학습주제
SQL
데이터베이스
다음: RedShift 실습
학습내용


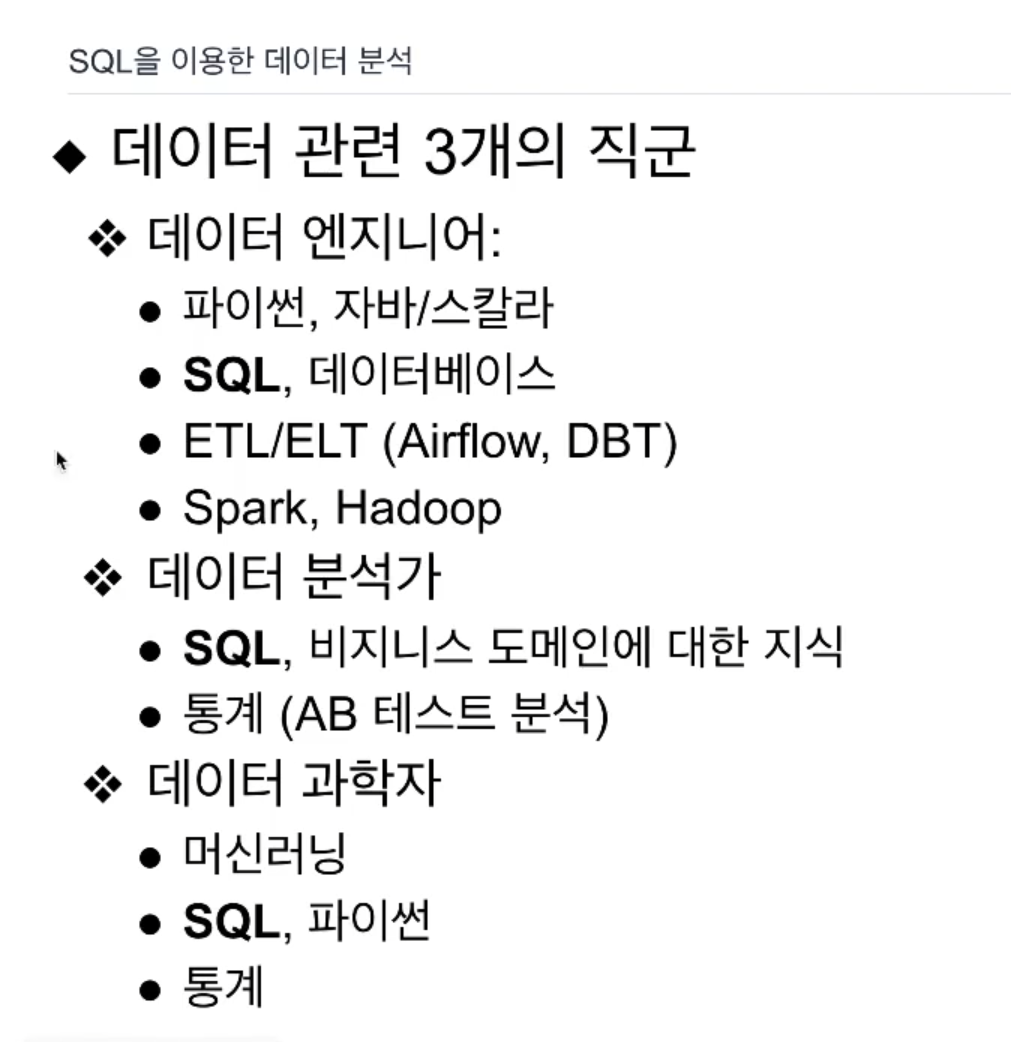
대용량 분산환경을 이용한 데이터 처리를 할 일들이 있을땐, Spark, Hadoop
결국 데이터 엔지니어는 데이터웨어하우스를 관리하는 사람이기도 함
SQL을 알아야 관리를 할 수 있음. 매우 중요한 스킬 셋
데이터 분석가도 SQL없이는 분석을 할 수 없음.
나머지 직군도 SQL 없이는 자기 일을 제대로 수행할 수 없음.
데이터 분석가 - 통계.
데이터 과학자 - 모델링 하는 사람.
training set, feature 할 때도 SQL을 필요로 함.
과학자들도 코딩할 줄 알아야 남의 도움 없이 혼자 작업할 수 있음.
수학적 지식보다 통계적 지식이 더 도움이 됨.
front, backend의 데이터베이스의 경우, 사용자들의 행동에 관한 정보, 상품 정보 등을 빠르게 저장하고 빠르게 읽어서 웹, 모바일 앱을 운영하기 위한 목적으로 사용됨.
SQL은 관계형 데이터베이스에서 다 사용되긴 하지만, 데이터 직군에선 큰 데이터를 작은데이터로 요약되고 이를 분석하기 위해 사용됨.

