학습주제
4번째 예제.
redshift connection 설정
학습내용

admin -> connections
들어가서 새로만들기
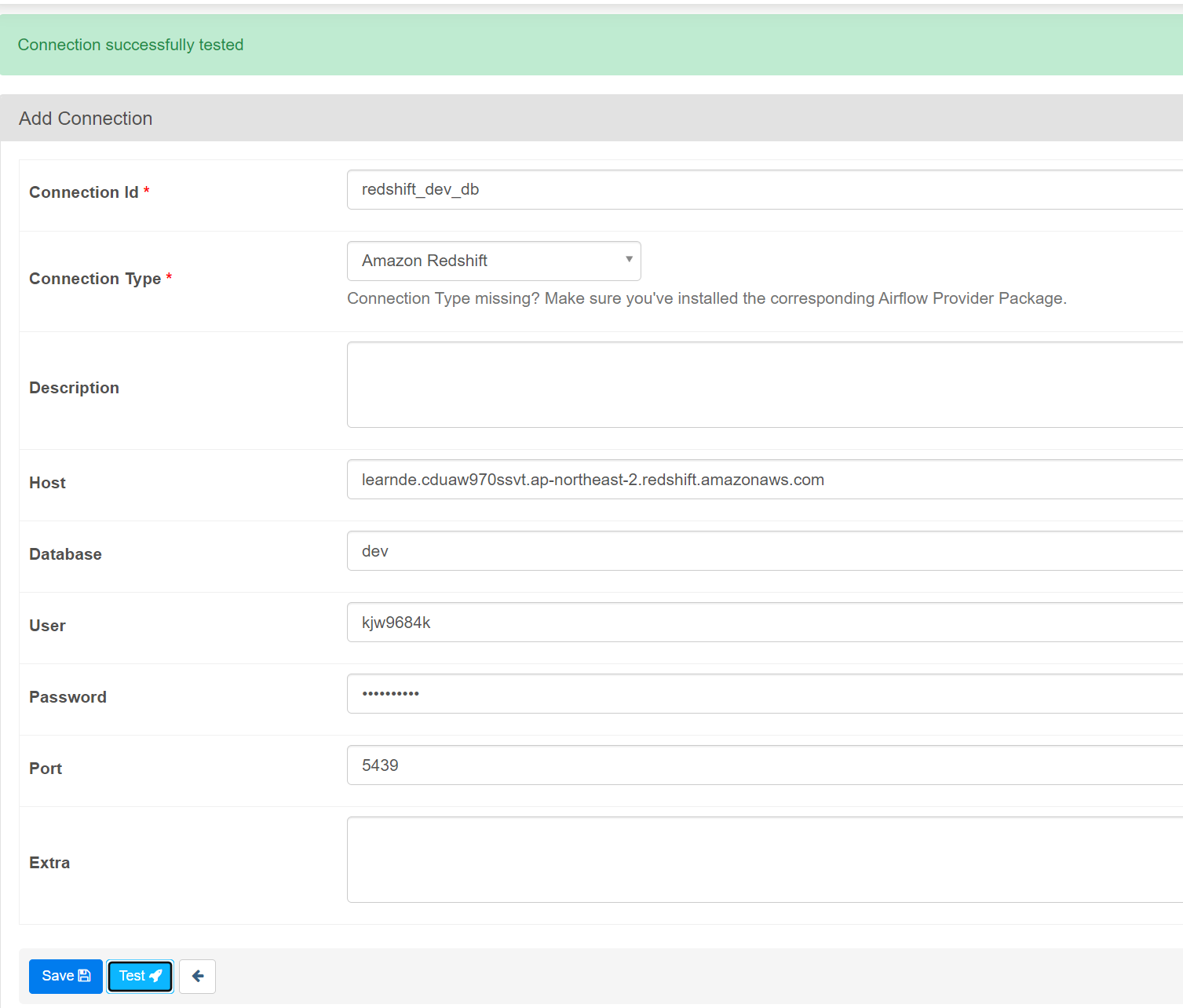
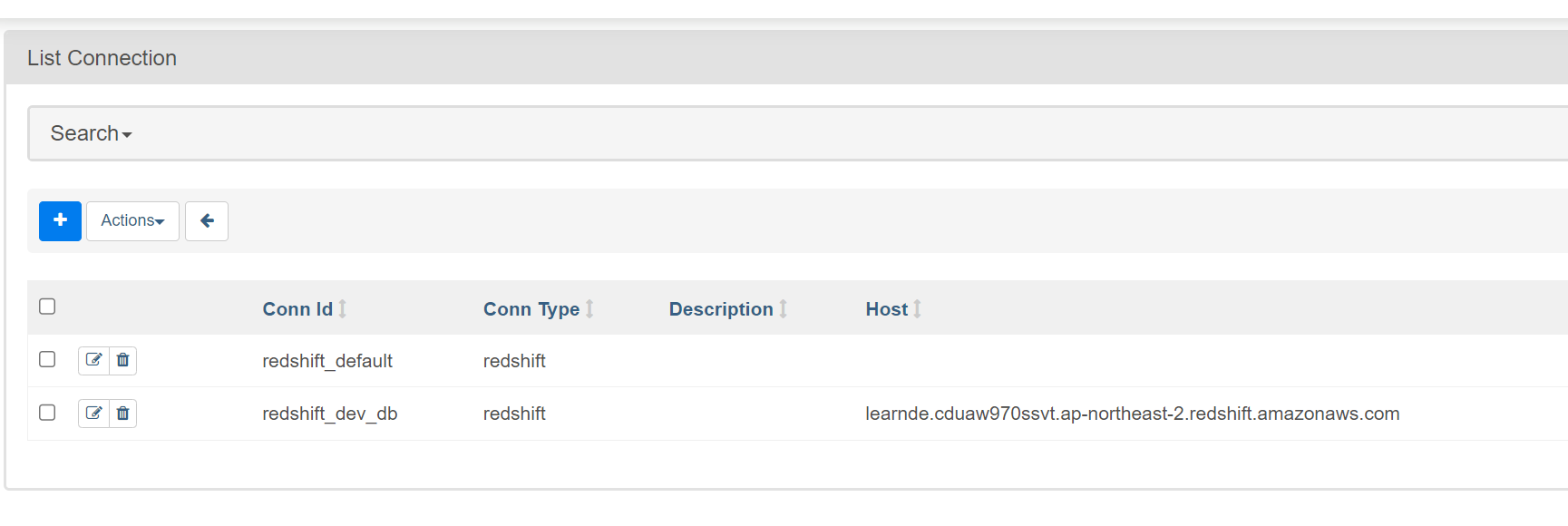
이전 함수에서 get_Redshift_connection 의 값을 그대로 넣으면 된다.
