학습주제
외부테이블을 이용한 Redshift 실습
학습내용
AWSGlueConsole IAM을 달아줘야함
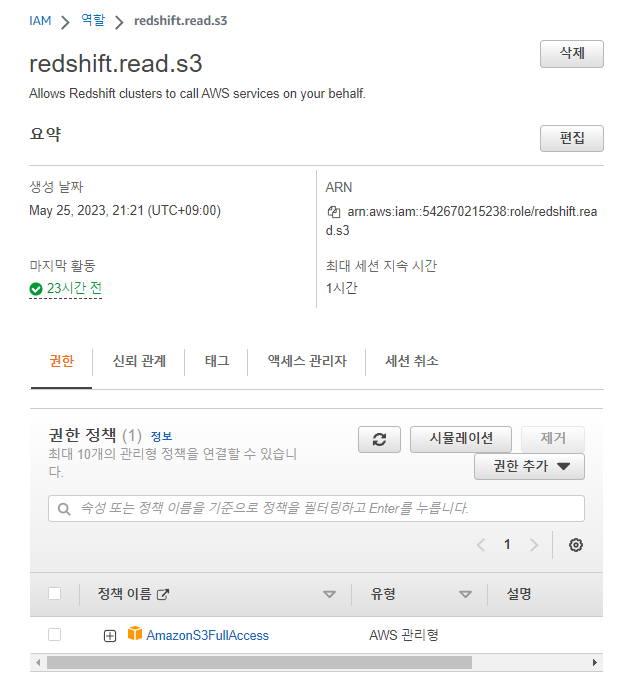
s3fullaccess에
GlueConsoleFullAccess를 추가함
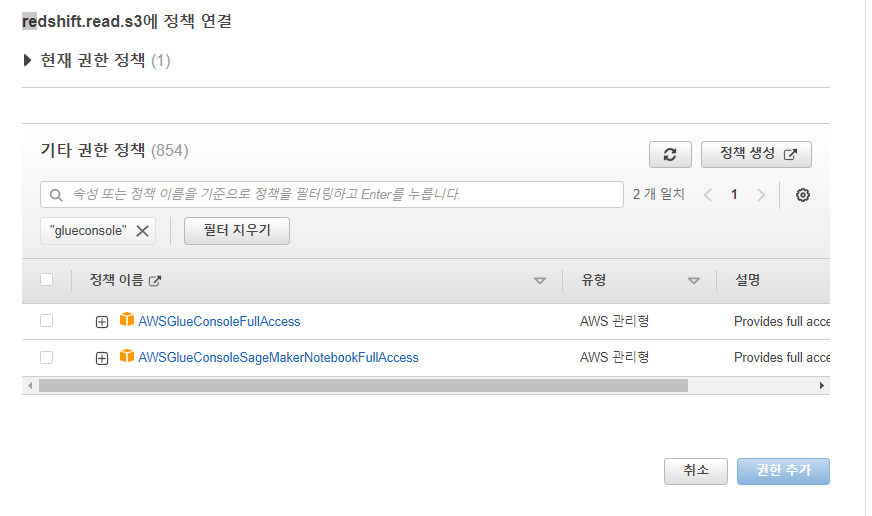
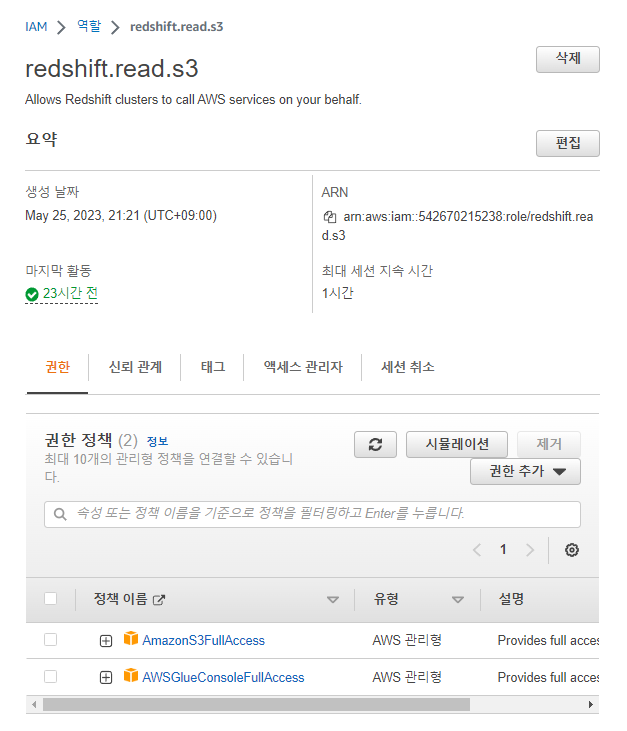
권한을 추가하였다.