이를 언급하는 이유는 이쪽 도메인에 익숙하지 않은 경우 배움에 있어서 어려움이 있을 수 있음. 경력 단절, 커리에 전환, 오랬동안 쉰 경우 사람들과 소통한 결과를 분석하심.
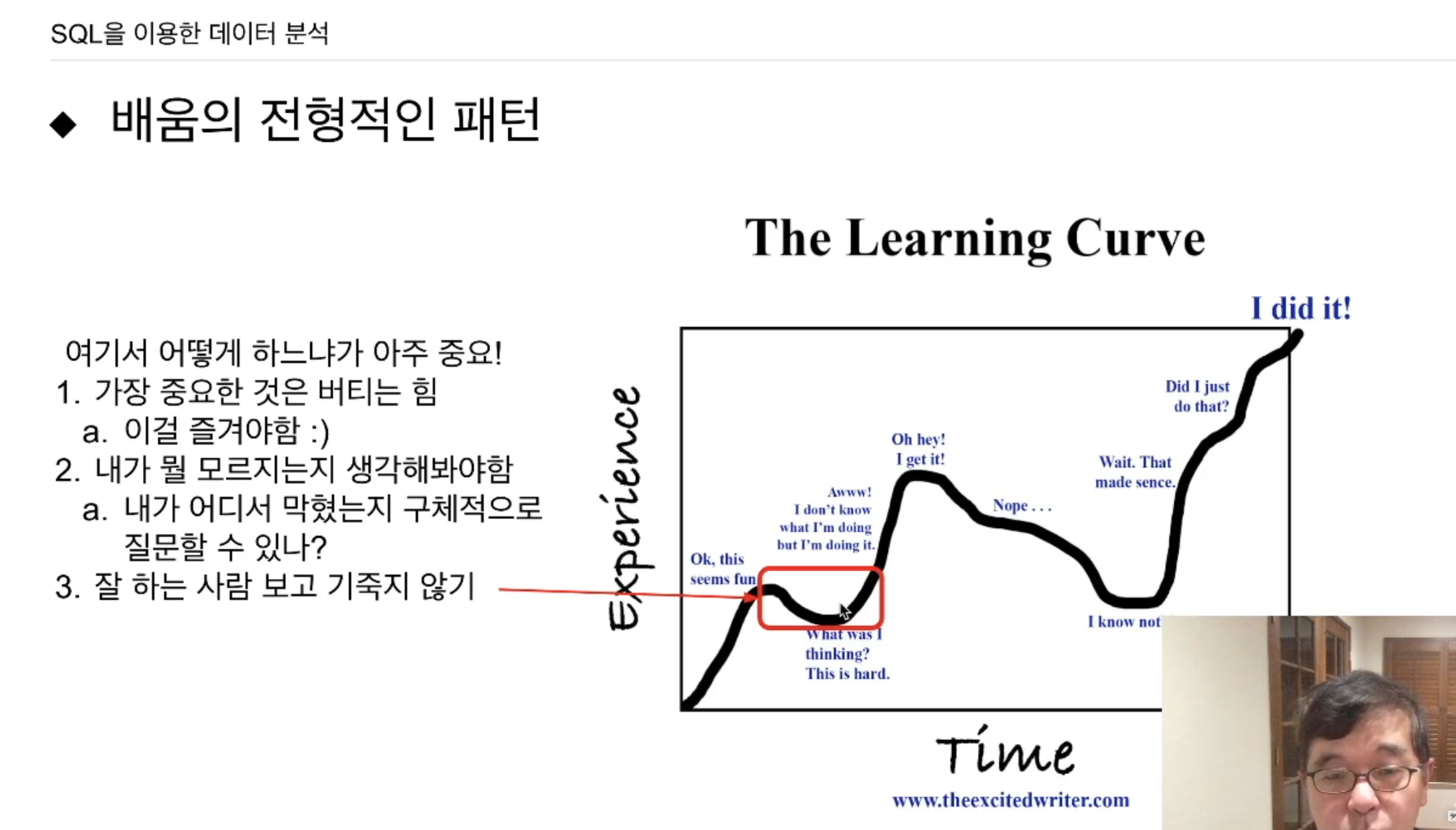
세상에 직선으로 발전하는 경우는 잘 없음. UP and DOWN이 발생함. 사람들이 주제에 대해 숙련되는데, 이러한 그래프를 보임.
- 처음 리니어하게 발전한다.
- 어느순간 정체기가 옴. 이 정체기를 어떻게 극복하느냐에 따라 이 길을 갈지 말지 결정됨.
정체기가 오는 것은 매우 자연스러움.
이 정체기 때 어떻게 극복하느냐가 제일 중요하다고 생각됨.
적어도 3달정도는 full time으로 매달려보고 안되면 다른 길로 돌아서도 됨. 하루에 8시간 이상씩 심도있게 파고들어 본 다음, 그래도 배움이 없다고 생각되면 돌려도 됨.
막혔다고 생각되었을 때 계속 스스로 물어봐야함. 처음에는 그조차도 어려움. 내가 뭘 모르는지도 모르기 때문. 그래도 계속 자문해봐야함. 그러다보면 내가 뭘 모르는 지 인식을 할 수 있음. 보통은 내가 가정을 잘 못하고 있기 때문에 발생하기에 내가 어떤 가정을 했는지 되짚어보는 것이 좋음.
자문 - 자답 -> 구체화
잘 하는 사람보고 기죽지 않기 (중요)
보면 아, 나는 멀었구나. 나는 뭘까. 이런 자존감이 떨어지는 문제로 연결되기 때문. 어떻게 바라봐야 할까? 그 사람은 나보다 더 많은 시간을 투여를 했고, 관련분야에 대한 경험이 있거나, 직간접적인 경험이 있는 사람이라고 할 수 있음. 아무리 머리가 좋더라도 하루아침에 어떤 topic에 대해 잘 알 수가 없음.

