학습주제
학습내용

데이터 웨어하우스가 작을 땐 프로덕션 DB
이후 클라우드 옵션 사용
ResShift, 빅쿼리 등
장담점에 대해 논의해본다.
클라우드 옵션
- 고정비용 옵션 (redshift)
- 가변비용 옵션 (big query, snowflake)
- 오픈소스는 고정비용에 가깝
고정비용은 비용관리 측면에서 편함.
가변비용은 쓴만큼 냄. 내가 처리하고 싶은 데이터 만큼 비용을 냄. 비용관리가 예측이 안됨.
가변비용 - 스케일러블함 최적화를 부분으로 해주지 않아도, 자동으로 설정됨.
고정비용의 경우 스토리지를 늘리려면 컴퓨팅 성능을 높여야함.
데이터 레이크
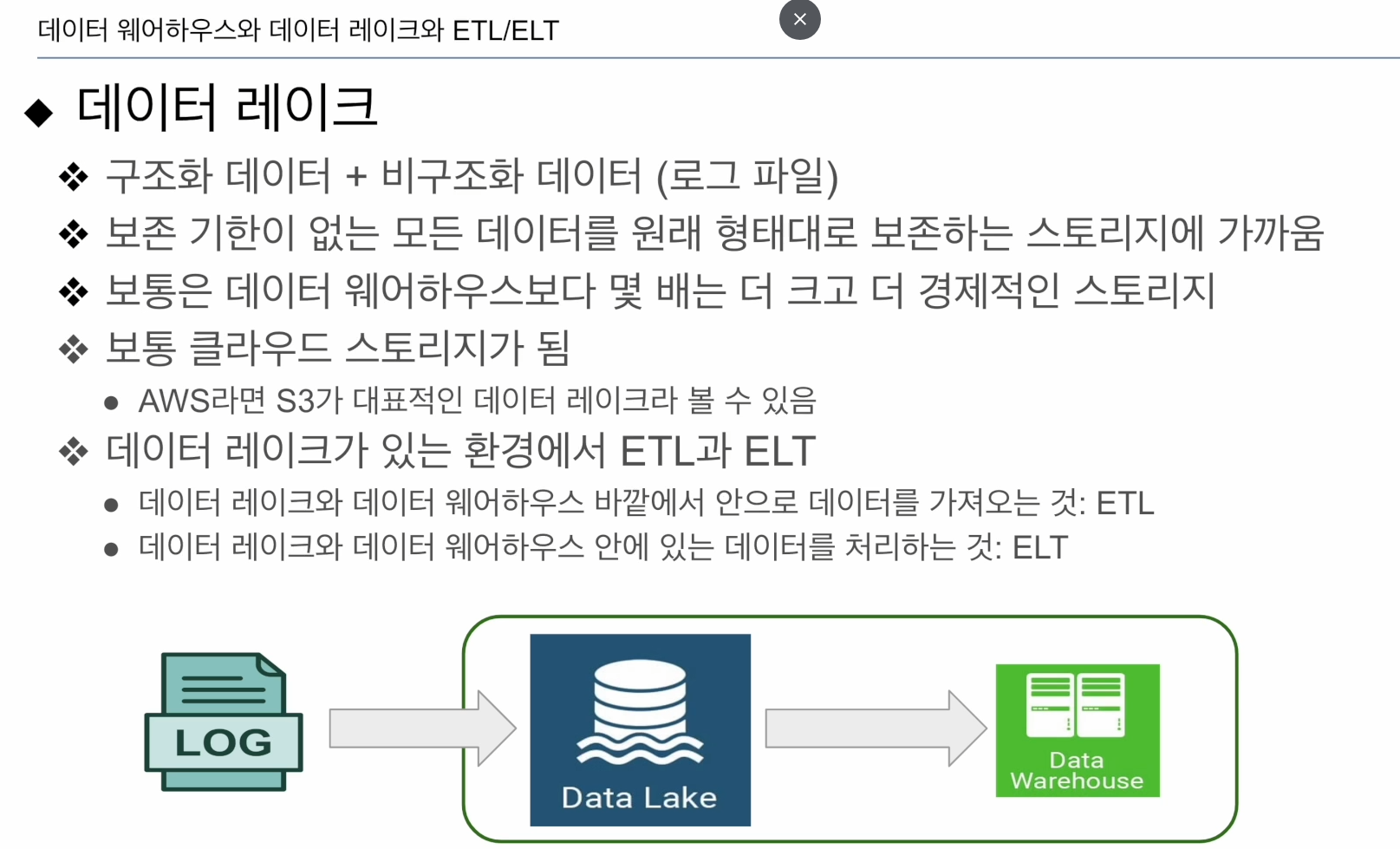
DW는 좀 비싼 옵션. 구조화된 데이터 처리에 용이
데이터 레이크 - 관계형 데이터베이스 X, 스토리지에 가까움. 비구조화 데이터
훨씬 더 경제적임.
