학습주제
데이터 웨어하우스 관리와 고급 SQL과 BI 대시보드
학습내용
데이터 웨어하우스 중심으로 맞춰져 있음
어떤 데이터 웨어하우스 기술들이 있는지 알아봄
- Redshift
- Snowflake
BI 대시보드 옵션들
데이터 웨어하우스가 어떻게 변하고 있는지?

어떤 일을 데이터 팀이 하는지
구성원은 누가 있는지
데이트 웨어하우스 소개
ETL 소개
데이터 레이크
7가지 데이터 웨어하우스 옵션
- RedShift 기능 소개
- Redshift 설치, 고급 기능 일부 데모
- 데이터 클라우드라고 할 수 있는 Snowflake 데이터 웨어하우스. Trial 기능 세팅 방법, 간단한 시연
- 대시보드 옵션, 데이터 웨어하우스의 미래/트렌드
다양한 데이터 웨어하우스 옵션

데이터 팀의 역할


신뢰할 수 있는 데이터로 부가가치 생성
부가가치가 무엇일까?
보통의 회사는 데이터로 바로 돈 X
데이터를 통해 본업을 가치를 높이는 방식으로 돈을 벌음
데이터가 간접매출을 내줌
이커머스. 물건을 온라인으로 팔때 매출, 데이터를 바탕 개인 추천, 검색 품질을 높여줌. 부가가치 생성.
데이터 조직. 직접매출 X, 본업을 잘 할수 있게하는 형태로 부가가치 생성
데이터 팀이 그냥 회사에서 인정받지는 못한다는 것. 회사에 중요하는 것 매출내는 것.
new oil이라는 소리가 있는데, 나는 회사에서 알아서 인정받겠지? 노노. 매출에 직접 기여하는 팀이 인정받음

의사 결정에 활용
디시전 사이언스. 결정을 ㅗ가학적으로
데이터를 고려한 결정
데이터 기반 결정
데이터 고려한 결정
내가 경영진으로 회사가 가는 방향. 비전 미션이 있는데, 데이터를 참고함. 데이터를 고려해 방향을 세밀하게 제어함. 조금 안맞아도 원하는 방향으로 움직이는 과정에서 데이터 참고
데이터 기반 결정
별다른 생각이 없고, 데이터가 이야기 하는대로 움직이겠다.
데이터는 기본적으로 과거의 기록. 지금까지 해오던 방식을 더 잘하는 방식은 가능하지만. 혁신적인, 새로운 방향으로 움직이는건 어려움. 최적화 - 데이터 드리븐. 혁신 - 데이터 인폼드 결정
의사결정자가 어떻게 하면 잘 결정할까?
지표 KPI를 데이터 기반 지표를 정의, 의사결정권자가 대시보드 보고 파악
(쉽게 결정을 도움)
어떻게 움직여야 할지를 볼 때, 리포트를 만들어서 어떤일이 벌어지고, 방향을 제시해줄 수 있음 - 데이터분석가

보통 머신러닝을 통해 이뤄짐 - 데이터 과학자
AI 팀, 프로덕트 사이언스 팀
제품 개발을 더 과학적으로 한다는 얘기
데이터를 기반으로 개인화 -> 경험 증대
운영 프로세스 최적화 -> 비용 감소
고객 상담 -> 챗봇 대체
QA 인터페이스 제공
데이터 조직이 회사에 기여하는 두번째 방법 -> 좀 더 고도화된 방법
- 디시전 사이언스
- 그 이후 프로덕트 사이언스 팀. 지표를 트랙킹하면서 개선해나감
데이터 조직을 리딩하는 리더가 부가가치에 대해 명확히 파악하고
다른 리더들과 소통을 잘 해내야함.
거창하게 시작하지 않고 -> 작게 조금씩 신뢰를 만들어나가야함.
일의 복잡도, 크기를 늘려가는 형태가 이상적임.
