학습주제
데이터 웨어하우스
학습내용
관계형 데이터베이스를 조작하는 SQL에 대해 배웠다.

데이터 웨어하우스에 대해 좀 더 알아보기로 한다.

여전히 SQL 기반 관계형 데이터베이스
그러나 프로덕션 데이터베이스와는 별도여야함.
프로덕션 데이터베이스에 분석과 관련된 쿼리를 날리다보면 사고가 나고, 이는 서비스의 불안정성, 서비스 중단과도 연관.
별도의 데이터베이스를 만들게 됨.
프로덕션 데이터베이스를 데이터 웨어하우스로 가져오게 됨. 마음놓고 쿼리를 날릴 수 있음. 데이터웨어하우스(OLAP), 프로덕션 데이터베이스(OLTP).
이메일을 어떤 정보를 날렸는지 데이터베이스.
광고에 관련된 정보를 갖는 데이터베이스.
서포트팀이 있어서 사용자들의 불만사항을 저장한 데이터베이스.
데이터베이스는 모여있을 때 힘을 발휘하게 됨.
데이터 웨어하우스에 가게 되면 내가 원하는 정보가 테이블로 존재하고 있음.
데이터 웨어하우스 - OLAP
프로덕션 데이터베이스 - OLTP
이번엔 AWS Redshift를 사용할 예정. 그러나 Google Cloud의 Big Query, Snowflake이 훨씬 더 스케일러블하고 좋은 웨어하우스임. 나중에 회사에 데이터 웨어하우스를 결정해야 할 때는 Big Query, Snowflake 둘 중 하나를 우선고려.
Redshift는 고정비용 옵션.
Big Query, Snowflake는 가변비용 옵션.
장단점이 있음.
고정비용: 비용관리 예상이 쉬움.
가변비용: 갑자기 비용이 올라갈 수 있는 소지가 있음.
이를 고려해도 가변비용이 훨씬 좋음. 안쓸때는 돈을 안내도 됨.
Redshift는 초반에 쉽긴 함. 사용법 자체에선 큰 차이는 없음. SQL 문법, 내용들이 유사함.
내부 직원을 위한 데이터베이스다보니 처리속도가 그렇게 중요하지 않음. 단 데이터의 크기가 더 중요한 고려요소.
만약 회사에서 Redshift를 기술로 채택했다고 가정. 누군가는 2단계 구조 (폴더 - 테이블)를 만들어 줘야함.
이러한 과정을 ETL, 또는 데이터 파이프라인이라고 함.
외부에 존재하는 데이터를 읽어다가 데이터 웨어하우스의 테이블로 저장해줌.
ETL = Extract Transform Load
