학습주제
Redshift 기타 서비스
학습내용

- Redshift Spectrum(s3 큰 파일을 외부 테이블로 사용할 수 있게함)
- Redshift Serverless
- Athena (별도 서비스. 스펙트럼과 많은 유사성이 있음.) 아파치 프레스토
- Redshift ML
아파치 프레스토는 오픈 소스 분산 SQL 쿼리 엔진입니다. 이는 대량의 데이터를 처리하고 분석하기 위한 고속 및 확장 가능한 도구입니다. 프레스토는 대용량 데이터 웨어하우스와 데이터 레이크에서 작동하며, 복잡한 분석 작업을 수행할 수 있습니다. 프레스토는 ANSI SQL을 지원하며, 다양한 데이터 소스에 연결할 수 있는 플러그인 아키텍처를 가지고 있습니다. 이를 통해 프레스토는 다양한 데이터 형식과 데이터베이스 시스템과의 상호 운용성을 제공합니다. 또한 프레스토는 확장성이 뛰어나며, 클러스터 환경에서 여러 노드를 활용하여 높은 성능을 달성할 수 있습니다. 이러한 특징으로 인해 프레스토는 대규모 데이터 분석 및 쿼리 작업에 널리 사용되고 있습니다.
Athena는 분산 SQL 쿼리 엔진으로 작동하며, S3에 저장된 데이터를 쿼리할 수 있습니다. Athena는 SQL을 사용하여 데이터를 질의하고 분석할 수 있는 간단하고 직관적인 인터페이스를 제공합니다.

별도의 사인업, 서비스 세팅이 필요하지 않음
AWS Athena는 완전히 관리되는 서버리스 쿼리 서비스로, 데이터를 Amazon S3에 저장된 파일로부터 직접 쿼리할 수 있습니다. 즉, Athena는 S3에 저장된 데이터를 쿼리하기 위한 엔진입니다. Athena는 SQL을 사용하여 데이터를 쿼리하고 분석할 수 있는 간단하고 직관적인 인터페이스를 제공합니다. Athena는 필요한 시기에 필요한 만큼만 쿼리를 수행하여 비용을 최적화할 수 있는 장점이 있습니다.
반면에 AWS Spectrum은 Amazon Redshift 데이터 웨어하우스 서비스와 함께 사용되는 기능입니다. Spectrum은 Redshift 클러스터에서 실행되는 엔진으로, Redshift 클러스터의 데이터에 대한 쿼리 작업을 수행합니다. Spectrum은 Redshift 클러스터 내부에서 S3에 저장된 데이터에 대한 쿼리를 실행하므로, Redshift와 S3 간의 통합 쿼리 기능을 제공합니다. Spectrum은 Redshift와 연계하여 데이터를 분석하고 처리할 수 있는 기능을 제공합니다.
같은 지역의 S3, 클러스터가 있으면 같이 사용.
S3 데이터가 있는 경우, redshift 로 로딩 하지 않고, s3에서 확장테이블 처럼 쓸 수 있음.
s3 큰 데이터와, redshift와 조인 연산 가능
데이터 레이크 - S3 정보를 처리할 수 있는 기능을 레드쉬프트에 구현-> 스펙트럼
외부 데이터는 큰 테이블 - Fact 테이블
크기가 작은 테이블 - dimension 테이블
1TB 스캔할 때마다 5불 씩 과금
레드쉬프트 클러스터가 있으면 언제든 사용하고 과금하면 됨.
제약점. 그파일이 있는 s3 지역과 클러스터 지역이 같아야 함.

그냥 레드쉬프트 클러스터 -프로비전드 클러스트 (고정비용)
서버리스 - 가변비용. 쓴만큼 돈이 나가는 모델.
안써도 테이블을 적재해놓으면 돈이 빠짐
스토리지, 컴퓨팅 자원이 별개로 들어감
- 가변비용을 사용하는게 좋음. 스케일러블 하기 때문. 다만 비용 예측이 어려움
아테나

프레스토를 서비스화, 스펙트럼과 비슷한 기능.
비구조화 된 파일을 처리하는데 유용
비용모델도 비슷함.
레드쉬프트 안쓸 때 아테나를 사용
퍼포먼스는 조금 더 좋음
ML
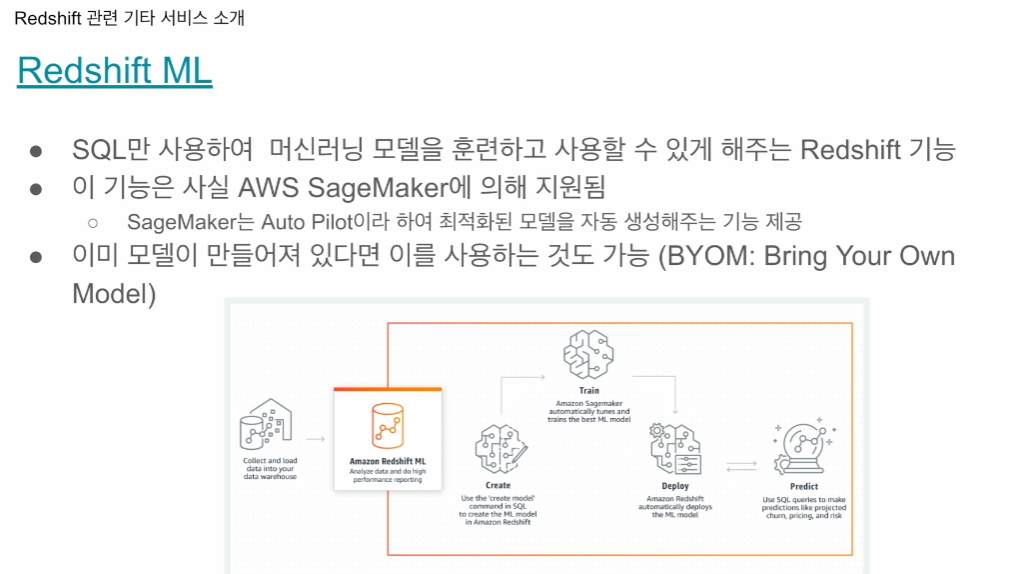
sage maker 와 연동됨 - 머신러닝 모델을 빌드, 배포 등 end-to-end 프레임워크
훈련데이터를 로딩을 하면, 알아서 머신러닝 모델을 찾아주고 세팅해줌.
- 지도기계 학습에 적용
- 예측값 분류, 회귀에 따라 알아서 분류해줌.
- 초매개변수도 설정해서 보여줌.
- 몇시간 하루 이상 돌릴 수도 있음(비용이 많이 나갈 수 있음)
sagemaker 모델을 만들었다는 전제 하에, SQL함수처럼 임베딩해서 테이블 레코드, 컬럼들을 인풋으로 제공, 그 결과가 아웃풋으로 나오는 형태로. 추론 예측을 실행시킬 수있음.
아에 모델 트레이닝까지 시켜볼 수 도 있고, 기존 모델을 가져다 쓸 수도 있음.
