학습주제
데이터 조직의 구성원
학습내용

데이터 엔지니어
- 데이터 인프라 구축
데이터 분석가 - DW 데이터 기반 지표 만들고 시각화
- 내부 직원들의 데이터 관련 질문 응답
- 데이터 엔지니어 기술 알기를 원하는 곳도 생겨남(AirFlow 등)
데이터 과학자 - 머신러닝 모델을 만듦어 고객 서비스 경험 개선, 개인화, 자동화, 최적화
- 어느정도 데이터 엔지니어링을 할줄 알기 원함\
- ML 엔지니어 -> ML 옵스로 진화

기본은 프로그래밍. 코딩 능력이 중요 - 알고리즘, 자료구조 들어옴
- 코딩 연습 꾸준히
- 파이썬만 알아도 충분
데이터 웨어하우스 구축 - 처음엔 mySQl처럼 작게 시작하나 나중에 RedShift 처럼 본격적으로 DW로 옮겨가면 됨.
- 정말로 데이터가 커지면 BigQuery, 스노우 플레이크로 가나, 그게 아니면 Redshift도 충분함
ETL 추가 늘어가면 - 실행순서, 실패하면 다시 실행하고, 운영상의 오버헤드 늘어남.
- Airflow로 플로우 조정
- Spark로 큰 리소스 분산처리.
자원의 낭비가 발생을 막기 위해 컨테이너를 사용, 도커, k8s사용 -> 주니어에게 바라는 기술은 아님. 도커는 단순해서 배울만한 가치가 있음. k8s는 나중에 공부
기본적으로 파이썬 알고, SQL 잘 알기. - Airflow ETL 관리 프레임워크를 어느정도 익히기
- Spark 프레임워크
- Docker는 간단하게 쓸줄 알면 금상첨화
- k8s까지는 주니어에게 바라는 스택은 아님
데이터 엔지니어가 알아야 하는 기술

간단한 프로세싱은 sql
비구조화 -> 구조화 경우에만 SQL 안씀
파이썬
DW
ETL: airflow
데이터 크기가 커치면 빅데이터 프로세싱 프레임워크 : 하둡 Yarn, 이제는 Spark
airflow까지가 주니어가 알아야할 기술
중니어 이상
서버가 항상 바쁜건 아니기에 k8s같은 서버 컨테이너 관리서비스 사용
클라우드 컴퓨팅
꼭 알아야 하는 기술. certification aws로 얻는건 나쁘지 않음. 이력서에도 한줄 의미있게 쓸 수 있음.
일을 하면서
- 머신 러닝
- AB 테스트, 통계 기본 지식
데이터 엔지니어 스킬 로드맵
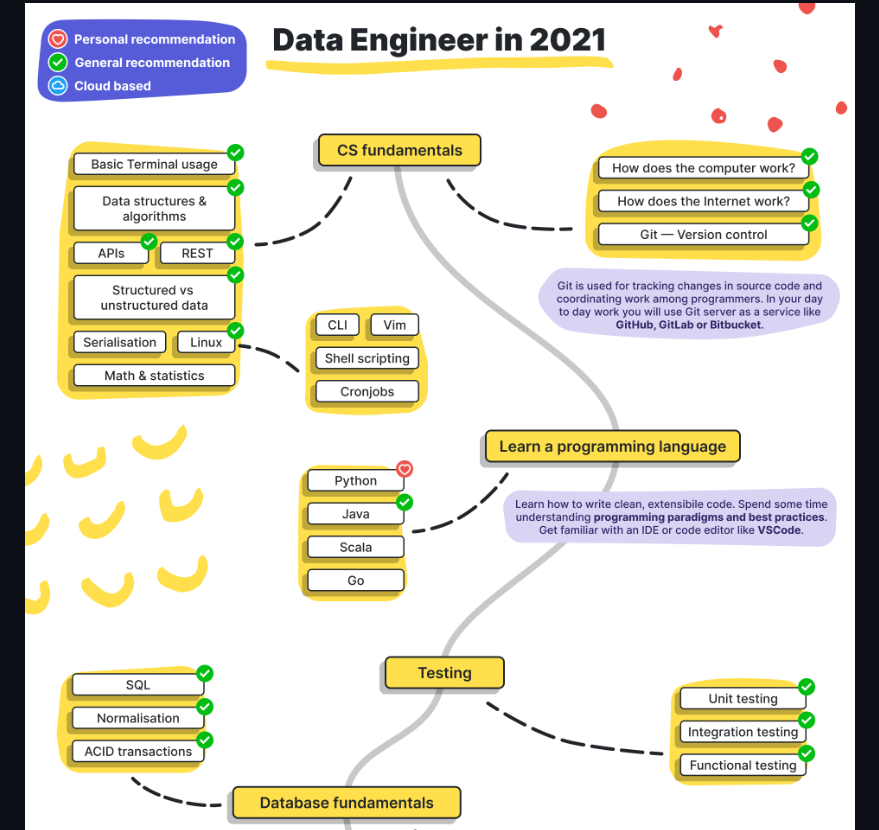
저번에 봤던 그림
더 엔지니어로 성장하고 싶으면 ML 엔지니어류
데이터 분석가

