학습주제
학습내용

현업에서 에어플로우


간편한 관리: MWAA는 완전 관리형 서비스로, 인프라 구성, 관리 및 운영에 대한 부담을 덜어줍니다. 사용자는 Airflow 클러스터를 설정하고 관리하는 데 필요한 시간과 리소스를 절약할 수 있습니다.
확장성: MWAA는 클라우드 내에서 자동으로 확장될 수 있습니다. 데이터 파이프라인이 더 많은 작업 부하를 처리해야 할 때, MWAA는 자동으로 필요한 리소스를 할당하여 처리 능력을 확장합니다.
안정성과 신뢰성: MWAA는 AWS의 인프라를 기반으로 하기 때문에 안정성과 신뢰성이 보장됩니다. AWS는 세계적으로 안정적인 클라우드 서비스를 제공하며, MWAA는 이러한 신뢰성을 활용하여 안정적으로 데이터 파이프라인을 운영할 수 있습니다.
통합된 AWS 생태계: MWAA는 다른 AWS 서비스와의 통합을 강화합니다. 예를 들어, S3, Redshift, Glue, Athena 등의 AWS 서비스와 원활하게 연동하여 데이터 파이프라인을 구축하고 운영할 수 있습니다. 이를 통해 데이터 이동, 변환, 분석 등을 효율적으로 수행할 수 있습니다.
보안: MWAA는 AWS의 보안 기능을 활용하여 데이터와 인프라를 보호합니다. AWS는 높은 보안 표준을 준수하며, MWAA를 사용함으로써 데이터 파이프라인의 보안을 강화할 수 있습니다.


데이터 엔지니어 5분
2번째로 추출을 많이 한 사람
회사에 가면 추출을 많이 하게됨.
할수 있는게 없으면, 추출을 하게 될 수 도 잇고, 유관부서 요청 등

뭔가 쳐낼 수 있는 성장감.
커뮤 능력
단점.
엔지니어 성장 한계
자동화를 할 수는 없을까?

데이터 레이크를 쌓고, DW로 미리 만들어 놓자. -> 쌓여진 지표를 가지고 가져다 쓸 수 있게.
그래도 유관부터 추출 요청은 있음.
기본적인 지표는 나가고 있음. -> 디테일 한걸 보고싶으면 요청을 하게됨.
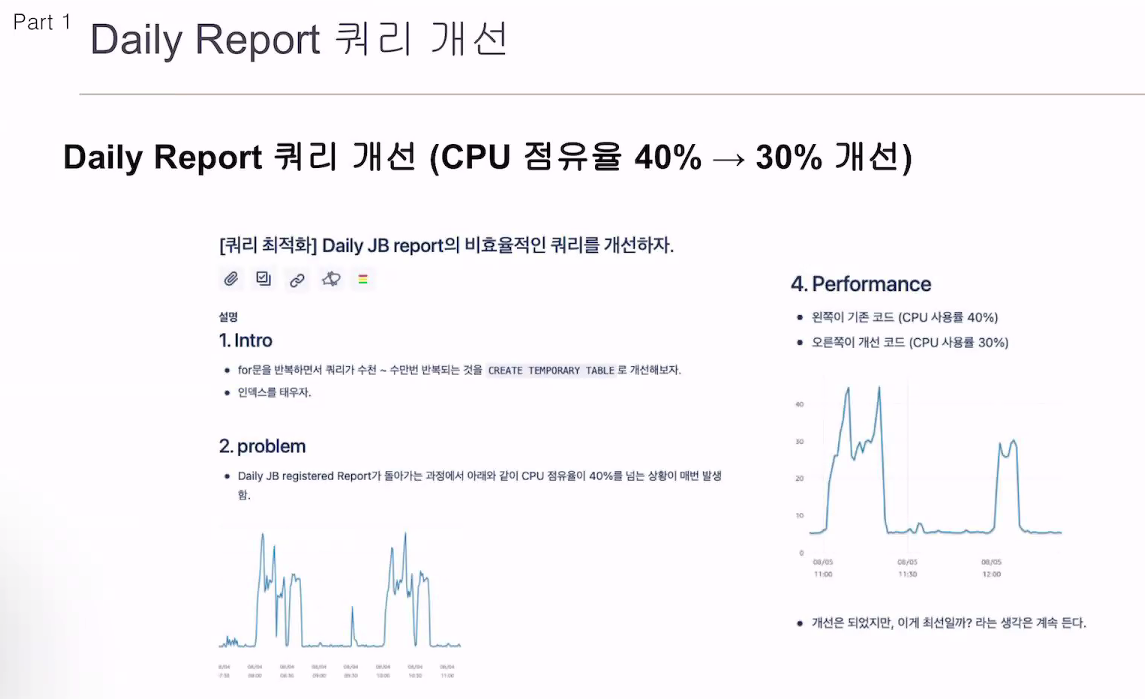
누가 시키지 않았지만, 개선작업을 진행시켜봄.
40% -> 30% 로 줄었지만 이게 최선일까? 라는 생각이 들었음.

단순 쿼리였음.
전체 유저의 정보를 가져와서, rds 접속. 유저별로 for문을 돌면서 db에 셀렉트를 날림.
mysql을 사용해 temp 테이블을 써서 한번에 쓸수 있게 함.


DW -> 데이터 파이프라인을 설계하자.
개인환경에서만 동작. 개인 PC에서만 동작. 유지보수하는 것도 오래걸림. 개선도 오래걸렸었음.
Airflow와 같은 공통 환경에 올려서 관리하자는 목표가 생김.

대그 팩토리 패턴에 대한 고민.
airflow 코드를 하나씩 까보고 있음.