이후 이 커넥션 ID를 사용하면
세팅값대로 연결이 됨.

https://github.com/learndataeng/learn-airflow/blob/main/dags/NameGenderCSVtoRedshift_v4.py
from airflow.providers.postgres.hooks.postgres import PostgresHook
def get_Redshift_connection(autocommit=True):
hook = PostgresHook(postgres_conn_id='redshift_dev_db')
conn = hook.get_conn()
conn.autocommit = autocommit
return conn.cursor()hook이 추가됨. postgres는 지금 사용하는 메타데이터 DB가 postgres라서?
hook을 부르고, 이걸 연결 객체 conn을 받음.
나머지는 동일.
나중의 실습중 하나로
dag 정의 시 default_arg에
'on_failure_callback': slack.on_failure_callback,
모든 태스크에 적용되는 설정, 다른 파라미터가 많지만, on_failure_callback, on_success_callback에 함수 넣어서 호출시킬수 있음
슬랙과 관계된 모듈을 만들어놓고,그 함수를 호출시킴

테스트 데코레이터를 사용함
여기선 xcom 사용할 필요가 없음. 알아서 처리해줌.
태스크 데코레이터를 쓰는경우에는, 파이썬 오퍼레이터 지정 X, 엔트리함수 자체를 태스크로 사용.
https://github.com/learndataeng/learn-airflow/blob/main/dags/NameGenderCSVtoRedshift_v5.py
from airflow import DAG
from airflow.models import Variable
from airflow.providers.postgres.hooks.postgres import PostgresHook
from airflow.decorators import task
from datetime import datetime
from datetime import timedelta
import requests
import logging
def get_Redshift_connection(autocommit=True):
hook = PostgresHook(postgres_conn_id='redshift_dev_db')
conn = hook.get_conn()
conn.autocommit = autocommit
return conn.cursor()
@task
def extract(url):
logging.info(datetime.utcnow())
f = requests.get(url)
return f.text
@task
def transform(text):
lines = text.strip.split("\n")[1:]
records = []
for l in lines:
(name, gender) = l.split(",")
records.append([name, gender])
logging.info("Transform ended")
return records
@task
def load(schema, table, records):
logging.info("load started")
cur = get_Redshift_connection()
try:
cur.execute("BEGIN;")
cur.execute(f"DELETE FROM {schema].name_gender;")
for r in records:
name = r[0]
gender = r[1]
sql = f"INSERT INTO {schema}.name_gender VALUES ('{name}', '{gender}'_"
cur.execute(sql)
cur.execute("COMMIT;")
except (Exception, psycopg2.DatabaseError) as error:
print(error)
cur.execute("ROLLBACK;")
logging.info("load done")
with DAG(
dag_id = 'namegender_v5',
start_date=datetime(2022, 10, 6),
schedule='0 2 * * *',
max_active_runs=1,
catchup=False,
default_args={
'retries': 1,
'retry_delay': timedelta(minutes=3),
# 'on_failure_callback': slack.on_failure_callback,
}
) as dag:
url = Variable.get("csv_url")
schema = 'keeyong'
table = 'name_gender'
lines = transform(extract(url))
load(schema, table, lines)이 스크립트에서 url, schema, table 변수들은 DAG 블록 내부에 정의되어 있습니다. Python에서는 들여쓰기가 중요한데, 이 들여쓰기 덕분에 url, schema, table은 이 DAG 블록의 지역변수로 동작합니다.
그러나 이 변수들은 이 DAG 블록 내에서는 전역 변수처럼 작동하므로, 이 DAG 블록 내의 모든 함수에서 접근할 수 있습니다.
이제 DAG 블록에 대해 설명하겠습니다. DAG 블록은 with 키워드를 사용하여 정의됩니다. with 키워드를 사용하면, DAG의 시작과 끝을 명확하게 표시할 수 있습니다. 또한 이 방법을 사용하면 DAG 내부에서 생성된 모든 태스크는 자동으로 이 DAG에 포함됩니다.
그래서 데코레이터(@task)가 dag 이름을 인식하는 것이 아니라, with DAG(...) 블록 내에 정의된 모든 태스크를 자동으로 해당 DAG에 추가합니다. 이러한 방식은 코드의 가독성을 높이고, 각 태스크를 명시적으로 DAG에 추가할 필요성을 없애줍니다.
마지막으로, DAG 블록 내에 선언된 url, schema, table 등의 변수들은 이 DAG 블록 내의 모든 태스크에서 접근 가능합니다. 이렇게 DAG 블록 내부에 정의된 변수들은 해당 DAG 블록 내에서는 전역 변수처럼 작동하게 됩니다.
with DAG(...) 구문을 사용하면 '닫힌다'는 것은 파일이나 데이터베이스 연결 등의 리소스를 해제하는 것과는 다르게, DAG의 정의가 끝났음을 의미합니다. with 블록이 끝나면, 해당 DAG에 속한 모든 태스크들의 정의가 끝났으며, 이 DAG는 이제 완전히 정의되었다는 것을 의미합니다. 이는 'DAG가 닫힌다'라는 것이 아니라, 'DAG의 정의가 완료되었다'는 것을 의미합니다.