이로써 redshift에서 외부 테이블을 접근할 수 있는 권한이 생김
S3 웹 콘솔로 이동
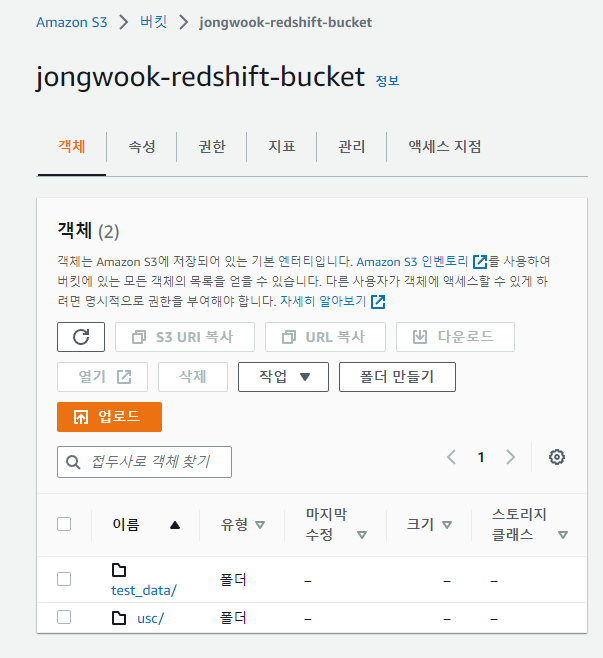
usc 폴더를 만듦
여기에 user_session_channel.csv를 업로드함
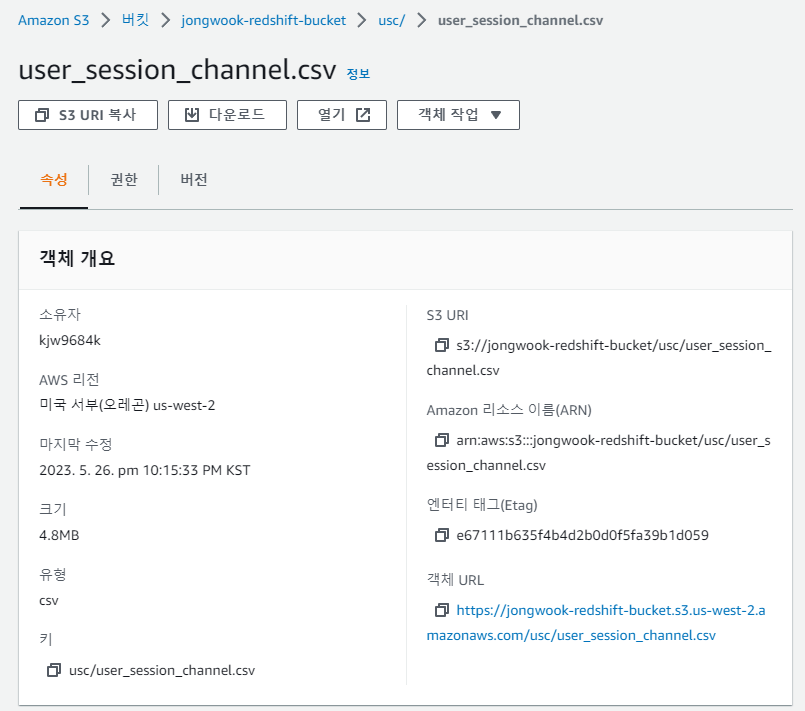
위의 S3 URI를 통해
external table의 주소를 설정
권한을 추가하였고, 버킷에 usc 폴더를 만들고 원하는 파일을 업로드 하였다.
다시 콜랩으로 돌아와
https://colab.research.google.com/drive/144fARzv8TDBqn7ovdP7P8ZdmlA6iwUX6#scrollTo=-pQBd8qZpJaM
!pip install ipython-sql=0.3.9
CREATE EXTERNAL SCHEMA external_schema
from data catlog
database 'myspectrum_db'
iam_role 'arn:aws:iam::542670215238:role/redshift.read.s3'
create external database if not exists;CREATE EXTERNAL SCHEMA external_schema: 이 부분은 'external_schema'라는 이름의 외부 스키마를 생성하라는 명령입니다. 외부 스키마는 Redshift가 외부 데이터 소스에 있는 데이터를 이해하고 쿼리할 수 있게 해주는 구조를 정의합니다.