사전 지식 설명
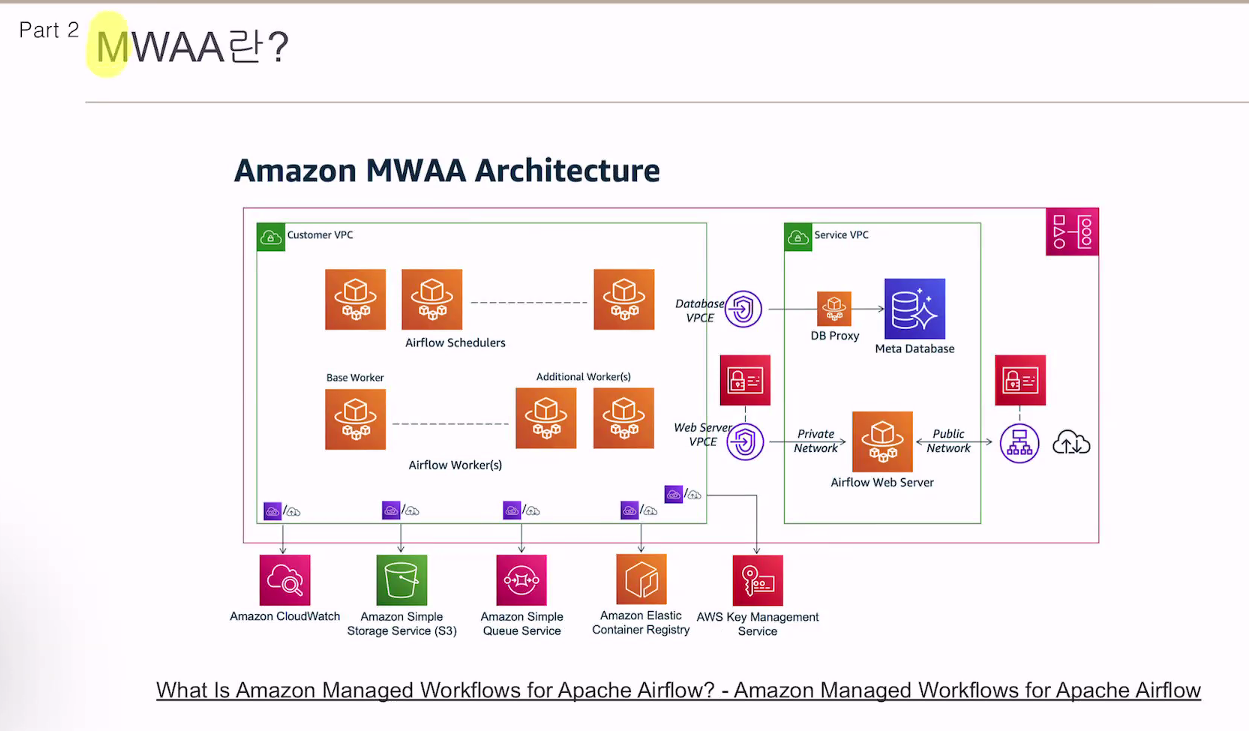
아마존에서
워커, 스케줄러, 데이터베이스, 큐 등을 관리해줌.
사용자는 환경에 대해 생각할 필요 없이 사용만 하면 됨.
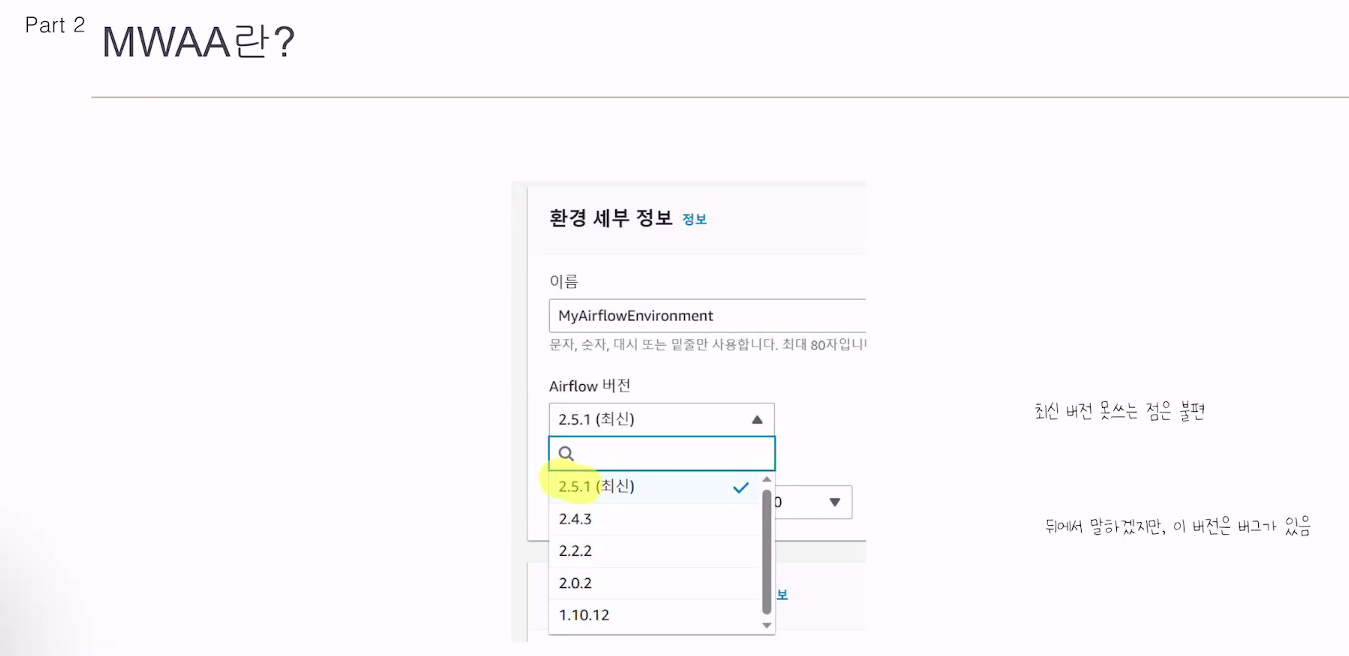
아랫버전에선 1가지 버그가 있음. 개선하지 못하고 아마존에서 지정한 버전만 사용할 수 있음.
데이터 파이프라임 핵심 가이드 읽어보기.
흐름에 대해 이해하는데 도움이 될 것임.
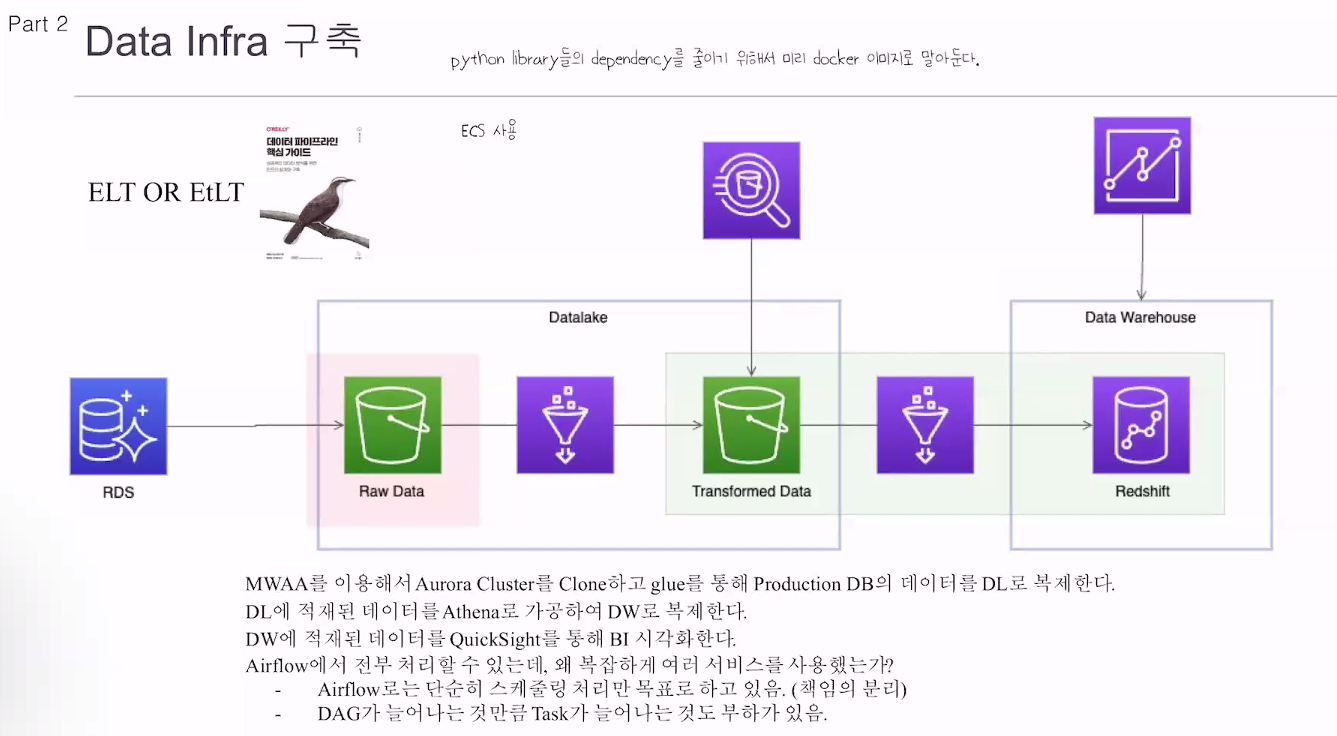
글루, 아테나를 굳이 쓰는 이유? 에어플로우는 단순 스케줄링 처리만 목표로 하고 있음.
