학습주제
Backfill
학습내용

부록. 도커 메모리 이슈(노트북)
PC 때와 마찬가지로 환경설정 명령어를 입력하고 docker ps healthy 상태 확인하였으나,
메모리가 부족하다는 경고가 뜸.
이에 워커 수를 줄여봄.
그리고 노트북 역시 8GB를 할당하였으나, compose up 에 상당한 시간이 걸림.

8080이슈가 해결이 안됐을 때는 트리거 이후로 넘어가지 않았음.
SQLalchemy 이슈는 무시해도 되는 것 같음.
DB를 초기화하라는 에러가 남.
이에 도커의 컨테이너, 이미지, 볼륨을 모두 지우고, airflow를 재설치 시도함.
yml은 그대로 유지.
워커의 수를 줄이는 것과 데이터베이스 초기화 사이에는 직접적인 연관성이 없지만, Airflow의 설정 변경이나 특정 작업 수행 과정에서 데이터베이스의 상태나 구조에 문제가 발생할 수 있습니다.
특히, Airflow는 메타데이터 데이터베이스를 사용하여 작업 흐름의 상태를 추적합니다. 이 메타데이터 데이터베이스에 문제가 발생하면, 데이터베이스를 초기화하거나 복구해야 할 수 있습니다.
워커 수를 줄였더니 DB 초기화 에러나서
스케줄러 컨테이너에 들어가서
초기화 시도함.
ctrl + c와 docker compose down은 다름. 완전히 초기화 시키기 위해선 compose down까지
모든 워커, 스케줄러 등등을 초기화해야되는 것 같음. yml에 추가하고 지워보자.
결과적으로 우분투 OS에서 도커 설치한후 ID 환경설정 하고, 에어플로우 컨테이너 올리니 잘 돌아감.
저번에 발생했던 모듈이 설치되지 않는다는 이슈가 있음.
백필을 어떻게 처리하는지 그 개념.
시스템 파라미트
최종적으로 퀴즈

아마존에서 다양한 리포트를 읽어오는 대그, 태스크들이 있음.
보니까 2일동안 실패했었음.
경고 메세지가 왔었지만 처리를 못했음.
2일동안의 데이터가 빠져있다는 의미
24, 25일 실패라고 하면
매일 업데이트로 스케줄을 설정해놨기에, 23, 24일의 정보가 빠져있다는 의미
쉽게 재실행할 수 있는가? -> 에어플로우가 쉽게 해줌.

문제가 있어도 다시 실행하면 됨.
과거 데이터가 잘못됐어도, 다시 읽어오면 해결됨.
가능하면 최대한 풀리프레쉬
난이도가 올라감.
오버헤드, 스트레스 등

인크리맨탈의 경우 과거 시점으로 돌아가 다시 해줘야하기에 복잡할 수도 있음.

어제 타임스탬프에서 연월일만 빼옴. 이게 yesterday
프로덕션 DB에서 이 어제의 결과를가지고 DW에 적재할 것임.
맹점. 매일 문제 없으면 상관 없음. 실패할 수도 있음. 코드만의 문제가 아니라 소스가 되는 프로덕션 DB가 로드가 많이 걸렸다면 대그가 실패함. 그 날짜의 데이터는 DW에서 빠져있을 것임. 내가 빠르게 인지를 못하거나, 나중에 처리하려다 보면 이게 문제.
문제 발생날 발견해서 다시 실행하면 문제가되지 않음
나중에 시간이 지나서 이 코드를 재실행하면 실패했던 날 전날을 얻어 업데이트 하진 않음.
며칠이 지난 다음 빠진 날짜를 찾아내기 위해