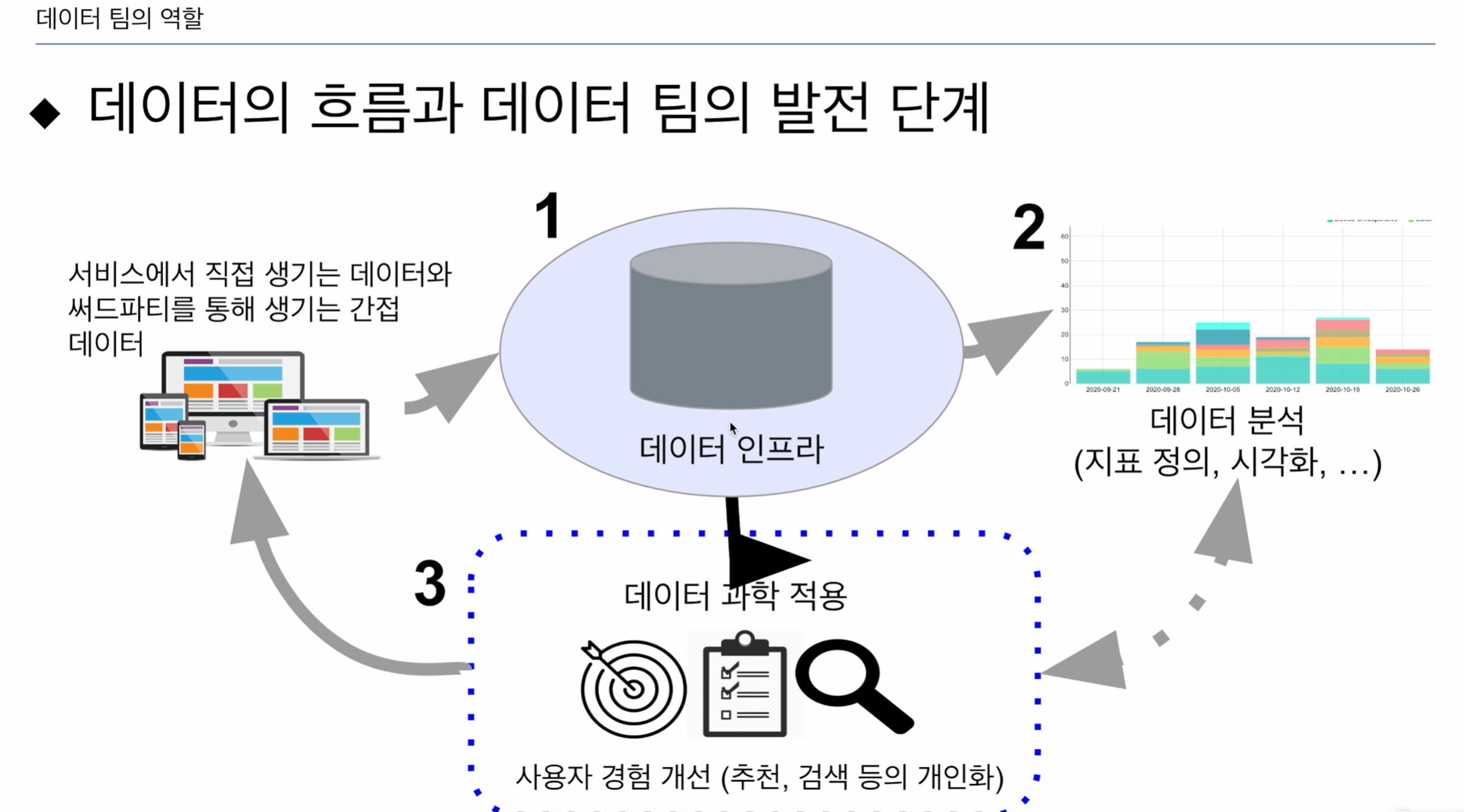
- 온라인 서비스에서 생기는 데이터, 페이지 방문기록, 버튼 클릭, 등등이 데이터로 생서됨. 프로덕션 데이터로 들어가거나 로그 형태로 구현됨. 이메일을 보내거나, 광고를 어딘가 띄우거나 사용자와의 인터렉션이 생김. 간접 데이터도 발생.
- 수집 정제를 하여 데이터 인프라, (데이터 엔지니어)
- 데이터 분석용, 데이터 웨어하우스 셋업, 관리
- 다양한 소스에서 데이터를 추출, 정제해, 적재, 구현, 관리(데이터 파이프라인, ETL)
- 데이터 분석가가 디시전 사이언스 (의사결정에 도움) 경영진과 논의, 데이터 기반으로 계산 대시보드 위에 시각화, 지표가 잘 만들어지면 의미가 분명해져 액션 취할 수 있음 -> 리포트도 작성. 데이터 수집이 선행되어야 함
작은 스타트업은 데이터 인프라가 없어 데이터 분석가부터 고용해서 사용함. 데이터 분석가는 수집된 데이터를 갖고 사용해야하기 때문에 능력이 떨어지게됨.
데이터 인프라를 구축하지않는 중소기업들이 많음.
강사님 유데미 있었을 때도 데이터 분석가가 먼저 고용되고 해고되었음.
- 데이터 인프라 구축
- 데이터 분석
- 데이터 과학자가 프로덕트 사이언스 팀을 만듦(머신러닝, AI) 데이터에서 패던을 찾아, 서비스 경험 개선, 운영비용을 줄임.
어떤 일을 머신러닝으로 대체했을 때 그 전보다 나아졌는지, 객관적으로 알려면 데이터 인프라가 구축 -> 시각화가 선행되어야 함.
절차적으로 구현되어야 데이터가 힘을 가짐.