에어플로우가 복잡해지는 문제도 있음. 여러서비스를 사용하면서 책임을 분리시킴.
대그가 늘어나는 것만큼 태스크가 늘어나는것도 부하가 있음.
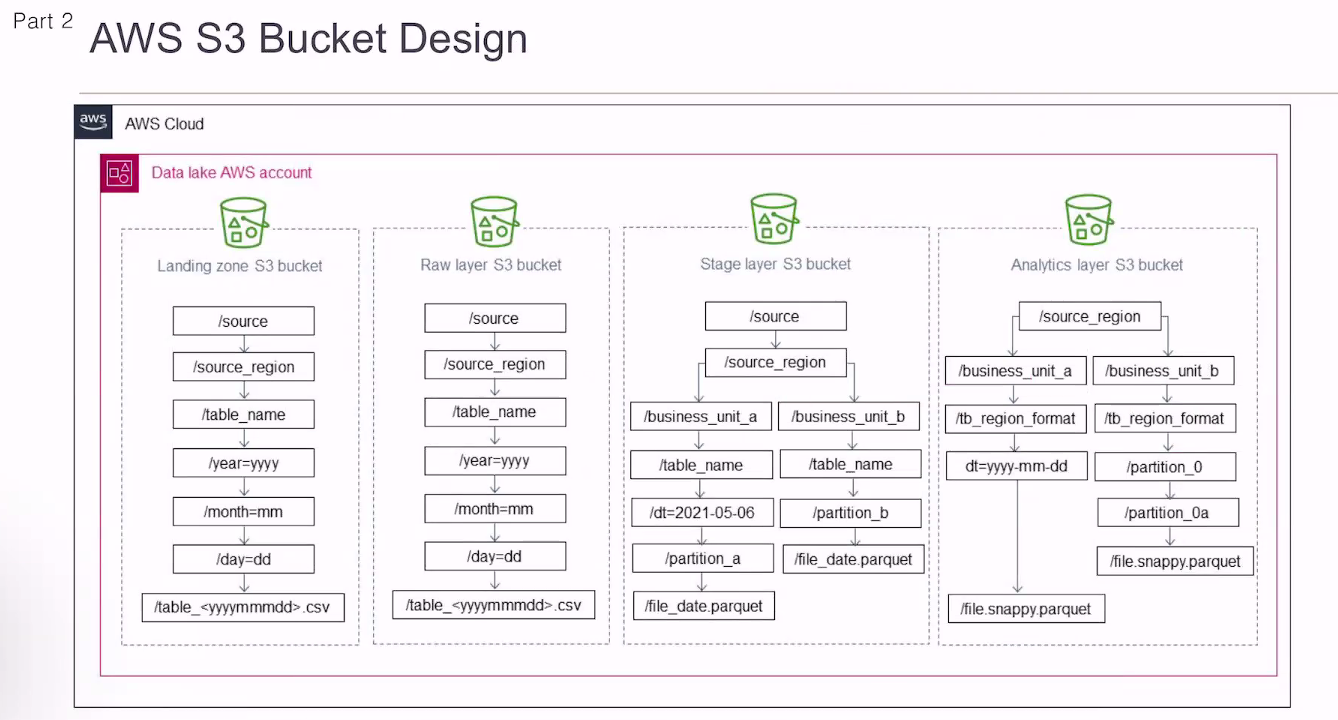
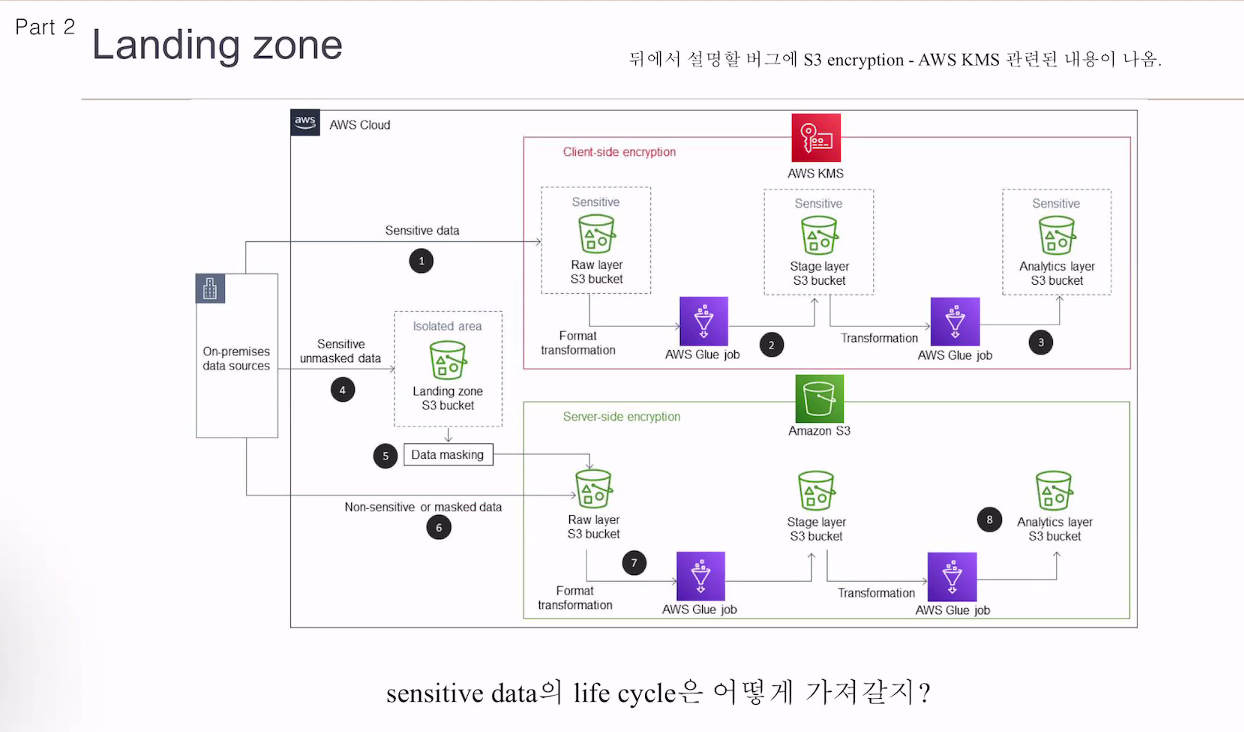
개인정보, 민감정보는 DW에 올릴 필요 없음.
민감정보는 다 필터링해서 DL에 적재하지 않고 있음.
10년전 데이터를 오늘 쓸 확률이 얼마나 될까?
없으면 버킷에 넣을 필요가 없음.
버킷도 버킷에 따라 비용이 다름. 잘 사용하지 않는 버킷은 잃어버려도 상관 없겠다 싶은, 싼곳에 적재.
데이터 거버넌스 얘기 -> 라이프 사이클