인자들이 파이썬 오퍼레이터레서 필요했던 'context', 'params'를 쓰지 않고,
대그 변수를 그대로 넘겨줌.
밑에 가보면 with 아래에 url, schema, table이 선언됨. 보면 태스크 호출하는거 같지 않고, 함수 호출하는것처럼 보인다.
뭔가 내가 태스크를 만든다는 느낌이 안들게 됨. 이유는 태스크 데코레이터를 사용했기 때문. 앞으로 요 태스크 데코를 사용할 예정. 항상 쓸 필요는 없음. 내가 파이썬 오퍼레이터를 써야한다면 저걸 쓰고, 기존 오퍼레이터를 쓴다면 태스크 오퍼레이터를 쓰지 않음.

버전을 실행시켜보고,
웹 UI로 하겠지만 CLI로 시연시켜봄
5개의 파이썬 코드, 대그를 셋업했던 도커의 dags 폴더에 복사해본다.
그 폴더는 에어플로 셋업 밑에 dags 폴더임
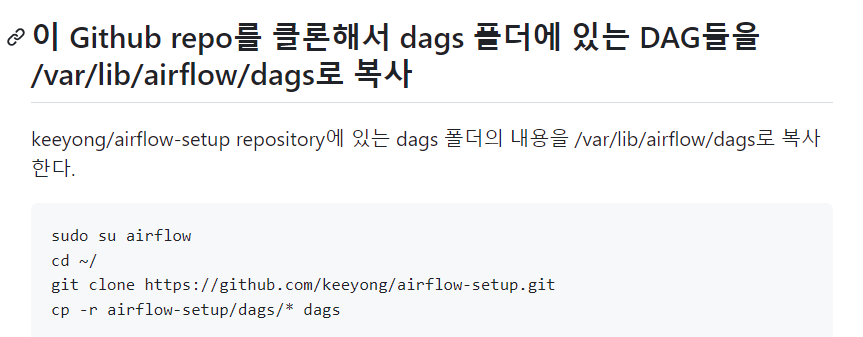
airflow-setup로 이동해 ls -tl실행시키면
dags 폴더가 보인다
이 밑 파일들이

도커에서 사용하는 파일들임.
그게 있는 리포를 복사해온다
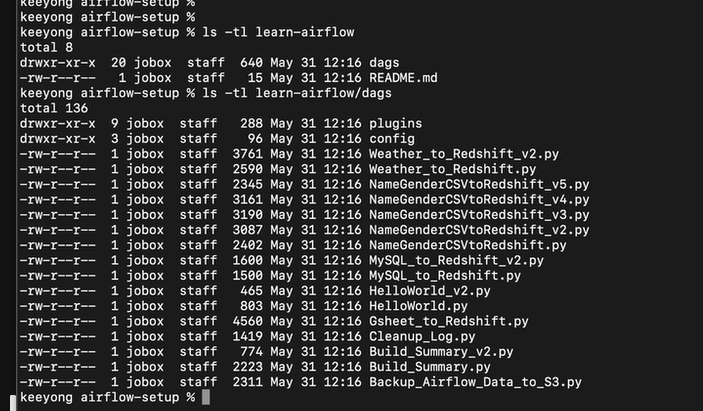
파일들도 있지만 서브 폴더들도 있다 (깃허브)
다같이 카피를 해본다.
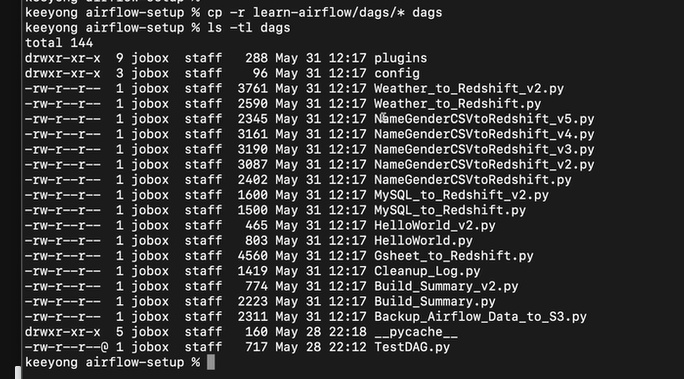
이걸 dags 폴더로 옮겨준다
aws는 방법이 조금 다른거 같음
cp -r learn0airflow/dags/* dags/
-r옵션은 리컬시브하게 서브폴더까지 이동
ls -tl dags를 보면
파일이 복사된 것을 확인할 수 있다.
