학습주제
Redshift
학습내용

특징 소개
설치(serverless, Trial) - 최대 3달 혹은 300불
초기 설정(스키마, 그룹, 유저)
COPY(벌크 업데이트) 명령으로 테이블에 레코드 적재
- AWS S3 버킷 생성. IAM 부여
구글 콜랩에서 연결해서 진행
고급 기능
- 권한, 보안, 백업, 테이블 복구, s3 외부데이터를 내부데이터 처럼 사용. 중단, 제거

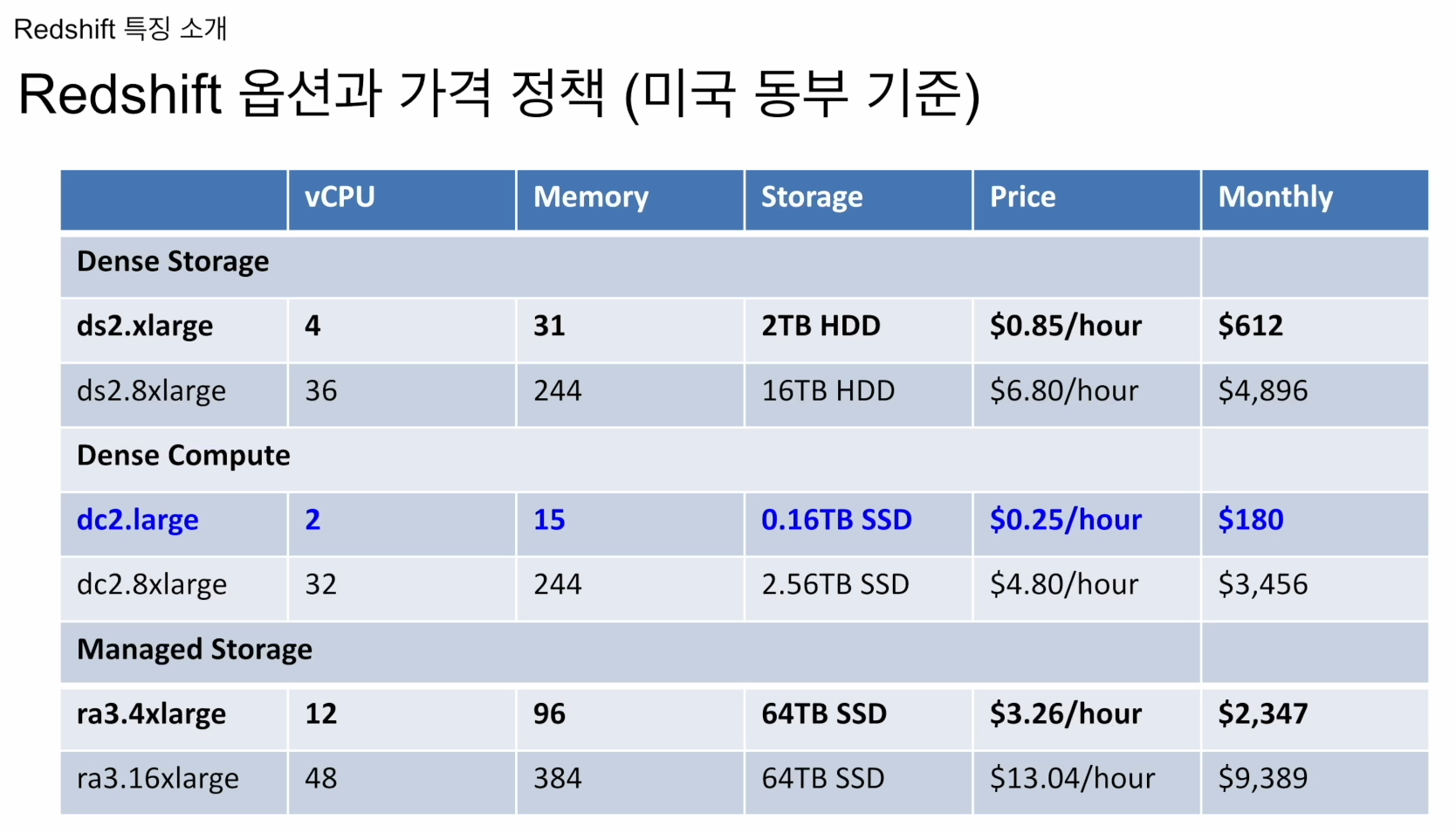
클라우드 기반 빅데이터 웨어하우스

최대 2PB
작게는 160GB 시작
고정비용으로 사용했을 때 이야기
SSD를 사용하기에 처리속도 빠름
- OLAP 이라 프로덕션 데이터베이스로 사용은 불가
컬럼 기반
컬럼 바이 컬럼으로 저장. 레코드별 X
데이터를 쓸 때 모든 컬럼을 쓰지 않음. 성능이 좋아짐

보통 INSERT INTO를 사용해서 레코드를 하나씩 적재 X
모든 레코드를 파일에 저장 후, AWS s3에 로딩하고 COPY 커맨드로 일괄 복사
빅쿼리, 스노우플레이크도 동일 개념 제공
가변비용도 제공함. - 쓴만큼 돈을 낸다. 이번에 데모
데이터 공유 기능
- 데이터로 매출을 올릴 수 있음
PK uniqueness를 지정해줘도 데이터 엔진이 보장 X
mysql, postgresql은 보장

결국 SQL 기반
postgresql 모든 기능 지원은 X
