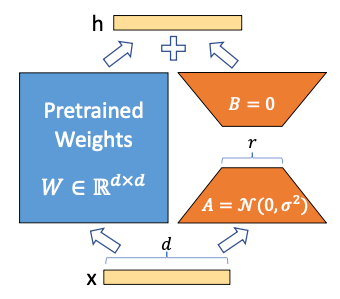
- 훈련할 때
Fine Tuning 할 때 Pre-trained Model의 Weights는 건드리지 않겠다. 이를 Weight를 Freeze한다고 합니다.
대신에 Pre-trained Model의 Weights보다 훨씬 훨씬 훨씬 작은 새로운 Weights를 옆에 붙여서 이 Weights만 훈련시키겠다. 새로 훈련된 아주 작은 Weight를 LoRA Weight라고 부릅니다.- 해석할 때
입력을 Pre-trained Model의 Weight와 LoRA Weight에 모두 통과시킵니다. 최종 결과는 Pre-trained Weight를 거친 값과 LoRA Weight를 거친 값을 적절히 섞어서 (Weighted Sum) 사용합니다.
위의 그림에서 왼쪽의 파란 상자가 Freeze 시키는 Pre-trained Model의 Weight이고, 오른쪽의 주황색 사다리꼴 두 개가 새로 훈련시킬 LoRA Weight입니다.
참고한 블로그에서 설명을 잘 해놓아서 그대로 인용하였다.
한번 더 요약하면
- 학습할 때는 Pretrained Weight는 냅두고 그보다 훨씬 작은 크기의 LoRA weight를 만들어서 얘만 학습한다는 거고,
- 추론할 때는 입력을 Pretrained, LoRA 둘 다 통과시키되 두 결과 값을 가중합한다.
이렇게 하면 학습할때 훨씬 작은 파라미터만 학습해도 되면서 동시에 추론할때는 pretrained도 같이 참조하여 처리할 수 있다.
다만 여기에서의 전제는 LoRA weight가 기존 weight에 비해 얼마나 유효하냐는 것인데..
원리
여기에서 선형대수학때 배웠던 Decomposition 개념이 등장한다.
남은 것은 Low-Rank라는 표현인데 Rank Decomposition 이라는 기법을 사용하기 때문에 붙인 이름입니다. 간단히 이야기하면 아주 큰 행렬 W를 좀 더 작은 두 개의 행렬 A와 B로 나눌 수 있다는 이론인데요 (W = A X B). 이때 행렬 A와 B가 W보다 작은 Rank를 가집니다. Rank는 행렬이 선형적으로 독립적인 column을 갖는지 표현하는 값인데, 자세한 이야기는 이 글의 취지를 벗어나기 때문에 생략하겠습니다.
이걸 수식으로 보자면
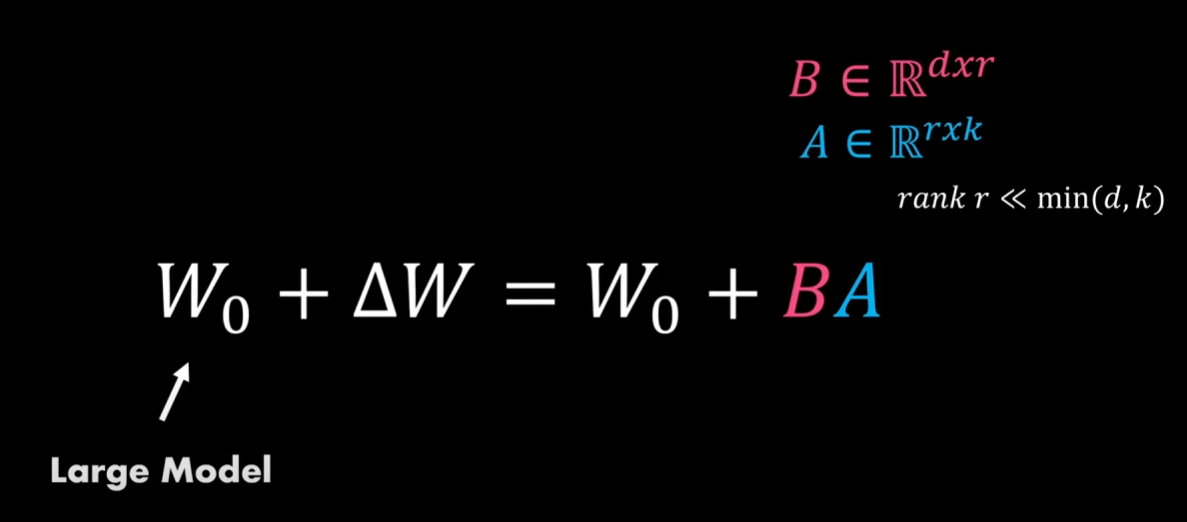
W0 + dW = W0 + BA 로 표현될 수 있는데
여기에서 위에서 설명했던 내용을 대입해보면
dW = Pretrained Weight
B x A = LoRA Weight
즉, pretrained로 학습된 weight matrix가 더 작은 matrix들로 분해가 되었고, 이를 가지고 Fine Tuning 하는 것이 LoRA 인 것이다.
