학습주제
Name Gender 예제 프로그램 포팅
학습내용

구글콜랩에서 만들어본 s3 csv -> redshift 테이블로 적재해봤는데
멱등성
SQL 트랜잭션
원래 코드는 헤더가 레코드로 적재되는 이슈도 있었음.
https://colab.research.google.com/drive/1gZ1VUqLiVtVENCpfxxuRJU0Sp3RB1qx6?usp=sharing

from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
import requests
import logging
import psycopg2
def get_Redshift_connection():
host = "learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com"
user = "keeyong" # 본인 ID 사용
password = "..." # 본인 Password 사용
port = 5439
dbname = "dev"
conn = psycopg2.connect(f"dbname={dbname} user={user} host={host} password={password} port={port}")
conn.set_session(autocommit=True)
return conn.cursor()
def extract(url):
logging.info("Extract started")
f = requests.get(url)
logging.info("Extract done")
return (f.text)
def transform(text):
logging.info("Transform started")
lines = text.strip().split("\n")[1:] # 첫 번째 라인을 제외하고 처리
records = []
for l in lines:
(name, gender) = l.split(",") # l = "Keeyong,M" -> [ 'keeyong', 'M' ]
records.append([name, gender])
logging.info("Transform ended")
return records
def load(records):
logging.info("load started")
"""
records = [
[ "Keeyong", "M" ],
[ "Claire", "F" ],
...
]
"""
schema = "keeyong"
# BEGIN과 END를 사용해서 SQL 결과를 트랜잭션으로 만들어주는 것이 좋음
cur = get_Redshift_connection()
try:
cur.execute("BEGIN;")
cur.execute(f"DELETE FROM {schema}.name_gender;")
# DELETE FROM을 먼저 수행 -> FULL REFRESH을 하는 형태
for r in records:
name = r[0]
gender = r[1]
print(name, "-", gender)
sql = f"INSERT INTO {schema}.name_gender VALUES ('{name}', '{gender}')"
cur.execute(sql)
cur.execute("COMMIT;") # cur.execute("END;")
except (Exception, psycopg2.DatabaseError) as error:
print(error)
cur.execute("ROLLBACK;")
logging.info("load done")
def etl():
link = "https://s3-geospatial.s3-us-west-2.amazonaws.com/name_gender.csv"
data = extract(link)
lines = transform(data)
load(lines)
dag_second_assignment = DAG(
dag_id = 'name_gender',
catchup = False,
start_date = datetime(2023,4,6), # 날짜가 미래인 경우 실행이 안됨
schedule = '0 2 * * *') # 적당히 조절
task = PythonOperator(
task_id = 'perform_etl',
python_callable = etl,
dag = dag_second_assignment)이 코드를 에어플로우로 포팅을 해본다.
콜랩으로 계산했던 코드를 보고
airflow로 포팅한 첫번째 버저 확인
레드 쉬프트 연결해
테이블 연결
conn 만들어서 레드쉬프트 연결. 오토커밋 True
ETL 함수를
3개 만들었음
transform의 경우 헤더 제거를 위해
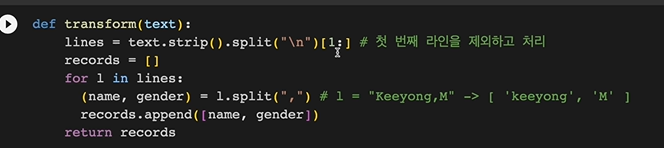
split("\n")[1:]
으로 제거했었음
load 함수가 핵심.
오토커밋이 트루
try 안에
cur.execute("BEGIN;")으로 명시적으로 트랜잭션을 열고
풀리프레쉬를 시도하기에
cur.execute(f"DELETE FROM {schema}.name_gender;")
지금 테이블 레코드 다 날림. 껍데기 남아있음
마지막으로 cur.execute("COMMIT;")
커밋을 해야 실제 물리 테이블로 씌여지고 다른 사람들에게 보여짐
만일 try 사이에 에러가 나면
except가면
롤백
그리고 raise를 써서 사람에게 알림
이를 에어플로우로 포팅함
이걸 파이썬 오퍼레이터로 많이 안코치고 포팅을 해본다.