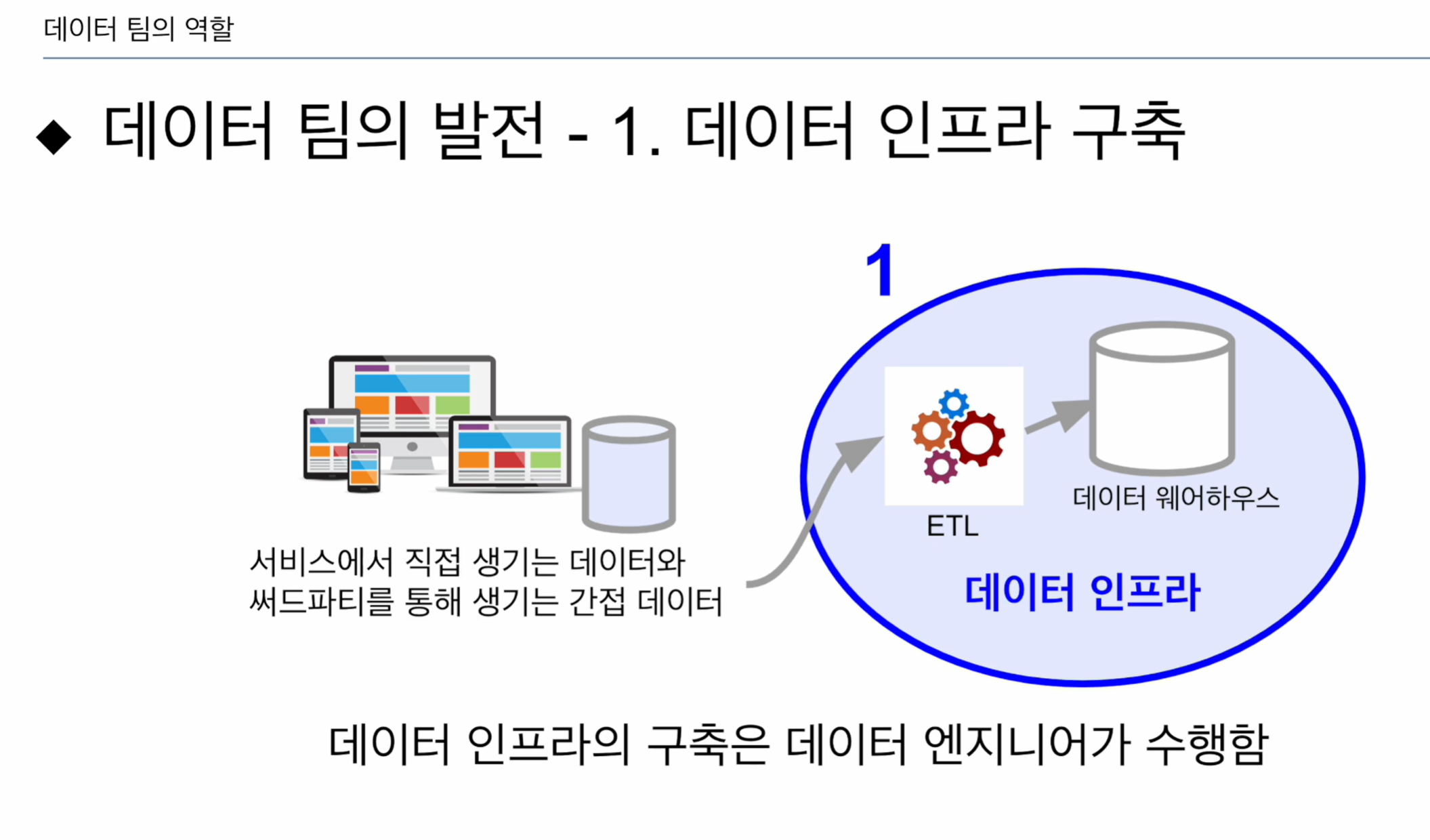
1. 데이터 인프라 구축. 직접데이터, 써드파티의 간접데이터
- 팀이 고도화되면 점점 더 많은 써드파티 데이터를 가져옴 -> ETL의 수가 많아짐.
이러한 데이터 구축은 데이터 엔지니어가 수행
빅쿼리, 스노우플레이크, 하이브, 스파크
ETL은 대부분 파이썬으로 작성.프레임워크 이용 airflow. 다음에 따로 살펴봄.
spark를 쓸정도면 데이터 팀이 고도화되었다는 것을 의미
프로덕션 DB - 프로덕션 서비스를 제공하기 위한 최소한의 DB. 고객이 사용함. 빠른 속도가 보장되어야 함.
데이버 웨어하우스 - 데이터 분석을 위함 (크기가 훨씬 큼.). 내부에서 데이터 분석을 하는사람들이 접근. 응답속도 좀 느려도 돼.