툴, 라이브러리로 엑세 가능 JDBC, ODBC로도 redshift 조작 가능
스토리지 중심
컴퓨팅 중심(초기 스타트업)
둘다 추구(굉장히 비쌈)
서울, 도쿄, 뉴욕 가면 210정도 함
용량이 다 차면 scale up
dc2.large -> dc2.8xlarge
scale out: 1대 -> 다수 대수 서버로 증대
이후 serverless라는 새로운 옵션이 나오면서 쓴만큼 돈을 냄

스케일링 방식은 고정비용일 때 의 얘기
Scale Out방식 한대 더 추가
Scale up 사양을 업그레이드
Scale Out -> resizing -> Auto Scaling으로 자동 확장

기본적으로 가변비용 옵션
미리 용량을 구매? X. 내 쿼리가 필요한 만큼 리소스르 사용.
훨씬 스케일러블, 하지만 비용 예측이 불가함
고정비용 -> 재무팀 선호
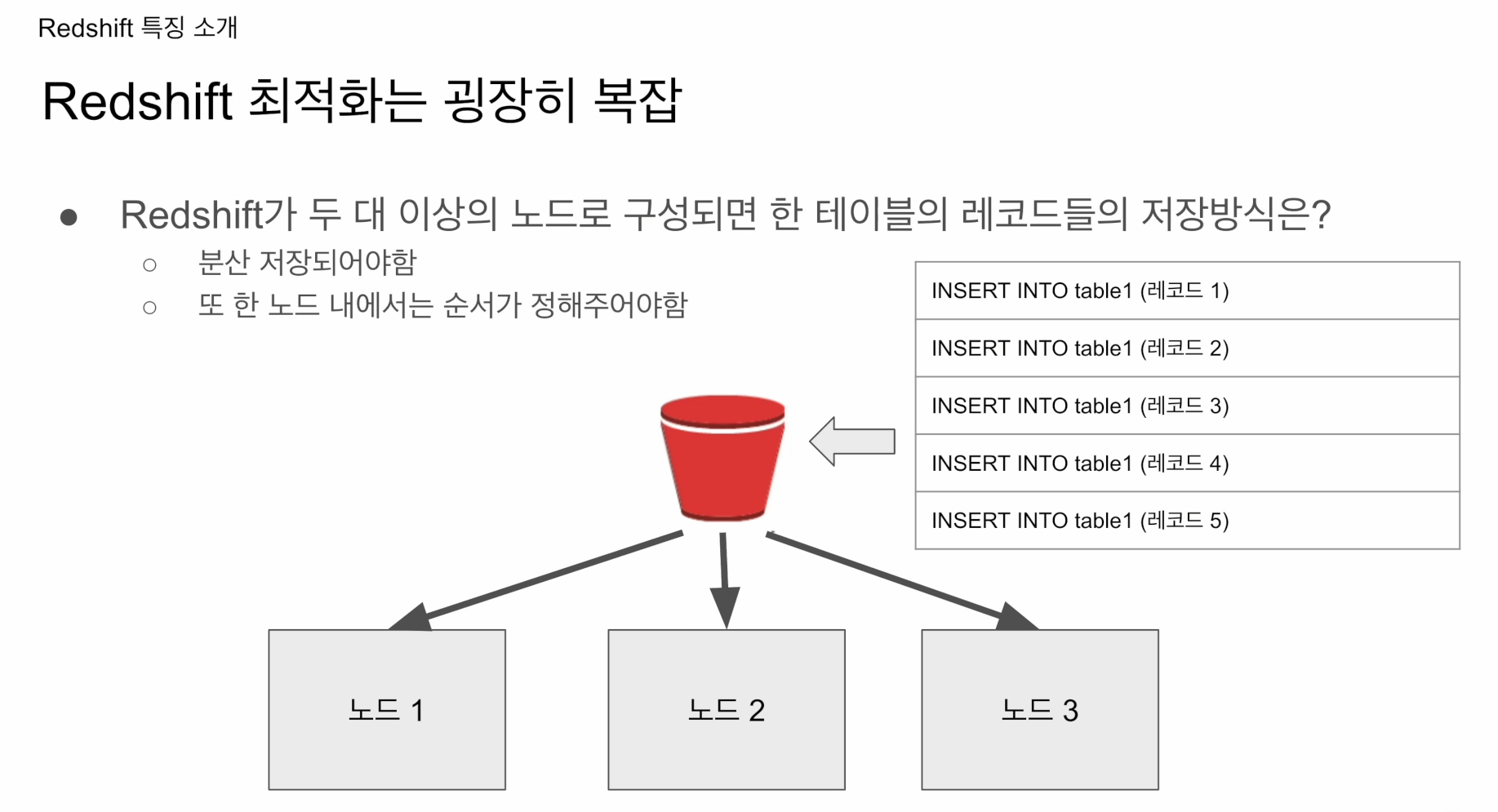
서버의 수가 하나보다 커질 때부터 개발자가 지정해줘야함
위처럼 세개의 노드로 구성된 클러스터가 있다. 테이블 1의 레코드 5개가 있다면 어떻게 분산 저장될 것인가? -> 개발자가 지정
빅쿼리, 스노우플레이크는 개발자가 알 수도 없고 알필요도 없음. 알아서 관리해줌. 나는 SQL만 실행시켜주면 됨.
redshift는 관리의 번거로움이 있고, 데이터 스큐 문제 발생