거의 변경없이 포팅을 함
관계 모듈을 몇개 임포트 함
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
import requests
import logging
import psycopg2
def extract(url):
logging.info("Extract started")
f = requests.get(url)
logging.info("Extract done")
return (f.text)
def transform(text):
logging.info("Transform started")
lines = text.strip().split("\n")[1:]
records = []
for l in lines:
(name, gender) = l.split(",")
records.append([name, gender])
logging.info("Transform ended")
return records
def load(records):
logging.info("load started")
schema = "kjw9684k"
cur = get_Redshift_connection()
try:
cur.execute("BEGIN;")
cur.execute(f"DELETE FROM {schema}.name_gender;")
for r in records;
name = r[0]
gender = r[1]
print(name, "-", gender)
sql = f"INSERT INTO {schema}.name_gender VALUES ('{name}','{gender}')"
cur.execute(sql)
cur.execute("COMMIT;")
except (Exception, psycopg2.DatabaseError) as error:
print(error)
cur.execute("ROLLBACK;")
raise
logging.info("load done")
def etl():
link = "https://s3-geospatial.s3-us-west-2.amazonaws.com/name_gender.csv"
data = extract(link)
lines = transform(data)
load(lines)
dag_second_assignment = DAG(
dag_id = 'name_gender',
catchup = False,
start_date = datetime(2023,4,6), # 날짜가 미래인경우 실행 안됨
schedule = '0 2 * * *' # 매일 2시
)
task = PythonOperator(
task_id = 'perform_etl',
python_callable = etl,
dag = dag_second_assignment)각각을 태스크로 만들 것인가? 이를 묶어서 하나의 태스크로 갈것인지 정해야 한다.
여기선 세개의 함수를 하나의 태스크로 만들었음. 하나의 파이썬 오퍼레이터가 있다는 말.
밑에 내려가보면 대그 만들었음. name_gender
태스크 한개 생성함.
perform_etl 태스크 실행될때, etl 함수를 실행시킴
콜랩에서 실행을 함수로 묶음
구글 콜랩에서 봤던 코드를 포팅했는데 태스크 하나로 포팅함.
각각을 태스크로 만들어 볼 수도 있음.
현재 get_Redshift_connection()이 문제임.
현재 호스트, 비밀번호가 하드코딩되어 있음
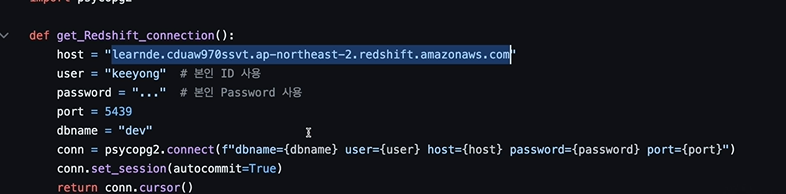
host 가 바뀌면 직접 코드로 들어가 바꿔야 함
더 큰 문제는
유저와 패스워드가 그대로 노출되어 있음.
이 깃헙 리포가 해킹될 수 있음.
이런것들이 코드 바깥으로 나가는게 좋음
csv 파일 링크도 하드코딩

얘도 환경변수로 빼내면 좋음
각각을 태스크로 만드는 것도 개선사항이 될 수 있음
태스크 데코레이터를 쓰면 조금 더 읽기 쉬워지는 부분이 있음

params를 사용해본다
파이썬 오퍼레이터를 써볼 때 씀. 파이썬 콜러블로 이 오퍼레이터를 실행할때 뭔가 변수들을 넘기고 싶을 때 params로 딕셔너리 형태의 변수들을 넘기고, 파이썬 콜러블로 지정된 함수에서 받는 방법이 있었음.
