학습주제
학습내용

iterrows는 index와 시리즈(딕셔러니 처럼 키,값)을 리턴. index는 정수값, 날짜등으로 구성. 대신 날짜를 쓰려면 strftime으로 형 변환 해야 쓸 수 있음.
from airflow import DAG
from airflow.decorators import task
from airflow.providers.postgres.hooks.postgres import PostgresHook
from datetime import datetime
from pandas import Timestamp
import yfinance as yf
import pandas as pd
import logging
def get_Redshift_connection(autocommit=True):
hook = PostgresHook(postgres_conn_id='redshift_dev_db')
conn = hook.get_conn()
conn.autocommit = autocommit
return conn.cursor()
@task
def get_historical_prices(symbol):
ticket = yf.Ticker(symbol)
data = ticket.history()
records = []
for index, row in data.iterrows():
date = index.strftime('%Y-%m-%d %H:%M:%S')
records.append([date, row["Open"], row["High"], row["Low"], row["Close"], row["Volume"]])
return records
@task
def load(schema, table, records):
logging.info("load started")
cur = get_Redshift_connection()
try:
cur.execute("BEGIN;")
cur.execute(f"DROP TABLE IF EXISTS {schema}.{table};")
cur.execute(f"""
CREATE TABLE {schema}.{table} (
date date,
"open" float,
high float,
low float,
close float,
volume bigint
);""")
for r in record:
sql = f"INSERT INTO {schema}.{table} VALUES ('{r[0]}', {r[1]}, {r[2]}, {r[3]}, {r[4]}, {r[5]});"
print(sql)
cur.execute(sql)
cur.execute("COMMIT;")
except Exception as error:
print(error)
cur.execute("ROLLBACK;")
raise
logging.info("load done")
with DAG(
dag_id = "UpdateSymbol",
start_date = datetime(2023,5,30),
catchup=False,
tags=['API'],
schedule = '0 10 * * *'
) as dag:
results = get_historical_prices("AAPL")
load("kjw9684k", "stock_info", results)위의 풀리프레쉬 형태의 코드를 인크리멘탈 업데이트 식으로 바꾸어 본다
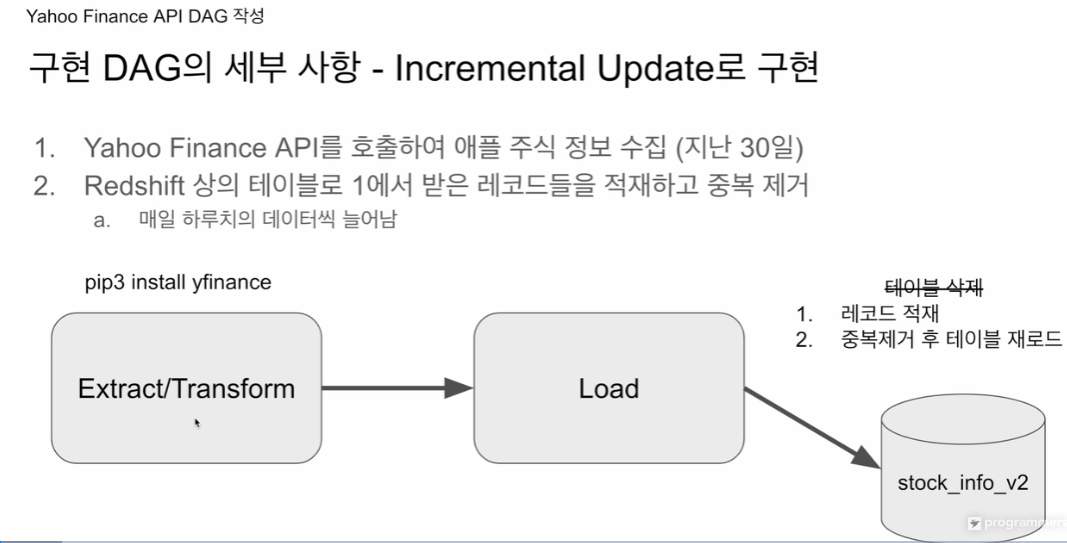
Load 부분이 바뀜.
앞단에서 풀리프레쉬 할땐 원본 테이블을 삭제 하고 새로 테이블 만들었음.
이제 인크리멘탈 업데이트는, 읽어오고, 중복제거 후 테이블 재로드
이 대그가 매일 실행된다면 하루씩 레코드가 늘어날 것임. 22, 23, 24개..