정말 큰 데이터를 저장하는데 무리가 없음.
클라우드 업체의 스토리지를 데이터 레이크로 종종 사용
AWS s3, 구글 클라우드 스토리지 등
로그 - 대표적인 비구조화 데이터
로그 -> 데이터 레이크 -> DW
ETL: 데이터 시스템 밖의 데이터를 데이터 시스템으로 불러들이는 과정. (목적지: 데이터 레이크, DW) - Airflow
ELT: 위의 그림처럼 데이터 시스템안에 들어온 데이터로 새로운 데이터를 만들거나 정제하는 과정.(다시 데이터 레이크에 넣던지, DW으로 이동시킴) - DBT 툴 많이 씀

ETL: 회사의 데이터 크기가 크지고, 활용도가 늘어나면 기하급수적으로 늘음. fail etl 발생. 고치고 재실하는게 중요해짐. 관리의 오버헤드가 커짐. ETL 작성을 쉽게해주는 툴 Airflow
ELT: 데이터 시스템 내의 데이터를 이용. 많은 테이블이 시스템 내에 있을 텐데, 레이어를 하나 더 올려 추상화해줌.

그럼 어떤 데이터 소스를 가져오나?
프로덕션 데이터베이스의 데이터
- 리뷰, 구매기록, 레이팅 등
이메일 마케팅
크레딧카드 매출 데이터 - 할부, refund 확인
서포트 티켓 데이터
서포트 콜 데이터 - API 통해 불러옴
B2B 영업. 세일즈 데이터 - Salesforce
사용자 이벤트 로그 (비구조화, 크기가 매우 큼) - 가격이 경제적인 데이터 레이크에 저장.

Airflow