외부의 데이터를 추출, 내가 원하는 포맷으로 변환, 그런 데이터를 데이터 웨어하우스에 저장. 이를 통틀어 데이터 인프라라고도 함.
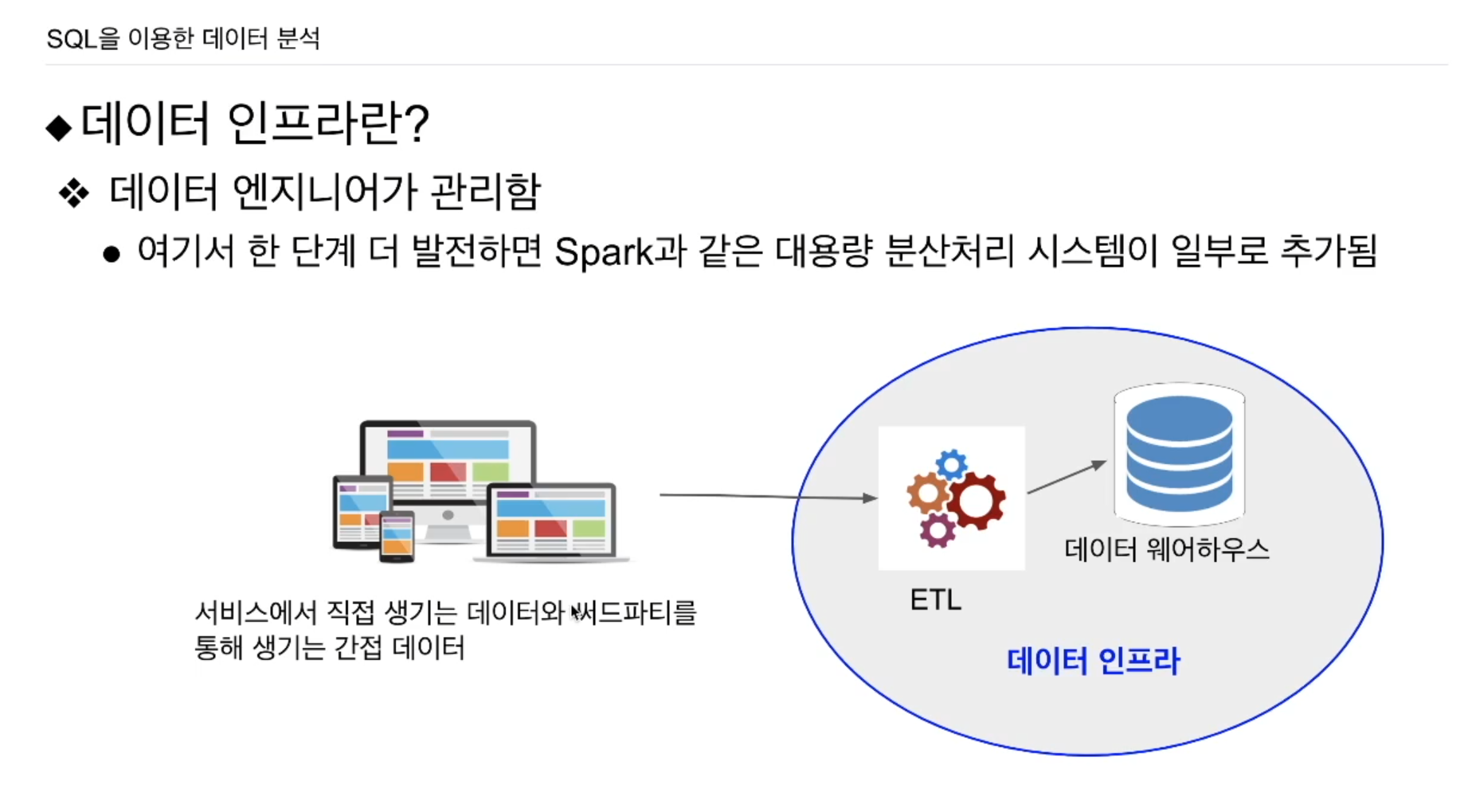
많은 수의 ETL들이 존재함. ETL은 결국 코드임. 처음은 저정도로 충분함. 이후 시스템이 발전하게 되면, 비구조화된 데이터도 많이 생기게됨. 이를 프로세싱하기 위한 Spark가 데이터 인프라에 추가됨.
데이터팀에 있어서 데이터 인프라 구축이 첫 단계
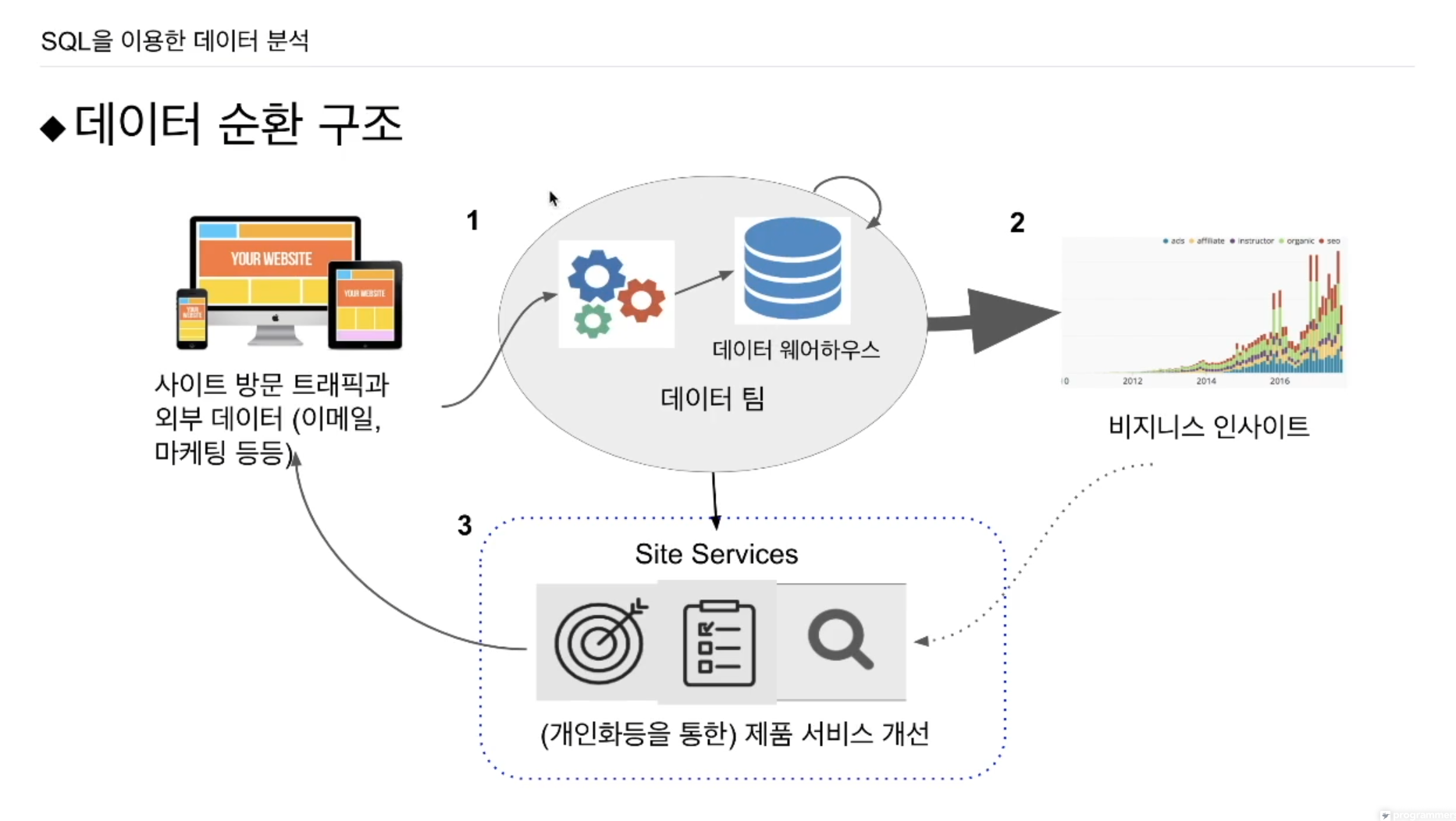
데이터들을 가지고 통합을 해서 일종의 서머리 테이블을 생성. 이를 가지고 시각화를 하게 됨. 다양한 종류의 데이터 분석에 사용. -> 데이터팀의 발전단계 2단계 (데이터 분석가들이 함). 데이터 분석가는 SQL, 통계지식을 갖고 접근.
3단계인 데이터과학자들이 들어와 머신러닝, 딥러닝 형태로 발전을 시킴. 예를 들어 추천을 개인화, 회사의 프로세스를 데이터기반으로 모델링하여 최적화.