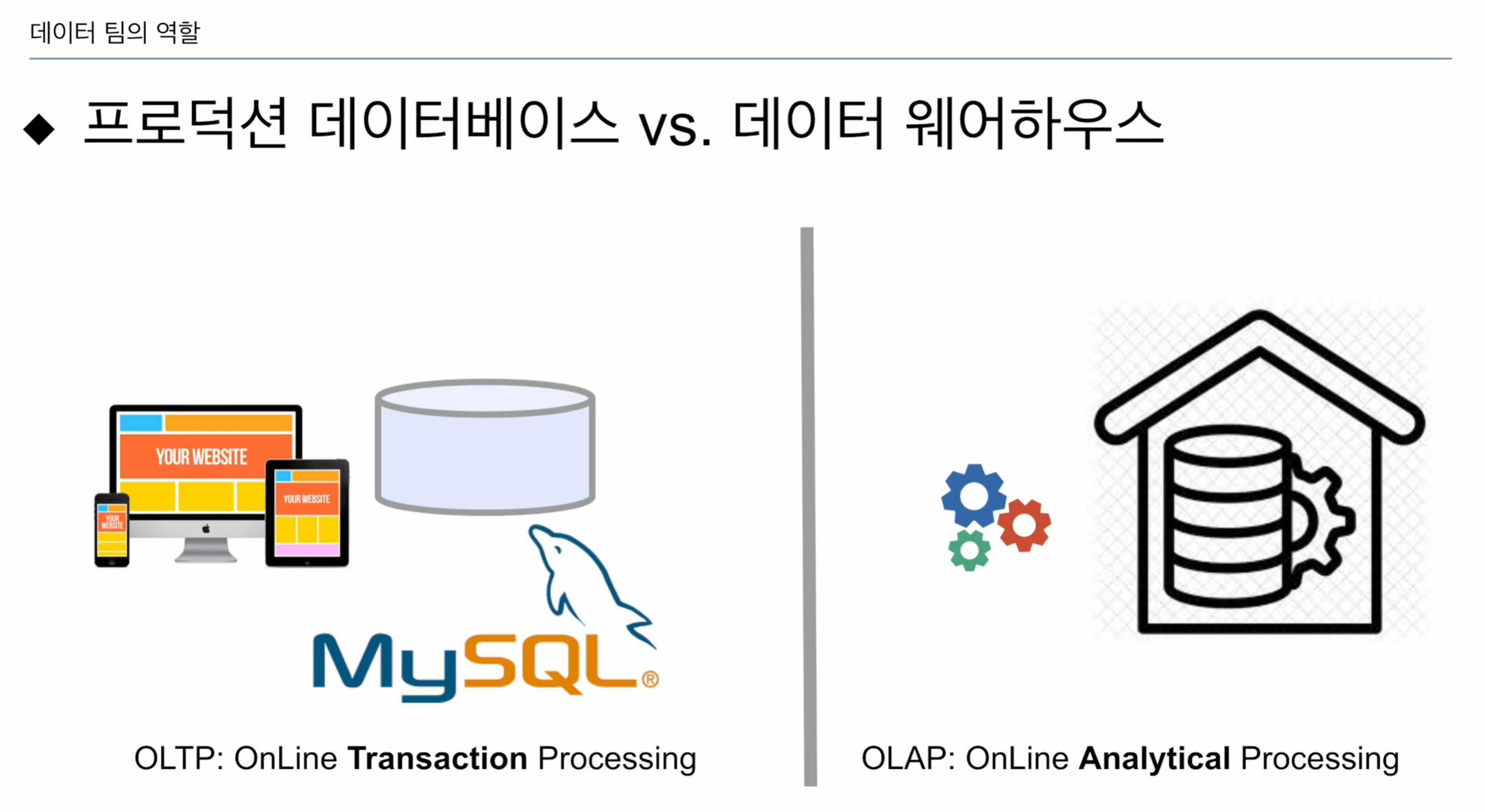
프로덕션 데이터베이스: mysql, OLTP
트랜젝션: 분명한 거래 같은 것. 온라인 웹서비스 기준 회원등록, 물건사는 것, 우리 사이트에 어떤 물건을 등록 -> 다 트랜젝션임.
- 처리속도 중요
- 처리 데이터는 크지 않음. 서버 1대짜리 솔루션임.
- 아껴쓰는게 중요함. (서버 구동용으로)
- 백엔드, 데브옵스 엔지니어가 만짐
- 엔드유저를 위한 DB
OLAP: 분석용. 분석을 위한 온갖 데이터 가져다 저장.