데이터스큐란 레드쉬프트 클러스터 내에서 데이터가 불균형하게 분산되는 상황을 의미합니다. 이는 특정 파티션(partition) 또는 슬라이스(slice)에 데이터가 과도하게 몰리는 현상으로, 성능 저하와 쿼리 실행 시간 증가로 이어질 수 있습니다.
데이터스큐는 주로 테이블의 분산 키(distribution key) 또는 정렬 키(sort key) 선택의 부적절한 사용, 데이터 적재 과정의 문제, 데이터 변형 작업의 미흡한 처리 등으로 인해 발생할 수 있습니다. 데이터스큐 문제를 해결하기 위해서는 데이터 분산 및 조정을 최적화하고, 적절한 분산 및 정렬 키를 선택하며, 쿼리 성능 모니터링 및 최적화를 수행하는 등의 작업이 필요합니다.
어떤 테이블을 세개의 노드로 나눠저장할 때 불균형하게 저장할 수 도 있음.
ex 98% 노드 1, 1% 각 노드 2,3 - 분산저장의 의미가 없음
노드 1의 로드에 상당한 시간 -> 전체 처리시간 증가
하둡 위에서 돌아가던 프레스토, 스파크 모두 같은 이슈 갖고 있음
빅쿼리, 스노우플레이크는 알아서 해줌

크게 세가지 속성이 있음
- Diststyle: 한 테이블에 속성으로 지정, 그 속성에 맞게 테이블의 레코드들이 노드로 분배. all: 모든 레코드들이 모든 노드에 복제, even: 노드별로 돌아가면서 1개씩 넣음. key:특정 컬럼의 값을 기준으로 레코드들이 다수의 노드로 분배. key로 사용하는 것이 테이블의 PK. 어느 컬럼을 기준으로 배포하는지 지정해줘야 함.