FROM DATA CATALOG: 이 부분은 외부 스키마의 정보가 어디서 올 것인지를 명시합니다. 데이터 카탈로그는 외부 데이터에 대한 메타데이터를 보유하고 있습니다. 'FROM DATA CATALOG'를 지정함으로써, 해당 외부 스키마의 메타데이터가 AWS Glue Data Catalog나 Hive Metastore 같은 데이터 카탈로그에서 가져와질 것임을 의미합니다.
DATABASE 'myspectrum_db': 이 부분은 데이터 카탈로그 내의 특정 데이터베이스를 참조하게 합니다. 여기서 'myspectrum_db'는 데이터 카탈로그 내의 데이터베이스 이름입니다.
이 외부 데이터베이스는 AWS S3와 같은 외부 저장소에 저장된 데이터에 대한 메타데이터 정보를 가지고 있습니다. 이 메타데이터에는 각 테이블의 이름, 데이터의 위치, 데이터 형식, 각 컬럼의 이름과 데이터 타입 등이 포함됩니다.
myspectrum_db밑에 스키마가 놓이게 됨. 스펙트럼을 사용하겠다는 의미
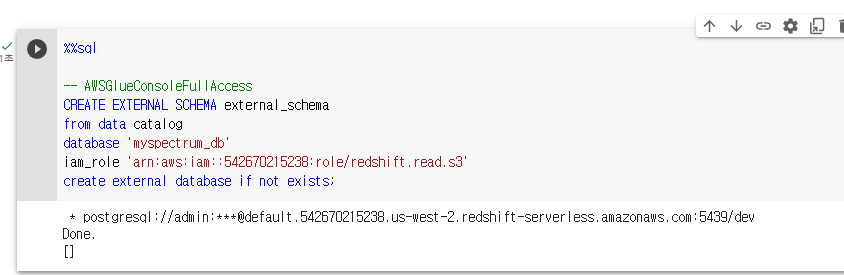
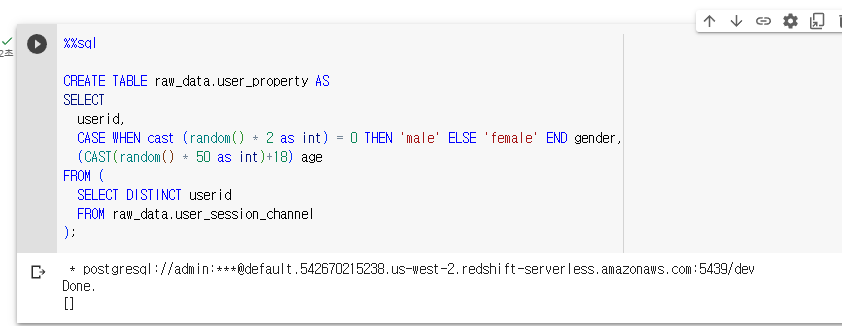
location을 잘못 설정해줘도 성공했다고 뜬다

location을 제대로 설정했는데 이번엔 이미 존재하는 테이블이라고 해서 안된다.
그리고 외부테이블은 참조 형식이라
외부 테이블의 참조 정보를 삭제하려면, 보통 AWS Glue Data Catalog나 Hive Metastore 등의 메타데이터 저장소에서 직접 해당 테이블의 메타데이터를 삭제해야 합니다.
한번의 실수로 복잡해졌다
다시 말해, 외부 테이블을 '삭제'하려는 원래의 목적에 따라 적절한 대안을 선택해야 합니다. 예를 들어, 만약 'user_session_channel' 테이블의 구조를 변경하려는 것이 목적이라면, 동일한 이름으로 새로운 외부 테이블을 생성하면 됩니다. 만약 해당 테이블에 대한 참조를 완전히 제거하려는 것이 목적이라면, 메타데이터 저장소에서 해당 테이블의 메타데이터를 직접 삭제해야 할 수도 있습니다.
그렇다고 한다
다만, 이 방법은 기존의 외부 테이블의 메타데이터를 변경하지 않습니다. 외부 테이블의 'location' 파라미터는 외부 테이블이 생성될 때 설정되며, 나중에 변경할 수 없습니다. 따라서, 외부 테이블의 위치를 변경하려면 새로운 외부 테이블을 생성해야 합니다.
