학습주제
실리콘밸리 회사들의 데이터 스택 트렌드 (10개 회사)
- 조사 바탕
학습내용

데이터 플랫폼이 어떻게 발전해왔나
초기 단계: 데이터 웨어하우스 + ETL
발전단계: 데이터 양 증가에 따라 더이상 감당하지 못하는 단계 2가지 변화 필요.
1. 데이터 레이크 도입: 비구조화, 훨씬 큰 데이터를 경제적으로 보관
2. 이를 처리할 수 있는 빅데이터 프로세싱 프레임워크(스파크)
성숙단계: 데이터 활용 증대
시티즌 데이터 사이언티스트, 애널리스트. 직접 하려는 경향이 생김
- ELT 단의 고도화가 필요. 데이터 품질 보장 피룡. DBT 도입
- 머신러닝 활용 유스케이스 증가. 얼마나 빨리 배포, 성능이 떨어지는지 모니터링. MLops같은 직군이 생김.
- 각 현업부서들이 직접 DW, ETL 구현
발전단계
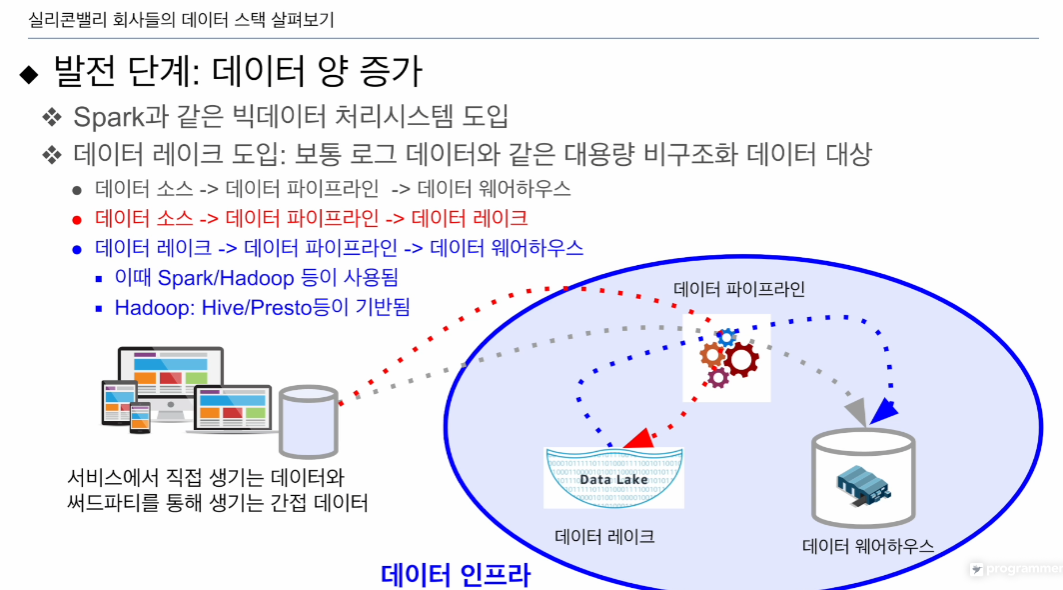
데이터 양이 증가: 데이터 레이크 필요
로그데이터
데이터 레이크 -> 데이터 레이크로 적재
데이터 레이크 -> 데이터가 적고 고품질일 시, 데이터 웨어하우스 적재
이 유스케이스는 위의 세가지 형태가 있음
- 데이터 소스 -> ETL -> 데이터 웨어하우스
- 데이터 소스(굉장히 큼) -> 데이터 레이크
- 데이터 레이크 -> 데이터 웨어하우스
- 데이터 레이크 -> 데이터 레이크
- 데이터 웨어하우스 -> 데이터 웨어하우스
빅데이터 프레임워크를 필요로함(Spark, Hive, Presto)
Aws Athena가 있음
외부 -> 내부 ETL
내부 -> 내부 ELT
데이터 양이 커지기 때문에 데이터 레이크 같은 경제적이고 큰 스토리지
이를 처리하기 위한 Spark 필요
성숙단계
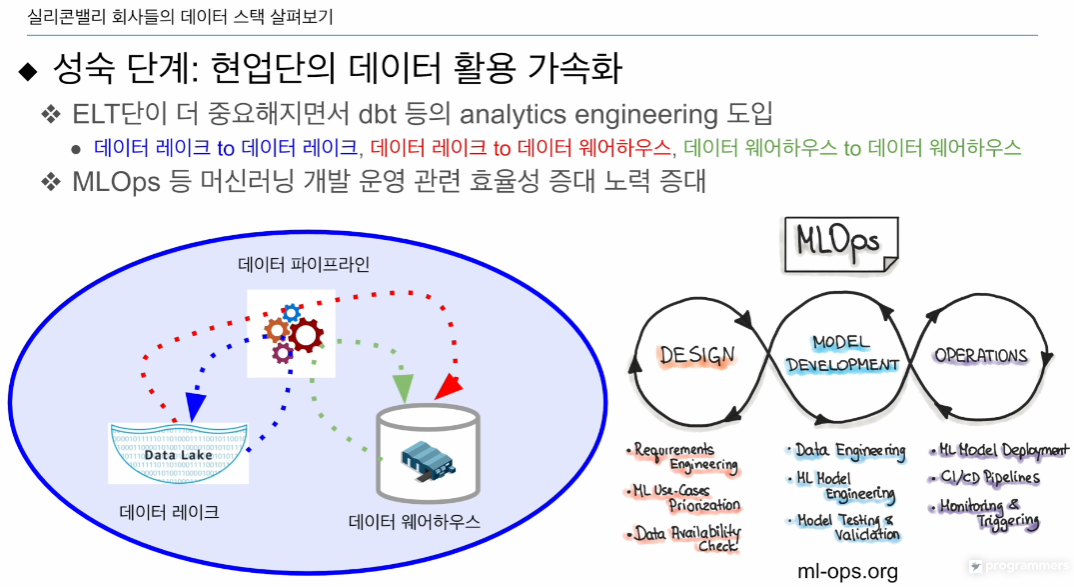
데이터 품질이 중요해짐
머신러닝 사용이 가속화됨
ELT 단에서 데이터의 품질이 중요해짐
다양한 테스트를 붙여야함.