읽어와야하는 csv 파일을 파이썬 콜러블로 실행되는 함수에 인자로 넘김.
execution_date을 얻어본다. 이 변수의 의미는 다음 챕터에서 설명. 에어플로우가 갖는 시스템 변수를 어떻게 읽어볼 수 있는지 과정 설명.
테이블 레코드 삭제 방법은 delete from은 where을 써서 조건에 맞는 레코드만 삭제, sql 트랜잭션 존중.
truncate은 조건없이 테이블만 쓰고 바로 날림. 트랜잭션 무시함.
두번째 버전에서
달라진 부분은
def etl(**context):
link = context["params"]["url"]
# task 자체에 대한 정보 (일부는 DAG의 정보가 되기도 함)을 읽고 싶다면 context['task_instance'] 혹은 context['ti']를 통해 가능
task_instance = context['task_instance']
execution_date = context['execution_date']링크가 아까는 하드코딩 되어 있었지만 넘겨진 params의 url에서 넘겨받아
그 링크를 extract에 인자로 넘겨준다
execution_date를 시스템 변수를 받는 방법은 context 딕셔너리를 받는데, 다양한 에어플로우가 관리하는 변수들이 존재함. 태스크 인스턴스, 유니크한 아이디임.
params엔 다양한 키들이 존재. etl이라는 함수를 파이썬 오퍼레이터에서 사용될 때, 다양한 파타미터들이 params 아래 딕셔너리 값들임. 이걸 위에서 엑세스함.
이렇게 두번째 버전 마무리

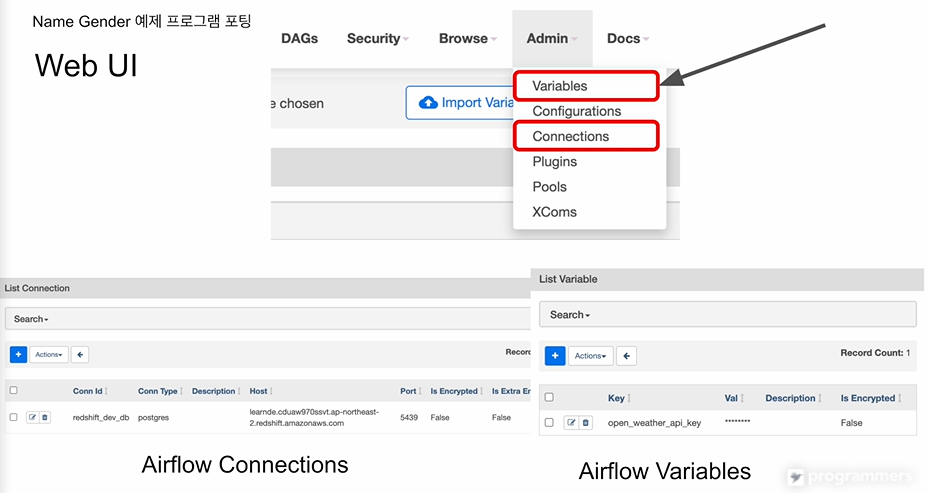
그전에 Connections와 Variable을 설명
get_Redshift_connection이라는 함수 있음. -> 매우 중요한 정보들이 있고, 만에 하나 호스트 이름을 바꾸려면 코드를 들어가서 바꿔야함. 이때 사용할 때 connections임. 환경변수 설정으로 코드 바깥으로 빼줌
다른 예제에서 get_Redshift_connection내부 값을 밖으로 뺄것임
variables csv 링크를 파이썬쪽 함수로 넘겨줌. csv 위치가 바뀌면 코드를 바꿔줘야함. 이것 역시 에어플로 환경설정으로 빼낼수 있는데, 가장 적합한 후보임. variables는 마치 에어플로우를 키밸류 스토리지로 씀. 코드에서 정보를 읽어다가 쓰게됨.