크론탭을 쓰지 않고 왜 에어플로우 썼냐
- 백필. 크론탭에선 할순 있지만 거의 못하는 작업.

공식적으로 스트리밍 작업 지원 X
카프카 등을 사용함
오퍼레이터 목록을 보면 상당히 많음. 가져다 쓰기만 하면 됨.
쉽게 다른 서비스를 쓸 수 있음.
업데이트가 빠름.
버그 등이 빠르게 픽스가 됨.
맥스님은 안정된 버전을 쓰는게 좋다고 하심.
도큐먼트가 잘 정리가 되어 있음
단점 - 러닝 커브
logical date(execution date) -> execution date -> logical_date을 쓰라고 권장.
두개 똑같음.
이거에 대한 러닝커브가 심하다
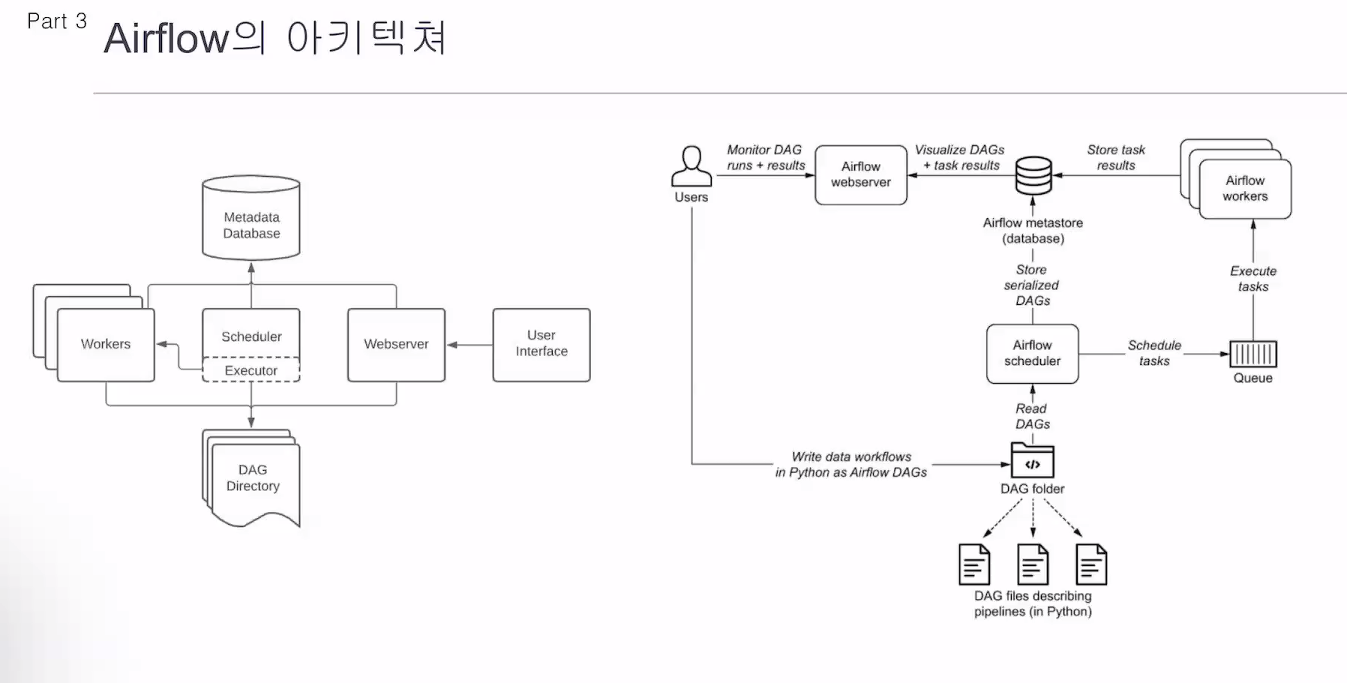
유저는 대그를 생성
웹서버에서 대그를 돌림
스케줄러가 스케줄링을 하고 큐에 넣음. 워커가 큐에 있는 작업을 가져가서, 결과를 냄.
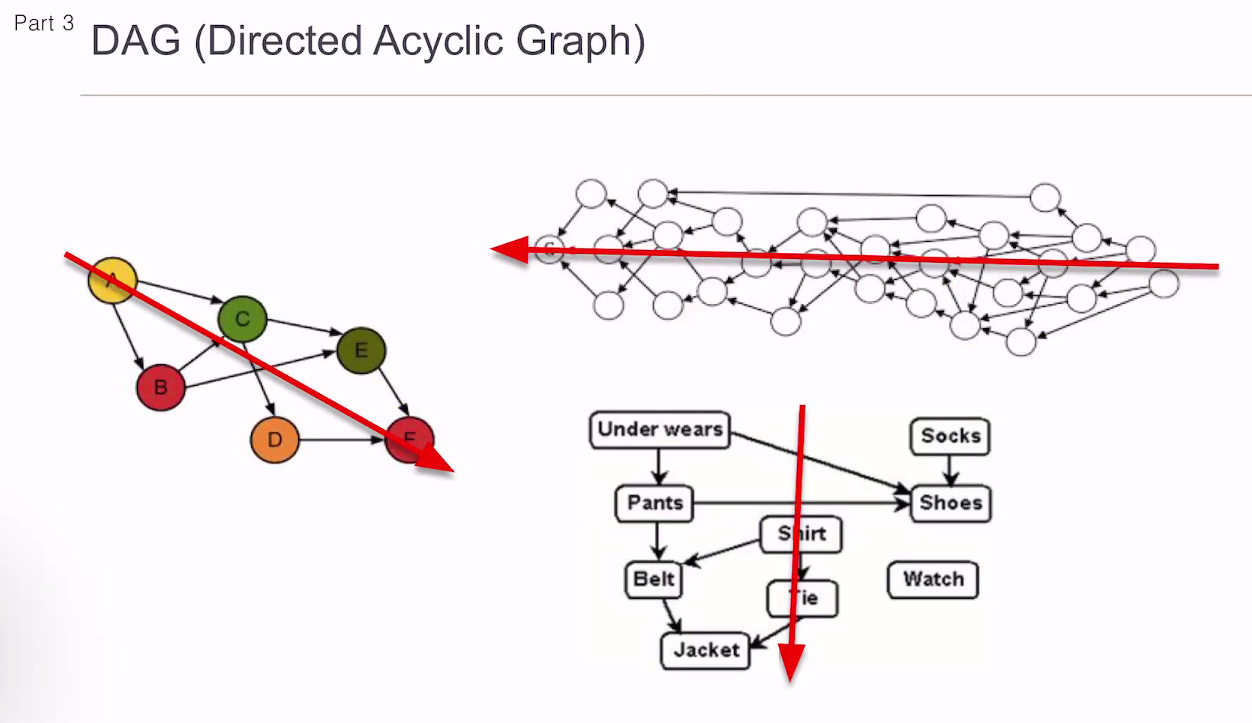
방향성만 있고 순환하지 않음.
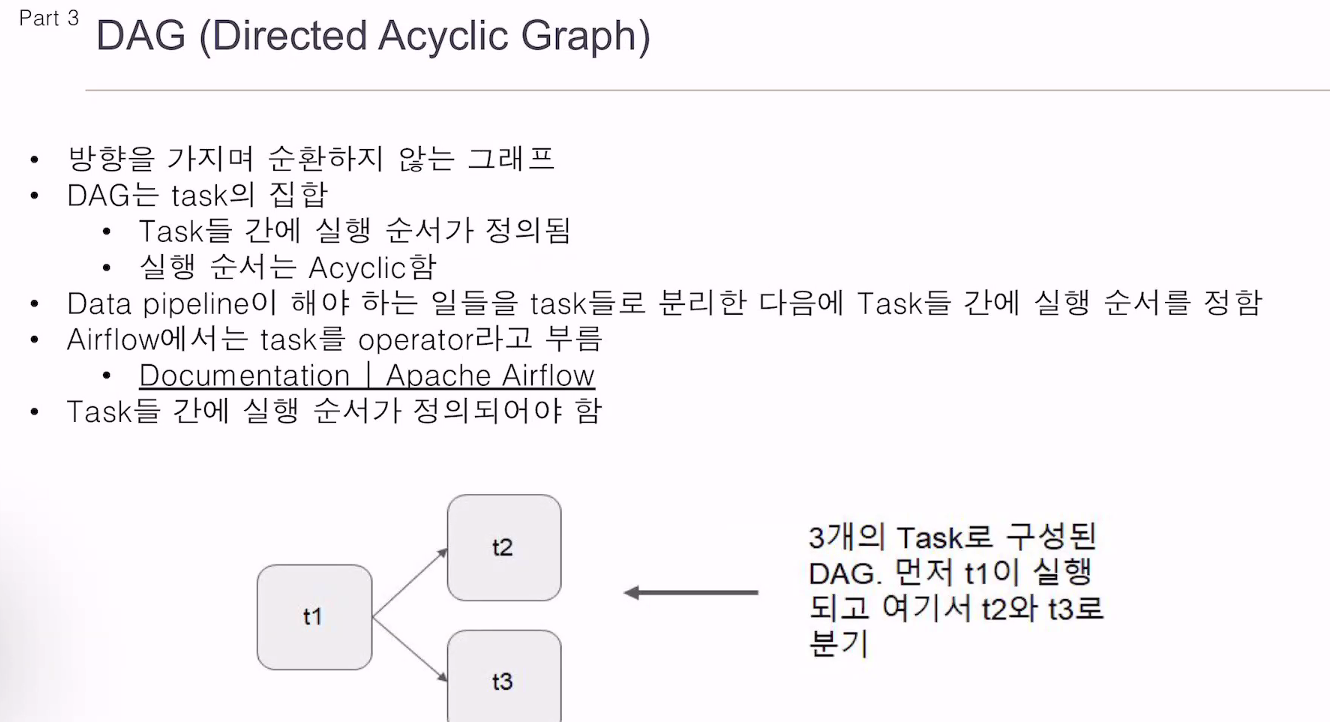
대그는 순환하면 안됨.
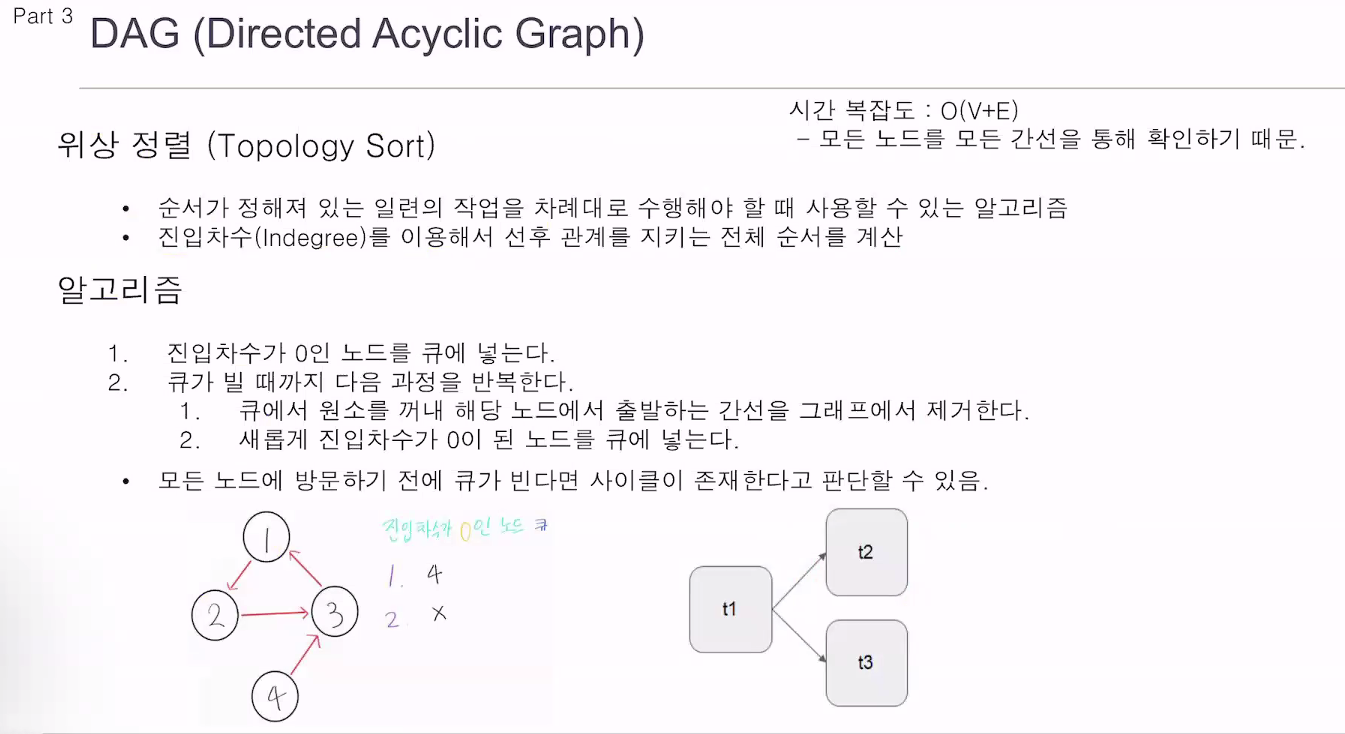
위상 정렬
대그랑 똑같이 보면 됨.