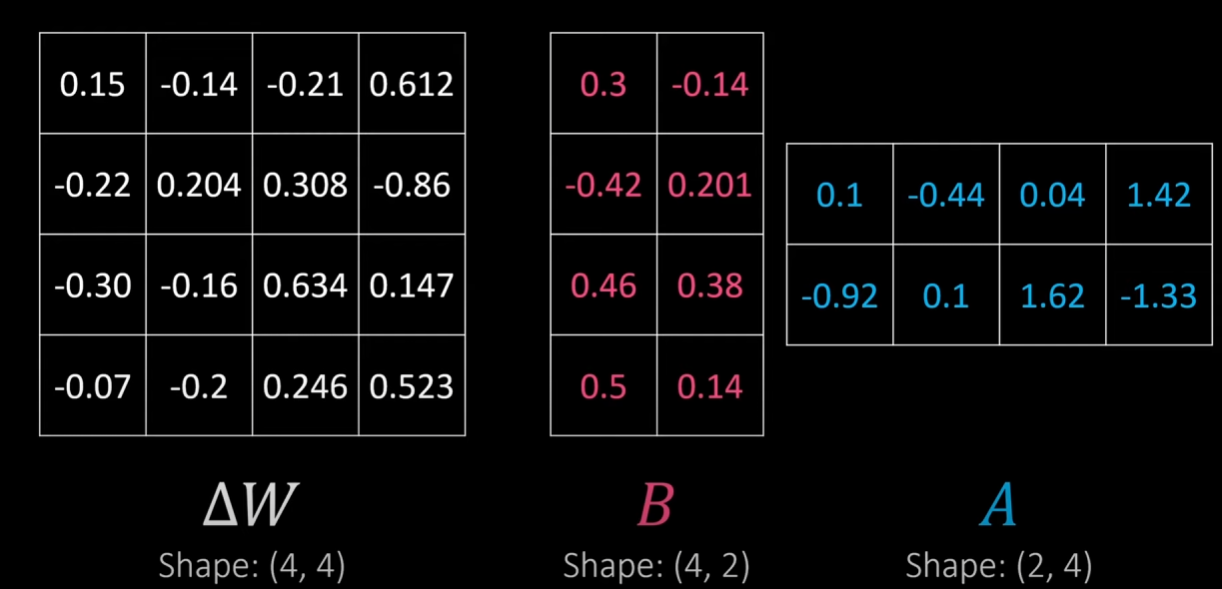
위 그림에서는 dW가 (4,4)라서 체감이 크게 되지 않지만
dW가 (500, 500) 이라면 B (500, 2) x A (2, 500) 이므로 차이가 훨씬 크게 느껴진다.
여기서 사용된 2라는 상수는 실제로는 r이라는 변수로 사용된다.
r 파라미터
LoRA Weight의 크기를 결정짓는 것은 그림에 r이라고 표현된 값입니다. Pre-trained Weight W의 차원이 500x500이라고 해보겠습니다. 그럼 내부적으로 250,000개의 값(파라미터)을 가집니다. r을 4로 했다고 해보죠. 그럼 A의 차원은 500x4 (2,000개 파라미터), B의 차원은 4x500(2,000개 파라미터)가 됩니다. A, B를 합쳐도 4,000개 파라미터입니다. r=4 일 때 LoRA Weight는 Pre-trained Weight 대비 파라미터가 1.6% (4,000 / 250,000) 뿐 입니다.
r을 2로 줄이면 훈련시킬 파라미터가 더 줄어듭니다. r이 커질수록 원래 Pre-trained Weight와 크기가 비슷해지기 때문에 성능이 올라가고, r이 작을수록 성능은 낮아집니다. 대신 r이 커질수록 LoRA Weight도 커집니다. 실제로 LoRA 훈련시에 r을 몇이로 하느냐가 중요한 실험 세팅입니다.
요약하자면 r은
dw(N, M) = B(N, r) x A(r, M) 에서의 r이다.
- r이 작아질수록 훈련시킬 파라미터도 작아지지만, 그러므로 성능은 낮아진다.
- r이 커질수록 훈련시킬 파라미터가 많아지지만, 그만큼 성능은 높아진다.
일종의 sampling rate라고 생각할 수 있다.
장점과 단점
장점
- Full Fine Tuning 대비 아주 적은 양의 파라미터만 훈련시키면서, Full Fine Tuning과 같거나 심지어 더 좋은 성능을 내기도 한다는 점입니다.
- 또다른 장점으로 Fine Tuning 한 Task 별로 전체 Weight를 관리할 필요없이 Pre-trained Model은 그대로 두고 LoRA Weight만 바꾸면 된다는 점도 있습니다.
단점
- 첫번째는 Full Fine Tuning 과 비교해서 추가적인 Weights가 들어가기 때문에 상대적으로 메모리를 더쓰고 추가적인 연산(LoRA Weight를 통과하고 나중에 Pre-trained Weight를 통과한 값과 합치기) 때문에 속도가 느려질 수 있다는 점입니다. 하지만 현실적으로는 앞에서 설명한대로 LoRA Weight가 Pre-trained Weight 대비 무시할 정도로 작은 크기이기 때문에 문제가 크지는 않습니다.
