학습주제
Redshift ML 사용하기
sage maker 연동통해 간단한 ML 모델
학습내용

머신러닝이란
배움이 가능한 알고리즘의 개발
개발자가 코드를 작성해서 만드는게 아니라
예제로부터 패턴을 알고리즘으로 알아내는 것
훈련데이터 - 트레이닝 셋 (지도학습)
훈련데이터가 없으면 비지도학습
비전, NLP 같은 처리가 있음. GPT가 나오면서 어느정도 쓸수 있는 기술로 바뀜.
인공지능 > 머신러닝 > 딥러닝

산물 -> 머신러닝 모델
블랙박스 - 개발자가 선택한 알고리즘에 따라 달라짐
결정트리, 등등
딥러닝도 이해하기 어려움
선형회귀, 결정트리는 상대적으로 이해하기 쉬운편
지도 머신러닝
비지도 머신러닝
강화 학습(게임을 인공지능으로 플레이시킬 때)
구체적인 예
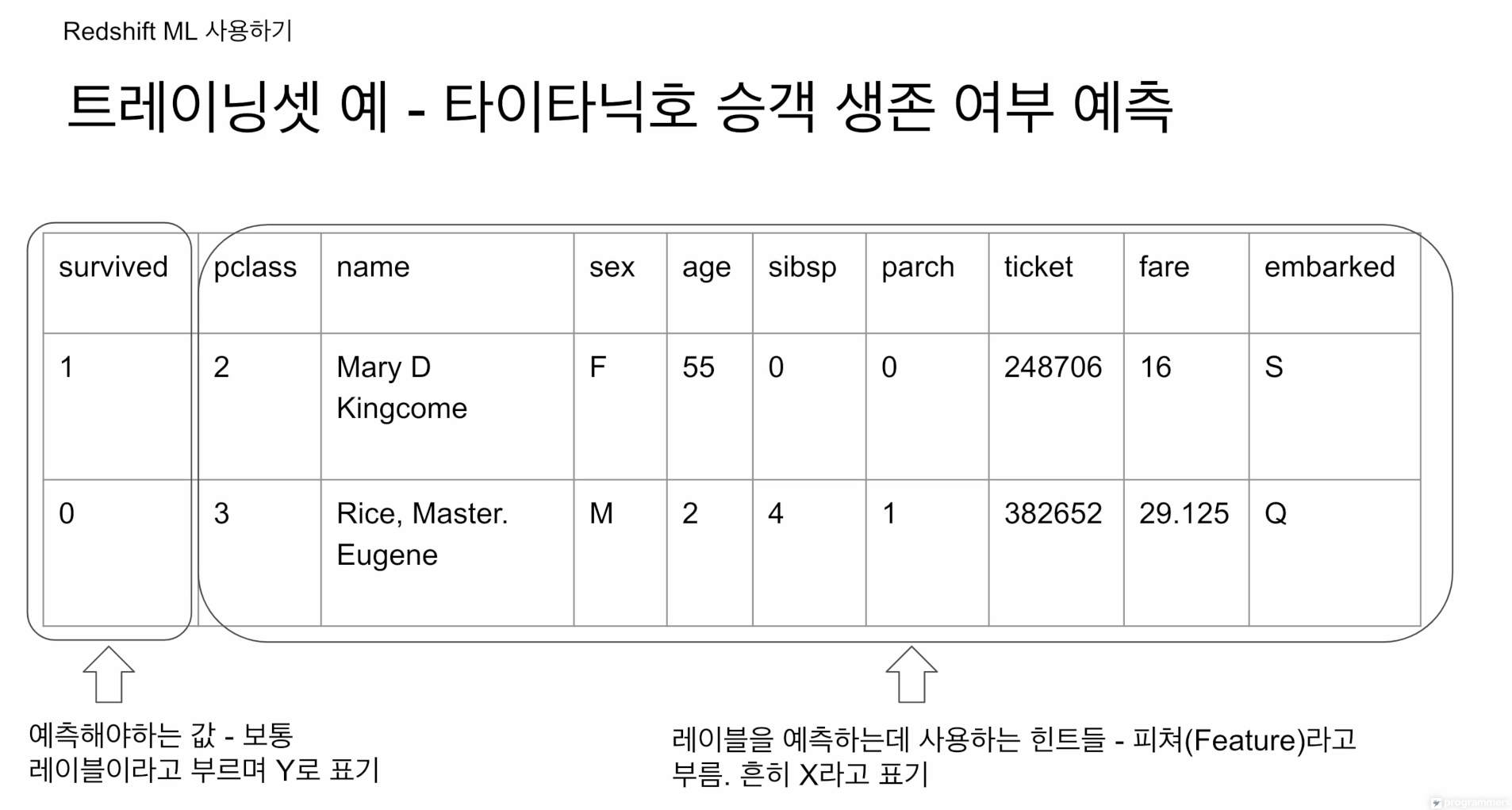
타이타닉 호 승객 생존여부 예측
지도학습 머신러닝 모델
예측값 - Y로 표기, 레이블이라고 부름
힌트들 피쳐라고 하고 X로 표기
어떤 정보는 의미가 있고, 어떤것 없고, 각각만 놓고봐선 모르지만 합치면 좋은 INPUT이 되기도 함
결국 숫자로 바꿔 행렬연산 함. 이름같은 경우엔 관련 없음
pre processing 과정이 필요
지도학습방법.
