학습주제
DW에서 PK Uniqueness 보장하기
학습내용

풀리프레쉬 -> 인크리멘탈 업데이트 바꿔봄

하나의 레코드를 지칭할 수 있는 방법이 필요해짐
그 때 하나의 필드를 PK. 상황에 따라 여러 필드를 묶어서 사용도 가능
어떤 필드를 PK로?
두가지 방법으로 지정
필드 옆에 어트리뷰트로 지정
product_id INT PRIMARY KEY,
PRIMARY KEY (order_id, product_id)
두개의 필드를 가지고 하나의 레코드를 지칭하게끔 함.
컴포짓 키라고도 함.
저렇게 키를 잡으면
하나가 포린 키가 되기도 함. Foreign key는 다른 테이블에서 PK를 이 테이블에서 사용하는 경우
FOREIGN KEY (product_id) REFERENCES products (product_id)
주문마다 여러개의 제품 id가 생성될 수 있음.
포린키를 보면
CREATE TABLE products (
product_id INT PRIMARY KEY,
name VARCHAR(50),
price decimal(7,2)
);sql optimizer가 쿼리를 최적화 할수 있음.
데이터 정합성이 깨졌을 때 체크해주기도 함.
foreign key는 적어줄 수록 좋은 정보라고 생각됨.
필드, 필드 집합을 테이블 생성시에 PK로 지정.
관계 데이터 시스템이 전체 레코드에서 유일함을 보장해줌.
나는 걱정 하지 않고 적재하고, 중복 케이스가 보이면 관계형 데이터베이스가 INSERT를 실패시킴. 그리고 PK가 깨졌다는 에러를 내게 됨.
DW는(빅데이터기반) PK uniqueness를 보장해주지 않음.
? 왜 보장을 해주지 않는지
그럼 엔지니어로써 어떻게 보장할 수 있는지.
인크리멘탈 업데이트에서 중복을 제거하고 PK 유니크니스를 보장해본다.
유제 테이블에는
이메일 필드를 PK로 쓰는 경우가 있음.

지켜주려고 하다보면 레코드가 엄청나게 많은데, 모든 레코드들을 B+ 트리같은걸로 메모리에 올려놓고 Look up을 함. 체크를 매번 해야함. 엄청나게 시간이 많이 들어감. 체크를 하기 위한 효율적인 데이터 구조를 만들어야 할 상황이 놓이기에 메모리 리소스도 많이 잡아먹음.
OLTP 같은 프로덕션 DB는 PK 유니크니스를 보장해주는게 꼭 필요하지만 일반적으로 데이터 크기가 적음. 대용량을 적재할 일이 많이 없음.
DW 는 보통 큰 데이터를 적재함. 그때마다 이미 키가 있는지 체크하게 된다면 엄청나게 비효율적. 이걸 보장해주는건 엔지니어, 분석가가 할 일.
분석가 - ELT 할때 PK 유니크니스 보장
CREATE TABLE keeyong.test (
date date primary key,
value bigint
);
INSERT INTO keeyong.test VALUES ('2023-05-10', 100);
INSERT INTO keeyong.test VALUES ('2023-05-10', 150);일반적인 경우
같은 값을 연달아 적재할 경우,
두번째가 실패함.
DW경우, 레드쉬프트, 하둡기반 하이브, 프레스토 경우 성공함
PK 유지 방법