https://github.com/keeyong/airflow-setup/blob/main/docs/Airflow%202%20Installation.md
git clone https://github.com/learndataeng/learn-airflow
을 복사해온다
나도 복사 성공함. 디렉토리가 도커랑 좀 다르지만 적당히 적용하면 가능함
도커로 돌아가서 웹서버(에어플로우) 를 다시 띄워보기로 한다
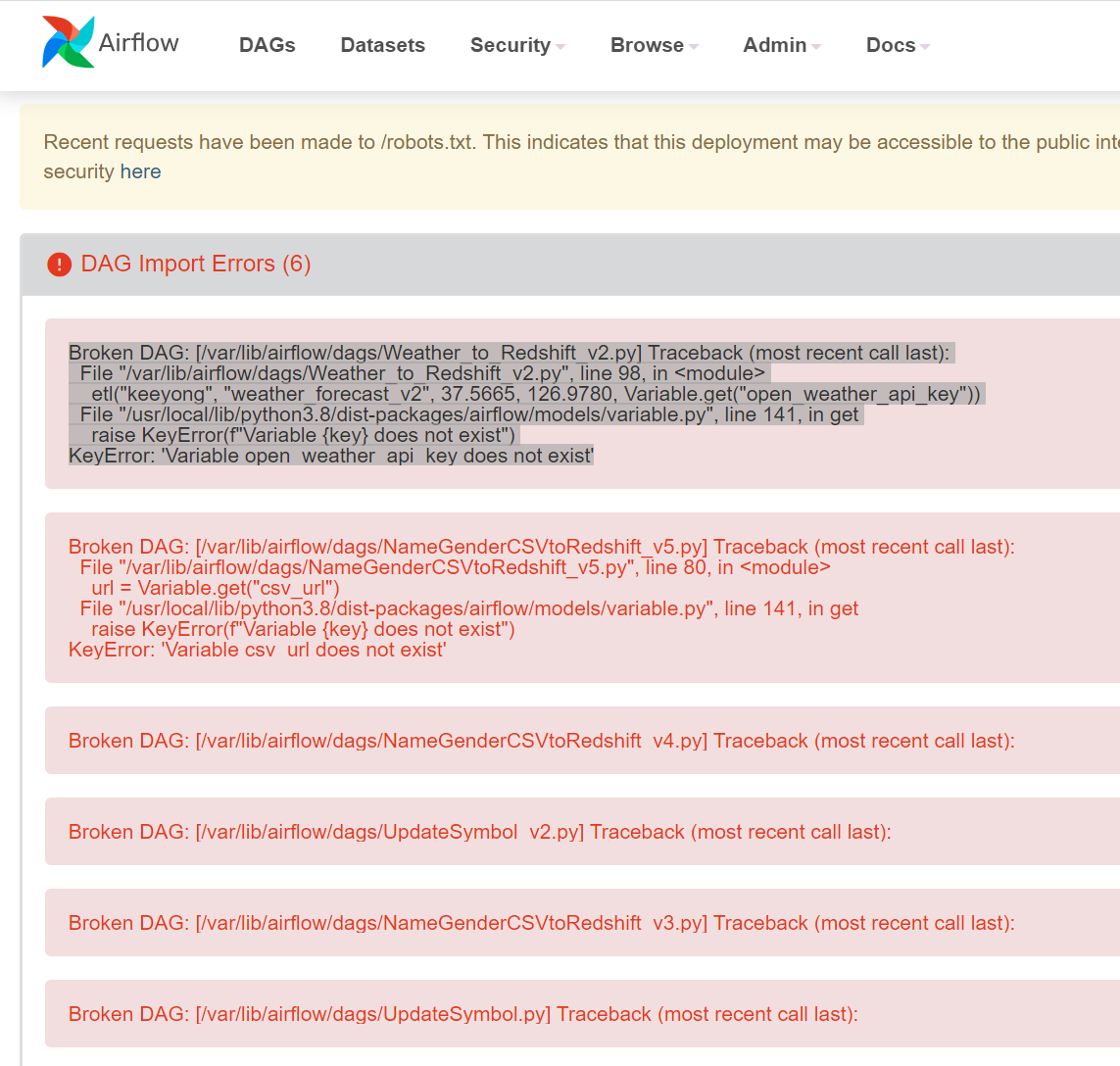
웹서버가 돌아가는 화면이 보일 것이다
8080포트로 접근하면 된다.
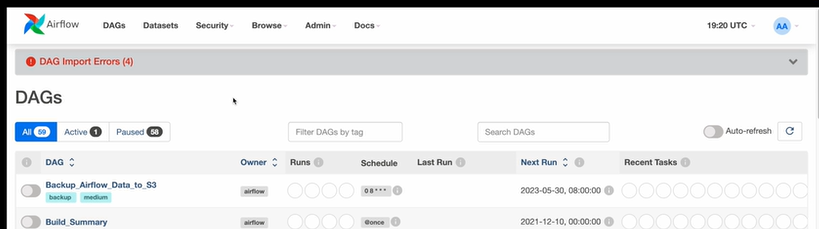
나의 경우 에러가 났다
아 강사님도 동일한 에러가 났구나
제공된 오류 메시지를 보면 'Variable open_weather_api_key does not exist'라는 에러가 발생했습니다. 이는 Airflow에서 사용하는 'open_weather_api_key'라는 변수가 정의되지 않았다는 것을 의미합니다.
이 변수는 Airflow의 웹 인터페이스에서 'Admin' -> 'Variables' 메뉴를 통해 설정할 수 있습니다. 여기에서 'Key' 필드에 'open_weather_api_key', 'Val' 필드에 해당 API 키 값을 입력하고, 'Save' 버튼을 클릭하여 변수를 저장합니다.