구체적으로 얘기하면
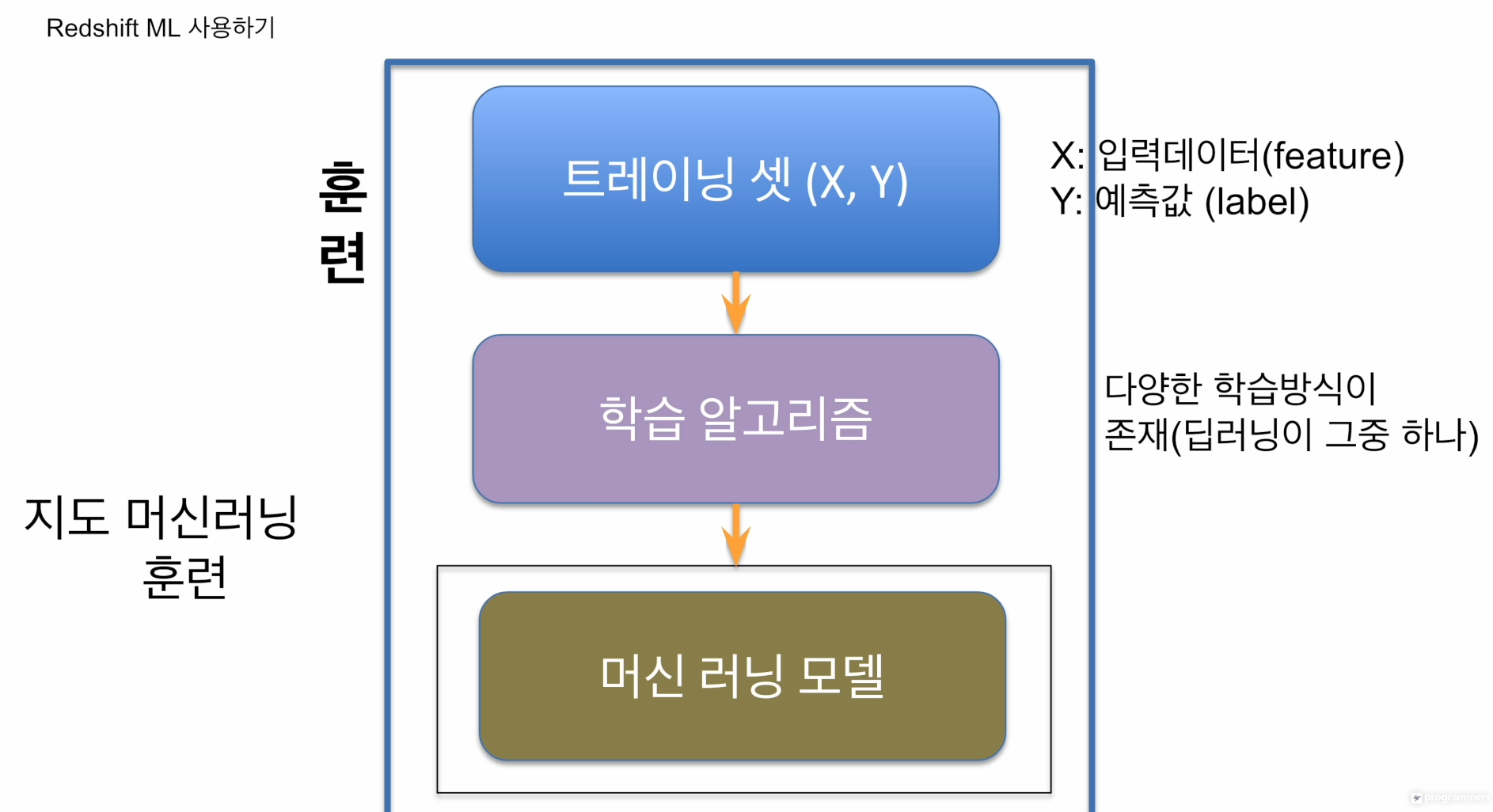
입력데이터 X, 레이블값 Y가 주어짐
적당한 학습알고리즘을 골라 학습을 시킴. 학습을 몇번이나 반복할건지, 느리게 할껀지 등등 선택. 줄 수 있는 파라미터가 많음.(시간, 자원이 무한하다면 가능한 조합을 고를 수 있음).