하드웨어, 소프트웨어 모두를 지칭함.
미리 구성된 서버를 사용하고 돈을 지불함. 요즘은 소프트웨어를 그런 형식으로 사용함.
클라우드 업체에서 MySQL를 설치해놓음. 나는 그 맞는 사양을 적고 버튼만 누르면 내가 원하는 MySQL 서버가 런치됨.
-
No Provisioning: 준비할 필요가 없다. 내가 원하는 사양을 입력만하면 바로 클라우드로 제공
-
Pay As You GO: 쓴만큼 지불한다. 예전엔 내가 필요한 만큼의 자원을 예측하여 서버를 구성하였음. 이렇게 되면 내 사업이 안좋아지게 되면 서버는 무용해지는 점을 극복함. 이젠 초기투자가 필요가 없음.
-
탄력적으로 자원을 유지해야한다. 그렇게 코드를 짜는게 쉽지가 않음. 클라우드 업체 통해서 하드웨어, 소프트웨어 구성해놨다가 할당해서 사용하다가 필요없어질 때 반환해야하는데 보통 까먹음. 탄력적으로 운영하는게 힘들기 때문에 필요 이상으로 자원을 할당했을 경우가 많음 -> 클라우드 비용이 비싸다.

물리적으로 구성하는게 정말 쉽지 않음. peak time (블랙프라이데이, 특수 할인기간) 때와 traffic이 가장 낮을 때를 비교하면 100배이상 자원 사용 차이가 남. 그렇다보니 직접 운영비용이 생각보다 많이 들어감.
새로운 프로젝트를 해야되는데, 서버를 구축해야한다면 위와 같은 과정을 거쳤어야 함. 3달정도 소요됨.
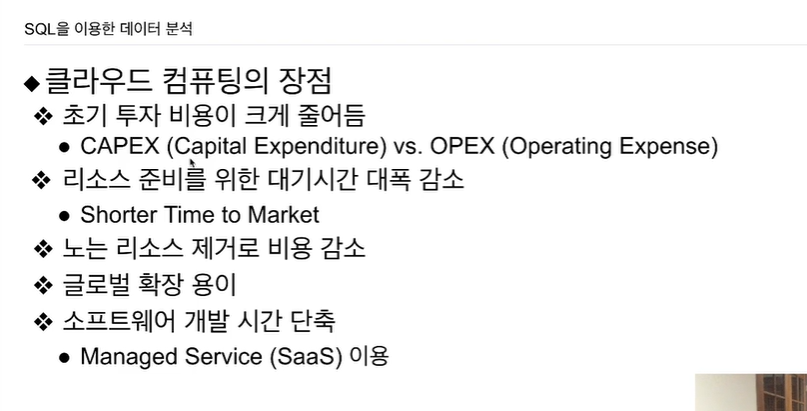
- CAPEX: 초기투자비용
- OPEX: 운영비용
재무팀은 클라우드 컴퓨팅을 부담스러워함. CAPEX에 익숙함. 클라우드컴퓨팅 모델은 OPEX임. 재무팀에선 이를 예상하기가 힘듦. 반대가 나옴.
기회비용 측면에서 이점 발생 -> 리소스 준비 대기시간 감소
노는 리소스 제거. 그러나 코드 관심 없으면 그대로 놀게됨.
전세계의 데이터 센터를 갖기 때문에 글로벌 확장 용이.
다양한 소프트웨어를 set의 형태로 제공함. 직접 만들필요 없음.

블랙프라이데이, 사이버 먼데이에 Capacity를 맞추는데 놀때에 비해 100배 차이가 남. 남아프리카공화국 엔지니어 제안. 노는 서버를 시간당 돈받고 내주면 어떨까? 아마존에서 가장 이익을 내는 서비스가 됨.
ML/AI도 end-to-end로 서비스 제공.
넷플릭스는 99% 서버, 소프트웨어를 AWS 위에서 돌림.
AWS가 서울에도 들어옴.
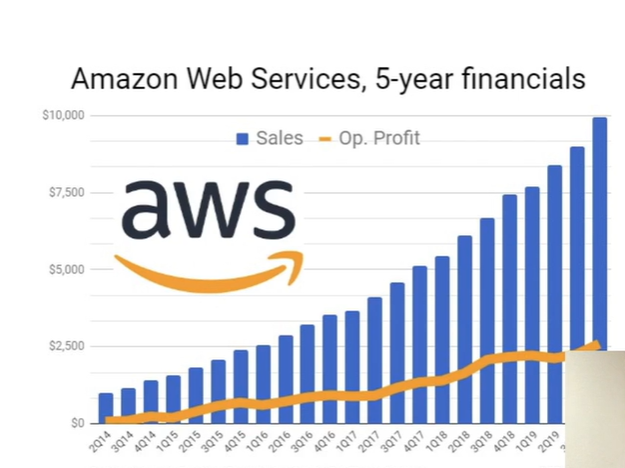
azure, googld cloud가 쫒가가는 순.

다양한 사양한 서버를 다양한 운영체제에 대해 지원. 요즘은 애플의 맥 운영체제까지 지원
EC2
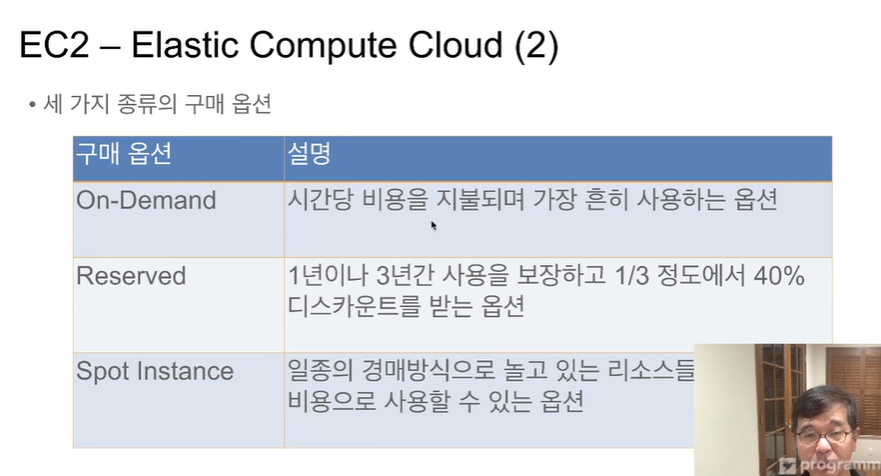
보통 처음에 On-Demand로 감. 그 이후 Reserved 고민.
Spot Instance: 아마존의 놀고있는 서버를 경매 방식으로 제공. On-Demand보다 조금 싸게. 그러나 조금 더 높은 가격을 부르면, 부른 업체에게 넘어감. 그러니 이 서버가 항상 가동되지 않아도 괜찮은 연산을 수행시 적합.