- ETL, ELT 스케줄링, 에러 확인시켜주고, 파이프라인 재시작 등
- 특정 ELT, ELT 실패 재실행 (Backfill, 개발자들에게 악몽같음. 100개중 1~2개는 fail) 이 과정이 생각보다 복잡함.
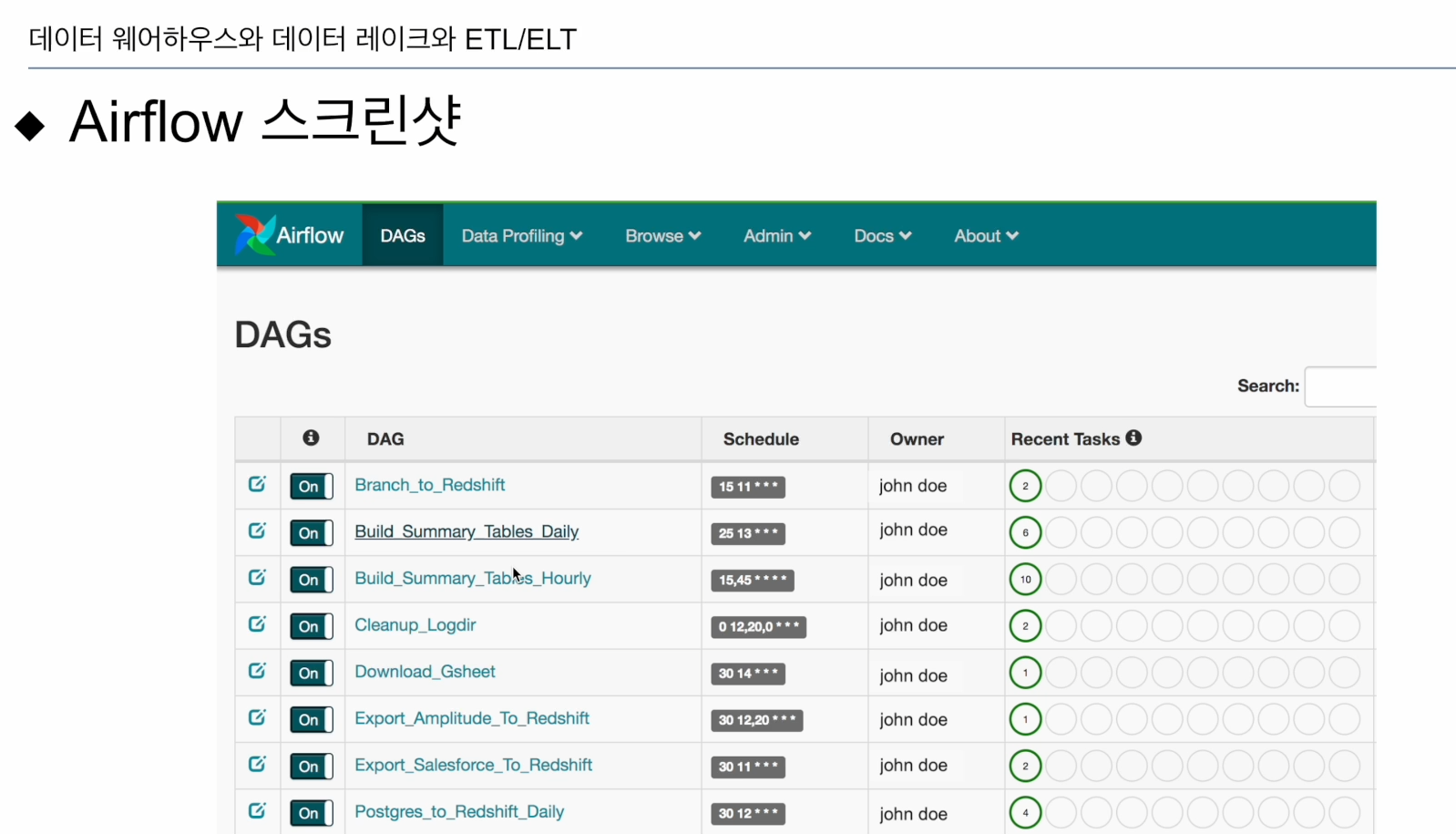
Airflow에 접속하면 다음과 같은 화면 제공
DAGs - 데이터 파이프라인
이 파이프라인들이 정해진 시간에 실행. 오른쪽에 마지막 실행 결과 확인.
웹UI를 통해 제공
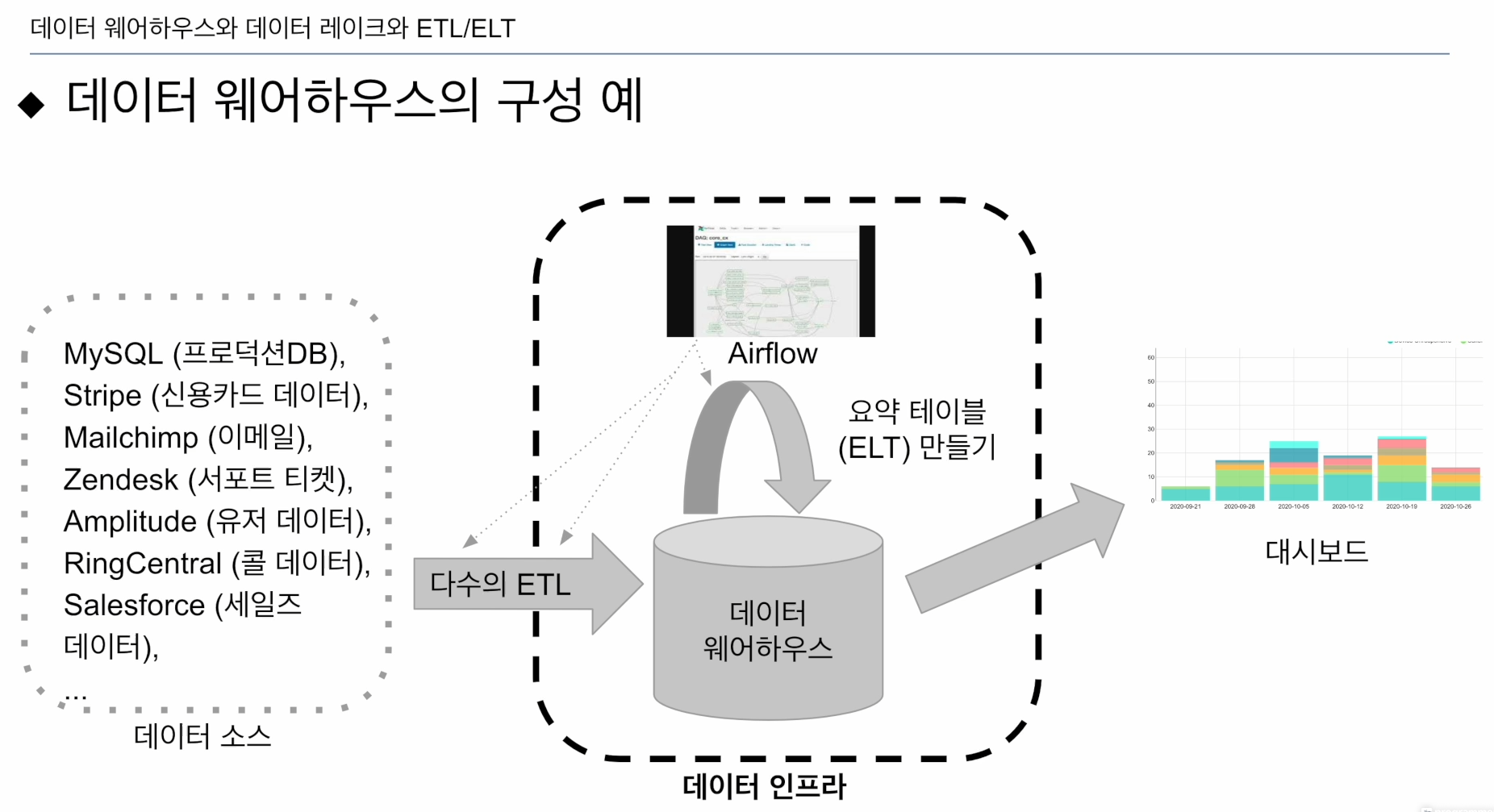
이 회사는 데이터 레이크는 없었음.
하나씩 Airflow 위에서 실행시켰음