데이터 크기가 작거나, 너무 최적화하면 오버피팅 문제가 발생
트레이닝셋에서 70~75로 모델을 만들어서 20~25%를 입력으로 주어 레이블과 비교해 성능을 평가해. Hold-out test라고 함.
랜덤하게 데이터를 샘플링해서 테스트 용으로 쓰고, 나머지를 훈련 시킬수도 있음
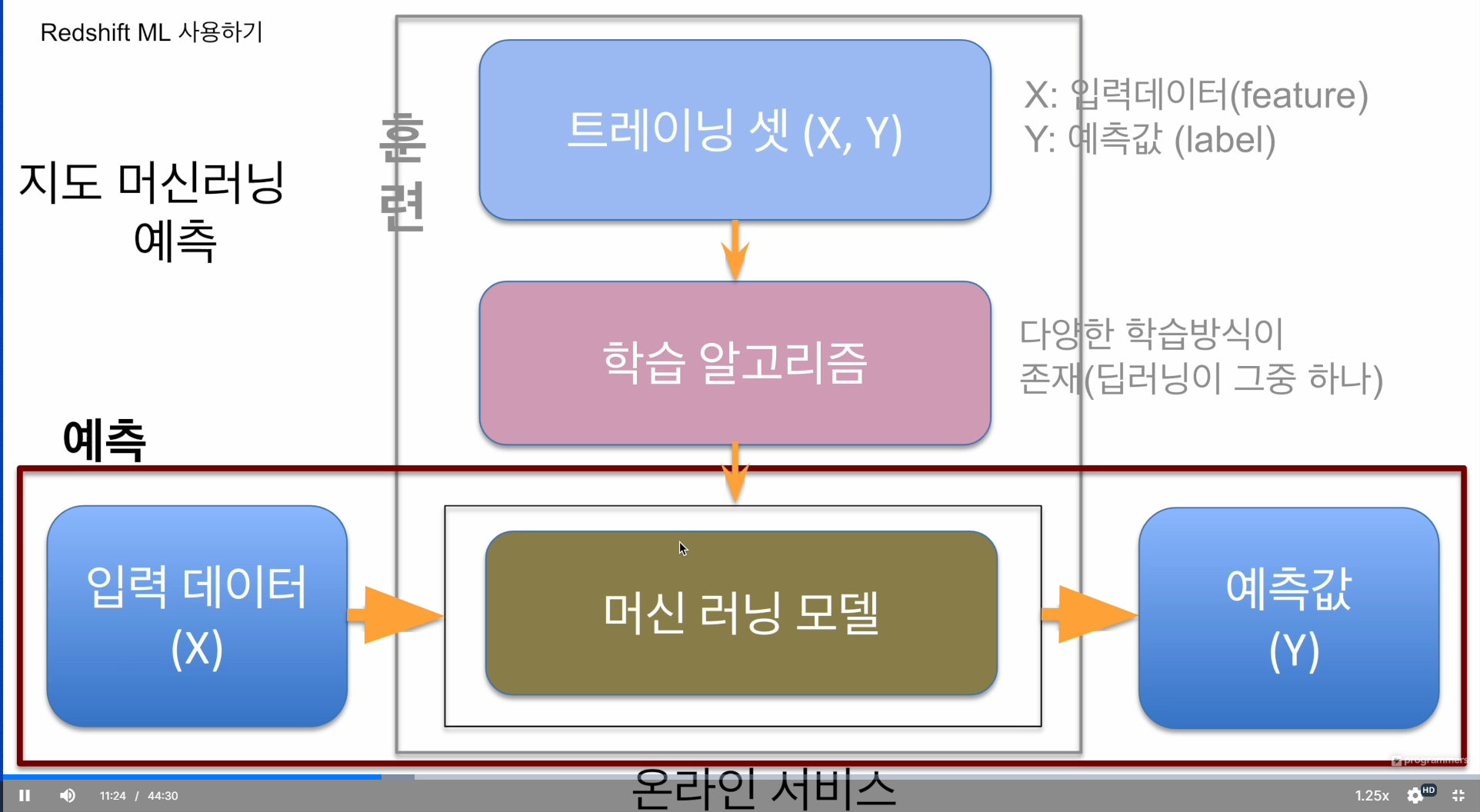
실제로 쓰기 시작함
추천 모델이라면
실제 사용자가 우리 서비스에 로그인 한순간 좋아할 것 같은 상품을 보여줌
입력데이터 - 사용자의 과거행동, 정보
동일한 X가 들어와야 머신러닝 모델이 동작함. 훈련시 데이터가 같다면,
그걸 바탕으로 예측값을 내줌.