모든 에어플로우 대그가 멱등성이 꼭 보장되지는 않음. 아닐수도 있음.
대그는 간단하게
공통 모듈, 태스크 그룹 코드화를 시켜놓기.
variable로 환경별 구분? 개발환경, 실환경 구분.
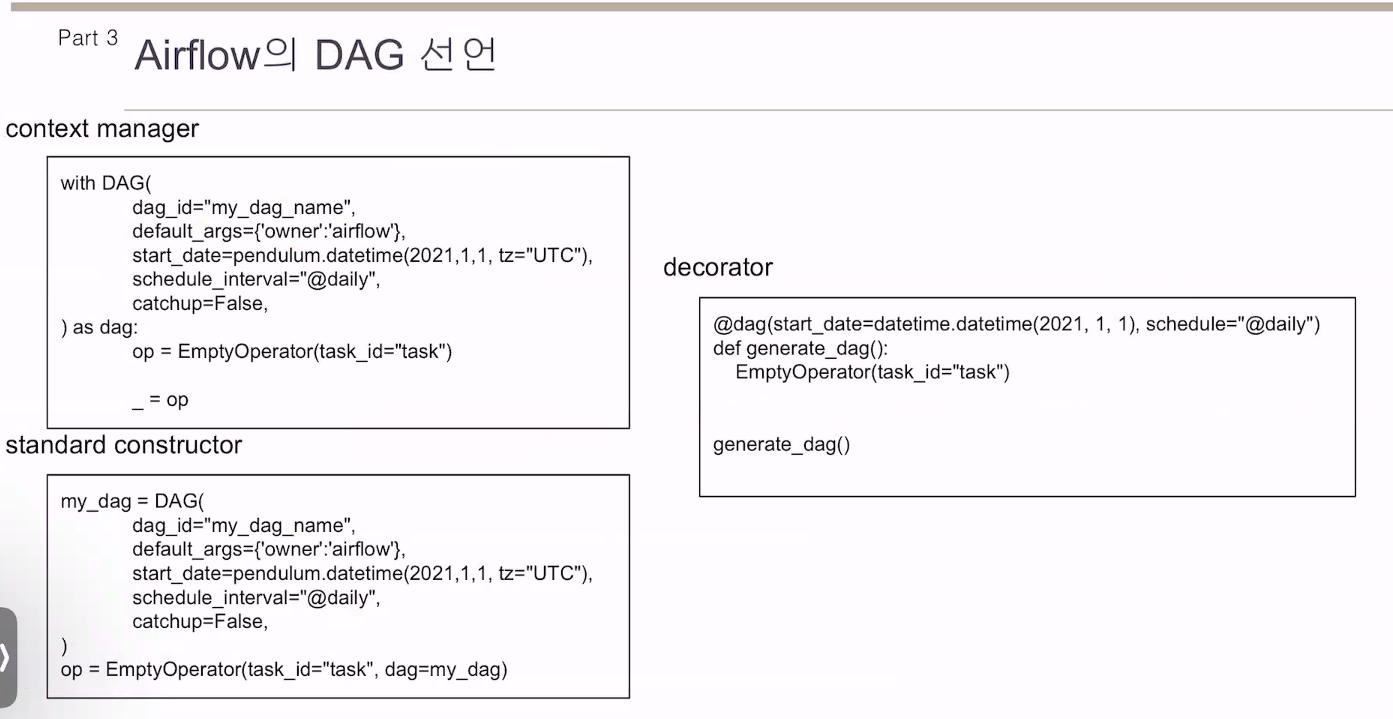
context manager 방식을 주로 사용
standard의 경우 dag를 연결해줘야 하는 귀찮은 점.
대그에 10의 태스크가 있다면 일일히 써줘야함.

모든 기능을 다 알필요는 없음. 이런것들이 있다.
오픈소스 코드들이 100% 완벽히 동작하고 그런건 아님.
에러 있을 수 있고, 버그도 있을 수 있음.
Operator: 코드가 돌아가고 액션이 취해지고 결과를 받는다.
Sensor: 오퍼레이터와 비슷. 어떤 행동이 실행되었는지 체크, 실행되었으면 True, 아님 False만 뱉음. S3 버킷을 감시하고 있음.
센서는 True가 될 때까지 반복을 시킴. 빠른 서비스기 때문에 아테나로 어떤 쿼리를 실행시킴. 정상적으로 실행시켰다면 execution_id를 뱉고 끝냄. 아테나 센서를 붙여서 이 쿼리가 성공했는지, 실패했는지를 체크. False가
hook
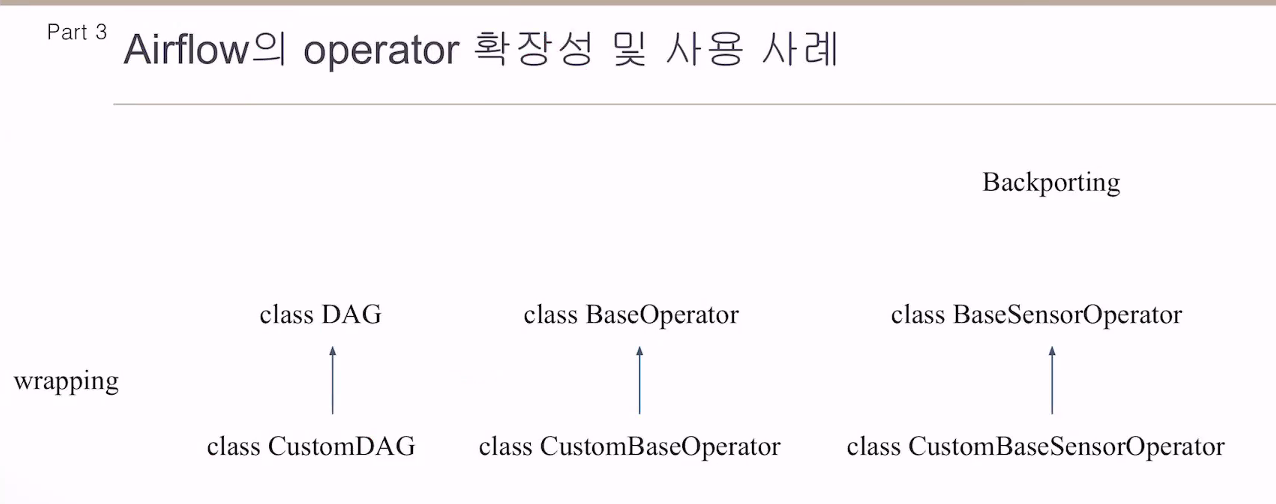
백포팅, 래핑
카카오에선 오픈소스를 사용할 때 반드시, 래핑해서 쓰게 되어 있음.
버그, 비효율적인 부분 개선을 위해 래핑해서 쓰고 있음.
실제로 대그는 파라미터가 굉장히 많음.