원본 데이터를 그대로 쓰기 불편하니 ELT로 레이어로 생성(요약 테이블, 소비하기 쉬운 형태). DBT 툴 많이 사용

ETL: 외부에서 내부로
ELT: 내무에서 내부로, dbt 많이 사용
- 데이터 분석가가 수행.
- ELT의 소스가 로그라면 데이터 레이크에 위치(스토리지, 컴퓨팅 파워 X)
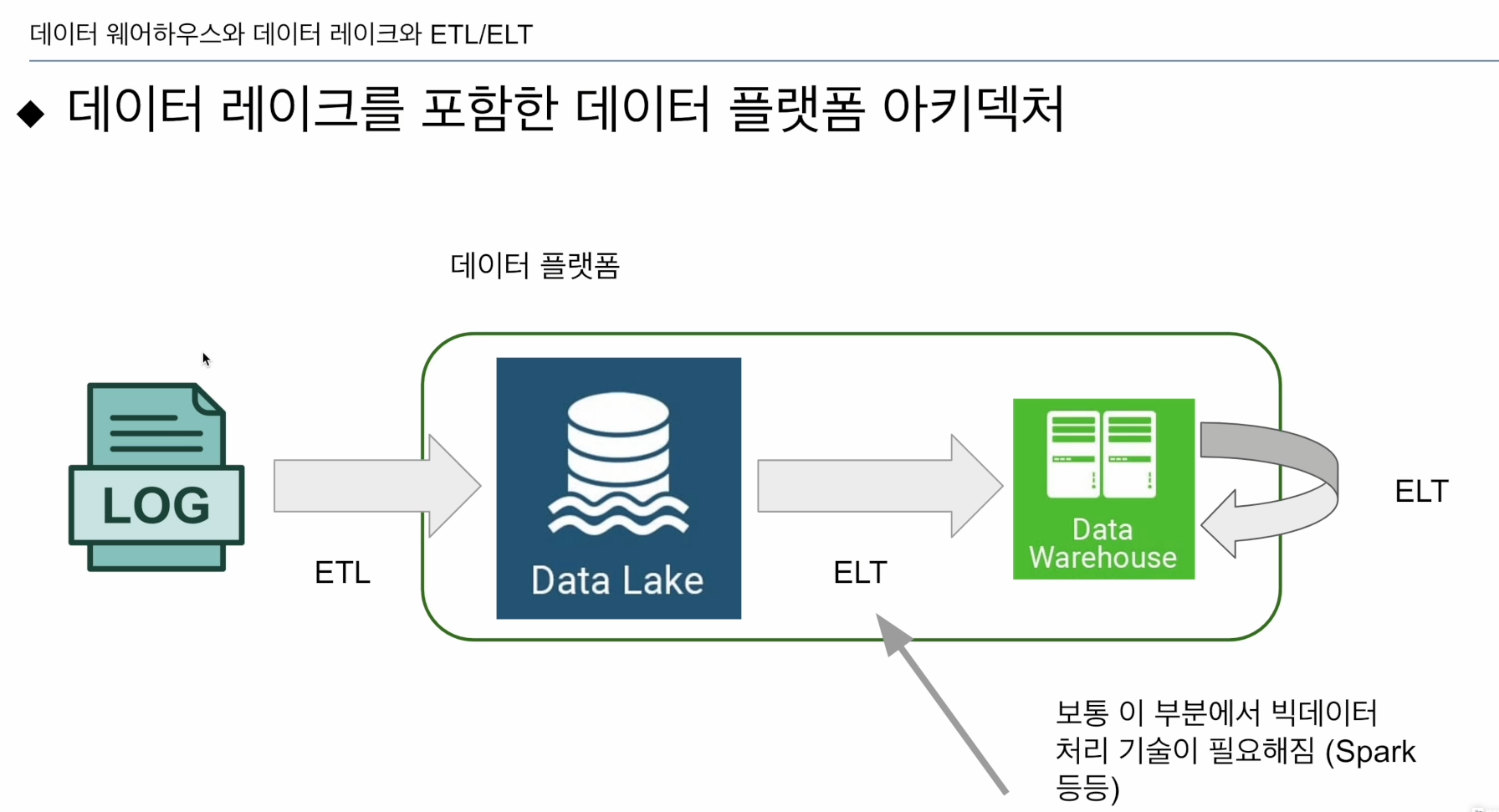
로그파일의 경우 데이터 레이크에 넣고(하루에 한번 ETL), ELT를 통해 DW에 로딩하는게 일반적.
ELT 과정을 구현할 때 파이썬 코드만으로는 엄청나게 오래걸리거나, 메모리 문제 등 온갖 이슈가 생김. - 이러한 로그파일을 처리하는데 빅데이터 프로세싱 프리임워크 (spark)