테이블은 저번에 만든걸 사용
date에 primary key를 걸어둠
created_date 을 만들어둠. GETDATE() 을 디폴트로 부여함.
OPEN API. 오늘 호출하면 앞으로 8일간 정보를 가져옴. 날짜가 가져와질수록 더 정확한 날씨가 예측이 될 것임. 오늘 API를 호출을 했다면, 오늘부터 8일까지의 날씨정보 리턴. 내일 호출하면 또 8일간의 날씨정보가 리턴될 것임.
오늘 내일 연달아 호출하게 되면 일주일 간의 정보가 중복이 될 것임. 그 경우 언제 어떤 정보를 우선시할지가 중요해짐. 이 때를 created_date을 참고할 예정.
5월 30일에 요청했다면 created_date에 저장.
5월 30일 부터 8일간의 레코드 저장.
5월 31일에 요청했다면 created_date에 저장
풀리프레쉬는 기존 테이블을 날리지만, 인크리멘탈 업데이트의 경우 기준 레코드에 새로 읽어온 8개를 적재하고, 그 안에서 중복제거를 할 예정.
이 때 created_date을 사용할 예정.
하나의 날짜에 대해 두개의 레코드가 존재하게되어 PK uniqueness가 깨지게 됨.
이 때 어느 레코드를 우선해서 중복을 제거할 것인가?
created_date가 최신인 레코드를 우선시하겠다. 날씨예보는 날짜가 가까워질수록 더 정확해지기 때문.
따라서 date 가 중복이더라도 created_date을 기준으로
이런식으로 PK가 유일함을 보장한다.
SQL 문법으로 ROW_NUMBER 사용
윈도우 함수임.
편의상 date, created_date, temp가지고
date은 값이 하나만 존재해야하지만 그게 지켜지지 못함.
created_date 최신일수록 해당 값을 더 신뢰
1일의 경우 3일
2일의 경우 가장 최신인 4일
temp 값이 다른 것을 볼 수 있다.
최종적으로 6개의 레코드에서 2개의 레코드만 뽑아내고 싶음.
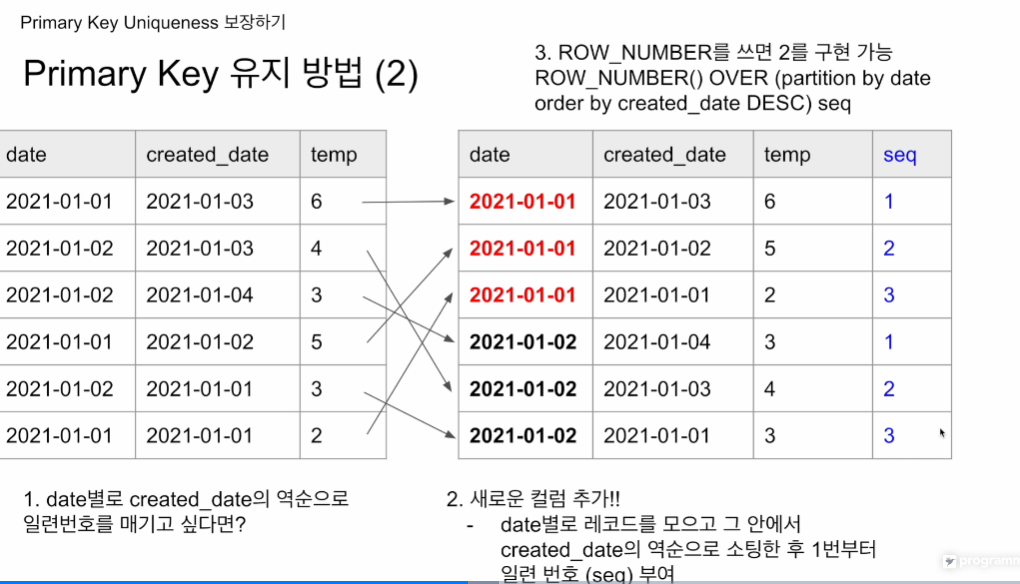
- date 별로 모아서 created_date의 역순으로 일련번호를 매기고 싶음. 그 일련번호를 매기고 1번인 것만 선택을 하면 최종적으로 중복이 제거됨.
- date 끼리 그룹핑
- created_date이 큰 것부터 내림차순
- seq라는 컬럼이 생김. 순차적으로 연번 부여
ROW_NUMBER() OVER (partition by date order by created_date DESC) seq
구체적으로 문법을 살펴보면 저렇게 선언 OVER 뒤에 문법()
ROW_NUMBER - 일련번호 붙여라 - 필드이름은 seq. OVER 다음에 어떤 기준으로 붙일지
- partition by: 어떤 필드를 기준으로 레코드를 그룹핑 할 것인지.
- order by: 묶인 그룹 레코드들을 어떤 순서대로 일련번호를 붙일 지.
오른쪽에 보면 seq가 생성된 것을 보이고, 값이 1인 것들만 챙기면 PK 유니크 챙기고, 중복 제거 가능함.