이 두개를 여러 용도로 써볼 예정.
variables을 사용해서 csv url을 하드코딩하지 않고 환경설정으로 빼본다.
이는 웹 UI에 admin 아래 보면 있음.
connections에 가보면
어떤 백엔드이고 호스트는 뭐고 포트는 뭐고
아이디 패스워드
ID를 부여할 수 있음.
코드 안에서는 이런 정보들은 다 감춰지고 아이디만 가지고 코드를 작성하면
에어플로우가 커넥션을 할때는 저 정보를 가지고 쓰게 됨.
variable같은 경우
키 밸류 스토리지.
키에 해당하는 값이 저장이 됨.
내가 쉽게 코드 안에서 읽어올 수 있고
필요하다면 값을 바꿔서 저장
키의 특성에 따라 암호화된게 보임
새로운 varible은 플러스버튼 connection도 마찬가지
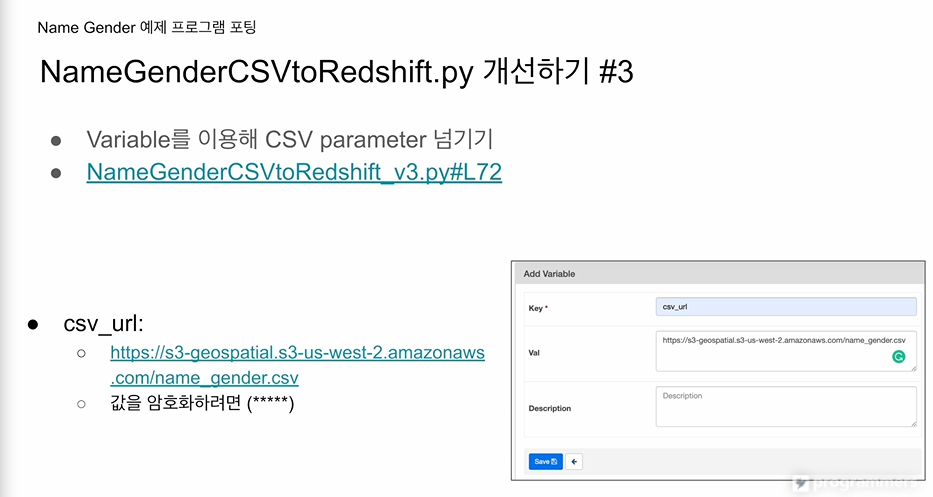
csv 파일을 하드코딩하지 않고
variable을 사용
airflow 코드 안에서 값을 읽어다 쓰는걸로 만들어본다
앞에선 하나의 태스크를 써봤는데 etl을 나누어 별개의 태스크로 만들어봄.
태스크 간의 값을 어떻게 넘길것인가.
하나의 함수때는 명확하게 지정해줄 수 있었음.
한 파이썬 오퍼레이터의 출력이 어떻게 다음 오퍼레이터에 입력이 되는가?
-> Xcom을 사용해서 첫번재 파이썬 오퍼레이터의 출력값이 다음 파이썬 오퍼레이터의 입력값이 되게 함.