드는 생각. 전에 배웠던 알고리즘, 장고 등을 다시 복습해보면서 확인해보면 좋겠다.
내가 이런 질문을 해도 되나? 이런 자기검열을 자제.
나보다 잘하는 사람은 그만큼 직간접적인 시간을 쏟았기 때문. 비교는 어제의 나와만.
정체기를 지나면 어느순간 폭발적으로 성장하는 시기가 옴.

한번 내가 이런 좋은 경험을 해봤기 때문에 그 이후 공부는 편해짐.
처음 하는것은 다 어려움. 내가 못났다 생각하며 남들과 비교하지 말고, 계속 자신에게 자문, 자답을 하면서 구체적으로 알아내고 깊게 들어갈 수 있는 process를 만드는 것이 매우 중요.

일종의 스토리지. 비 구조화된 데이터는 저장 X. 강점과 약점이 되기도 함.
데이터 분석관점에서 대부분 분석할 데이터는 구조화된 데이터. 가장 좋은 기술이 되기도 함.
관계형 데이터베이스에 저장된 데이터에 질의, 구조화 = SQL
데이터만 구조화되어 있다고 하면 데이터 분석에 있어서 좋은 기술임.
빅데이터가 뜨면서 SQL의 세상이 지고 있다는 말이 있었으나, 다시 SQL은 살아남. SQL은 데이터가 구조화되어 있다고 하면 쉽게 쓸수 있고 오랜시간 검증된 기술이기 떄문.
아직까지 이정도로 구조화되고 사용하기 쉬운 검증된 기술이 없음.
데이터 일을 하는 사람들은 꼭 알아야 할 언어.