변경할 수 없다고 한다.
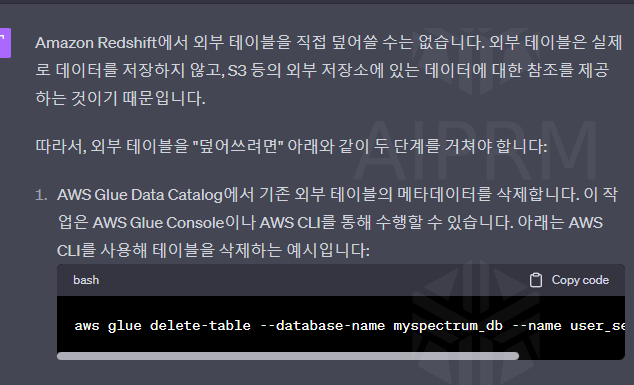
참조 외부 테이블을 삭제하려면 번거로운 모양
External table같은 경우, 버킷 폴퍼 파일을 대상으로 만들기에 스키마 생성과 동시에 레코드들이 로딩되는 형태임.
일단 'keeyong-test-bucket/usc' 경로로 테이블 1개는 생성되었으므로
접근해본다 -> 실패. s3 버킷은 고유한 이름을 가짐.
psycopg2로 생성해봄
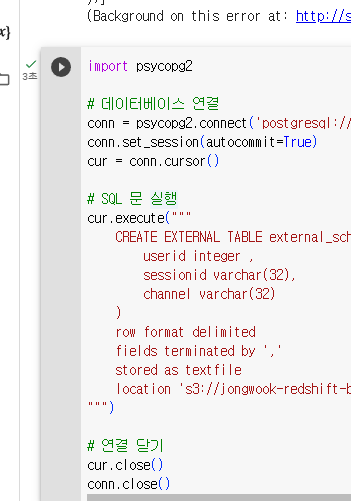
성공함.
연결한 뒤,
커서를 생성해서
cur.execute() 안에 SQL문을 넣고 돌림
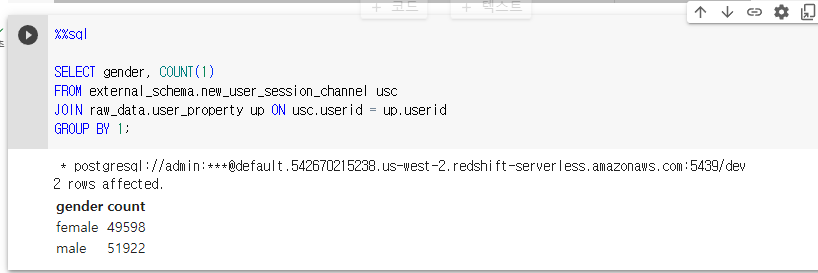
new_user_session_channel로 생성했더니 외부 팩트 테이블과 내부 디멘션 테이블의 조인이 성공함.
IAM 역할의 경우 인증시간이 1시간이라 초과한줄 알았는데 아니었음.
%%sql은 Jupyter Notebook의 매직 커맨드입니다. 이 커맨드는 Jupyter 셀에서 SQL 쿼리를 직접 실행할 수 있게 해줍니다. 이 기능은 ipython-sql이라는 라이브러리를 통해 제공됩니다.
요약
강사남과 함께하면 뭔가 스무스 하게 진행되는데, 내가 잘못 한 거에 대한 복구가 어려울 수 있다. 속성수업이다보니, 이런 예외처리에 관한 수업은 없다. GPT통해서 열심히 묻고 답하는식으로 배워야함.
실제 프로젝트에선 바로 만들어지지 않을 경우가 많기 때문.
그렇다고해서 수업을 게을리 하라는 게 아니라, 예외처리에 대한 수집도 병행
%load_ext sql
%sql postgresql://username:password@localhost/mydatabase
%%sql
SELECT *
FROM mytableMagic 커맨드는 Jupyter 환경에서 특별한 작업을 수행하거나 설정을 변경하는 데 사용되는 특별한 커맨드입니다. %%sql 같은 Cell Magic 커맨드는 셀 전체에 적용되며, %sql 같은 Line Magic 커맨드는 단일 라인에 적용됩니다.
ipython-sql 라이브러리를 설치한 후에는 %load_ext sql 커맨드를 사용하여 SQL 확장 기능을 로드하고 활성화시킵니다. 그 후에는 SQL 쿼리를 작성하여 DB와 상호작용할 수 있게 됩니다.