- 처리할 수 있는 크기 중요
- 아주 빠를 필요 없음
- 회사 내의 직원들이 접근, 주로 데이터 엔지니어, 과학자
- 데이터 사용이 민주화된 조직이면 일반 마케팅 부서, 프로덕트 매니저도 사용자라 볼 수 있음
OLAP를 중심으로 어떤것들이 있고, 특정 DW가지고 셋업, 무슨 특징 확인

회사가 작으면 큰 데이터 베이스를 쓸 필요 없음
- 작을때는 mysql 써도 상관은 없음
- 혹은 postgresql
- 커지면 그때가서 교체
프로덕션 DB기술로 우리 DW감당이 안되면 클라우드로 많이 이동함
AWS Redshift, 빅쿼리
스노우플레이크 등이 있다
오픈소스라면 하이브, 프레스토, 스파크
스파크는 사실상 표준임 (빅데이터 처리 기술).
모두 SQL 지원
제대로 된 데이터 팀이 있는지 알고싶으면 데이터 웨어하우스로 뭘 하는지 물어보면 됨.
데이터 웨어하우스 셋업하려고 데이터 엔지니어를 뽑는다면 많이 배울수 있는 기회가 되기도 함.

추출, 정제, DW에 로딩
- 로딩할 때는 테이블 형태