현업 부서들과 같이 일하고, 더 일잘하게 도와주는 역할
의사결정을 조금 더 객관적 과학적으로 하게끔 도와줌
- 팀의 중요 지표를 정의, 대시보드로 시각화
- 태블로, 룩커를 많이 사용함
- 오픈소스 : 수퍼셋(aribnb)
도메인이나, 지식이 있으면 도움이 됨. 없어도 배우다보면 알게됨.
대시보드에 없지만 여러 질문이 들어오면 대답해줌
우리가 두가지 방향으로 프로덕트 만들었는데 매출 관점에서 어느게 나은지(리포트, 의견 요구)
의사결정을 위한 데이터 제공을 위한 요구받음.(갑자기 들어오는 경우 많음) - 생각보다 질문이 많고 반복적임. 이를 대시보드형태로 만들어 셀프로 알아서 찾아가게끔. 능력있는 데이터 분석가의 기준

SQL
잘 쓰는 대시보드: 룩커, 태플로, 파워 BI, 수퍼셋
데이터 엔지니어들이 가져다 놓은 데이터를 어떻게 쓸 것인지, 테이블 스키마를 어떻게 정의할 것이냐. 그걸 잘하는게 좋음
통계 지식이 중요함. 데이터 분석이 의미가 있으려면, 신뢰도 등등(데이터 엔지니어도 알면 좋음)
데이터 모델링 관점에서 raw 데이터로 새로운 데이터를 만듦. ELT라고 함. DBT기술이 들어감.DBT는 "Data Build Tool"의 약자로, SQL 기반 데이터 웨어하우징과 ETL(Extract, Transform, Load) 프로세스를 관리하기 위한 개발 도구입니다. DBT는 데이터 엔지니어링과 데이터 분석 작업을 쉽게 수행할 수 있도록 도와줍니다.
추세는 데이터 엔지니어링쪽인 지식이 있으면 좋다고 여겨짐.

- 소속감이 있기 어려움
- 앞으로도 이렇게 살아야 하나? 커리어패스에 의구심 갖기 쉬움. 인프라가 잘 안되어 있지 않으면 할 수 있는 일이 많지 않아짐. DW 있는지 꼭 확인해봐야함.
- 중앙집중 구조, 하이브리드 구조에서 비교적 만족도 높음. 현업부서에 직접 속하면 만족도 떨어짐.
- 데이터 분석가는 조직 구조가 중요함
- 요즘 추세는 별도의 데이터 분석가를 고용하기보단, 팀 내에서 분석능력을 키우는 쪽으로 가는 중 (시티즌 데이터 애널리스트)