User 테이블 예시.
사람의 이름에 해당되는 Column(char type), 생년월일(date type). 테이블 스키마라고 함. 스키마 -> 컬럼 이름, 타입은 뭔지.
그 스키마에 맞춘 레코드들이 입력됨.
추가로 구매 테이블이 생성될 수 있음. 사용자가 어떤 물건을 샀고, 할인은 있었는지, 방법은 무었이었는지.
스키마를 정한다 -> 컬럼의 이름과 타입을 정의함.
레코드 추가 -> 스키마를 준수한 데이터 입력
텍스트 같은 경우 구조화되어 있지 않아, parsing해야함. 이미지, 비디오 등등.
테이블 스키마를 정의하는 DDL
CREATE, ALTER, DROP TABLE 등
앞서 정의된 테이블 스키마에 맞춰 테이블 레코드들이 들어가 있다고 할 때, 조건에 맞는 레코드들을 읽어오고, 새로온 레코드들을 추가하고 삭제, JOIN 조건으로 merge 등을 사용하는 DML
SELECT, UPDATE, DELETE
데이터 과학자, 데이터 분석을 하는 관점에서 SQL를 배워본다.

프로덕션 데이터베이스는 빠른 응답속도. 웹, 앱서비스에 연동되어 사용. 빠른 응답을 못해주면 사람들이 오래 기다리게 됨. front, back-end가 사용
- 새로운 사용자가 등록 될 때
- 구매 이력을 보고싶을 때
- 어떤 물건을 구매했을 때
데이터 웨어하우스. 우리가 중점적으로 배울 지점.
처리 데이터의 크기가 큼. 빠른 속도는 그렇게 중요하지 않음. 가능한 처리 데이터의 크기가 중요. front, back-end와 관계가 없음.
프로덕션 데이터베이스에 있는 데이터를 데이터 웨어하우스로 주기적으로 옮겨줘야 함.
만일 프로덕션 데이터베이스만 있는 회사에 들어왔을 때. (보통 초창기 스타트업) 원하는 데이터를 뽑을려면 프로덕션 데이터베이스에 SQL 쿼리를 날리게 됨. 만일 데이터가 큰 쿼리를 날리게 되면 서비스에 영향을 주게 됨. 그럼 백엔드 개발자들이 기분이 안좋음. 사람이 실수를 안할 수는 없음. 계산, 시간이 오래 걸리는 쿼리를 날릴 수도 있음. 사고로 이어지면 -> 백엔드가 이제 프로덕션 데이터베이스 쓰지 말라고 함. 그래서 별도의 데이터 웨어하우스가 필요함. 회사의 서비스로 쓰는 데이터베이스와 별개로 사용되는 데이터베이스임.
나중에 취업할 때, RedShift 등 이런 데이터 웨어하우스를 기술스택으로 갖고 있는지 물어보고 없으면 고생할 확률이 높음. 처리가 오래 걸리는 쿼리를 날리면 front, back-end와의 불화를 야기할 수 있음.
다음주 Spark 강의와도 연동해서 사용 예정.

테이블 수가 몇천개가 넘어가면 테이블 이름만 놓고 관리하려면 힘들어짐.
데이터베이스라고 폴더 형태로 관리하기 시작.
폴더 아래에 테이블들을 놓음. 사용자는 폴더 이름만 보고 알 수 있게 함. 이게 2단계 구조.
이번 실습에서 데이터베이스를 스키마라고 부름. MySQL은 데이터베이스라고 부름.
테이블들을 flat하게 관리하는게 아니라 폴더 내에 넣어서 관리한다.
폴더 이름을 보고 어떤 데이터가 저장되어 있을 지 추측케함.