- DW 거대한 관계형 데이터베이스
- ETL을 데이터 파이프라인이라고 부름
- 소스에서 원하는 데이터 추출 extract
- 원하는 포맷으로 바꾸고 정제(클린업) transform
- DW load
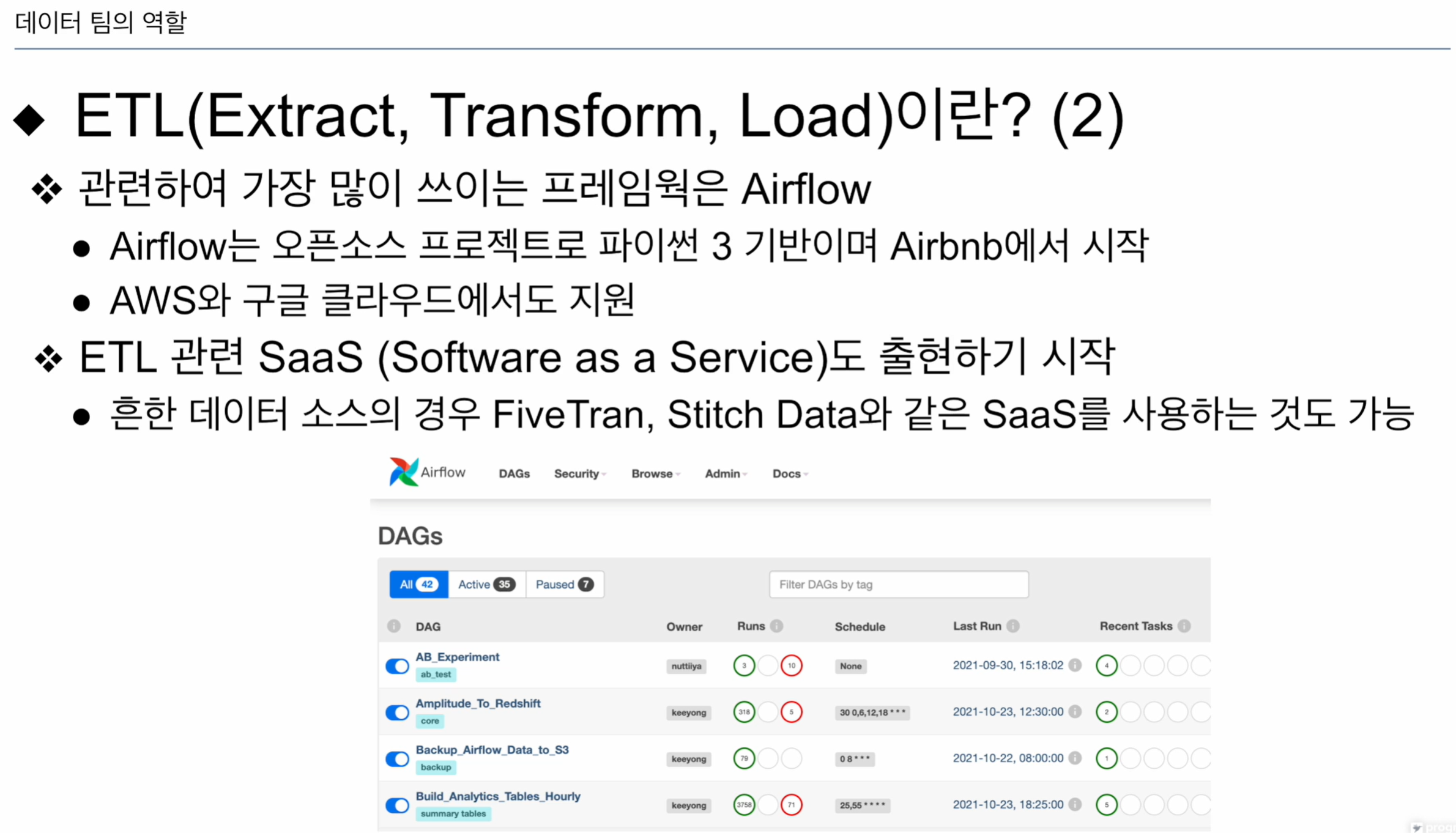
ETL관련 가장 많이 쓰는 프레임워크: Airflow
직접 빌드해서 만드는 프레임웤도 있지만
Saas형태로 코딩 없이, 데이터 소스 설정, DW 설정해서 데이터를 이동시켜주는 서비스도 있음
- 아직까지 기능이 강력하진 않음
- 어느 시점에 데이터 엔지니어가 airflow를 세팅함
- 보완적 역할음 함

지표를 시각화하는 대시보드 만들고, 필요에 따라 문제나 기회에 대해 리포트
비스니스 애널리틱스, 디시전 사이언스팀 등등
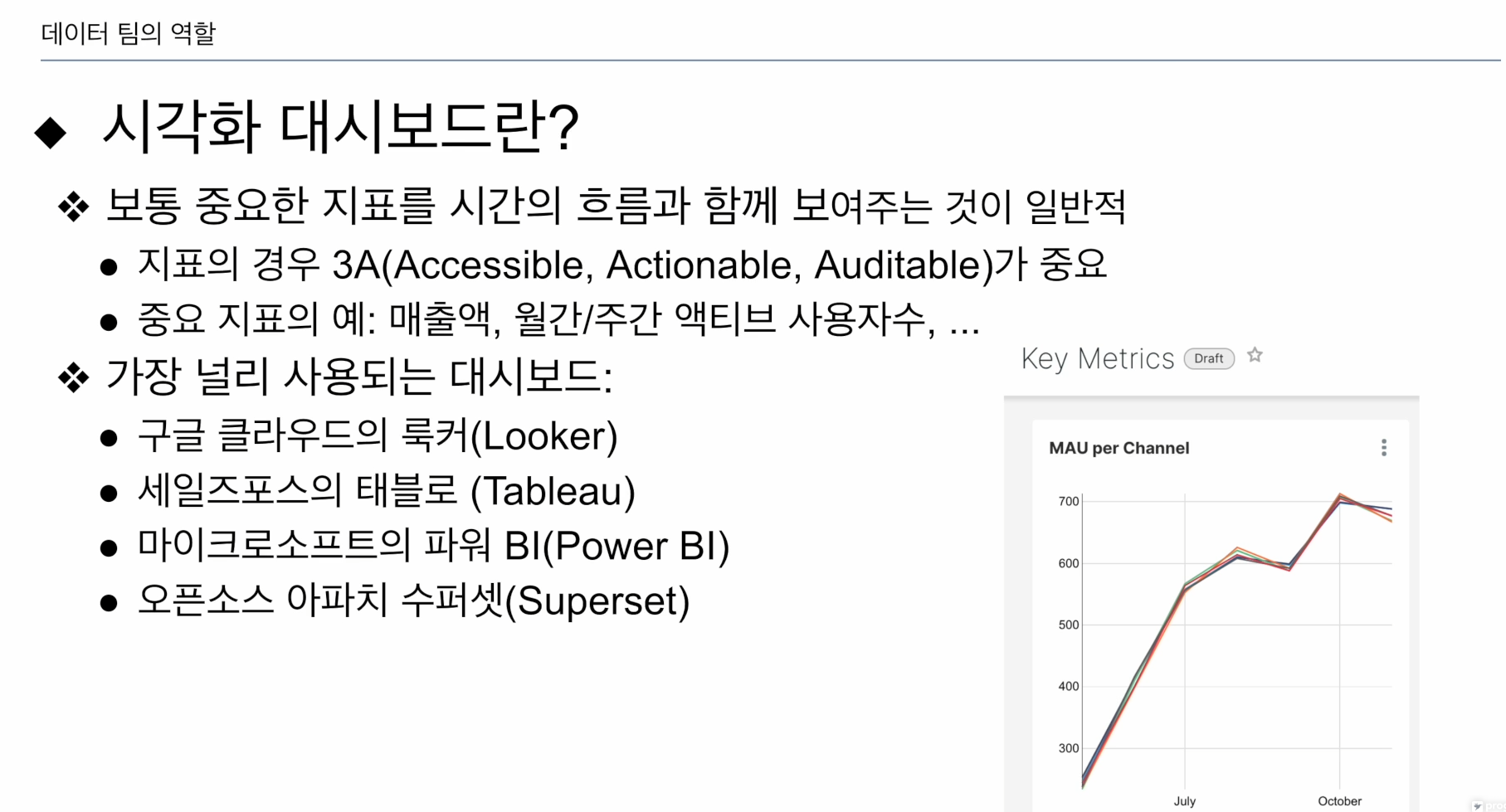
태블로가 가장 많이 씀.
power BI
Superset (에어비엔비)
특저 팀, 개인에게 중요한 지표를 시간의 흐름과 함께 시각화로 트렌드를 확인시켜줌.