톱레벨 폴더를 버킷이라고 함. 그 밑에 서브 폴더, 파일, 디렉토리 업로드. 버킷별로 permission
1테라에 2만 5천원.
Infrequent Access storage: 0.1%의 잃을 확률. 위의 반값
Glacier storage: 테잎같은 형태. access 하는데 엄청나게 오래걸림.

관계형 데이터베이스를 서비스형태로 제공.
Redshift - 데이터 웨어하우스
AWS 콘솔을 통해 런치할 예정.

- SageMaker: 딥러닝, 머신러닝을 통해서 모델을 만들고 모델을 테스팅하고 모델을 최종적으로 API 형태로 deploy 자동화 해주는 프레임워크.
모델을 만들기 위한 4가지 과정.
- 어떤 문제를 해결할 것인지 가설 세우기.
- 그 가설에 기반한 Training set 수집
- 어떤 머신러닝 알고리즘 선택. 초매개변수 선택. cross validation, 훈련, 평가 데이터 나눔.
- 이 모델을 production 형태로 api로 제공.
SageMaker는 3, 4번째를 자동화해줌. AWS만 있는게 아니라 다른 회사도 머신러닝 프레임워크 제공함.
- Lex: 챗봇 서비스.
- Polly: 텍스트를 주면 음성으로 바꿔주는 서비스
- Rekognition: 이미지를 인식하는데 사용하는 서비스

알렉사: 보이스봇 플랫폼. 다양한 API 플러깅 같은데 지원. 나만의 음성인식하고, 그에 맞춘 특정 기능을 추가할 수 있음.
Connect : 콜센터 솔루션. Contact center
Lambda: API만들려면 EC2로 서버 론칭, 어떤 API를 구동할 수 있는 프레임워크를 만들어야 했는데, API 자체의 로직만 특정 언어로 만들면 바깥에 노출시키고 노출 빈도를 아마존에서 알아서 조절해줌. 다른 회사도 존재. serverless computing.
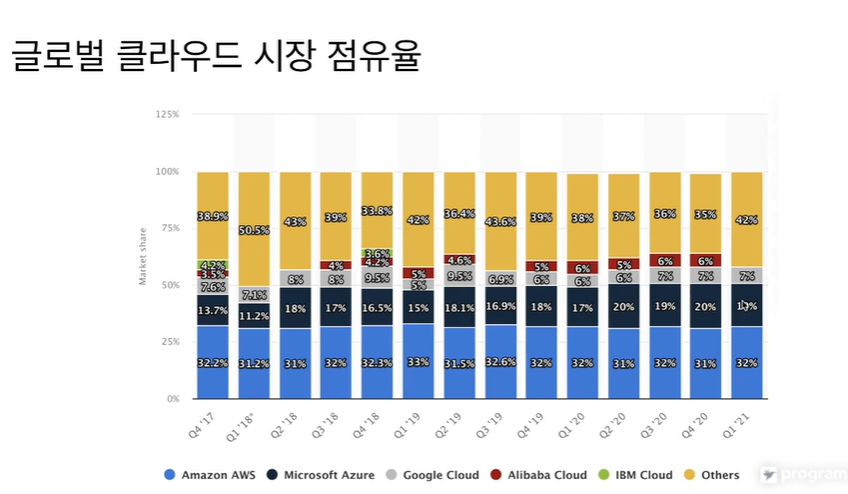
Azure가 조금씩 커지는 중. 나머지는 비슷.


SQL 엔진. 사이즈만 보면 나쁘지 않은데 2 PB가기 전에 여러 이슈가 나옴. 맥스님도 64TB까지 써봤는데 이때부터 여러 이슈 발생함.
Columnar starge 레코드를 저장할때, 레코드 하나 저장. 레코드 하나 저장식임 보통은. redshift는 컬럼별로 저장이 가능. 컬럼 A만 레코드별로 저장. 컬럼 B만 레코드별로 저장. 컬럼을 추가하거나 삭제하는게 아주 빠름.