지금까지 지도 머신러닝
Sage Maker?

머신러닝 모델을 end-to-end로 가능케해줌
MLOPS 프레임워크
머신러닝 모델 관련, 훈련데이터 준비 기능
훈련데이터 가지고 머신러닝 모델 훈련
Cross-validation 홀드아웃등으로 검증
실제 예측을 요하는 입력데이터를 로깅하고 모니터링
다양한 형태의 프레임워크를 지원.
사이킷 런으로 모델을 만들수도 있음.

스튜디오라는 구글 콜랩과 같은 노트북 환경
자체 SDK 제공
파이썬 모듈을 임포트해서 사용할 수도 있음
사용할 때마다 돈이 나감
그렇게 싼 서비스가 아님.
노트북을 어느 환경에서 돌리느냐에 따라 가격 달라짐
GPT처럼 autopilot이라는 코딩없이 모델 훈련 가능
autopilot에서 레이블값만 알려주면, 알아서 훈련시키고 최종적으로 가장 좋은걸 순서대로 보여줌.
create model 백그라운드에서 auto pilot으로 호출, 3~4시간, 20~40불 정도 나가고. 만들어줌. 그 모델이 들어간 SQL 함수를 만들어줌.

AutoML 기능
사람이 분석하듯이 EDA를 수행. 의미없는 필드를 드랍하기도 하고 스케일링을 함. 필드 값 범위가 크면 정규화도 해줌. 어떤 머신러닝, 파라미터 조합을 정할지 하나씩 실행시키고 결과를 기록. 알고리즘에 따라 정확도 지표를 정함. 레이블 값이 어떻게 분포되냐 따라 F1이든 ROC 든 등등
성능을 보고 맘에드는 걸 선택하고 API 엔드포인트로 배포까지 함.
실제 예측을 원하는 입력값을 전체를 로깅할것인지 일부만 할것인지.
데이터 패턴들이 바뀌는지 모니터링하며 성능을 확인할 수 있음.

1. 캐글 데이터셋 사용(고객 이탈률 데이터. 통신사 개인정보 바탕으로 사용자가 통신서비스를 계속 사용할지 이탈할지 예측)
2. csv 파일을 s3 버킷 아래 폴더로 업로드
3. 위 데이터를 raw_data. 아래에 테이블형태로 COPY
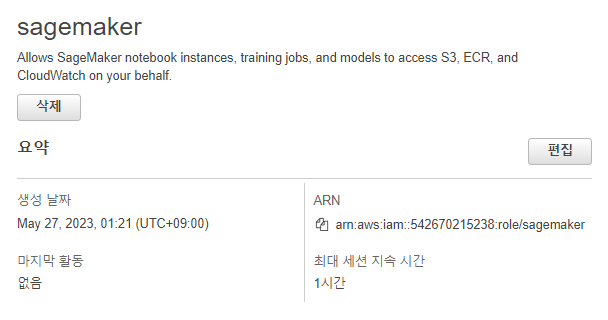
4. SageMaker 사용 권한을 레드쉬프트 클러스터에게 부여
- 전과 약간 다름. 양방향으로 권한 부여해야함
- CREATE MODEL 명령 사용 (8:2로 훈련)
- Model SQL 함수 사용해서 테이블상 레코드들을 대상 예측 수행
- SageMaker 관련 리소스 제거
- 삭제가 잘 안될수도 있음. 리소스를 직접 확인하고 다 삭제해줘야 함. 안그러면 비용 청구됨.

21개 컬럼, 3333레코드 수.
purpose가 문자열로 Test, Train으로 분리되어 있음
어느컬럼이 레이블? -> Churn 컬럼 (boolean)
19개 필드들이 있는데, Input이 되는 정보들. 문자열은 숫자로 바꾸든 사용을 X
피쳐 셀렉션. 컬럼 값을 어떻게 할 것인지 정함.