3A가 중요함
중요하지 않은 지표를 제공하면 안됨.
Accessible: 자동화가 안된다그럼 안됨. 바로 접근 가능해야함.
Actionable: 등락의 의미가 분명
Auditable: 사람은 실수가 있기때문에 확인할 방법이 따로 있어야함.
KPI: 매출액, 사용자 수(실제 사용하는 사용자, 실제 돈을 내고 쓰는 사용자)
데이터 드리븐, 인폼드 디시전 해줌
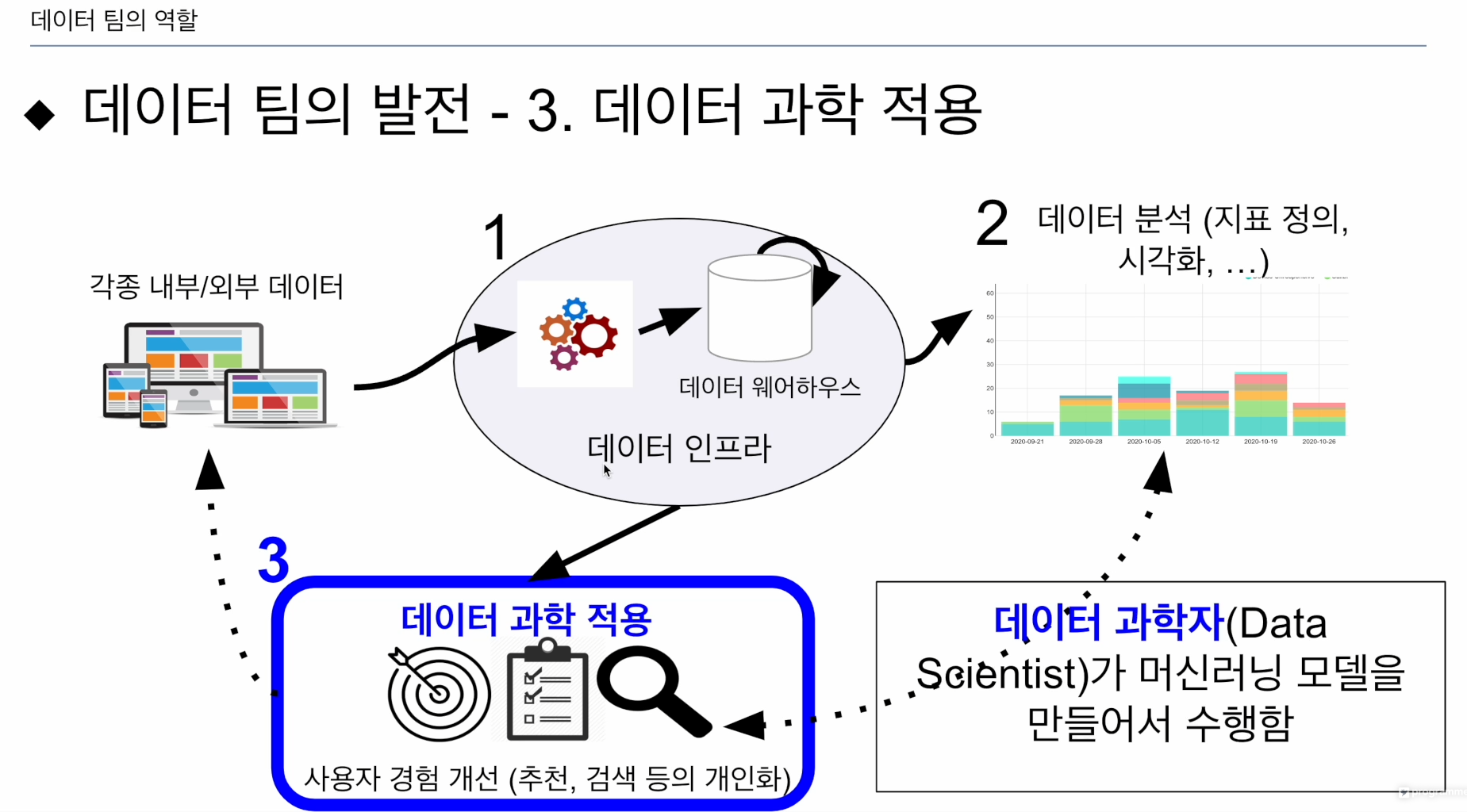
서비스 개인화, 사용자 경험 개선, 비용을 줄이고,
데이터 팀이 상당히 성숙했을 때 볼 수 있음
프로덕트 사이언스, AI 팀