- Distkey: style이 key인 경우 분배기준 컬럼 지정. 그 안에서 정렬 기준은
- Sortkey: 특정 컬럼 이름을 갖고, 그 기준을 갖고 정렬
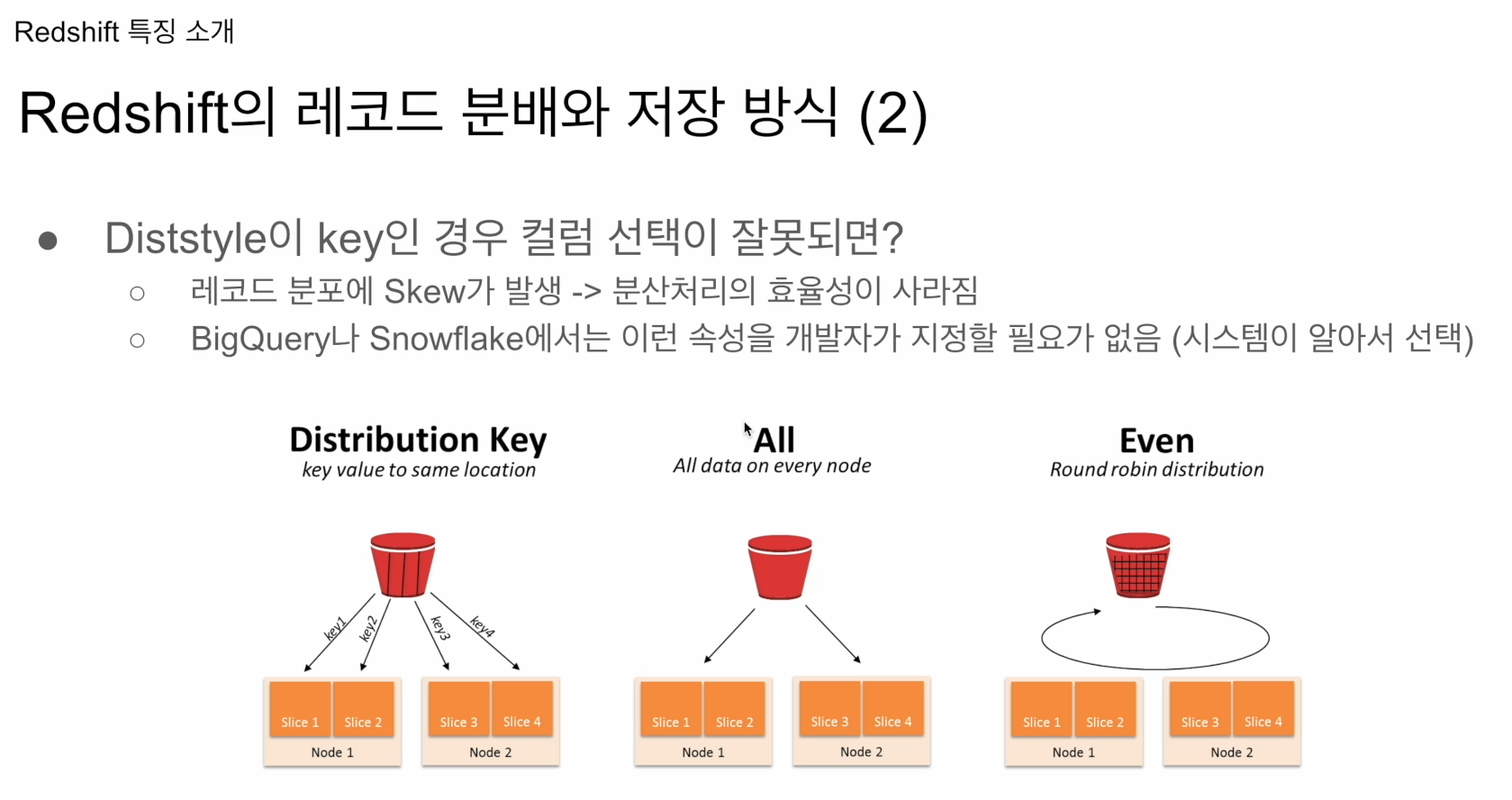
All: 테이블이 각 노드에 복제
even: round robin 형태. 돌아가며 저장
key: 특정 컬럼 기준, 특정 키의 값이 같은 레코드는 같은 노드로 들어감. 장점: 그 키를 기준으로 그룹바이, Join 할때 데이터 이동이 별로 없음. 그러나 데이터스큐가 있다면 노드 1에 많고, 노드 2엔 적은 데이터 들어갔다면, 나중에 퍼포먼스 문제를 일으킴.