하드코딩을 하게 됨
저렇게 1월 1일로 하드코딩 해놓고 실행시킴.
하루치가 실패했다면 저렇게 돌릴 수 있음.
지난 1년치가 실패했다. 루프를 돌려서 1월 1일~12월 31일까지
돌리도록 수정을 하게됨.
-> 이과정에서 실수를 하기 쉬워짐.
어떤 코드는 복잡해서 도대체 어디를 건드려야 할지 모르는 경우도 있음.
다 수정이 되어 원래대로 원상복구를 해야하는데 여기서도 실수를 할 수 있음.
결국 대그를 처음 만들 때부터 백필이 쉽게 가능하게끔 구조를 짜야함.
위험한 포인트 - daily, hourly 읽어와야하는 데이터를 현재시간을 기준으로 계산하는 순간, 실패하게 되면 빠지는 데이터가 생기고, 백필을 하려다보면 코드를 해킹하는 이슈가 생김.
에어플로우는 시스템 차원에서 해결할 수 있게 해놨음.
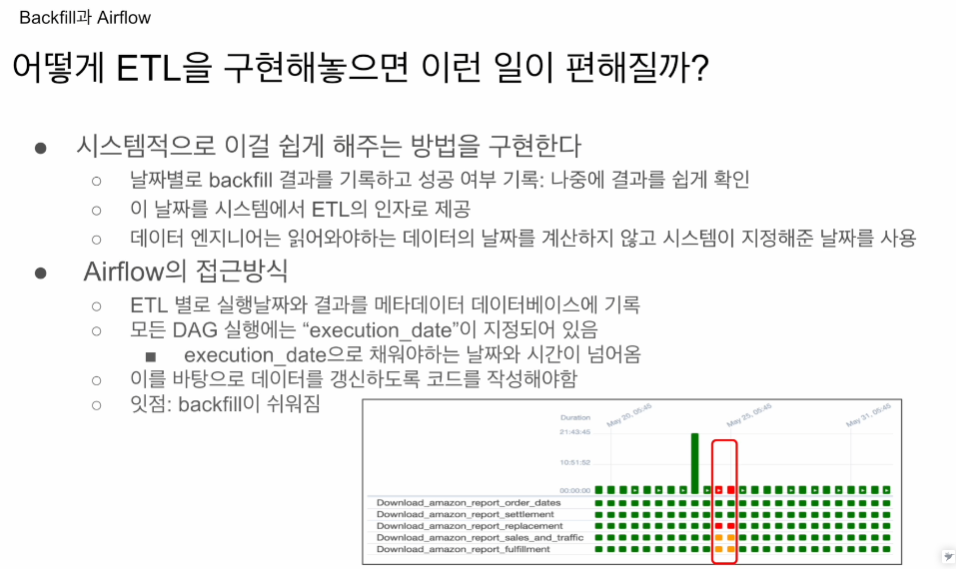
모든 실행에 대해서
DB에 기록을 해놓음 DAG가 23년 5월 19일 성공 20일 성공.
데일리의 경우 20일날 돌렸다면 19일의 데이터를 가져온 것임.
실패했다면 실패했다고 기록. 실패한 날짜와 읽어올려고 했던 데이터의 날짜.
24일, 25일 실패했다면 읽어오려고 했던 데이터 날짜는 23일, 24일이 됨.
시스템은 대그가 언제 실행되고 어느 주기로 실행되는지 알고 있음.
hourly라면 전 시간의 데이터를 가져오려 하는지 알고 있음.
풀리프레쉬, 인크리멘탈인지 에어플로우는 잘 모름.
25일 데일리 대그가 돌면, 그 전날 날짜를 시스템 변수로 제공을 하고 기록을 해놓음.
내가 시간을 계산해서 하는게 아니라 에어플로우 시스템 변수를 가져다 쓰면, 웹 UI로 가서 클리어 한번 눌러주면, 그 데이터의 날짜를 알기 때문에 시스템 variable로