AB테스트로 보다 객관화
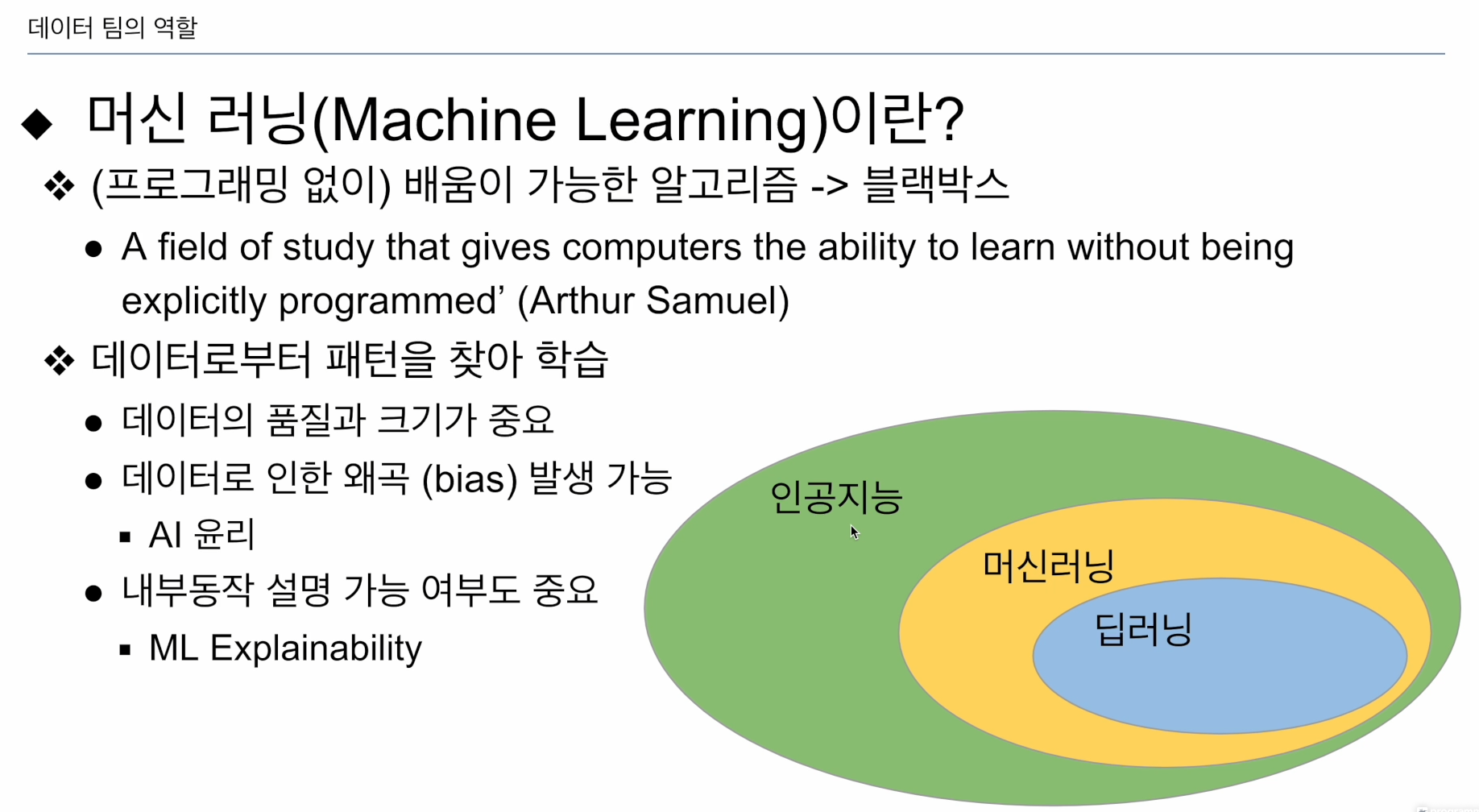
프로그래밍 없이 학습 - 머신러닝
예제: 훈련데이터 트레이닝 셋
데이터로부터 패턴을 찾고 학습함.
장점: 굳이 케이스 바이 케이스로 코딩하지 않아도 됨.
단점: 블랙박스. 설명 불가함. 이해할 수 없음 데이터 품질이 나쁘면 결과도 나쁨.
데이터 왜곡이 있으면 왜곡이 일어남. 범죄자 프로파일링 때 흑인을 넣으면, 흑인만 넣어도 범죄자라고 판담
헬스케어에서 결과를 설명해줄 수 있어야함. 머신러닝에서 진단 내린걸 왜 그런지 이유를 설명해줄 수 있어야함.