새로운 테이블을 만들것임.
스키마 자체는 동일 뒤에 v2를 붙일 예정.
적재방식: 1. 레코드 적재, 2. 중복제거 후 테이블 재로드. 유니크한 레코드들로 테이블을 재구성.
저게 조금 힘들어서, 원본 테이블을 임시테이블로 옮기고, 로딩한 값을 더함. 원본 테이블에 임시테이블에서 SELECT DISTINCT 값만 적재. 트랜잭션으로 두를 예정.
API 호출. 동일

앞단하고 동일함. 심볼로 티커를 호출해서 티켓을 만든뒤. history로 30일 데이터 추출. 이는 판다스 데이터 프레임이라 이를 index, row로 반복문 돌리는데 index는 바로 쓸수 없고 strftime으로 파이썬에서 쓸수 있게 형 변환. row는 키,밸류의 시리즈 값으로 바로 쓸수 있음.
append로 레코드에 한줄씩 입력

1. 임시테이블 생성하면서 현재 테이블의 레코드를 복사 (CREATE TEMP TABLE...AS SELECT)
- 세션이 끝나면 자동으로 없어지는 임시 테이블
- 임시 테이블로 야후 API로 읽어온 레코드를 적재
- 원본 테이블을 삭제하고 새로 생성
- 원본 테이블에 임시 테이블의 내용을 복사 (이 때 SELECT DISTINCT* 사용하여 중복 제거)
임시테이블은 에러나도 괜찮 트랜잭션은 4번 이후로. 트랜잭션은 최소로 거는게 좋음
트랜잭션 형태로 구성

코드를 보면
def _create_table(cur, schema, table, drop_first):
if drop_first:
cur.execute(f"DROP TABLE IF EXISTS {schema}.{table};")
cur.execute(f"""CREATE TABLE IF NOT EXISTS {schema}.{table} (
date date,
"open" float,
high float,
low float,
close float,
volume bigint
);""")
def load(schema, table, records):
cur = get_Redshift_connection()
try:
cur.execute("BEGINl;")
# 원본테이블 생성- 테이블이 처음 한번 만들어질 때 필요
# 임시테이블로 원본테이블을 복사해야되기 때문 (스키마 필요)
# 이후는 기본 테이블이 있기 때문에 새로 생성 안함.
_create_table(cur, schema, table, False)
# 임시테이블로 원본 테이블 복사
# 처음일 경우, 빈 테이블 복사
cur.execute(f"CREATE TEMP TABLE t AS SELECT * FROM {schema}.{table};")
for r in records:
sql = f"INSERT INTO t VALUSES ('{r[0]}',{r[1]},{r[2]},{r[3]},{r[4]},{r[5]};"
cur.execute(sql)
# 원본 테이블 생성
# 기존에 있던 테이블을 밀어버리고 신규 테이블 생성
_create_table(cur, schema, table, True)
# 임시 테이블 내용을 원본 테이블로 복사
# 행이 같은 경우 제외하는 SELECT DISTINCT *
cur.execute(f"INSERT INTO {schema}.{table} SELECT DISTINCT * FROM t;)
cur.execute("COMMIT;")
except (Exception, psycopg2.DatabaseError) as error:
print(error)
cur.execute("ROLLBACK;")drop_first 쓰는 이유: 항상 테이블을 드랍하고 새로 만들어서 문제 없었음. 인크리멘탈 업데이트는 원본테이블이 유지가 되어야 함. 처음 들어갈땐 혹시라도 처음 실행된 경우라면 그 경우에 만드는 것. -> 그런데 DROP TABLE IF EXISTS 면 어차피 존재하지 않으니까 패스되지 않나? -> 강조의 의미인가?
뒷단에선 삭제, 원본테이블 생성(스키마만) 임시테이블 내용을 원본으로 넘김
CREATE TEMP TABLE t를 사용하면 세션 끝나면 알아서 테이블 없어짐.
중복을 제거할 경우, 새 값이 나중에 들어왔기 때문에, 자연스럽게 기존 내용 다음 레코드에 새 레코드가 들어가는 형태.