그 방법이 갖고있는 장단점을 코드를 보며 설명
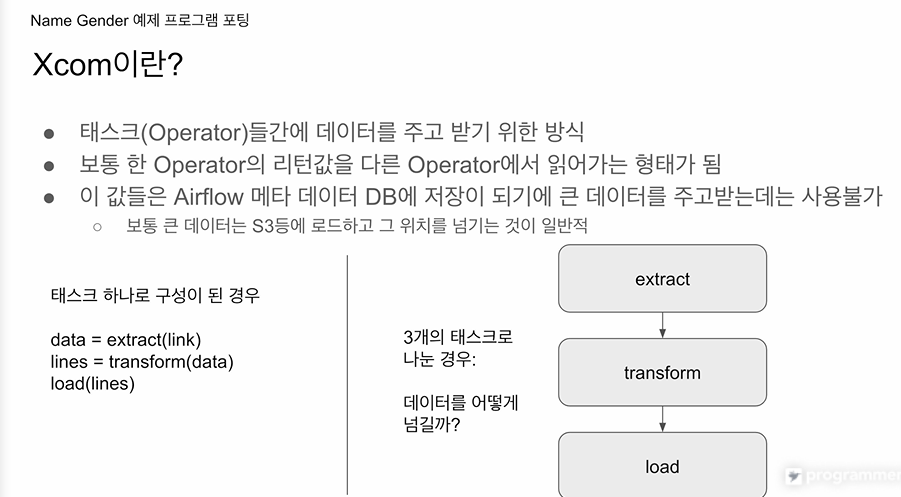
태스크들 간에 데이터를 주고받는 방식
더 정확히는 오퍼레이터 간에 데이터 주고받는 방식
태스크를 하나로 구성하면
그 함수에서
연달아 함수들을 호출하면서 데이터의 주고받음이 명백하고, 조율하기가 쉬웠음.
이걸 세개의 태스크로 나누면
extract -> transform -> load로 데이터를 넘기는지 고민.
Xcom은 에어플로우가 제공하는 기능임.
extract가 리턴한 값이 메타데이터 DB에 저장됨.
Xcom작동 방식: task 아이디를 주고, 리턴값을 달라고 요청.
-> 어느 태스크건 아이디와 함께 리턴값을 메타데이터 DB에 보관하기 때문
데이터가 굉장히 크면 메타데이터 DB에 오버로드를 줄 수 있음.
S3와 같이 굉장이 값이 싼 스토리지 이용
코드
from airflow.models import Variable
키밸류 스토리지 엑세스 때 사용 모듈
2개의 메소드가 있음. get, set
get - 키를 주고 값을 받아옴
set - 키와, 밸류를 주고, 지정한 키에 값을 지정한 밸류로 세팅.
앞단은 크게 달라진 점이 없음.
이번엔 각각이 파이썬 오퍼레이터에 사용될 예정.
def extract(**context):
link = context["params"]["url"]
task_instance = context['task_instance']
execution_date = context['execution_date']
logging.info(execution_date)
f = request.get(link)
return (f.text)
def transform(**context):
logging.info("Transform started")
text = context["task_instance"].xcom_pull(key="return_value", task_ids="extract")
lines=text.strip().split("\n")[1:]
records=[]
for l in lines:
(name, gender) = l.split(",")
records.append([name,gender])
logging.info("Transform ended")
return records
def load(**context):
logging.info("load started")
schema = context["params"]["schema"]
table = context["params"]["table"]
lines = context["task_instance"].xcom_pull(key="return_value", task_ids="transform")
cur = get_Redshift_conncection()
try:
cur.execute("BEGIN;")
cur.execute(f"DELETE FROM {schema}.name_gender;")
for r in records:
name = r[0]
gender = r[1]
sql = f"INSERT INTO {schema}.name.gender VALUES ('{name}', '{gender}')"
cur.execute(sql)
cur.execute("COMMIT;")
except(Exception, pycopg2.DatabaseError) as error:
cur.execute("ROLLBACK;")
logging.info("load done")
dag = DAG(
dag_id = 'name_gender_v3',
start-date = datetime(2023,4,6),
schedule = '0 2 * * *',
catchup = False,
max_active_runs = 1,
default_args = {
'retries': 1,
'retry_delay': timedelta(minutes=3),
}
)
extract = PythonOperator(
task_id = 'extract',
python_callable = extract,
params = {
'url' : Variable.get("csv_url")
},
dag = dag)
transform = PythonOperator(
task_id = 'transform',
python_callable = tranform,
params = {
},
dag = dag)
load = PythonOperator(
task_id = 'load',
python_callable = load,
params = {
'schema': 'keeyong',
'table': 'name_gender'
},
dag = dag)
extract >> transform >> load context는 Airflow에서 제공하는 시스템 변수입니다. context 딕셔너리는 실행 컨텍스트에 대한 정보를 포함하고 있습니다. 이는 여러 키(key)를 포함하며, 여기에는 다음과 같은 키들이 있습니다.