조금 더 일반화한다.
대상 테이블이 있고, 새로운 데이터 적재, 인크리멘탈 업데이트
- 임시 테이블을 만들고 현재 모든 레코드를 복사
- 임시 테이블에 새로운 데이터를 적재
- 중복 존재 가능- 예전 애플 주식정보도 동일한 방법으로 사용했었음. 그때는 DISTICNT를 사용해서 중복제거를 했었음. 만일 앞단에 데이터가 잘못 입력될 경우, DISTINCT 적용이 안될 수 있음. (위험요소 있음)
- 임시테이블에 ROW_NUMBER()을 PK로 partition을 잡고, order by 보통 타임스탬프 필드를 DESC 수행. pk 별로 한개의 레코드 잡기.
- 현재 중복제거한 임시테이블을 원본테이블로 복사

코드를 가지고 확인해본다
CREATE TEMP TABLE t AS SELECT * FROM kjw9684k.weather_forecast;
- 원래 테이블 내용을 임시테이블 t로 복사 CTAS
새로운 데이터(DAG)를 t라는 임시테이블에 적재함 - t에는 pk 기준으로 중복 데이터들이 존재 가능
DELETE FROM kjw9684k.weather_forecast;로 원본 테이블의 모든 레코드들을 삭제함.

중복을 없앤 형태로 새로운 테이블
INSERT INTO kjw9684k.weather_forecast
SELECT date, temp, min_temp, max_temp, created_date
FROM(
SELECT *, ROW_NUMBER() OVER (PARTITION BY date ORDER BY created_date DESC) seq
FROM t
)
WHERE seq = 1;SELECT * 을 하지 않음 seq 따라가면 안되기 때문
4개의 작업 중 어떤 걸 트랜잭션으로 묶어야할까?
다 묶어줘도 되고, 정합성이 깨질 우려가 있는 곳은 3, 4번임. 하나의 트랜잭션으로 오토 커밋이 True인 전제 하임. False는 이렇게 묻는게 의미가 없음.
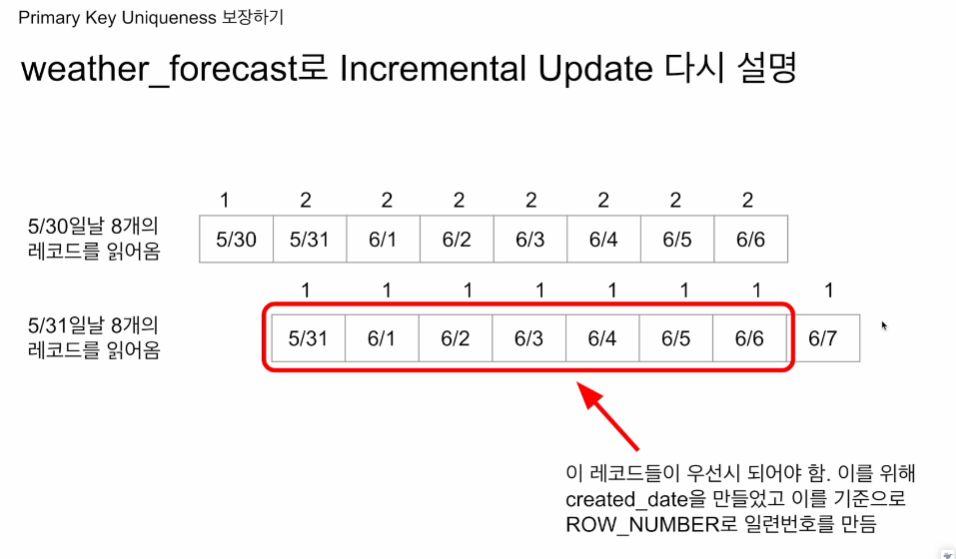
날짜 위 숫자는 우선순위에 따른 부여된 번호
최신일 수록 예보는 정확하기에 최신에 가까운 레코드를 취할 예정.
https://github.com/learndataeng/learn-airflow/blob/main/dags/Weather_to_Redshift_v2.py
코드리뷰