대그에 태스크 부분을 보면
result = get_historical_prices("AAPL")
load("kjw9684k", "stock_info_v2", results)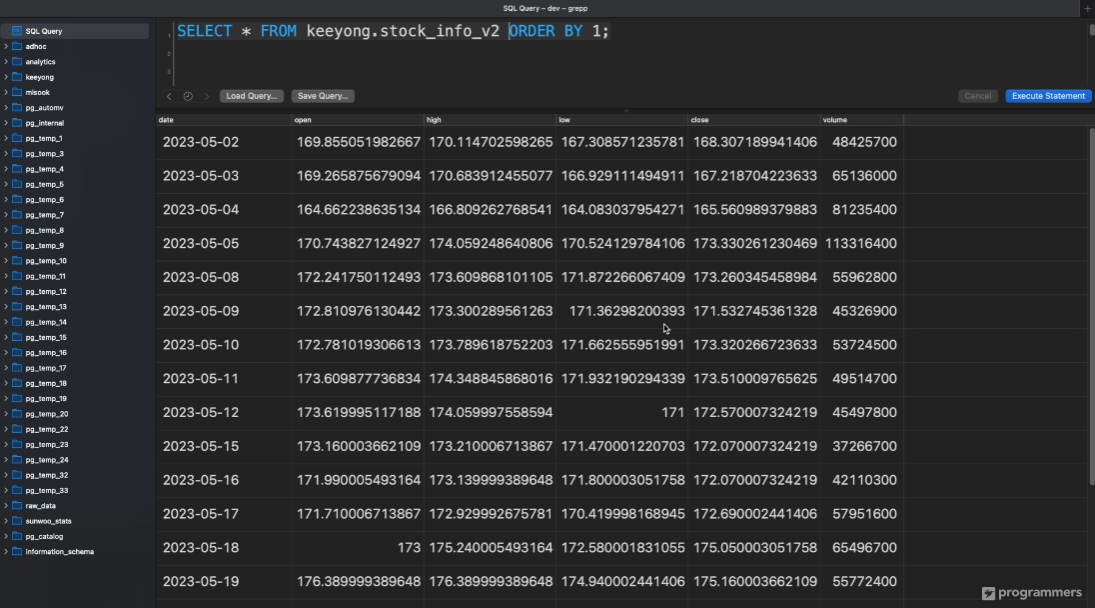
sql 클라이언트 툴임
postgres 계열의 관계형데이터베이스 쿼리하는데 사용
순차적으로 적재된 것을 확인.
한번 더 개를 실행하면
레코드가 하나 더 붙을 것임.
웹 UI에서 대그 실행해보고
하루치 추가됐는지 확인
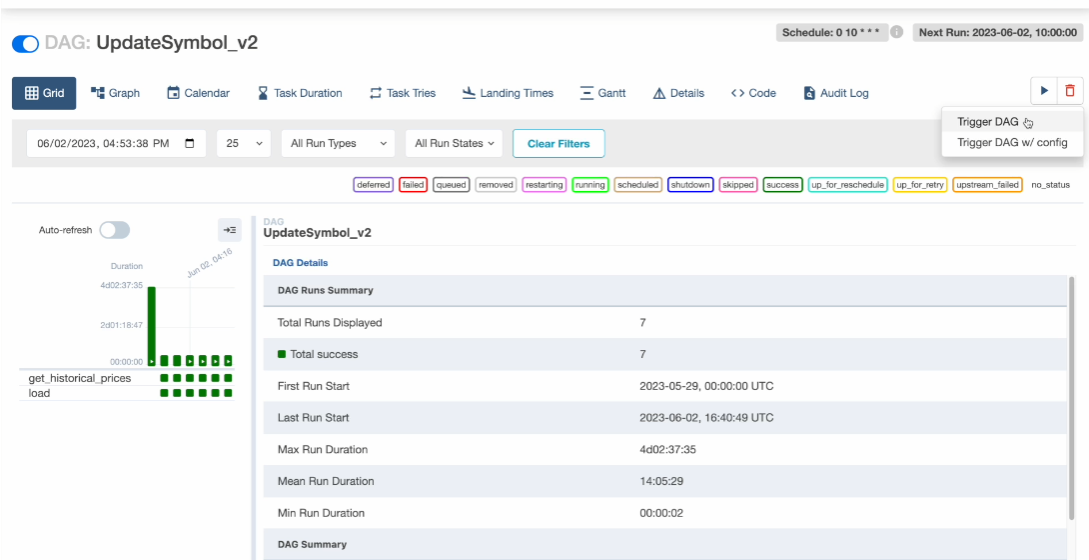
포스티코로 돌아와 sql을 다시 실행시켜 본다
23개의 레코드가 나왔고
6월 2일 정보가 추가된 것을 확인
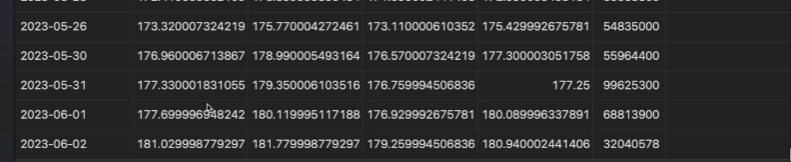
오늘은 일반적인 형태, 여러 인크리멘탈 업데이트가 있다.