execution_date: 현재 실행의 날짜와 시간 정보가 담겨있습니다.dag_run: 현재DAGRun의 상태를 나타내는 객체입니다.task_instance: 현재TaskInstance의 상태를 나타내는 객체입니다.params:params딕셔너리를 통해 Python 함수에 파라미터를 전달합니다.
따라서, 이 context를 사용하여 DAG의 실행에 필요한 정보를 가져오거나, 작업 간에 데이터를 교환하는데 사용할 수 있습니다. 위에서 보셨듯이, xcom_pull과 xcom_push 함수를 사용하면 작업 간에 데이터를 주고 받을 수 있습니다. context를 사용하는 또 다른 예로는 context['execution_date']를 사용하여 현재 작업이 언제 실행되고 있는지 알 수 있습니다. 이와 같은 방식으로 context는 Airflow에서 매우 중요한 역할을 수행합니다.
context는 Airflow에서 파이썬 함수(PythonOperator를 통해 실행하는)를 호출할 때 자동으로 전달하는 딕셔너리입니다. 이는 시스템에서 자동으로 관리하므로 개발자가 직접 넘겨주지 않아도 됩니다.
Airflow에서는 PythonOperator를 사용하여 호출된 함수가 반환하는 값이 자동으로 XCom에 저장됩니다. 이 값은 'return_value'라는 키로 저장되며, 이를 통해 다른 태스크에서 이 값을 참조할 수 있습니다.
예를 들어, '태스크 A'가 함수를 호출하고 이 함수가 어떤 값을 반환한다면, 이 값은 XCom에 자동으로 저장되며, '태스크 B'는 xcom_pull(task_ids='태스크 A', key='return_value')를 사용하여 이 값을 가져올 수 있습니다.
크게 달라진건 없음.
extract 사실상 동일
transform의 경우 extract의 리턴값이 인자로 들어와야하는데
xcom_pull이라는 함수를 쓰는데, extract 태스크의 리턴값을 읽어와라.
태스크 인스턴스 객체 내엔 xcom_pull이라는 메소드가 있어서 이를 통해 외부 태크크의 값을 가져올 수 있음.
로드도 보면
마찬가지로 트랜스폼의 리턴값을 받아오는 것을 확인할 수 있음.
extract에서
params를 사용해 Variable.get("csv_url")을 외부에서 참조하도록 함.
로드함수가 작업해야되는 최종 데이터 웨어하우스 테이블이 무엇인지.
params를 사용하여 스키마와 테이블로 넘겨주고
load 내부에서 params에서 읽어와서 코드를 구성함.
마지막으로 실행순서는
extract >> transform >> load
테스크 데코레이터를 쓰면 훨씬 간단해짐
오퍼레이터 안쓰고
태스크 데코쓰면 함수가 각각 태스크가 되고,
데이터 주고받는게 훨씬 직관적이게 됨.
xcom_pull이라는 건 이전의 태스크 리턴값을 읽어오냐면, 메타데이터 데이터베이스에 기록된걸 가져온다. 함수 실행이 끝나면 그 함수가 리턴해준 값과 태스크 아이디를 묶어서 DB에 저장해줌. 아무래도 DB는 유한하기 때문에 굉장히 큰 값을 리턴하면 DB가 차버릴 수 있음. Xcom은 굉장히 큰데이터를 주고받는 경우엔 사용할 수 없음. 데이터가 작은 경우 편리하게 주고받기 위해 사용. 굉장히 큰 데이터는 S3에 저장하고 그 링크를 리턴시킴. 이후 그 링크를 받아서, 그 링크에 가서 데이터를 가져오는게 일반적.