- 이 ELT를 실행하는데 Spark같은게 필요
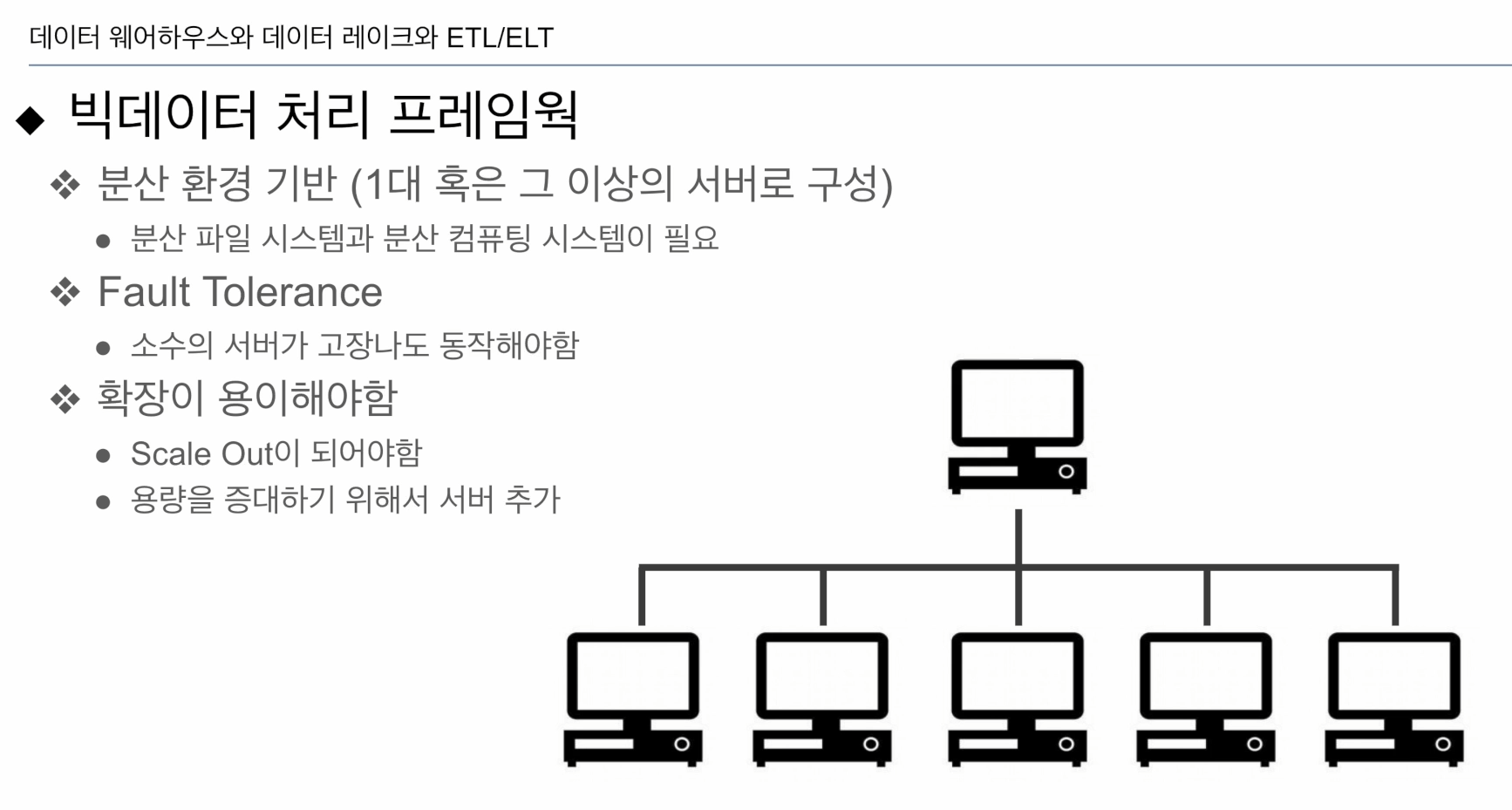
다수의 서버로 구성된 분산 시스템
- 중심에 master
- 각각 slave
CPU, 메모리, 디스크의 총합이 이 시스템이 가진 용량. 관리 측면에서 복잡도 높음. 고장나기도 함.
Fault Tolerance - 일부 서버가 고장나도 동작해야함.
- reflecation factor(3): 하나의 데이터 블락은 3개에 저장
서버 추가 :Scale Out
이미 있는 서버의 사양을 올리는 것: Scale Up
동시에 하는 경우가 일반적.