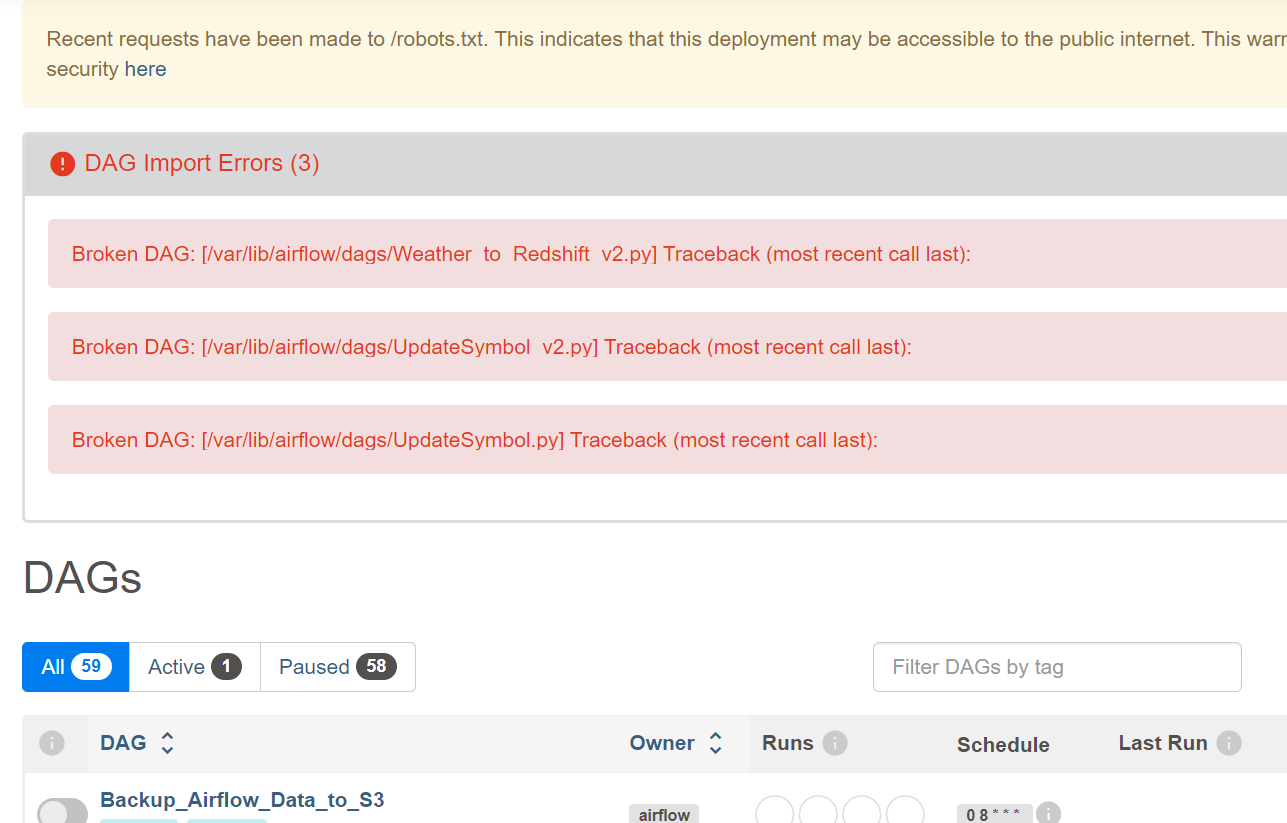
응? 대그들이 실패했나봄.
다시 확인해보자
connections와 variable이 안된거 같은데?
현재 name_gender, name_gender_v2는 가능해야함.
정상적으로 들어옴
에러는 정상임.
버전 v3 ~v5까지를 해결해본다
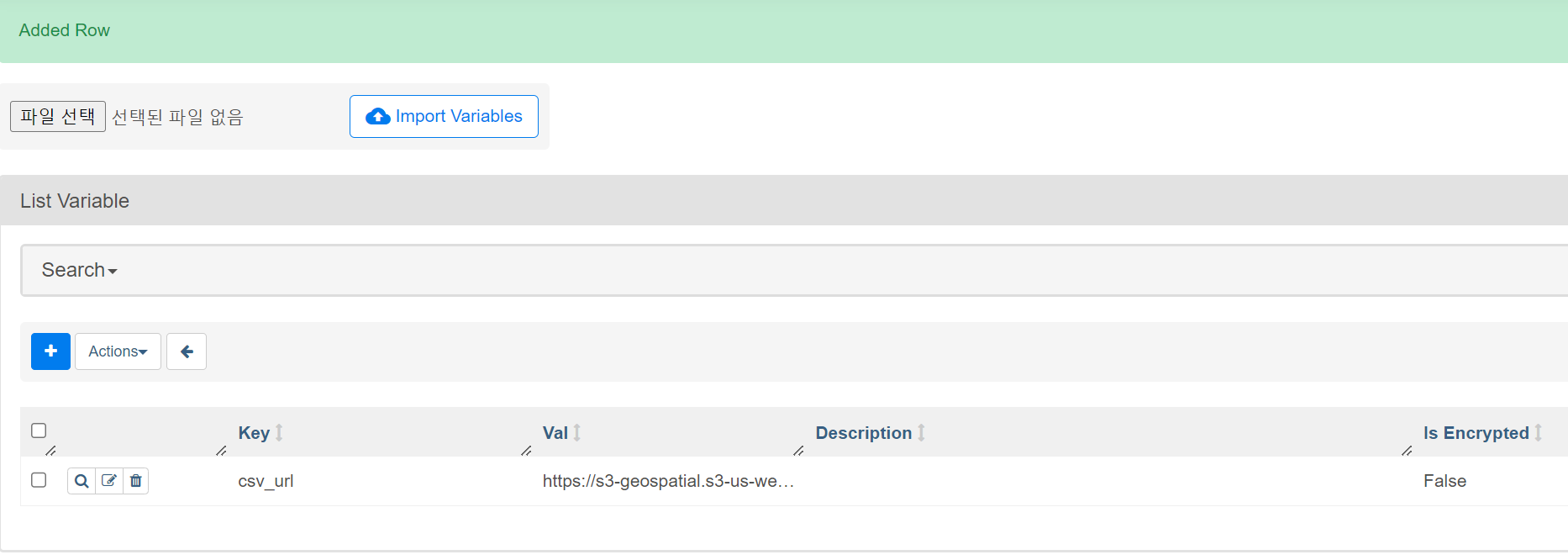
admin-variables로 이동
csv_url이 등록되어야 함
값으론 s3 csv 파일 링크를 복붙.