스키마를 보면 테이블의 구조를 할 수 있음.
속성: Primary Key
Primary Key로 지정된 컬럼은 유일해야 함. 동일한 값을 갖는 레코드가 1개만 존재. 보통 동일한 값이 들어가면 reject하게 됨. 그러나 데이터 웨어하우스에선 그러한 기능을 지원하지는 않음 (추후 기술)

데이터들을 조작할 수 있는 프로그래밍 언어: SQL

시간이 오래되어 유용성이 검증된 언어.
DDL로 정의된 테이블을 DML로 레코드를 CRUD해줌.

2000년 하둡이 등장하면서 SQL 시대가 끝났다라고 생각했더 때도 있었음. 그러나 SQL은 데이터의 크기에 상관 없이 사용할 수 있게 함. 대용량 데이터 웨어하우스도 결국 관계형 데이터베이스라는 소리. Spark은 pandas의 데이터 조작도 가능. sparkstream, graph 형태도 조작 가능. 다음주에 배울 예정.
기타 SparkSQL, Hive도 SQL에서 파생된 언어.

중첩 구조(nested structure)란 구조 안에 다른 구조가 포함된 구조를 의미합니다. 이는 트리(tree) 구조나 리스트(list) 구조에서 자주 사용됩니다. 예를 들어, 트리 구조에서 각 노드는 자식 노드를 가지고 있으며, 자식 노드 또한 자식 노드를 가질 수 있습니다. 이처럼 구조 안에 더 작은 구조가 중첩되어 있는 것을 중첩 구조라고 합니다. 이러한 중첩 구조는 데이터를 표현하거나 프로그래밍에서 자주 사용됩니다.