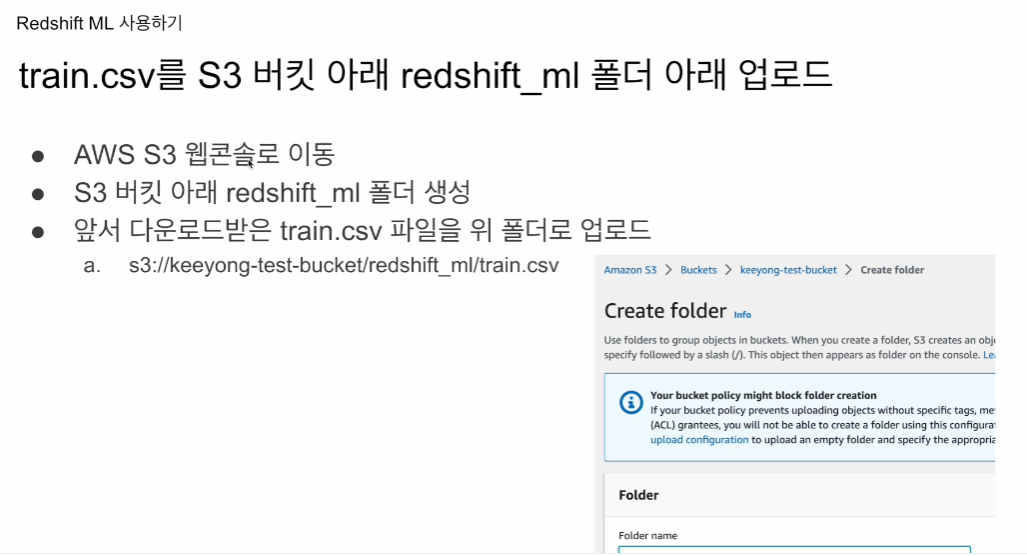
이미 업로드 함
S3의 csv 파일을 가지고 raw_data에 새로운 테이블을 생성함. COPY 명령어와 함께.

CREATE TABLE raw_data.orange_telecom_customers (
state varchar,
account_length integer,
area_code integer,
interational_plan varchar,
...
churn varchar,
purpose varchar
);
COPY raw_data.orange_telecom_customers
FROM 's3://jongwook_redshift_bucket/redshift_ml/train.csv'
credentials 'aws_iam_role=arn~~~:role/redshift.read.s3'
delimiter ',' dateformat 'auto' timeformat 'auto' IGNOREHEADER 1CREATE TABLE로 먼저 테이블 구조를 생성
COPY 이하 명령어가 아직 익숙치않음.
credentials은 권한이 부여되어 있는지 검증이 필요함
권한 (가장 복잡)

양방향으로 권한이 부여되어야 함
세이지 메이커가 클러스터에 있는 테이블에 엑세스