- 시스템 변수의 날짜를 가져다 써라. execution date
엑시큐션 date을 가져다 쓰면 인크리멘탈, 백필에 아무런 문제가 없음.
실패했다면 가서 clear를 누르면, 어느날짜의 데이터를 읽어와야하는지 알기 때문에 나는 그걸 읽어다 처리하면 됨.
모든 대그별로 데일리라면 실행결과가 성공, 실패인지. 읽어올 데이터의 날짜를 기록해놓음. - execution date
엑시큐션 date을 대그 구성할 때 읽어올 수 있음.
운영, 백필도 동일한 코드를 사용할 수 있음.
에어플로우는 일단 인크리멘탈이라 가정하고 엑시큐션_date를 적재함.
풀리프레쉬라면 무시하면 됨.
커맨드라인에서 대그 태스크를 실행할때, 연도월일을 제공하는 공간이 있었는데, 이게 execution_date로 넘어감.
UI에선 엑시큐션 date을 알기 때문.
CLI에선 직접 지정해줘야함.
Start date
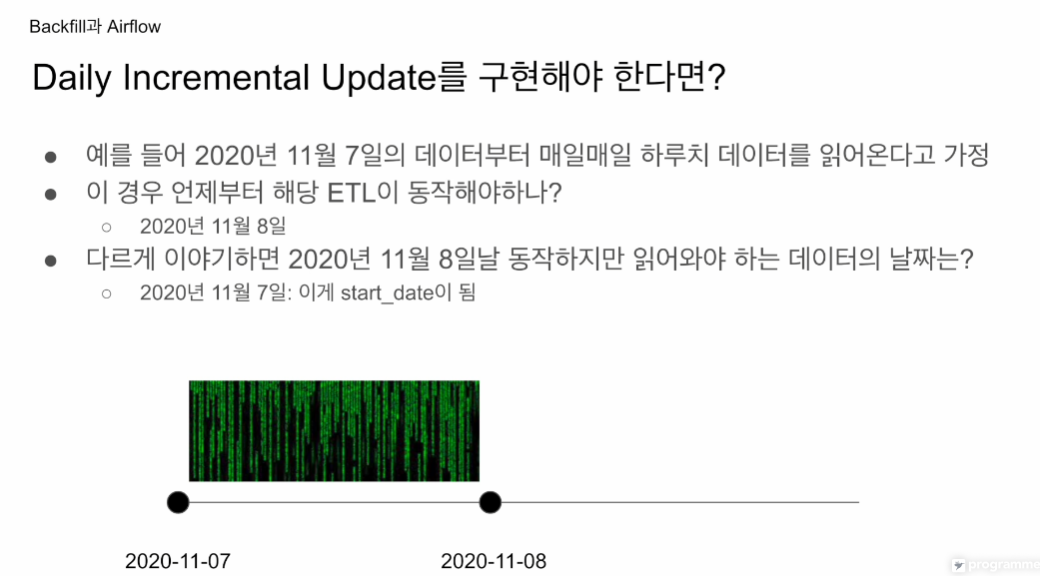
데이터의 시작이 7일이라면 실제 7일에는 이를 가져올 수는 없음. 8일은 되어야 전날인 7일의 데이터를 가져올 수 있음.
이 때 읽어와야 하는 데이터의 날짜 -> start_date
start_date은 데이터의 시작 날짜. not 대그의 실행 날짜.
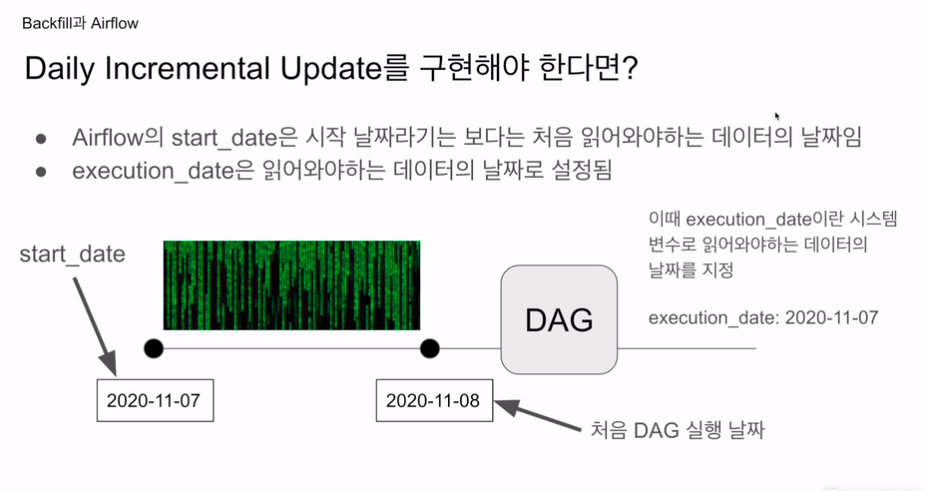
처음 읽어와야하는 데이터의 날짜임.
이 부분이 혼동스러움. 아 start_date은 대그가 실행되는 날짜구나! 하고 착각함.
읽어와야하는 데이터의 날짜.
에어플로우는 이러한 계산을 대신해줌.
실수
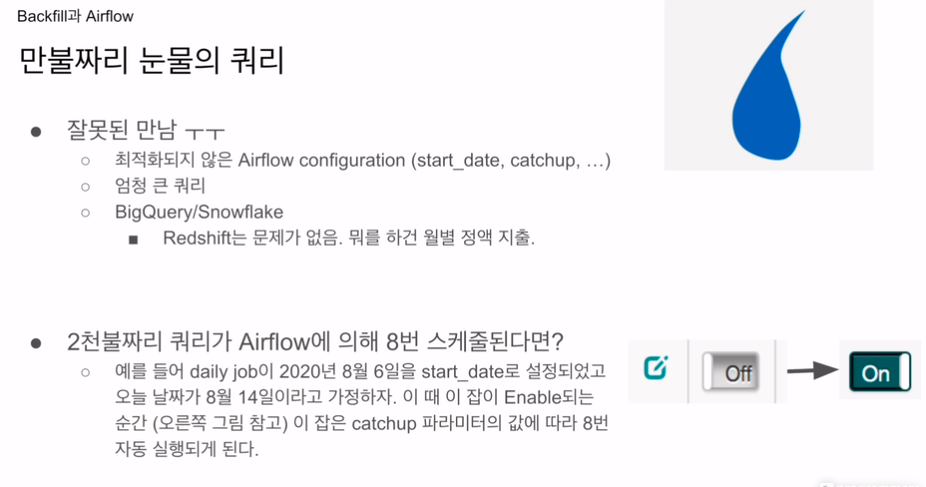
catchup 파라미터를 제대로 모른 상태에서
엄청나게 비싼 쿼리를 여러번 돌림.
레드쉬프트는 고정비용임