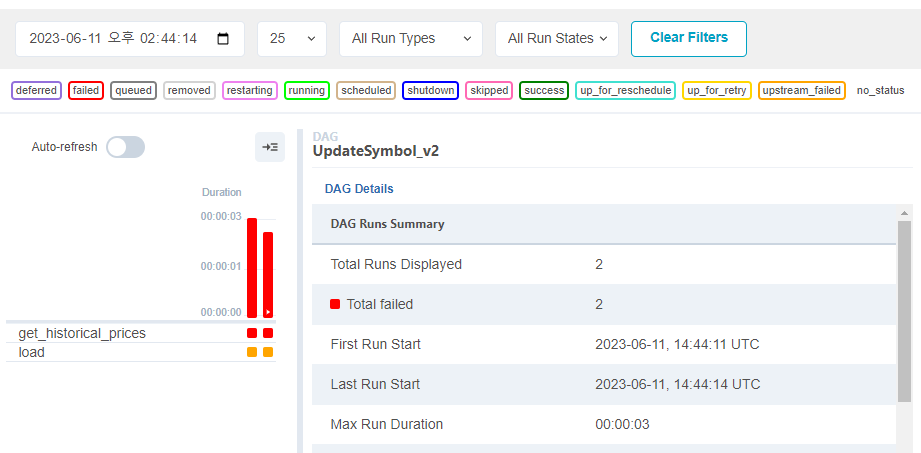
값을 변경한지 얼마 되지 않아 실패한듯
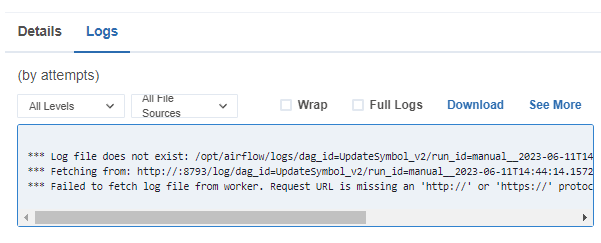
또 로그파일이 없다고 하는데..
루트로 로그인 하지 말고 스케줄러에 로그인해야 실행시켜볼 수 있음.
CLI에선 성공하는데 웹 UI에선 실패하는 이슈 발생.
그리고 로그도 전처럼 안뜸
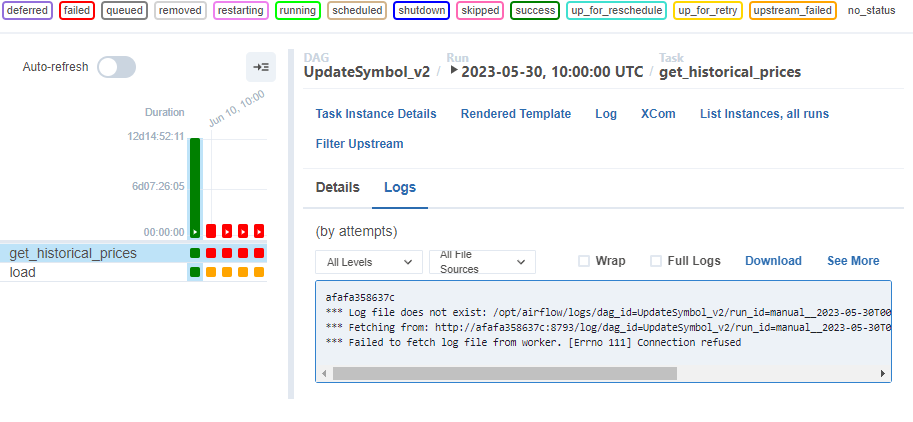
오늘 수업 야후 API 사용 전까지는 스케줄러가 정상적으로 로그를 생성했고, CLI에서 스케줄러에 직접 접속했을 때는 대그가 돌아가는 것으로 봐서,
루트 계정에서 yfinance를 설치해본다.