{
"name": "John",
"age": 30,
"address": {
"street": "123 Main St",
"city": "New York",
"state": "NY"
},
"phoneNumbers": [
{
"type": "home",
"number": "555-1234"
},
{
"type": "work",
"number": "555-5678"
}
]
}address 안에 street, city, state 필드가 들어가 있음.
구조화된 경우가 JSON 처럼 필드 안에 필드가 존재하는걸 읽는 데이터베이스는 많이 않음. 빅쿼리는 지원.
Spark이 비구조화된 데이터를 잘 처리해줌.
관계형 데이터베이스마다 SQL 문법이 조금씩 다름. 한국어로 치면 일종의 사투리. 소통은 되지만 어떤 때는 문법을 좀 바꿔줘야함.
프로덕션 DB, 데이터 웨어하우스와의 차이.
데이터를 어떻게 표현할 것인가. - 데이터 모델링 방법론.
가상의 매출데이터를 가지고 정의해본다.
매출 데이터 자체를 보면, 기간, 매장, 제품, 직원, 매출단가, 매출수량, 총매출액이 보인다.
이런 정보들을 한 테이블에 다갖다 집어넣으면
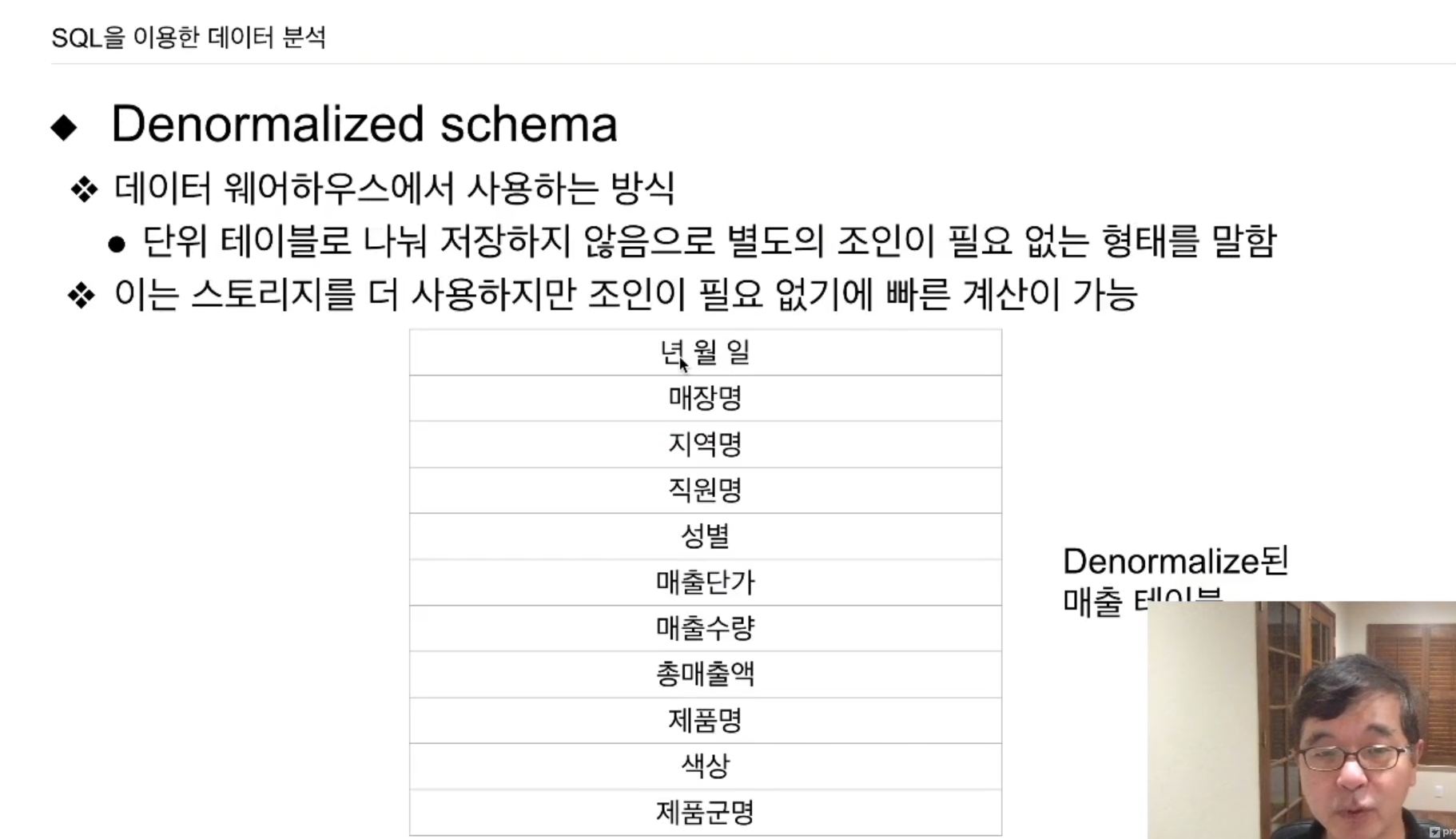
이를 디노멀라이즈드 스키마라함.
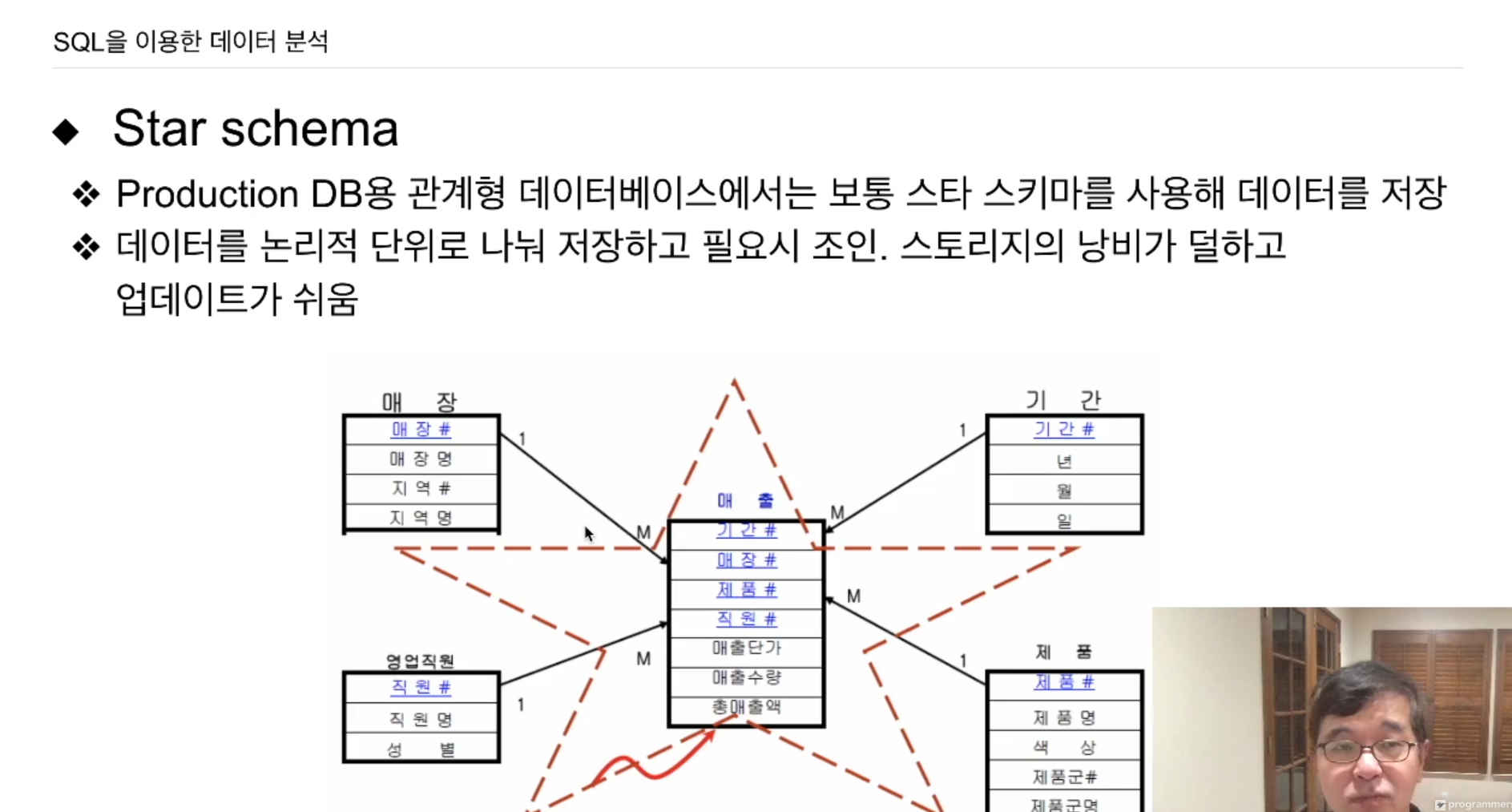