DBT라는 툴을 사용(분석가, 엔지니어)
ELT: 앞 슬라이드와 같음. DL -> DL, DL -> DW, DW -> DW
MLOps직군 만들어 머신러닝 개발 전반을 책임짐. 모델 자체는 과학자가 만듦.
모니터링, 에스컬레이션
더 나아가면 현업단에서 데이터 관련 의사결정을 직접하려고 함. DW, ETL을 직접 만들게됨.
실리콘밸리 회사 데이터 스택
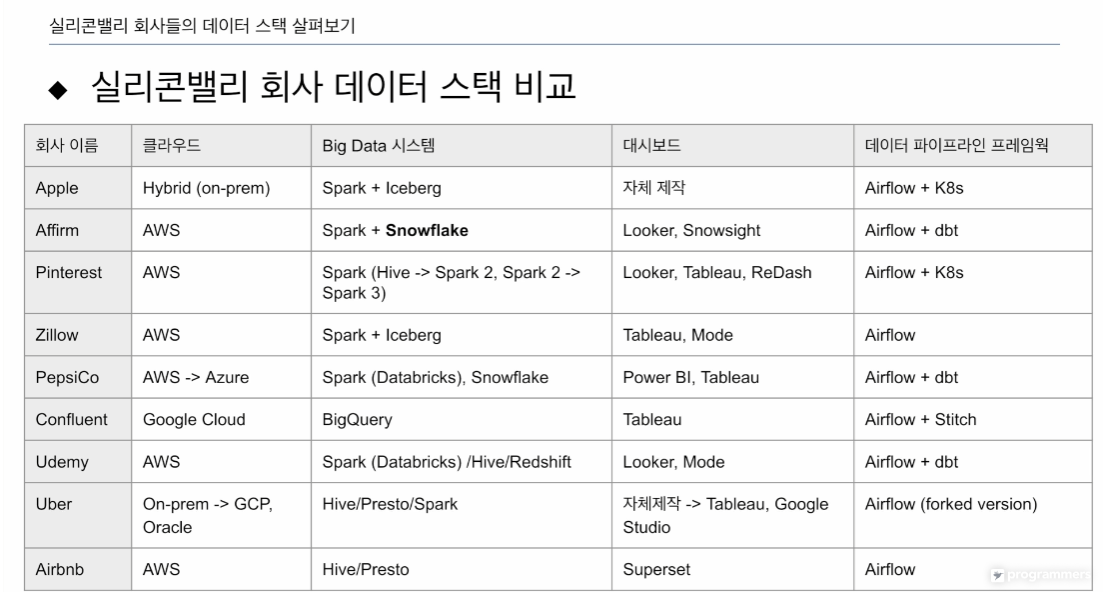
거의 대부분 AWS 를 클라우드로 사용
애플은 on-perm
우버는 Orcle로 갈아탐
아직은 AWS가 대세
빅데이터 시스템을 보면
다 Spark을 쓰고 있음. 가끔 BigQuery, Hive/Presto
애플은 Iceberg로 데이터 레이크 구현 -> Spark로 실행함
Affirm Spark - SnowFlake
Uber 데터웨어하우스로 빅쿼리
대시보드
자체제작도 있지만
태플로, 루커가 제일 많음
모드, 리대쉬도 있음
수퍼셋 - 에어비앤비
데이터 파이프라인은 예외없이 Airflow
데이터 엔지니어는 Airflow
빅데이터 처리 Spark
클라우드는 AWS
컨테이너 측면 도처 k8s