프라이버시 엔지니어: 개인정보가 갈수록 중요해지는데, 그 유출시 패널티가 엄청남. 회사의 명성에도 누가됨. 어떤 정보가 개인정보고, 시스템 내에 저장할 필요가 있는지, 저장한다면 어떻게 저장하고 보호해야하는지. 데이터직군이라기엔 약간 힘듦. 이 직군은 구글에서 시작
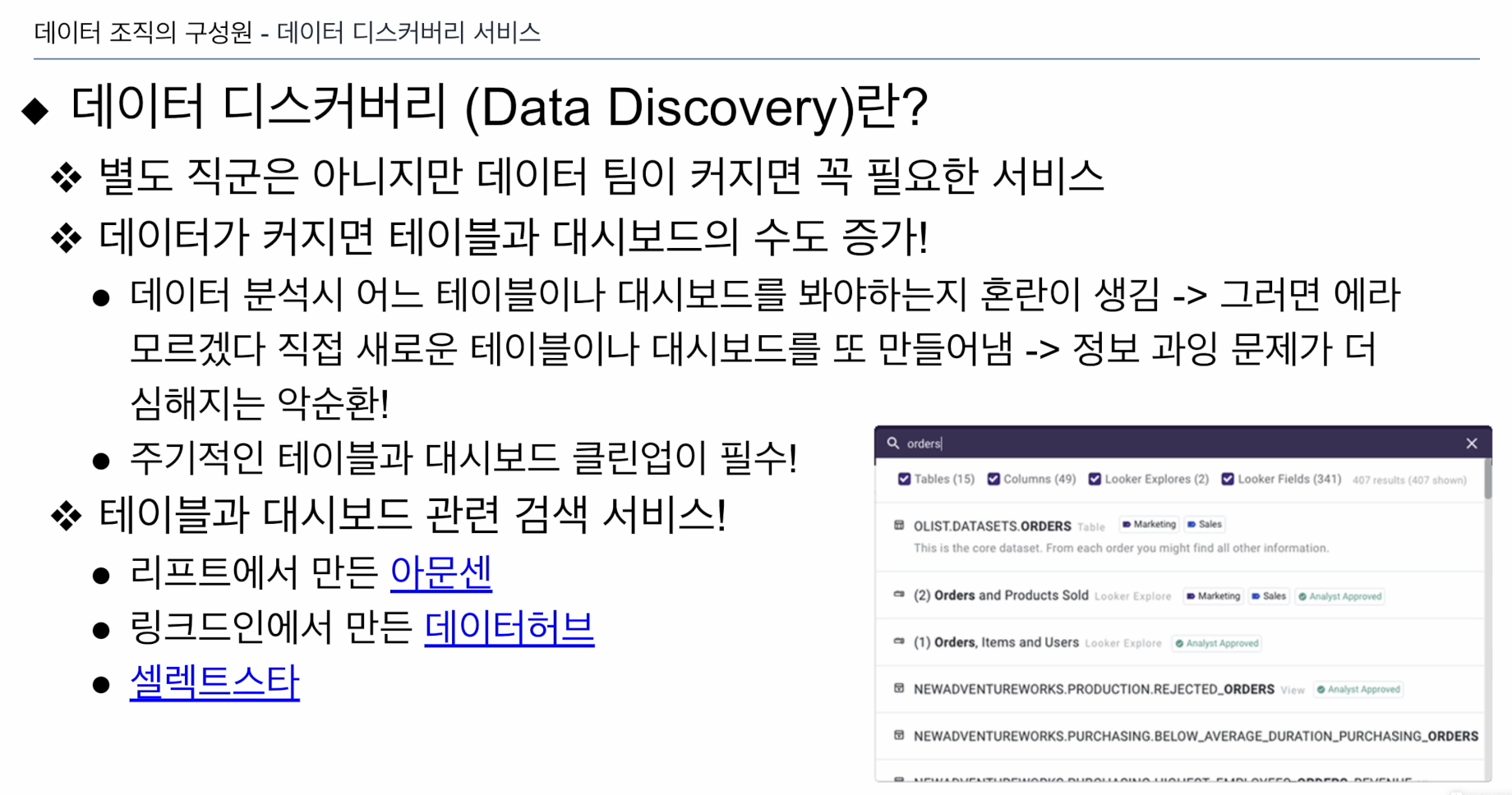
데이터 디스커버리 서비스: 대시보드의 수가 늘어남에 따라 내가 원하는 대시보드는 어디에 있고, 내가 원하는 정보는 어떤 테이블을 봐야하는가. 보통 데이터를 찾고, 정제에 70% 찾다보니 노가다임. 내가 찾는데 필요한 노력을 줄여주고 재밌는 30%일을 하는데 집중하게 해줌.
데이터 카탈로그: 카탈로그를 만들고 검색 서비스를 달아놓는데, 이를 데이터 디스커버리가 해줌.
ML OPS