- 또다른 단점은 LoRA Weight는 Pre-trained Weight에 종속적(Adaptation)이기 때문에 Pre-trained Model의 Weight가 바뀌면 LoRA Weight도 다시 학습해야한다는 점입니다. LoRA로 훈련시킨 Fine Tuned Model 많을수록 다시 훈련시켜야할 LoRA Weight 가 많아지는 셈입니다.
학습할 파라미터가 적어서 학습 효율이 높고, Task에 따라 LoRA Weight만 갈아끼울 수 있다는 장점이 있지만,
Pretrained Weight에 종속적이라는 점이 단점인 것 같다.
어찌됐든 요즘같이 거대 모델이 등장하는 시점에서 Fine Tuning이라도 해보려면 마땅한 방법이 없으므로 여전히 좋은 선택지라고 생각한다.
효율
LoRA 논문에 따르면 GPT-2 Large Full Fine Tuning(774M 파라미터) 대비 약 0.1%의 Weight(0.77M 파라미터)만 훈련시키고도 Full Fine Tuning과 동일하거나 더 좋은 성능을 보인다고 합니다. GPT-3의 Full Fine Tuning(175B) 대비 0.0026%의 Weight(4.7M)만 훈련시켜도 동등한 수준을 얻을 수 있다고 합니다.
이런 놀라운 효과 덕에 Fine Tuning을 고려할 때 LoRA 가 첫번째 기법으로 꼽히곤 합니다. Pre-trained Model 작다면 기존의 Full Fine Tuning도 고려할 수 있지만, Full Fine Tuning과 LoRA의 성능이 같다면 굳이 Full Fine Tuning을 고집할 필요는 없겠죠.
겨우 0.1% ~ 0.0026%만 학습시켰는데도 동일한 수준이라고 한다.
파라미터 개수로 따지면 8B가 8M이 된다고 볼 수 있고, 이 말은 훨씬 낮은 performance를 가지는 GPU 환경에서도 학습 해볼 수 있다는 말이다.
Full Fine Tuning vs LoRA vs Prompt Engineering
- Full Fine Tuning: 모든 파라미터를 업데이트
- LoRA: Rank Decomposition 기반의 PEFT
- Prompt Engineering: 입력되는 문장(프롬프트)을 조정하여 모델의 출력을 원하는 방향으로 유도하는 방식
그럼 언제 Full Fine tuning을 쓰고, 언제 LoRA 같은 PEFT를 쓰고, 언제 Prompt Engineering을 사용할까요? 정답은 없지만 현재 학계, 업계의 통용되는 가이드라인을 제시해보면 이렇습니다.
- ChatGPT, GPT-4, PaLM 같이 LLM이 매우 크고 강력하다면 (어림잡아 70B 이상),
Prompt Engineering을 먼저 시도해보는 것이 좋습니다. 부담없고 값싼 방법입니까요. zero-shot을 시도해보고, 잘 안 되면 few-shot도 시도해봅니다.
그래도 잘 안 된다면 LoRA 같은 PEFT를 시도해봅니다.
현실적으로 이 정도 크기의 모델을 Full Fine Tuning 하는 것은 매우 어렵습니다.- 모델이 상대적으로 작다면 (7B ~ 30B급)
Zero-shot은 작동하지 않은 가능성이 매우 큽니다.
Task에 따라 다르기는 하지만 솔직히 few-shot도 가능성이 높지는 않습니다. 그래도 비싼 노력은 아니니 시도해볼만 합니다.
LoRA가 효과가 가장 좋습니다. 7B라고 하더라도 Full Fine Tuing을 하기에는 여전히 큽니다.- 모델이 작은 경우 (2B 이하)
few-shot도 안 될 가능성이 매우 큽니다.
Pre-trained Model의 성능이 상대적으로 낮기 때문에 Fine Tuning에 많이 의지해야합니다.
이 정도 크기면 요즘 좋은 GPU에서는 굳이 LoRA를 쓰지 않고 Full Fine Tuning을 해볼 수 있습니다.
물론 LoRA는 언제나 Full Fine Tuning 대비 저렴하기 때문에 시도해볼만한 가치가 있습니다.
앞에 말씀드린대로 정답은 없고 Pre-trained Model, Task, 가지고 있는 데이터에 따라 달라지기 때문에 상황에 맞는 엔지니어링이 필요합니다.
요약하자면,
Billion급 모델에서는 zero shot, few shot 등의 prompt engineering 먼저 시도해보고, 그 다음 LoRA를 시도해보자.
모델이 Billion급보다 충분히 작다면 Full fine tuning도 시도해볼 수는 있다고 한다.
다만 요즘에는 Billion보다 훨씬 작은 모델에서도 꼭 PEFT가 아니더라도 Pretrained를 대체로 사용하는 경향이므로 웬만해서는 scratch로 밑바닥부터 학습하는 경우는 거의 없는 듯하다.