디폴트로 사용하는 커스텀대그가 있음. 자주 사용하는 것들은 래핑함.
무조건 백필성 작업만 한다면 catchup을 True
코드를 작성할 때 덜 귀찮게끔.
사용자가 굳이 쓸 필요 없는건 디폴트로 값을 주고 사용
오퍼레이터도 커스텀으로 만들 때 자주 사용하는게 있음.
중복되는 코드들이 있다면, 상속받아서 처리할 수 있게함.
센서오퍼레이터도 백포팅
목적
에어플로우(Airflow) 백포팅(Backporting)은 특정 버전의 에어플로우에서 새로운 기능이나 버그 수정을 이전 버전으로 되돌려 적용하는 과정을 말합니다.
일반적으로 새로운 에어플로우 버전은 새로운 기능, 개선 사항 및 버그 수정을 포함하고 있습니다. 그러나 에어플로우를 사용하는 사용자 또는 조직은 현재 운영 중인 버전에서 작동하는 것으로 확인된 기능과 안정성을 원할 수 있습니다. 때문에 새로운 버전을 전환하기 전에 적절한 테스트와 검증 과정이 필요합니다.
에어플로우 백포팅은 이러한 상황에서 새로운 버전의 에어플로우에서 특정 기능 또는 버그 수정을 추출하여 이전 버전에 적용하는 과정입니다. 이를 통해 이전 버전에서 원하는 기능이나 수정 사항을 활용할 수 있으며, 안정성과 신뢰성을 유지할 수 있습니다.
오버라이딩은 상속 관계에서 부모 클래스의 메서드를 자식 클래스에서 재정의하는 것이고, 오버로딩은 같은 클래스 내에서 메서드 이름을 동일하게 유지하면서 매개변수의 타입, 개수, 순서를 다르게하여 여러 개의 메서드를 정의하는 것입니다.

센서(Sensor)는 에어플로우(Airflow)에서 사용되는 개념으로, 특정 이벤트 또는 상태 변화를 감지하고 작업(task)을 실행하기 위해 사용됩니다. 센서는 워크플로우에서 특정 조건이 충족될 때까지 대기하며, 조건이 충족되면 작업을 실행하거나 다음 단계로 진행합니다.
poke와 reschedule은 센서의 두 가지 주요 동작 방식입니다.
poke:
poke는 센서가 주기적으로 상태를 확인하고 조건이 충족될 때까지 반복적으로 대기하는 방식입니다. 센서는 정해진 주기로 특정 조건을 확인하고, 조건이 충족되면 작업을 실행하거나 다음 단계로 진행합니다. 예를 들어, 파일의 존재를 감지하거나 특정 시간이 되었는지 확인하는 등의 작업을 수행할 수 있습니다.
reschedule:
reschedule은 센서가 조건이 충족되지 않아서 작업을 실행하지 않고 대기 상태로 남아 있는 경우, 센서가 다시 스케줄링되어 조건을 확인하는 방식입니다. 즉, 센서는 조건이 충족되지 않으면 일정 시간 후에 다시 스케줄링되어 조건을 다시 확인합니다. 이를 통해 센서는 작업이 실행될 때까지 반복적으로 조건을 확인하고 대기합니다.
poke와 reschedule은 센서의 동작 방식을 다르게 조정하기 위해 사용됩니다. 어떤 센서가 사용될지는 워크플로우의 요구 사항과 조건에 따라 결정됩니다.
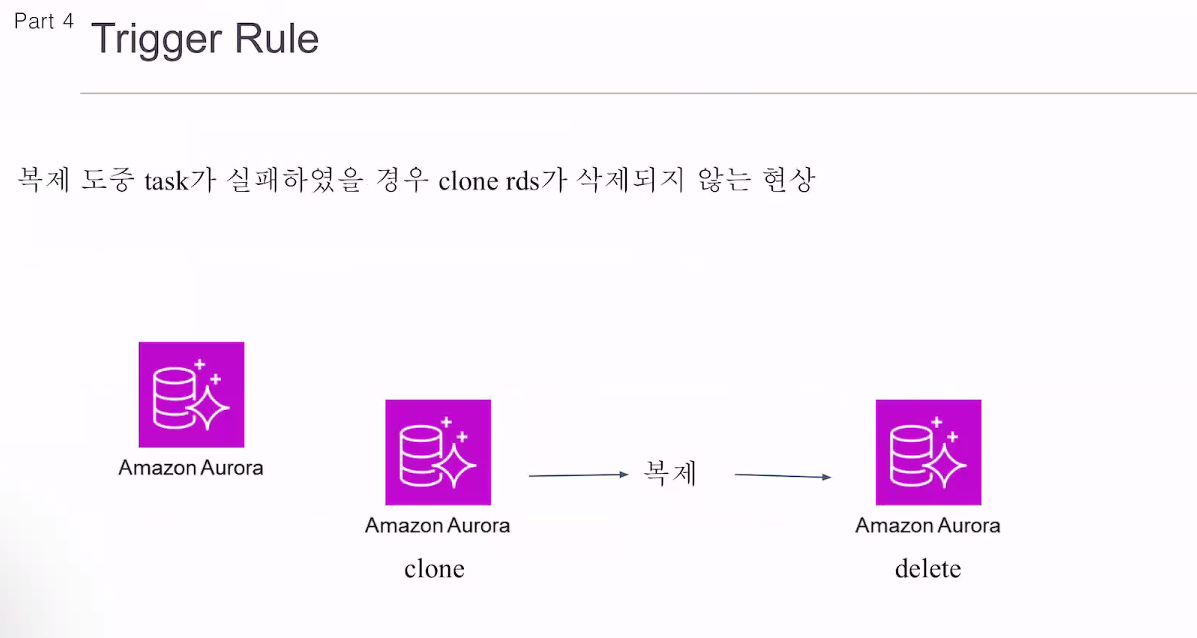
태스크가 실패하면
센서는 리트라이를 시킴.
포크 같은경우 태스크를 계속 점유하고 있음.
최대 1개의 태스크. 30초 동안 워커가 물고 있게됨. 워커는 기본 1개 태스크만 처리할 수 있음.
센서가 워커를 30초동안 물고 있게 됨.
리스케줄.
한번 실패하면 10초동안 물고있는게 아니라, 한번 시도하고 센서가 실패하면 리스케줄의 경우 리트라이 타임동안 놔버림.
스케줄에 다시 등록됨.