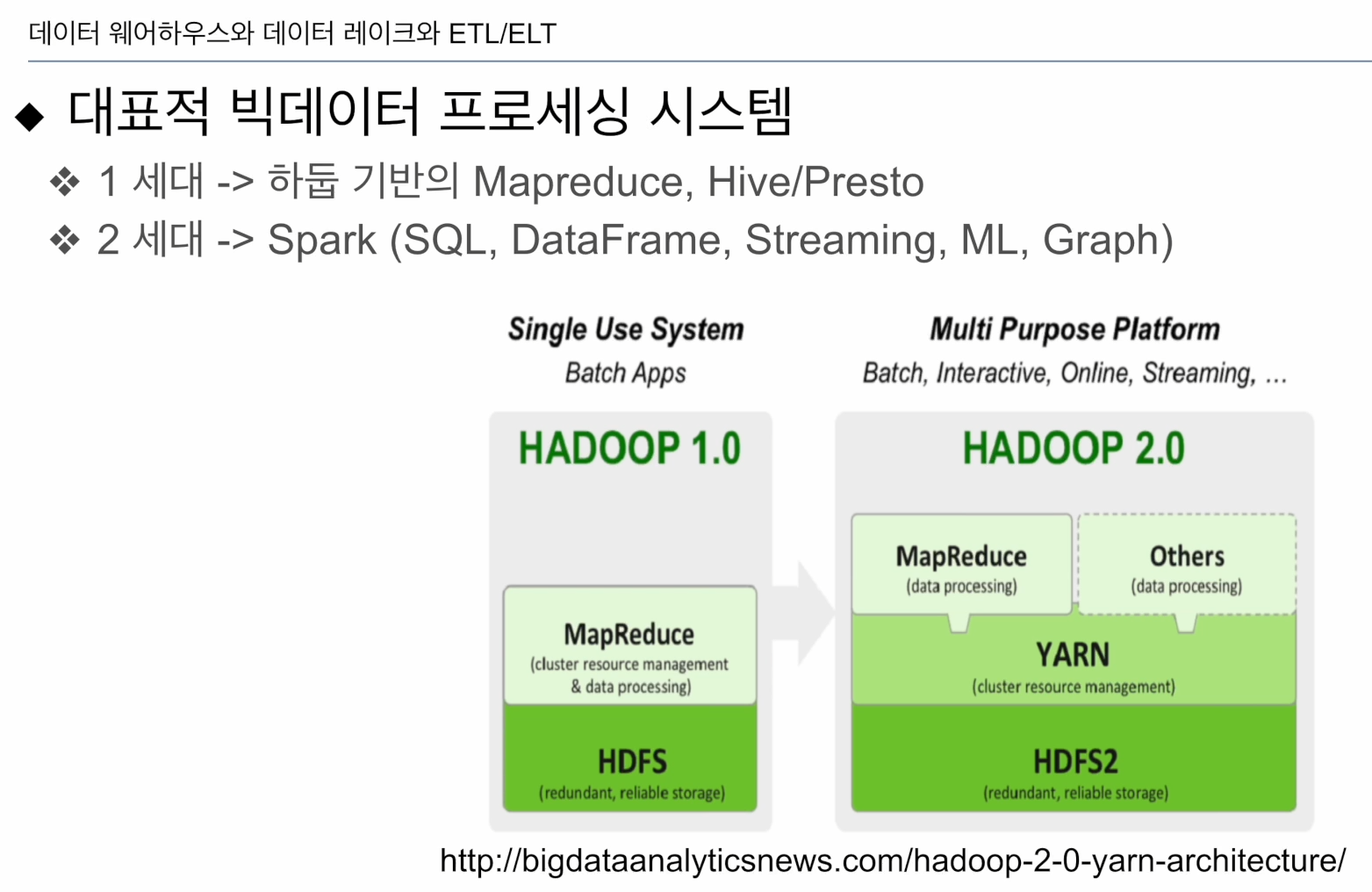
거의 2세대가 나왔다고 볼 수 있음.
1세데-> 하둡
맵리듀스 쓰기 불편, 생산성 떨어짐 -> SQL이 돌아와 맵리듀스 위에 돌아감
-> Hive/Presto.(그냥 SQL이라 생각)
하둡 2.0은 한단계 추가. 큰데이터를 처리해주는 프로세스 Yarn 위에 개발자들이 원하는 형태로 빅데이터 분산처리 시스템을 올림. 그렇게 나온게 Spark임.
Spark이 시장을 석권함.
빅데이터 관련된 종합선물세트: Spark
HDFS 하둡 데이터 파일 시스템. 분산 파일시스템.
HDFS 분산 파일 시스템: 파일 저장 방법
분산 컴퓨팅 시스템:프로세싱하고 새로운 데이터 만들어냄
-Hive/Presto
-Spark, 클라우드 스토리지와 연계해서 사용