다시 대그로 돌아와서
조금 시간이 지나면 (5분에 한번씩 스캔함(
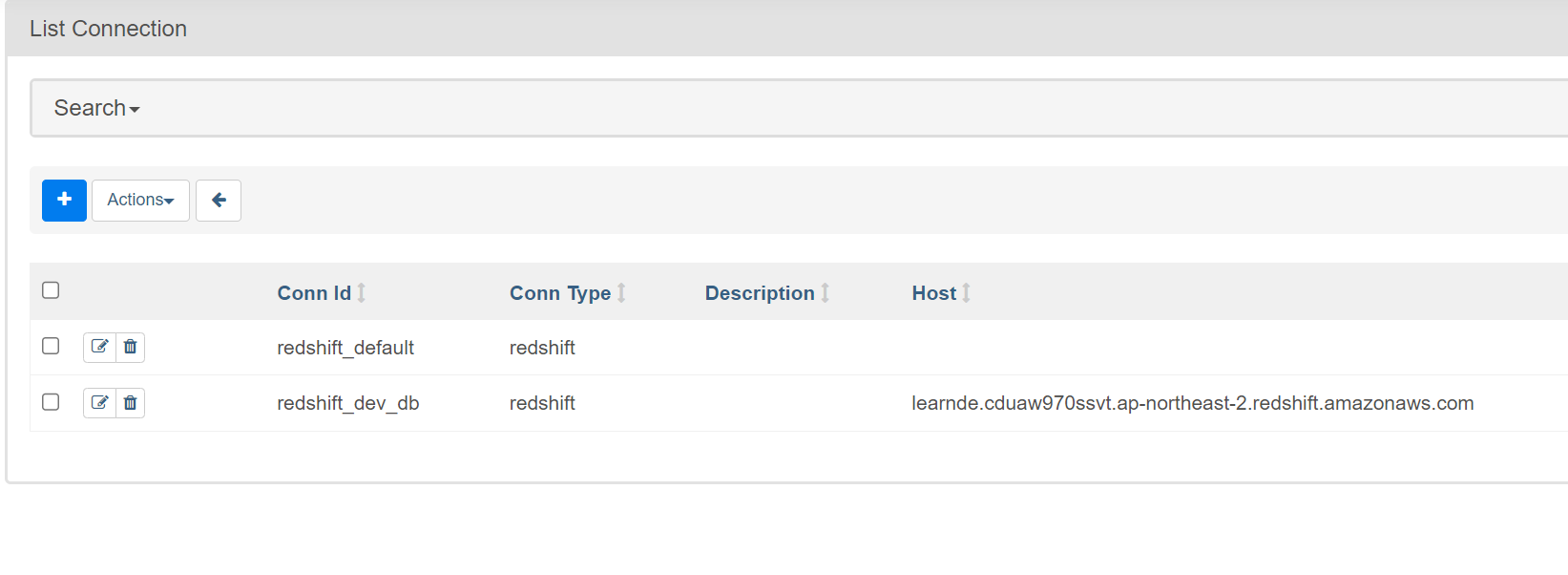
그 사이에 admin - connections
새로 하나 추가
기존에 추가했었음.
postgres 선택해도 동일 동작함.
호스트는 수업자료
database db
user id는 수업때 제공
password 받았던 내용
업데이트 되었음
버전 5까지 제대로 등록이 되었다
v2 부터 활성화시도
v2는 태스크 하나임
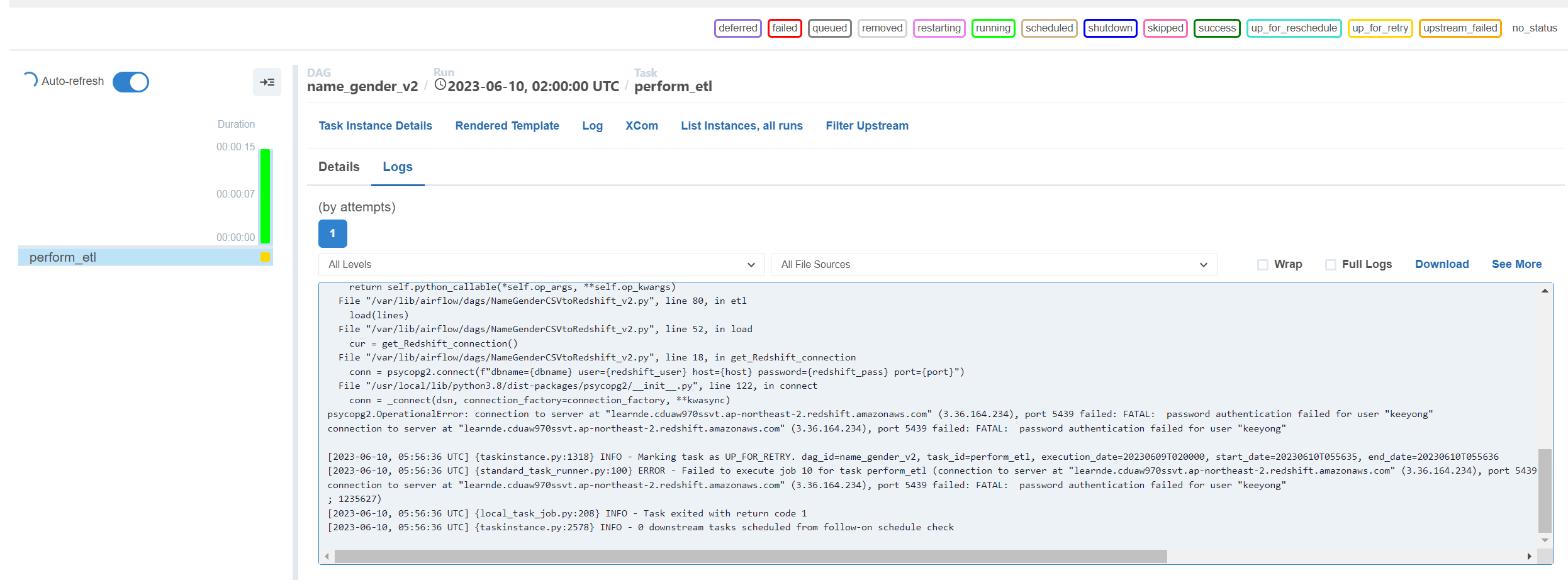
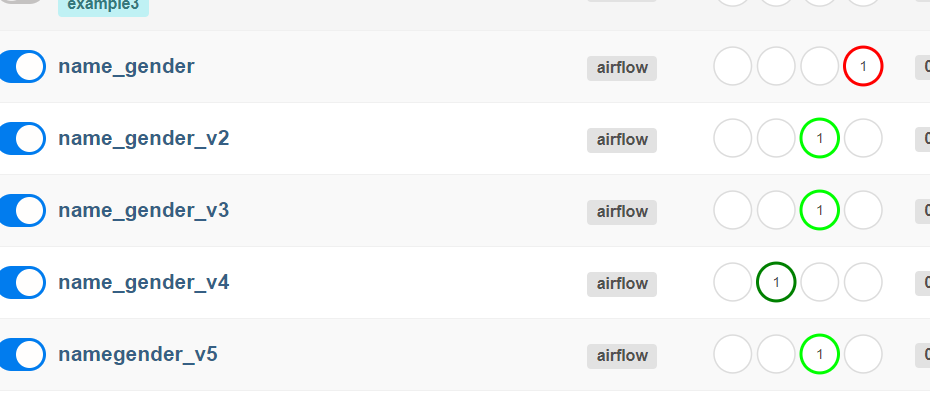
코드가 실패함.