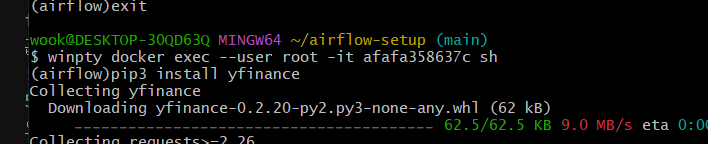
정상적으로 설치됨.
웹 UI에서 실행시켜본다.
실패함. 각 컨테이너가 아닌, 스케줄러에서만 또 설치함.,
가능하다면 Dockerfile이나 Docker Compose 파일에 필요한 패키지 설치 단계를 추가하는 것이 더 효율적입니다. 이렇게 하면 컨테이너를 시작할 때마다 자동으로 패키지를 설치할 수 있습니다.
이 방식을 권장하고 있음.
근데 저것도 잘 모르겠음.
이에
from airflow.operators.python_operator import PythonOperator
# pip install 작업을 위한 함수
@task
def install_packages():
import subprocess
subprocess.check_call(['pip', 'install', 'yfinance'])
with DAG(
) as dag:
install_packages()태스크 형식으로 실행시켜본다.
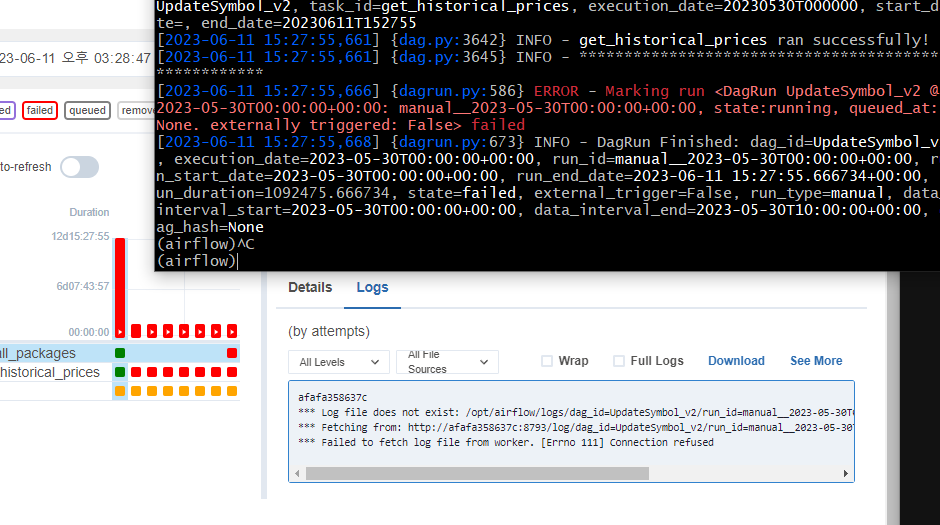
뭔가 실패함.
위의 코드를 지우고 다시 실행하니 성공함
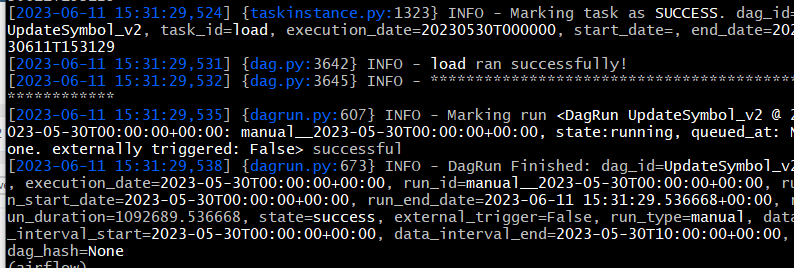
매번 저렇게 설치는 불안정하다고 한다. 한번 yml로 설치시도해본다
_PIP_ADDITIONAL_REQUIREMENTS환경 변수는 Docker-compose 파일 내의 여러 서비스(airflow-webserver, airflow-scheduler, airflow-worker 등)에서 공통으로 사용하는 &airflow-common-env 환경 변수 세트에 추가해야 합니다.