스타스키마의 경우 흔히 디멘션이라하는데, 기간에 대한 정보, 매장에 대한 정보 등을 별도의 테이블로 빼버림. 이에 매장, 기간, 제품 테이블이 생성되고 매장번호, 기간번호, 제품번호가 붙음.
매출테이블에서는 예를들어 매장에 대한 세부적인 정보를 들어있지 않으나 매장번호를 갖고 있음. 또한 기간번호, 직원번호 등을 가짐.
어떤 매출을 일으킨 직원을 알고싶으면 직원번호를 읽고 영업직원 테이블로 넘어가 그 직원번호를 가지는 레코드를 검색함. (JOIN)
ID를 가지고 접근한다는 것을 알 수 있다. 어떤 정보를 한 테이블에 다 갖다 넣는게 아닌 어느 논리적인 단위를 갖지고 별도의 테이블들을 생성해서 LINK 를 검.
이를 Star schema라 한다.
보통 프로덕션 DB에서 많이 사용. 스토리지의 낭비가 덜하고 업데이트가 쉬움. 대신 수많은 Join 연산을 사용해야함. 키를 가지고 매핑을 함. 시간이 더 걸리게 되어 있음. 테이블을 로딩하고 매칭하는 과정에서 시간, 리소스가 소요.
디노멀라이즈드 스키마의 경우 매장명 1개를 바꾸려면 모든 레코드를 탐색해야함. Join 사용하지 않음. 속도가 빨라짐. 단점은 모든 작업이 반복되어 있기 때문에 스토리지가 많이 필요해짐. - 데이터 웨어하우스에 적합한 방식. 스토리지 크기에 구애받지 않고, 직접 업데이트 할 일이 없음.
데이터 일을 하다보면 Star schema, Denormalized schema를 많이 듣게 됨.