이 코드자체는 패스워드를 넣지 않았기 때문에 실패.
이후 get_redshift_connection에서 connections에서 id pw 제대로 된건 동작할 예정
v4 돌려본다
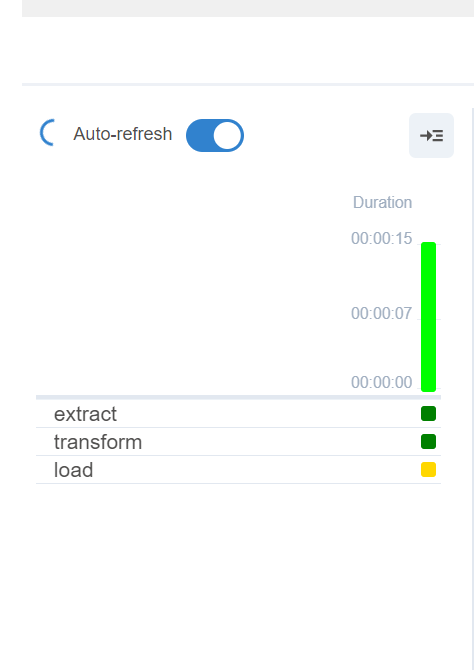
잘 돌아간다
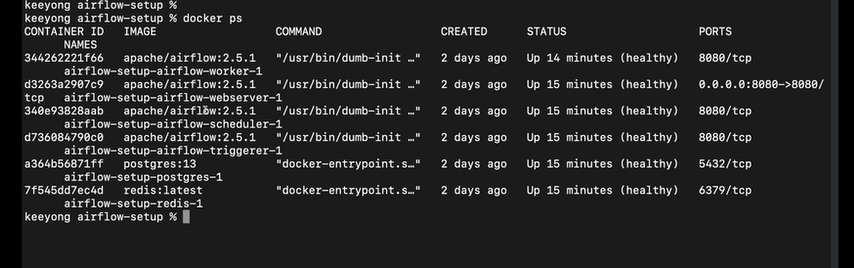
세개의 태스크
함수의 이름이 그대로 태스크 id가 됨
웹 UI를 통해 간략하게
admin에서 variable, connection 세팅
대그 활성화, 로그 명령어를 확인했다
이제 CLI로 구현
docker ps명령어를 실행하면 현재 실행중인 컨테이너 목록이 보인다
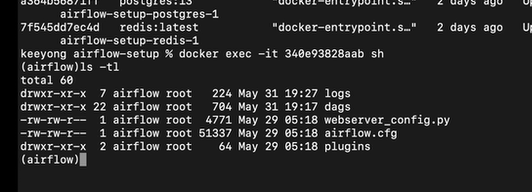
스케줄러의 컨테이너 아이디를 복사. 이 안으로 로그인 해야함
docker exec -it 스케줄러아이디 sh
이러면 스케줄러 안으로 로그인
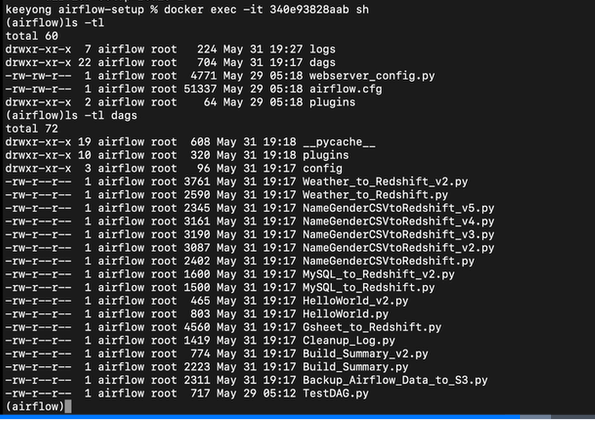
대그스 폴더가 보인다
폴더 안의 내용을 보면
아까 파일과 여기가 싱크된 것임.