예를 들어, pandas와 numpy를 설치하려면, 파일의 &airflow-common-env 부분을 다음과 같이 수정해야 합니다:
environment:
&airflow-common-env
AIRFLOW__CORE__EXECUTOR: CeleryExecutor
AIRFLOW__DATABASE__SQL_ALCHEMY_CONN: postgresql+psycopg2://airflow:airflow@postgres/airflow
# For backward compatibility, with Airflow <2.3
AIRFLOW__CORE__SQL_ALCHEMY_CONN: postgresql+psycopg2://airflow:airflow@postgres/airflow
AIRFLOW__CELERY__RESULT_BACKEND: db+postgresql://airflow:airflow@postgres/airflow
AIRFLOW__CELERY__BROKER_URL: redis://:@redis:6379/0
AIRFLOW__CORE__FERNET_KEY: ''
AIRFLOW__CORE__DAGS_ARE_PAUSED_AT_CREATION: 'true'
AIRFLOW__CORE__LOAD_EXAMPLES: 'true'
AIRFLOW__API__AUTH_BACKENDS: 'airflow.api.auth.backend.basic_auth,airflow.api.auth.backend.session'
_PIP_ADDITIONAL_REQUIREMENTS: pandas,numpy # 이 부분을 추가저렇게 하면 공통 부분 컨테이너에 모든 pip 모듈이 설치됨.
추가해봤다.
다시 컨테이너 내리고
docker compose up --build로
변경된 yml을 적용시킨다.
저번에 ID 적용했던건 어떻게 되려나 모르겠음.
잘못했다고 한다, 공백으로 구분해야한다고 한다. up을 하니 계속 설치시도만 함
_PIP_ADDITIONAL_REQUIREMENTS: pandas numpy yfinance
수정 후, 컨테이너 재가동
오 뭔가 잘 돌아가는거 같음.
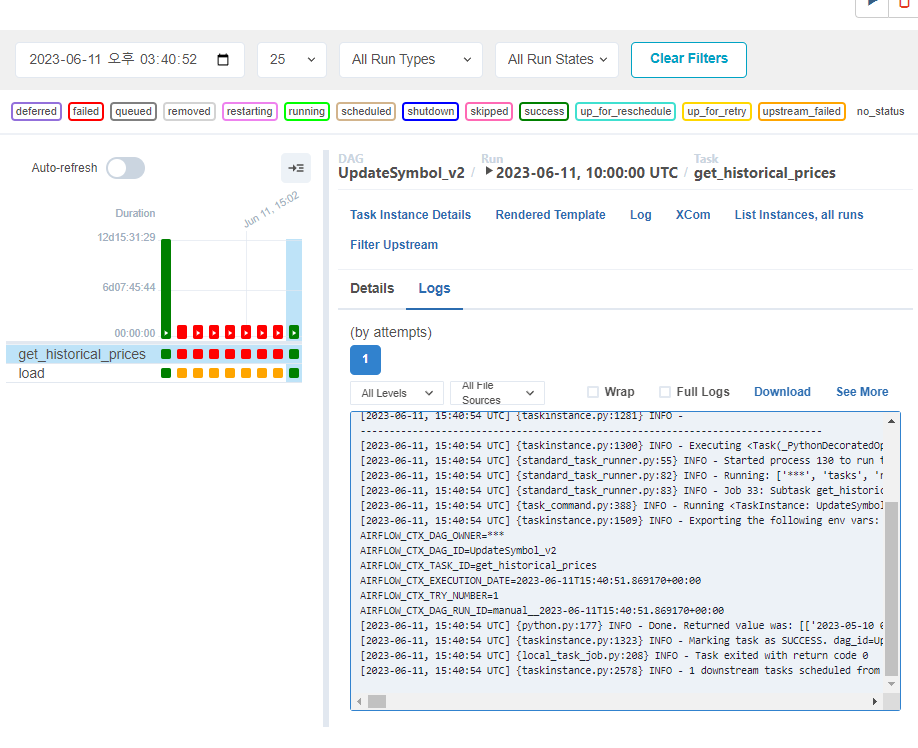
성공!!!!
모든 컨테이어에 관련 모듈을 설치해주는 게 중요했음!!!!
추가
https://airflow.apache.org/docs/apache-airflow/stable/howto/docker-compose/index.html
우분투에서 PIP 저거 인식 안됨.
정정.
vs code에서 파일 저장을 안한거 같음. 신뢰할 수 없는 파일이거 해제 안함.
지금 정상적으로 설치하는 것 같음. 뭔가 길어짐.
해결됨.
모듈 정상적으로 설치함.