레드쉬프트가 세이지 메이커 기능을 백그라운드에서 쓸수 있는 엑세스
레드쉬프트의 권한으로 한번 지정
CREATE MODEL sql을 지정할 때 씀
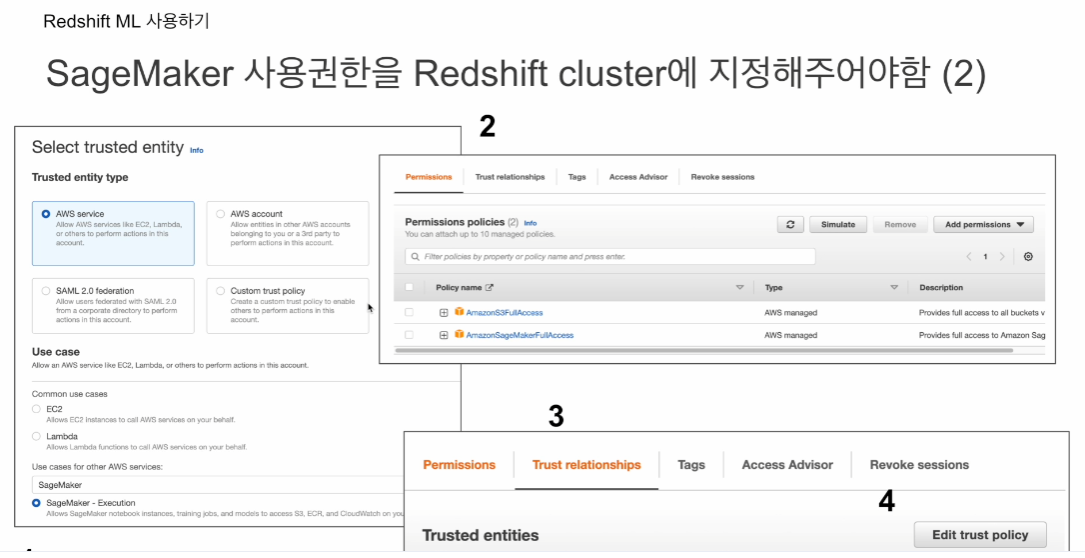
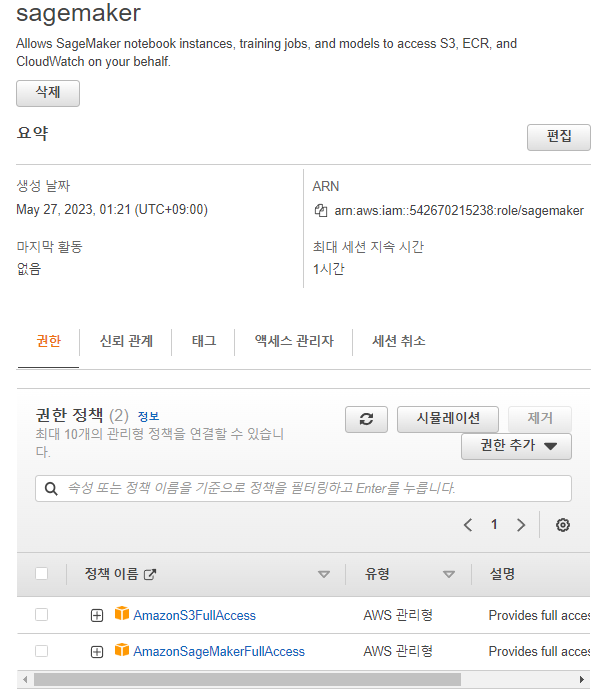
역할 만들기
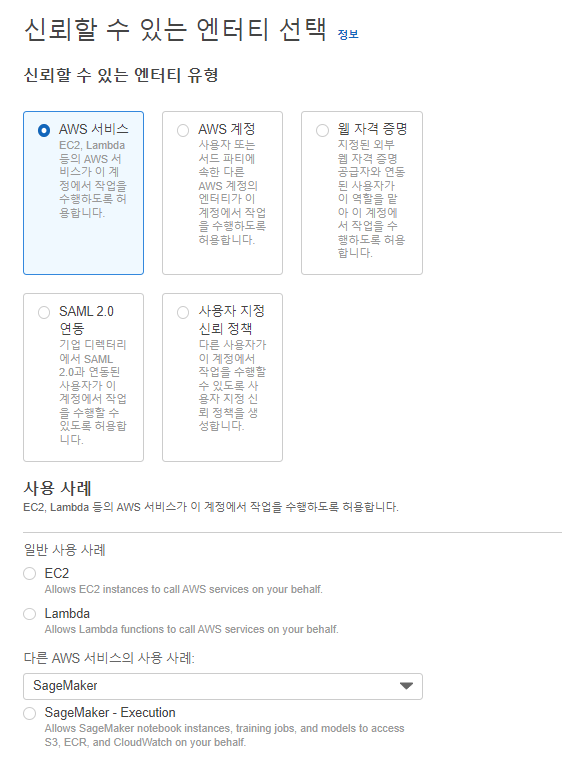
AWS 서비스 선택
다른 AWS 서비스의 사용사례로 sage maker 선택
정책 추가
강사님의 화면과 다소 다른거 같음 임시로 sagemaker로 역할 이름 만들고 이후 권한 추가함
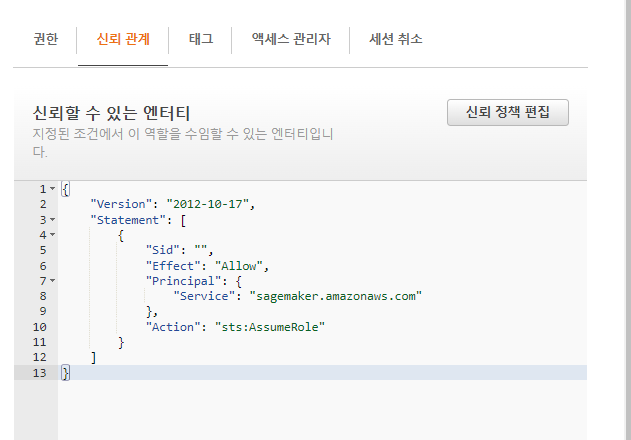
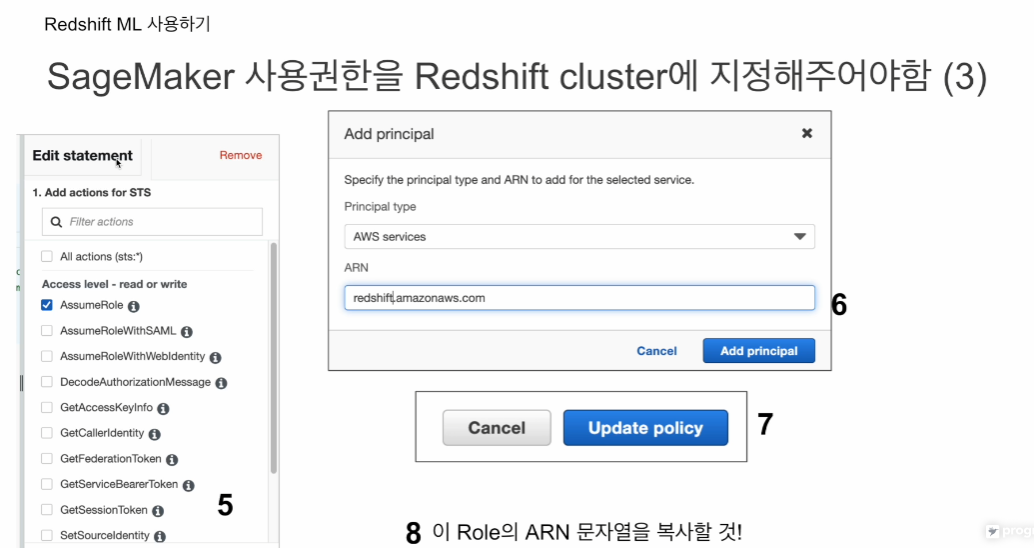
신뢰정책 편집에 들어가서
AssumRole 선택 환인
여기서 보안주체 추가 선택 - add principal
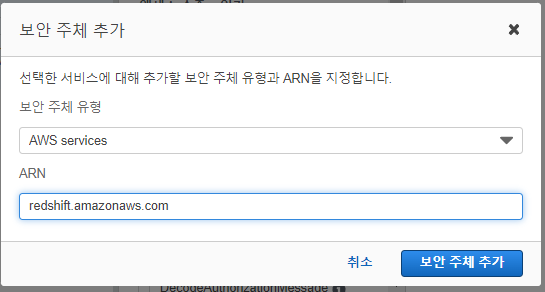
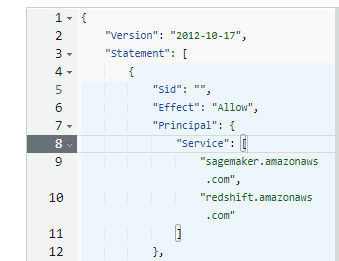
추가된 걸 확인
세이지 메이커, 레드쉬프트가 보안 주체가 된 것을 확인
정책 업데이트
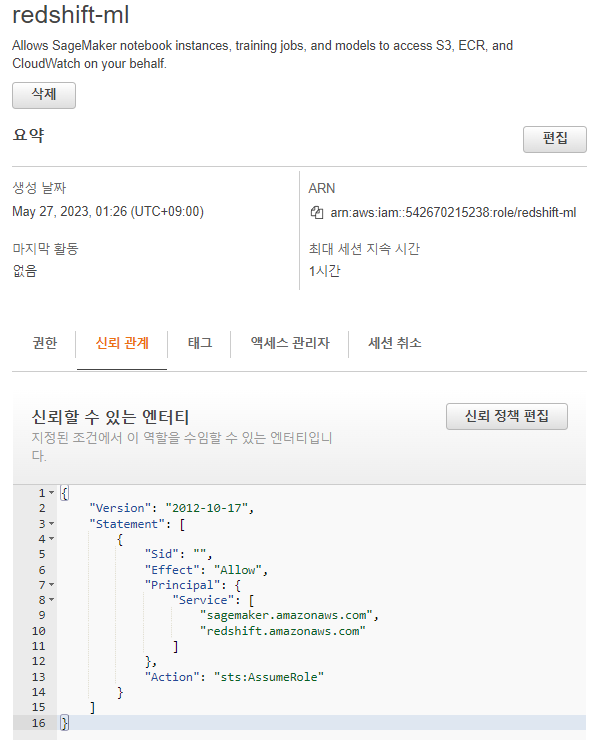
정상적으로 수행 이름은 바꿀수가 없어서 redshift-ml 로 다시 역할 만듦