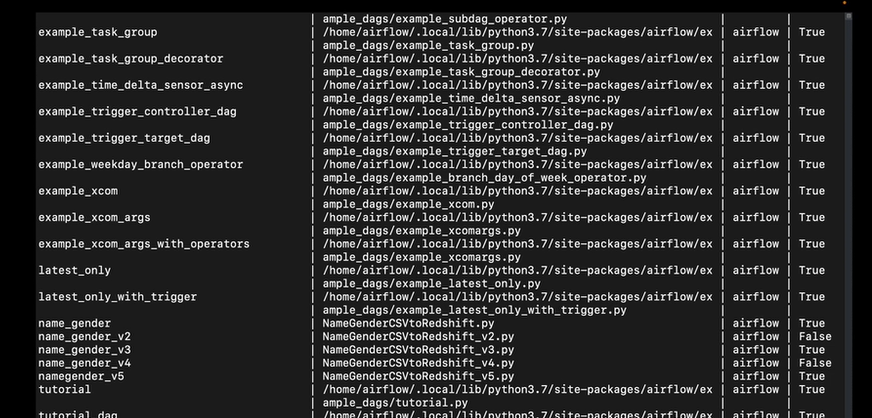
airflow dags list

aws의 경우 우분투에 바로 설치했기 때문에 airflow 명령어 바로 쓰면 된다. (주의 suso su airflow)
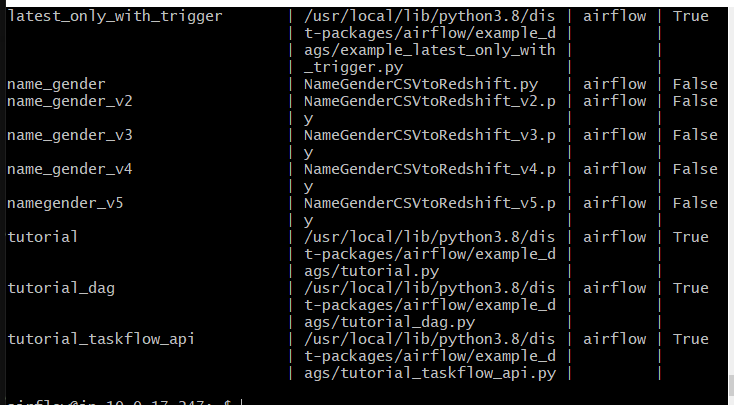
airflow taskss list namegender_v5
이런식으로 태스크 목록이 뜬다
앞에서 우리가 에어플로우로 connection, variable을 만들었는데
CLI도가능
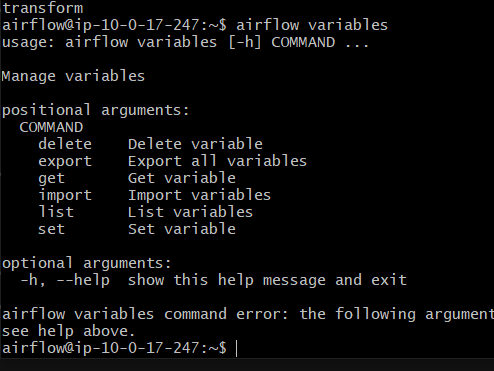
airflow variables
어떤 명령어를 줄 수 있는지 보임
list를 한번 보자
airflow variables list

키를 갖고 읽어올 수도 있음
airflow variables get csv_url

JSON 형태로 엑스포트도 할 수 있음. 백업할 수 있음
이어서
에어플로우로 코딩하다보면 많이 나오는 질문들이 있음.
질문

postgreshook을 사용했었음
레드쉬프트 커넥션 정보를 에어플로우 커넥션스 오브젝트로 만듦. 환경설정으로 만들고 ID를 가지고 데모에서 사용함
hook을 임포트. 그 모듈의 인스턴스를 사용해 레드쉬프트를 접근했었음.
오토커밋이, 포스그라스훅의 디폴트는 False. 자동 커밋 안함. 모든 쓰기작업은 명시적으로 COMMIT, END를 해야 물리 테이블에 쓰여짐. 그 경우에 SQL BEGIN은 어떤 영향이 있는가? 오토커밋이 FALSE이면 BEGIN은 아무 영향을 미치지 않음.

태스크를 얼마나 분리하는게 좋을까
장단점이 있음. 적당히 밸런스 있게.
오래걸리는 태스크일 경우, 중간에 에러가 날 경우 처음부터 다시시작해야함.
오래 걸리는 태스크를 세개로 분리할 수 있으면, 태스크 3번이 실패한 경우, 1,2는 성공했기 때문에 이 실패한 부분만 재실해주면 되기에 이점이 있음. 모듈화가 되기 때문에 코드의 가독성이 더 좋아짐. 너무 잘게 나누어 많은 태스크를 가지면, 각 태스크들이 스케줄러에 의해 스케줄이 되어야 하고, 스케줄 되는데 오래 걸릴 수 있고, 스케줄러에 부하가 많이 가게됨. 일반적으로 생각하는 기준은, 태스크의 수를 너무 늘리지 않되, 재실행 이슈가 발생했을 때 재실행 시간을 줄일 수 있는 관점에서 접근.

variable을 언제?
SQL을 airflow variable로 관리하는 경우 있음
코드를 매번 푸시하기 귀찮으니, airflow variable로 뽑아놓고 고쳐서 쓰겠다.
나쁜 방법은 아님. 그러나 굉장히 크리티컬한 SQL이라면 어느정도 테스트를 하고 airflow variable로 붙이는 습관이 좋음. 기록을 남겨놔야 나중에 디버깅하고 이슈를 해결할 수 있음.
코드 형태로 관리하면, 코드변경이 깃헙에 기록이 되고, 언제 누구에 의해 변경되었는지 확인할 수 있음. 장단점있음
굉장히 중효한 코드라면 variable에 넣지는 않을것 같음
숙제.
airflow.cfg ec2에서 설치할 때는 직접 수정했었음.
이것들을 풀어서 숙제로 제출.
1.DAGs 폴더들은 어디에 지정. 키가 있음.
2. csv url 정의가 안되어 있어서 에러나면 에어플로우가 바로 알지 못함. 5분마다 들여다 봄. 이것도 키가 있음.
3. 에어플로우를 API로 외부 노출하고 조작할 수 있음. 어센티케이션을 수정해야함. 어느 키인지? 나중에 실제로 API로 조작해보는 실습을 할 예정
4. variables를 보면 어떤 단어가 들어가 있느냐에 따라 인코딩, 되지 않기도 함.
5. 환경설정이 수정되면 이를 실제로 반영하기 위해서 해야하는 일은?
6. 메타데이터 데이터베이스가 있는데 이를 암호화하는데 사용되는 키는?
- [core]의 dags_folder = /var/lib/airflow/dags
- [scheduler]# How often (in seconds) to scan the DAGs directory for new files. Default to 5 minutes.
dag_dir_list_interval = 300 - 모르겠음
- [API] enable_experimental_api = False 이하 값 변경.
- 도커의 경우 docker compose down, docker compose up --build, aws의 경우 airflow webserber -D, airflow scheduler -D
6.# Secret key to save connection passwords in the db
fernet_key =