스파크, 프레스토도 이런 이슈 가짐
빅쿼리, 스노우플레이크는 알아서 해줌.
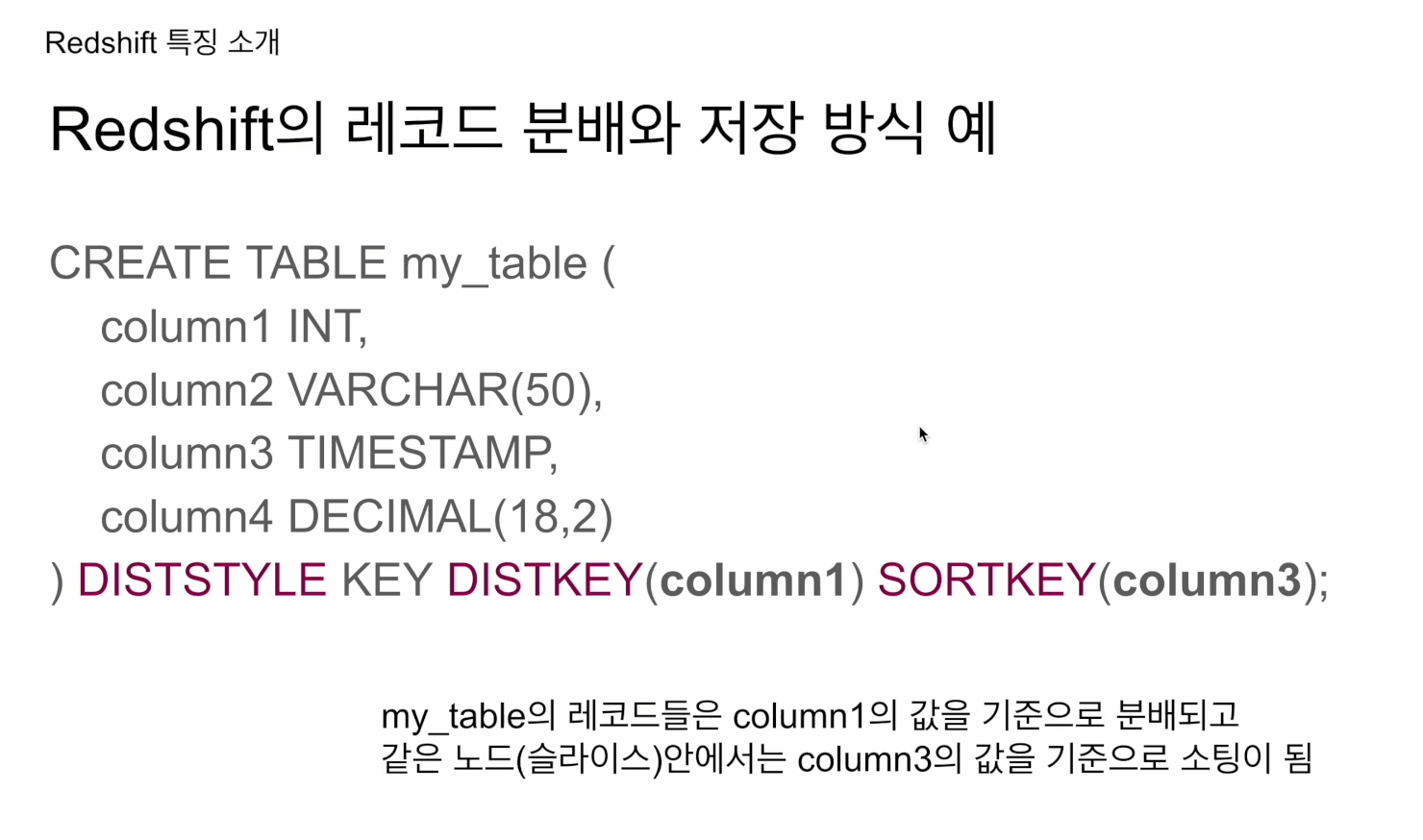
CREATE TABLE my_table (
column1 INT,
column2 VARCHAR(50),
column3 TIMESTAMP,
column4 DECIMAL(18,2)
```DISTSTYLE KEY DISTKEY(column1) SORTKEY(column3);
레코드들은 컬럼1의 값을 기준으로 분배되고, 같은 노드 안에서는 컬럼3의 값을 기준으로 소팅됨CREATE TABLE 형태로 쓰고 괄호 닫고 DISTSTYLE 언급 하는게 보기 좋음.