이 역할을 레드쉬프트 클러스터 자체에 어소시에이트 시켜야함
aws 웹 콘솔에서 redshift 서버리스 방문
네임스페이스 디폴트 방문
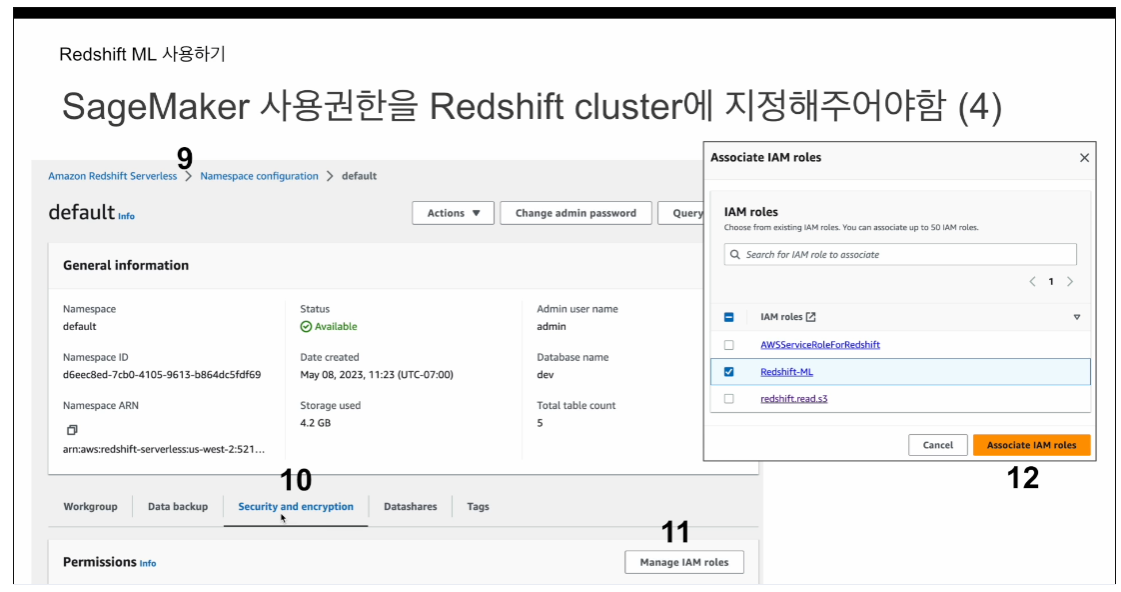
보안 및 암호화 방문
IAM 역할 관리에서 연결
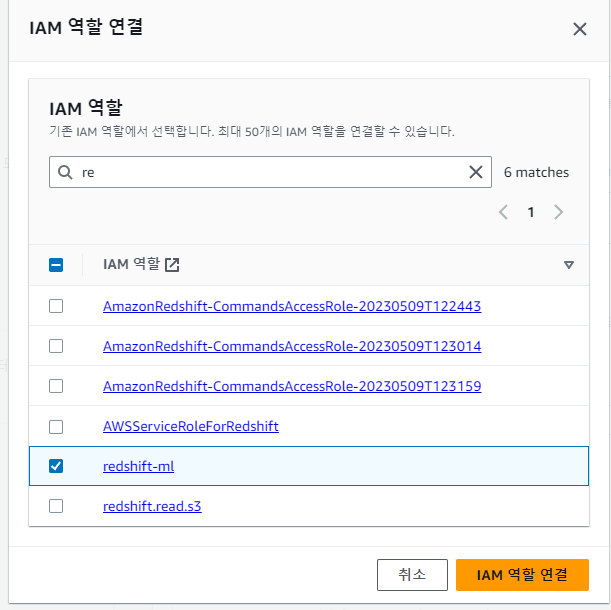
연결중
이제 CREATE MODEL 준비가 끝남
CREATE MODEL

CREATE MODEL orange_telecom_customers_model
FROM (
SELECT
state, account_length, churn
FROM raw_data.oragne_telecom_customers
WHERE purpose='Train'
)
TARGET churn
FUNCTION ml_fn_orange_telecom_customers
IAM_ROLE 'arn::~~:role/Redshift-ML'
SETTINGS(
S3_BUCKET 'jongwook-redshift-bucket'
)모델 이름을 수고, 인풋 피쳐들이 무엇인지 FROM에 부여, 아까 만들었던 테이블에서 purpose가 Train인 것만, 이때 select에서 purpose는 제외함. 어차피 훈련셋 구분용임