이번엔 빅쿼리를 돌림.
6, 7, 8, 9, 10, 11, 12, 13 총 8번 실행.
14 - 6 = 8
캐치업의 위험성.
start_date 부터 읽어오는게 맞다면 catchup True
풀리프레쉬, 과거 데이터 필요없으면 False
잘 모르겠으면 일단 catchup은 false
3번실행
13일 02:00꺼는 14일 02:00가 되어야 실행됨.
현재 시간은 13일 20:00이르모 아직 14일이 도래하지 않았음.
start_date이 대그가 처음 읽어와야하는 데이터의 날짜임.
대그가 하루에 한번 도는 대그면 그 다음날, hourly면 그 다음 1시간에 실행.
execution date은 데이터의 날짜가 저장됨.
12일 02시 대그 실행됐다면 execution date은 11일 02시
큐에 들어가서 예약이 되어서 대기하는 식임.
만일 지금시간으로 계산해서
마치 그날 실행되는 것처럼 보이지만 그 전날 날짜가 들어가면서 순차적으로 실행됨.
코드를 지금시간으로 계산해서 읽어올 데이터의 날짜를 정하면, 과거 날짜를 순차적으로 읽을 수는 없을 것임.
catchup이 True인 상황에서 execution date가 부여된 상황이라면 job을 따라잡기 위해 큐에 순차적으로 10, 11, 12일이 들어가며 날짜가 부여되고 실행될 것임.
13일은 14일 오전 2시에 실행될 것임.

start_date + 실행주기가 실제 실행 날짜
execution_date - 에어플로우가 주는 변수
catchup - True가 디폴트임.
end_date - 옵션적임. 내가 특정 날짜까지만 운영할게 명확할 경우. 보통 지정 안함. 꼭 써야하는 경우. 특정 범위의 날짜에 구간에 백필을 연달아 실행할 때.
모든건 인크리멘탈 업데이트 하는 가정 하에 이뤄짐.