서비스 코드를 개발하진 않음. 다른 개발자들이 만든 코드를 가져다 테스트를 돌리고, 통과한 코드를 프로덕션 배포 패키지로 만듦. 그 후 모니터링, 이슈 발생시, 추적해 문제해결. 해결이 어려우면 롤백. 이러한 전체 프로세스 구현, 운영
ML 옵스: 데브옵스와 동일하나, 모델 서빙 환경과 모델의 성능 저하를 모니터링하고 필요시 에스컬레이션 프로세스 진행.
데브옵스에서 "에스컬레이션 프로세스"는 문제 또는 이슈가 발생했을 때, 해당 문제를 상위 수준의 지원팀 또는 조직으로 전달하는 프로세스를 의미합니다. 이를 통해 문제가 신속하게 해결될 수 있도록 조치를 취할 수 있습니다.
프로덕션(Production)은 소프트웨어 개발 및 서비스 운영에서 실제 운영 환경을 의미합니다. 프로덕션 환경은 최종 사용자가 실제로 소프트웨어를 사용하고, 서비스가 운영되는 환경입니다.
테스트 - 배포 - 모니터링 - 이슈발생시 팔로우
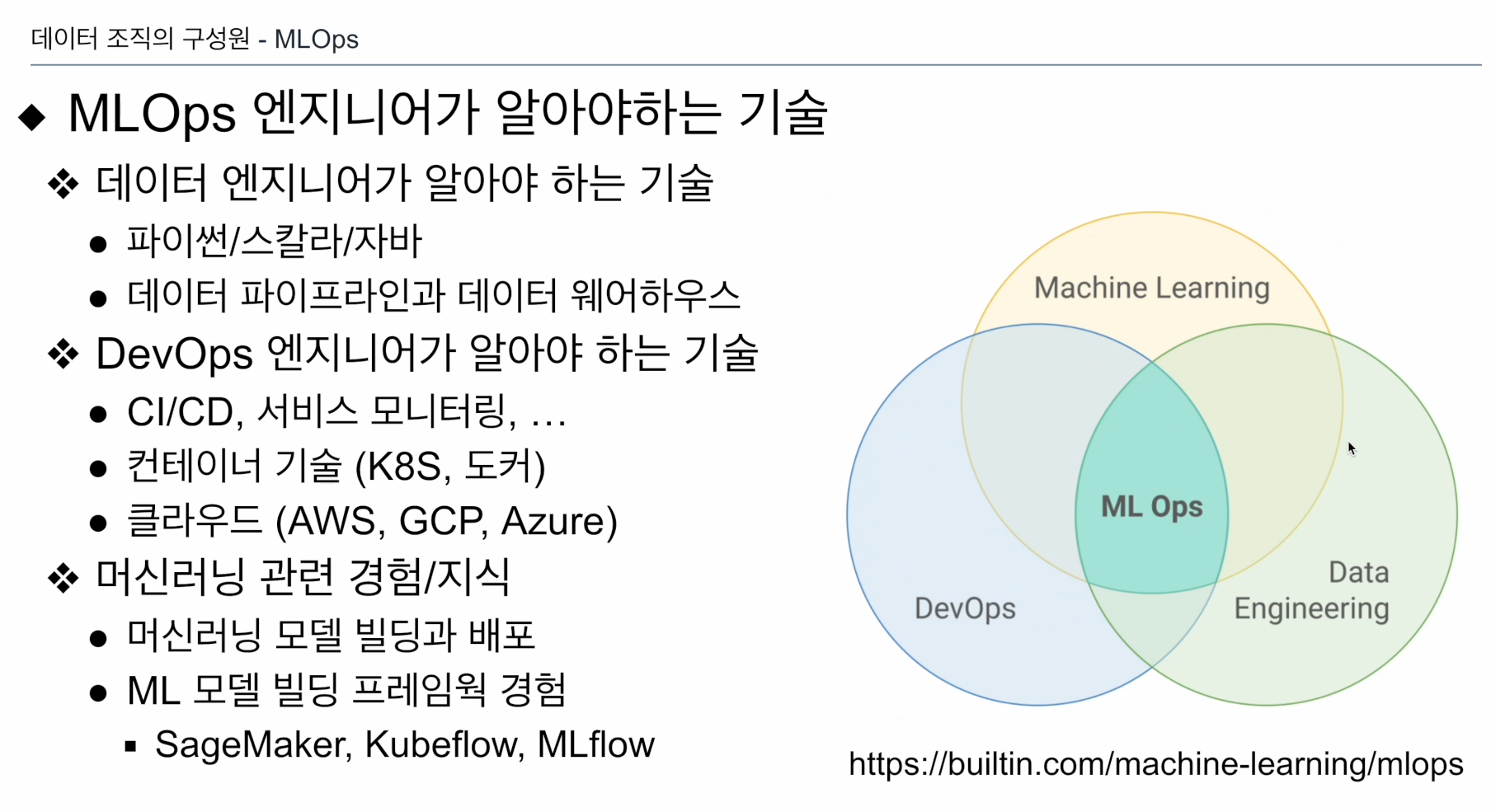
알아야할 것도 많고, 데브옵스 경험도 있어야하고, 주니어로 시작해도, 시니어와 함께 일하는 형태, 생긴지 얼마 안됨.
ML 모델 빌딩 프레임워크 경험
- SageMaker, Kubeflow, MLflow
이 중 하나는 편하게 쓸 수 있어야함
프라이버시 엔지니어

- 경제적 패널티, 회사의 명성을 보호
- 개인정보가 꼭 회사가 필요한 정보인지, 써야한다면 어느정도 변환을 해서 쓰는지?
시스템을 디자인 할 때부터 개입하게 됨.
개인정보 보호법 - GDPR
- HIPAA( 건강정보)
- CCPR (캘리포니아
데이터 디스커버리
별도의 직군은 아님
- 데이터가 커짐에 때라 테이블과 대시보드의 수가 증가
- 새로운 테이블과 대시보드를 만들어내는게 비효율적임 (기존에 있는 테이블 쓰는게 효율적)
- 알아서 검색해서 찾을 수 있게 하자!
- DB를 뒤져서 검색할 수 있게 해줌.
예시
- 리프트의 아문센
- 링크드인의 데이터허브 (제일 많이 씀). 이걸 SaaS 형태로 제공하는 회사도 있음.
- 셀렉스스타