예측, 레이블 컬럼으로 TARGET churn으로 명시
모델을 최종적으로 만들었을때 sql 함수는 FUNCTION으로 부여
이런 것을 실행할 권한이 있다는 것을 증명하기 위해
redshift_ml의 arn 스트링을 지정
이 과정에서 sage maker auto pilot이 수많은 결과를 이하 버킷에 로깅을 하게 됨.
해당 버킷 밑에 폴더가 만들어짐. iam의 role의 이름으로 부여되고 나중에 폴더 날려야함. 상대적으로 큰 공간을 차지하기 때문
실행시키면 꽤 오랜 시간 (3~4시간) 후 모델을 사용할 수 있게됨.

SHOW MODEL을 주기적으로 실행
model state 트레이닝 -> 레디 상태
xgboost라는 결정트리 모델을 채택
이진 분류 문제였음
퍼포먼스 기준은 F1을 보기로 함.
모델이 사실 2개의 함수, _prove가 붙은 함수.
이탈 확률이 50% 보다 크면 이탈, 작으면 이탈 X
확률을 직접 조정하고 싶다. 75% 이상이면 이탈

purpose가 test인 경우
19개의 인자 주고, purpose 제외
함수의 인자로 테스트 데이터의 인자를 churn을 제외하고 넣은 뒤 이를 prediction이라는 이름으로 바꿈. 레이블을 출력. churn 값과 비교하게 됨
모델 제거, 청소

혹시라도 남은 잔재들을 찾아서 삭제해야함. 안그러면 비용나감