인크리맨탈 업데이트
스냅샷
풀리프레쉬
풀리프레쉬는 쓰지 않음. 필요상 스냅샷을 찍고, 인크리멘탈 업데이트.
은행이라고 치면, 입출금 기록. 업데이트, 딜리트 없음. 인서트만 있음.
스냅샷은
유저의 탈퇴, 휴먼 전환
키워드만 기억해놓기
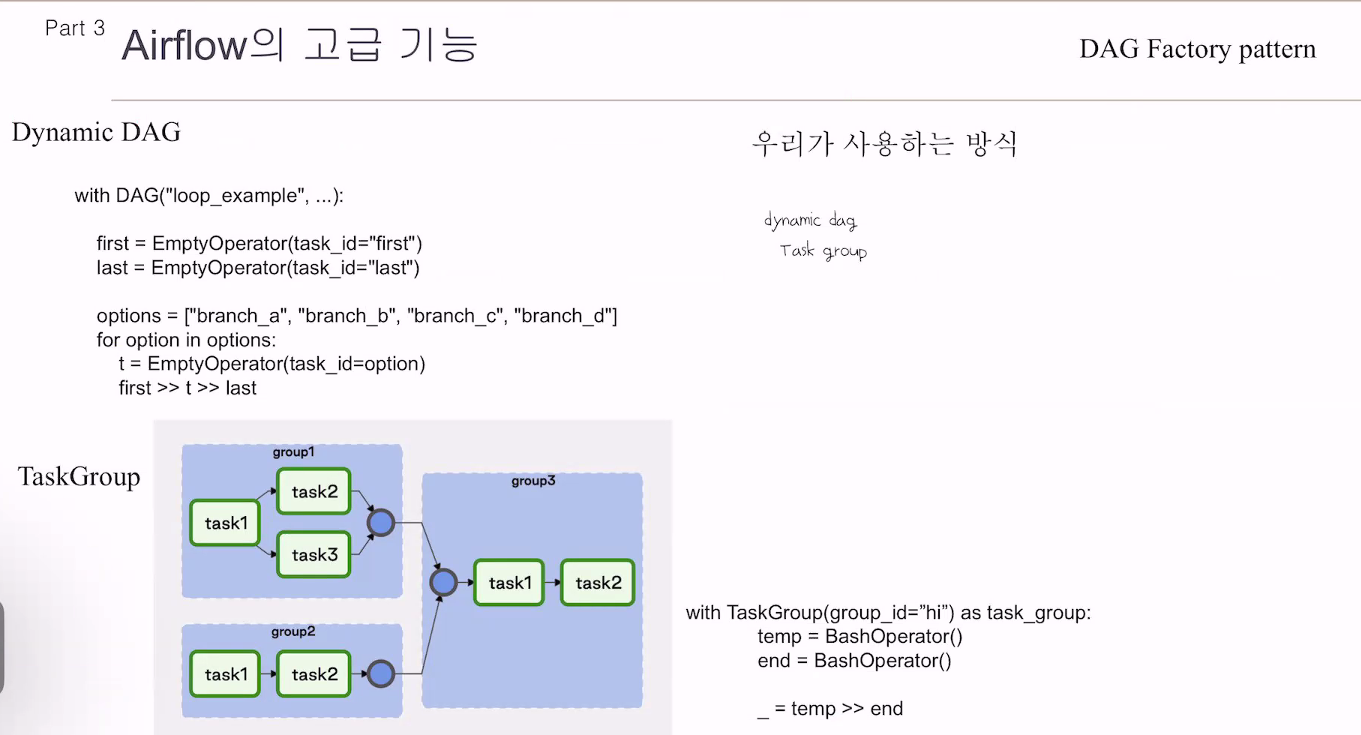
Dynamic DAG
기존 대그작성은
DAG:
task
task
태스크를 다 작성하는 방식.
옵션이라는 리스트가 있음.
for문을 통해 태스크를 넣어줌.
Dynamic DAG(Directed Acyclic Graph)는 에어플로우(Airflow)에서 동적으로 생성되는 워크플로우 그래프를 의미합니다.
일반적으로 에어플로우에서 DAG는 정적으로 정의되고 미리 구성된 형태로 실행됩니다. 그러나 Dynamic DAG는 런타임 중에 생성되고 변경될 수 있는 특징을 가지며, 실행 시간에 동적으로 워크플로우 그래프를 구성하는 데 사용됩니다.
Dynamic DAG를 사용하면 실행 시간에 동적으로 태스크(Task)를 추가하거나 제거할 수 있습니다. 이는 데이터의 동적인 흐름에 따라 워크플로우를 조정하거나 조건부로 태스크를 추가 또는 제거해야 할 때 유용합니다. 예를 들어, 반복적인 데이터 처리 작업이나 조건부 분기 작업을 수행해야 하는 경우에 동적 DAG를 활용할 수 있습니다.
Dynamic DAG를 구현하기 위해서는 에어플로우의 조건문, 반복문, 제어 흐름 관련 기능 등을 사용하여 워크플로우를 동적으로 구성해야 합니다. 이를 통해 실행 시간에 태스크의 생성, 연결 및 구성을 자유롭게 조정할 수 있습니다.
Dynamic DAG를 활용하면 복잡한 데이터 처리 작업이나 유연한 워크플로우 실행에 적합한 워크플로우 그래프를 구성할 수 있습니다. 그러나 동적으로 구성되는 만큼 워크플로우의 관리와 디버깅에 주의가 필요하며, 코드의 복잡성과 오류 가능성도 고려해야 합니다.
태스크그룹은
말그대로 태스크들을 그룹핑함
with DAG:
tasks = []
for e in el:
task.append(e)모듈화를 시켜 태스크 그룹을 만듦
태스크들을
from airflow import DAG
from airflow.operators.dummy_operator import DummyOperator
from airflow.utils.task_group import TaskGroup
from airflow.utils.dates import days_ago
default_args = {
'start_date': days_ago(1)
}
with DAG('dynamic_dag_example', schedule_interval='@daily', default_args=default_args, catchup=False) as dag:
start_task = DummyOperator(
task_id='start_task',
)
for i in range(1, 6):
with TaskGroup(group_id=f'group_{i}') as tg1:
task_1 = DummyOperator(
task_id=f'task_1_{i}',
)
task_2 = DummyOperator(
task_id=f'task_2_{i}',
)
task_1 >> task_2
start_task >> tg1
end_task = DummyOperator(
task_id='end_task',
)
tg1 >> end_task태스크 그룹들도 각자 id가 있음.
x.a, x.b, x.c 이런식으로

중괄호를 쓰면 에어플로우가 아는 방식으로 치환시켜줌.
에어플로우는 파이썬 오퍼레이터가 실행되면서 진자 템플릿 구분을 보고 치환함. 아무 아규먼트나 넣고, 실행되는게 아님.

파이썬 오퍼레이터를 보면 여기저기 있음.
base operator을 까보면
pre_execute
execute
post_execute
오퍼레이터가 동작할때 저 순으로 실행됨.
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from airflow.utils.dates import days_ago
default_args = {
'start_date': days_ago(1),
}
with DAG('bash_jinja_example', default_args=default_args, schedule_interval='@daily', catchup=False) as dag:
run_this = BashOperator(
task_id='run_this',
bash_command='echo "현재 시간은 {{ ts }}"',
)
위의 코드에서 {{ ts }}는 Jinja 템플릿 변수로, 에어플로우의 내장 변수 중 하나입니다. 이 변수는 해당 작업이 스케줄된 시간을 나타냅니다. 이 코드가 실행될 때, Bash 명령어는 'echo "현재 시간은 2023-06-12T00:00:00+00:00"'와 같은 실제 명령어로 치환되어 실행됩니다. {{ ts }}가 작업의 스케줄된 시간으로 대체되기 때문입니다.
이처럼 에어플로우에서는 Jinja 템플릿을 통해 동적으로 작업을 생성하거나, 작업의 인수를 동적으로 설정하는 등의 작업을 수행할 수 있습니다.
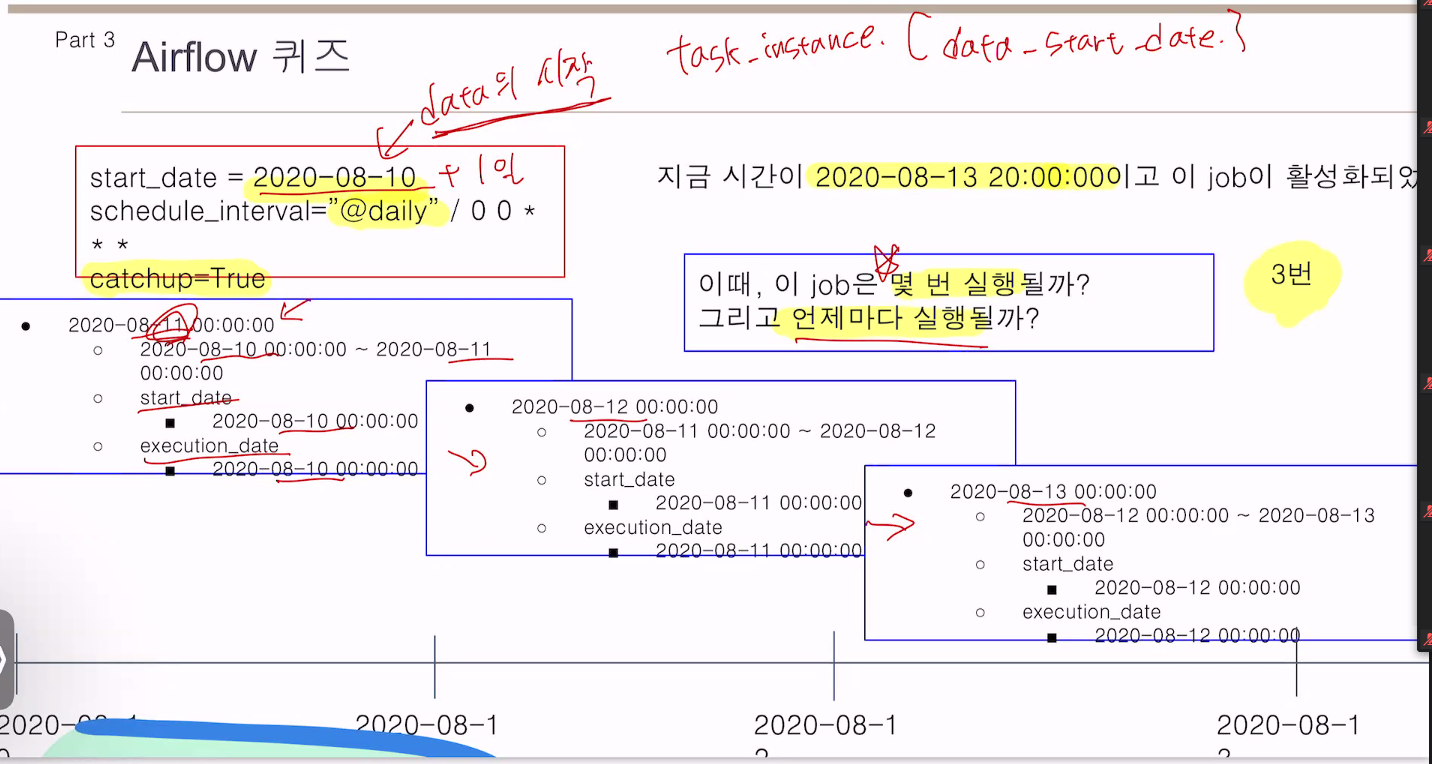
logical_date 개념
10일에 시작을 했다면
11일 0시에 시작시킴
11일 것은 12일 0시
12일 것은 13일 0시
현재 13일 20시이므로 3번 실행.