key, all, even 형태 있음
sortkey는 TIMESTAMP를 쓰는게 일반적
컬럼 1을 기준으로 같은 값들은 같은 노드에 들어감. 굉장히 스큐가 크면 디폴트인 even을 쓰는게 나을 수 있음. 적어도 노드에 균등히 분배되기 때문에 처리는 나쁘지 않음. 그러나 그룹바이를 할 때 같은 노드로 이동해야하기 때문에 빅데이터 프로세스에서 셔플링이 발생 -> 시간이 걸림. 셔플링 후에 스큐가 생기면 병렬처리 이점 사라짐
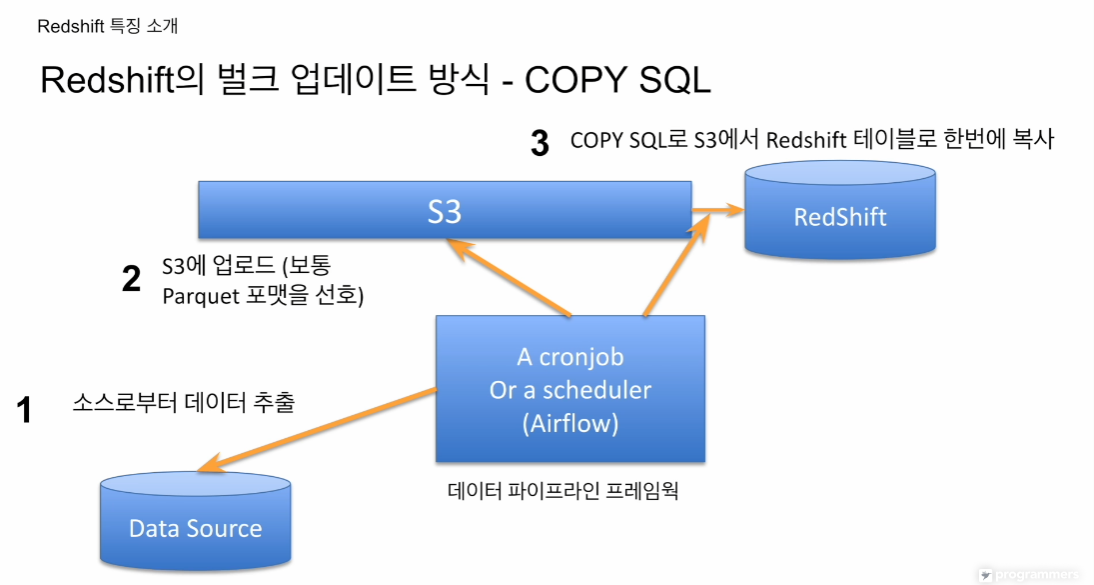
- COPY SQL
이 방식은 빅쿼리, 스토우플레이크 모두 갖고 있음. 에어플로우 등 스케줄링 잡이 있으면 데이터를 추출해서 그걸 원하는 포맷으로 바꾼 뒤, redshift 저장. INSERT INTO는 레코드 별 적재라 속도가 느림. 이걸 쓰면 적재하느라 시간이 다 가버림.
압축률이 좋은 바이너리 포맷으로 s3에 업로드, 그 다음 레드쉬프트에서 한번에 벌크 업데이트. 이 방식이 웨어하우스에서 일반적 사용됨.

Postgresql방식
CHAR는 UTF-8 기준임. 한글자는 1캐릭터. 레드쉬프트에선 바이트단위. 한국, 중국, 일본어는 1캐릭터가 3바이트임. 영어냐 한글이냐에 따라 담을수 있는 글자 수 다름
TEXT는 길이가 굉장히 긴 타입. 레드쉬프트는 256 제한.
VARCHAR은 6만단위로 조금 다름
다른걸 별다르게 차이 안남

SUPER - C, c+ 유니온 타입
post엔 JSON 타입이 있음.
레드쉬프트는 JSON 바로 지원 X. 기본적으로 CHAR 타입으로 받아와서 JSON 함수로 파싱하게 됨.