INSERT로 큰 테이블을 입력하면 비효율적. 시간이 오래걸림.
csv, json 파일로 저장해 AWS의 경우 S3로 저장 -> COPY -> Redshift로 일괄 복사.
고정 용량/비용 SQL 엔진
- 용량을 돈을 주고 사고, 월별로 고정된 비용을 지출. 비용관리 측면에서 예측하기 쉬움. 그러나 사용하지 않아도 돈이 나감. 산 용량보다 더 필요한 경우 이런 처리가 느림.
vs Snowflake, BigQuery: 쓴만큼 비용을 냄. 돈을 얼마나 낼지 예측이 안됨. 그래도 나음.
primary key uniqueness를 보장하지 않음: PK로 지정된 필드에 값이 유일하게 존재하는지 체크해야함. 예를들어 사용자 테이블의 주민번호, 이메일이 PK가 됨. 이 유니크하다는 가정이 먼저 우선됨. 레코드가 추가될 때마다 중복인지 체크해야함. 프로덕션 데이베이스는 매번 체크함. RedShift, Snowflake, BigQuery는 보장하지 않음. CREATE TABLE을 할때 어떤 필드를 PK 지정해도 중복된 값을 레코드로 INSERT해도 아무 문제 없이 동작.
-> 그럼 PK unique는 어떻게 보장? -> 데이터 엔지니어가 따른 오퍼레이션을 해서 유니크함을 보장해줘야함. 개발자가 따로 보장해줌.

언어 측면에서 호환됨. Postgresql 없는 기능도 지원.
Postgresql을 지원하는 클라이언트나 툴이있으면 이를 가지고 RedShift에 접근이 가능.
구조화된 데이터만 처리할 수 있는 데이터베이스 - SQL 중심.
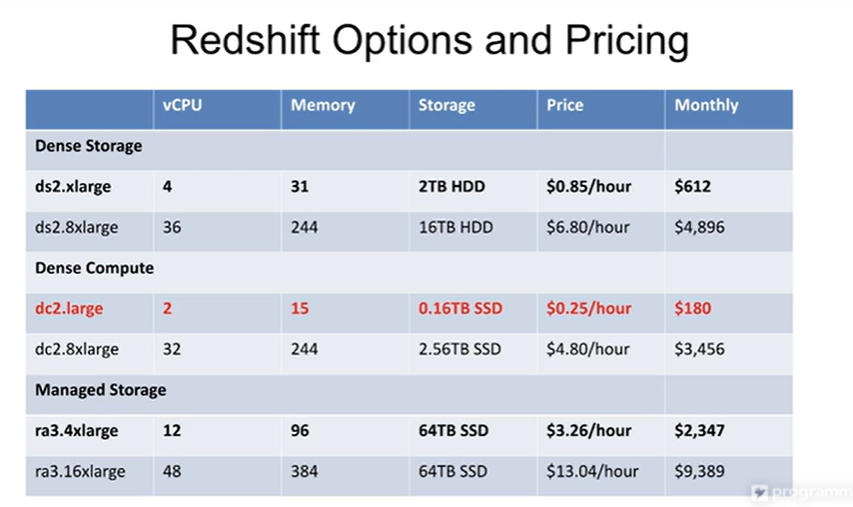
저장 집중 옵션.
처리 집중 옵션. -> ds2.large를 실습때 사용해볼 예정.
저장 + 처리 옵션 가장 강력.

하나 RedShift를 론치했다고 했을대 2단계 구조를 이렇게 만듦.
폴더를 만들어서 다양한 테이블들을 분류하고 관리함. RDBMS에 따라 데이터베이스, 스키마라고 부름
이 역시, SQL 커맨드로 만듦
CREATE SCHEMA raw_data;
CREATE SCHEMA analytics;
CREATE SCHEMA adhoc;RedShift admin 권한 갖고 있어야 함.
raw_data: 그대로 가져온 데이터들.
analytics: 더 쓰기 편하게 (denormalized) 만든 경우
adhoc: 데이터 분석, 데이터 과학자 내 나름대로 테스트하고 개발할 경우. 이 밑에 두라는 것.
raw_data를 데이터 엔지니어가 함. ETL 구현해서.
analytics는 데이터 분석가들이 관리함. 대시보드 만들고, 차트 만들고 등
adhoc: 개발자, 데이터 관련 사람들이 테스트하는 공간. 보통 아무도 관리 안함.