etl 함수에 5개의 파라미터를 넘김.
풀리프레쉬버전은 스키마, 테이블만 넘겼었음.
etl 함수 동작을 알아보면
@task로 태스크 함수 만들고
원본테이블이 없으면 생성을 하고,
현재 오토커밋이 False
이에 중간 중간 작업에 COMMIT을 집어넣음.
f"INSERT INTO t VALUES " + ",".join(ret)
으로 임시테이블에 새로운 데이터 집어넣음.
중복 레코드가 존재하는 상황
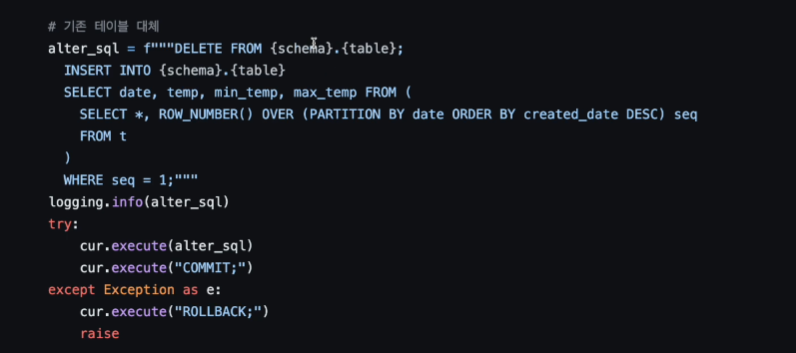
기존테이블을 날리고
새로적재를 하는데
SELECT * , ROW_NUMBER() OVER (PARTITION BY date ORDER BY created_date DESC) seq
INSERT INTO가 될 때, 보면 created_date가 SELECT에서 빠져 있는데, 이렇게하면
created_date timestamp default GETDATE()로 현재 시간이 알아서 들어가게 된다.
매일 하루씩 레코드가 증가하는식으로 커진
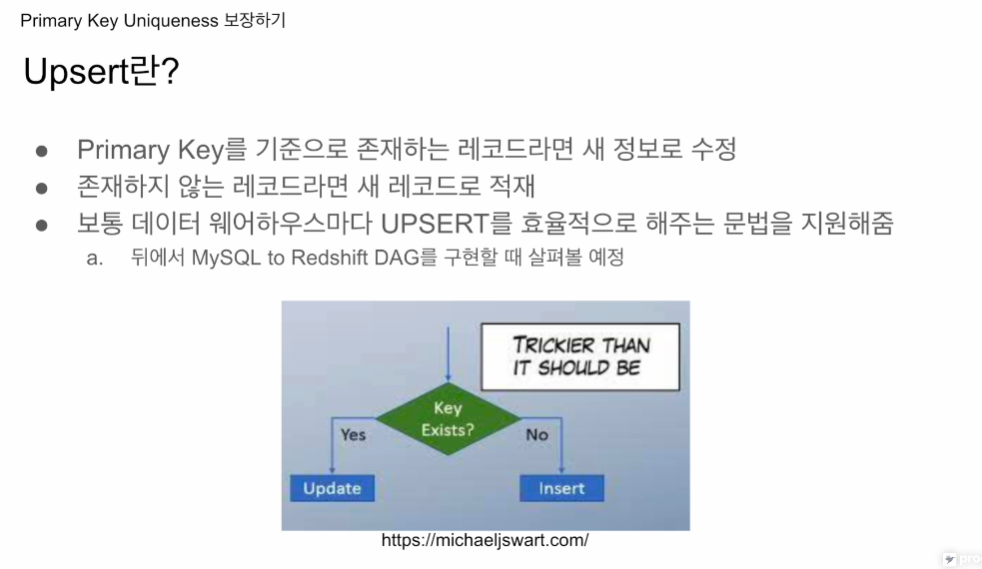
이걸 Upsert라고 부름
INSERT, UPDATE의 하이브리드.
자기들만의 UPSERT를 구현해주는 문법들이 있음.