멘토님은 오퍼레이터를 까봤었음.


MWAA 처음 실행시켰을 때
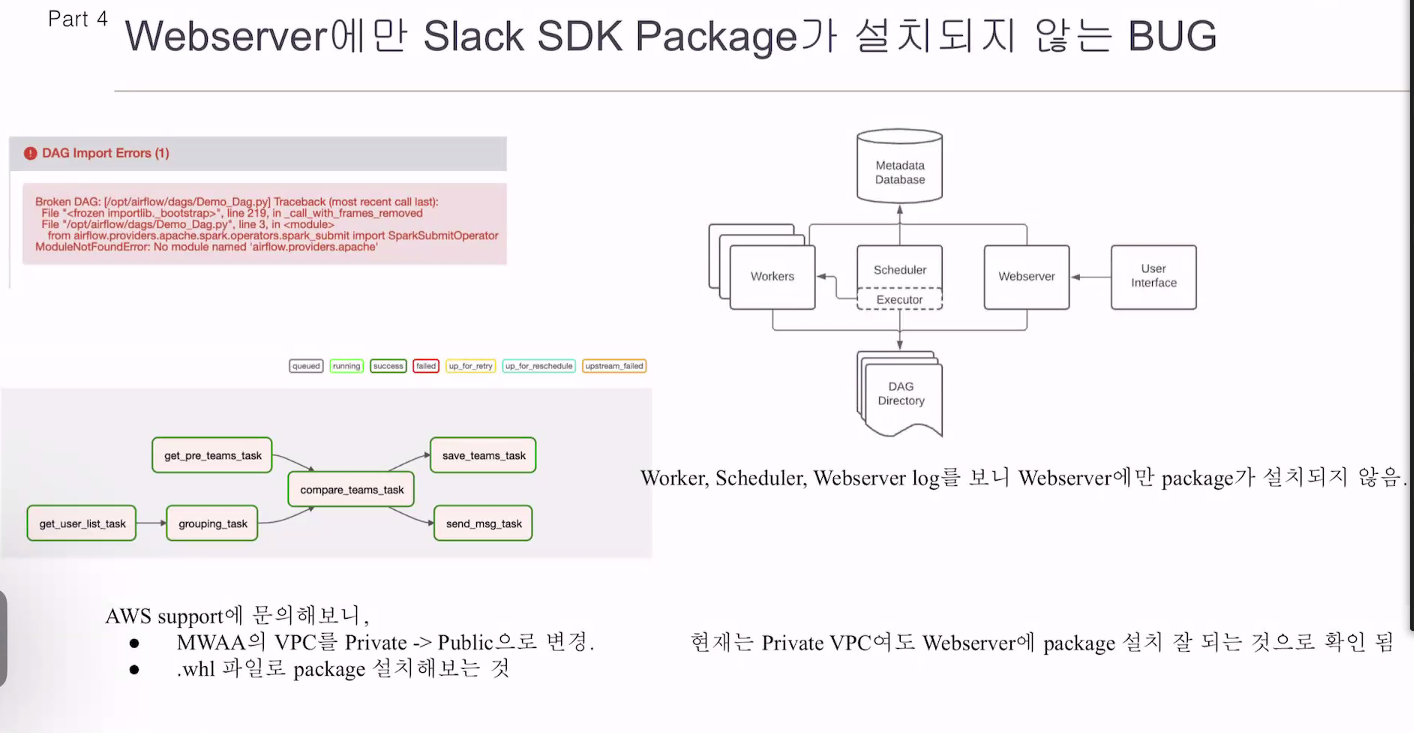
슬랙 SDK를 쓰겠다 -> 파이썬 기본이 아님 따로 인스톨해야함. 워커, 스케줄러엔 먹혔는데 웹서버엔 안됐음.
.whl 파일로 패키지를 설치해보라고 함.
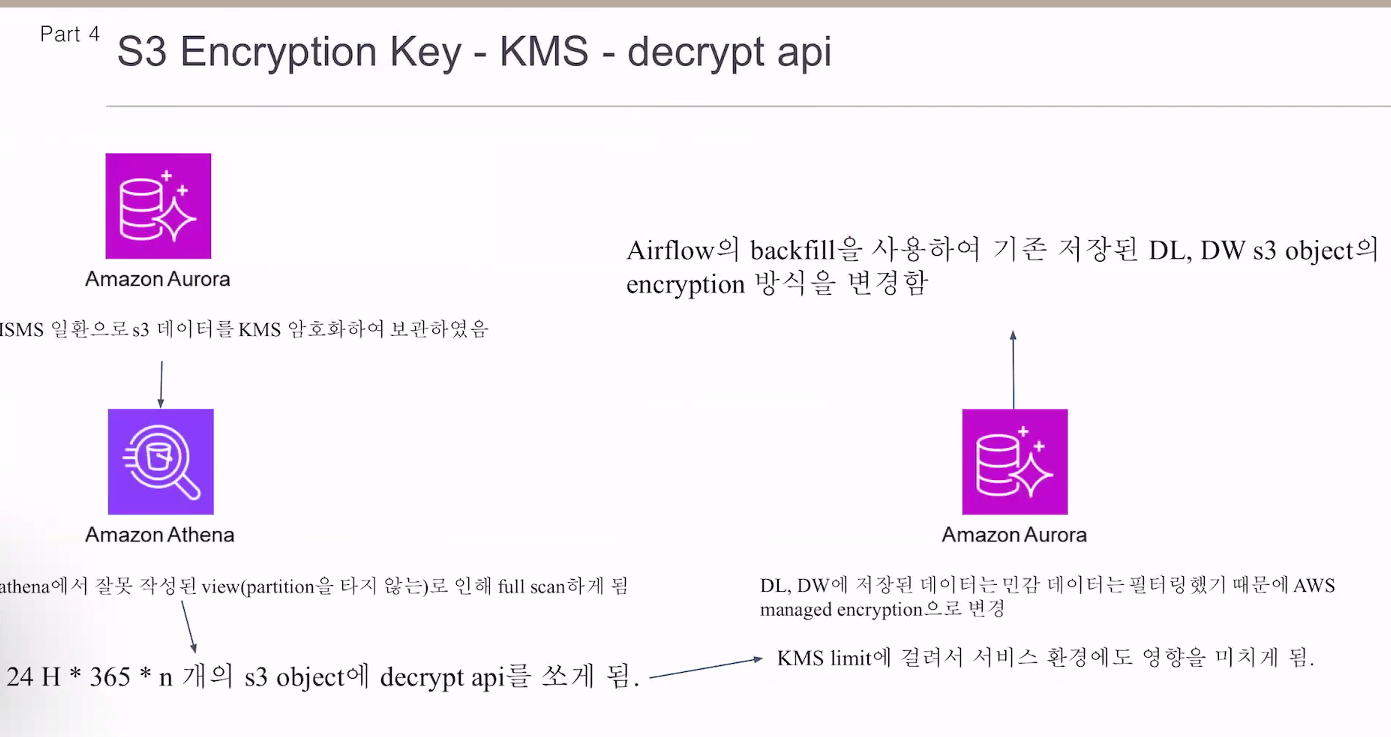
s3
키를 바꿀때
에어플로우 백필 기능을 써서 변경함.

2.6.0버전에서 해결됨.
잡이 큐 상태에서 걸려있음.
오토스케일링을 끄고
최대 최소 워커를 같게 함.

태스크를 줄여서
글루에서
처리를 시키자. DB connection이 timeout 발생. 15분
쓰레드 처리.
질문
모든 에어플로우 대그가 멱등성이 꼭 보장되진 않는다고 하셨는데, 멱등성이 보장되지 않아도 사용하는데 지장이 없는 예시를 알 수 있을까요?
현재시점의 데이터만 전달해주는 날씨 API.
1 2 3 4 5 6
멱등성을 보장해서 작성할 수 도 있지만.
대그가 잘 돌았고 잘 적재되었음.
만약 이걸 가공하는 단계에서
가공이 잘못되었다면 처음부터 가공해서 적재해야할 니즈가 생김.
execute_date을 1일, 2일 자를 주어도
api -> 현재 6일차만 줌.
이런 케이스가 생기면.
과거 데이터는 그대로 둠.
버그나서 빵꾸나고, 데이터 빈적도 있기는 함.
사용하는 서비스에 따라, 민감하면 raw_data를 매일 한번씩 적재.
적재 DAG -> 멱등성 보장
가공 DAG -> 멱등성 조금 덜 신경 씀.
