학습주제
GROUP BY 와 CTAS
CREATE TABLE AS SELECT
CTE
학습내용

!pip install sqlalchemy==1.3.9
!pip install ipython-sql==0.3.9
로 버전을 세팅함
바로 연결되는 것을 확인.
CTE - 서브쿼리, with을 사용해 임시로 사용할 테이블을 쉽게 만들어줌.
어느 테이블이건 새로 테이블을 사용할 때에는 품질을 의심해야함.
PK, uniqueness가 지켜지는지 등.
GROUP BY와 AGGREGATE

SELECT DISTINCT channel로
6개 레코드가 있다는 것을 알았음.
각 채널별로 몇개의 레코드들이 동일한 채널값을 갖고 있는지 세어봤었음.
필드들을 몇개 선택하고 그룹을 생성함. 보통은 1개를 가지고 생성
숙제 -> 월별, 채널별 레코드 수.
그룹핑이 한개의 필드만으로 안됨. timestamp에서 월 정보를 빼내서 월정보, 채널정보를 가지고 그룹핑을 해야함. 그 후 각 그룹별로 카운팅
COUNT, SUM, AVG, MIN, MAX, LISTAGG...
-> AGGREATE이라 부름
- 어떤 필드를 가지고 그룹핑을 할지 정함 (하나 이상도 가능)
- 그룹별 계산할 내용을 결정.
alias를 사용해 필드 이름을 붙임.

시간정보를 얻기 위해 session_timestamp 테이블 사용
SELECT
LEFT(ts, 7) AS mon,
COUNT(1) AS session_count
FROM raw_data.session_timestamp
GROUP BY 1 -- GROUP BY mon, GROUP BY LEFT(ts,7)
ORDER BY 1;SELECT의 첫번째 필드를 기준으로 그룹핑함.
월 정보만 빼오는 방법은 여러가지임.
간단하게는 LEFT라는 스트링함수를 사용해 처음 7글자만 빼오면 됨.
ResShift에는 기본적으로 연도 4자리-월 2자리-일 2자리 시간 2자리:분 2자리:초 2자리.밀리세컨드
LEFT는 스트링으로 받을 수 있는데, 자동으로 ts 필드의 timestamp 타입 값이 스트링 타입으로 캐스팅이 됨.
처음 7자를 빼게되면 연도 4자리, -, 월 2자리가 나오게 됨.
GROUP BY 1의 경우 ordinal number임. select의 첫번째 필드를 기준.
내림차순을 하려면 ORDER BY 1 DESC;

테이블 2개를 사용
MAU - 월별 유니크한 사용자 수
월별 채널별 유니크한 사용자 수
- 숙제 있음
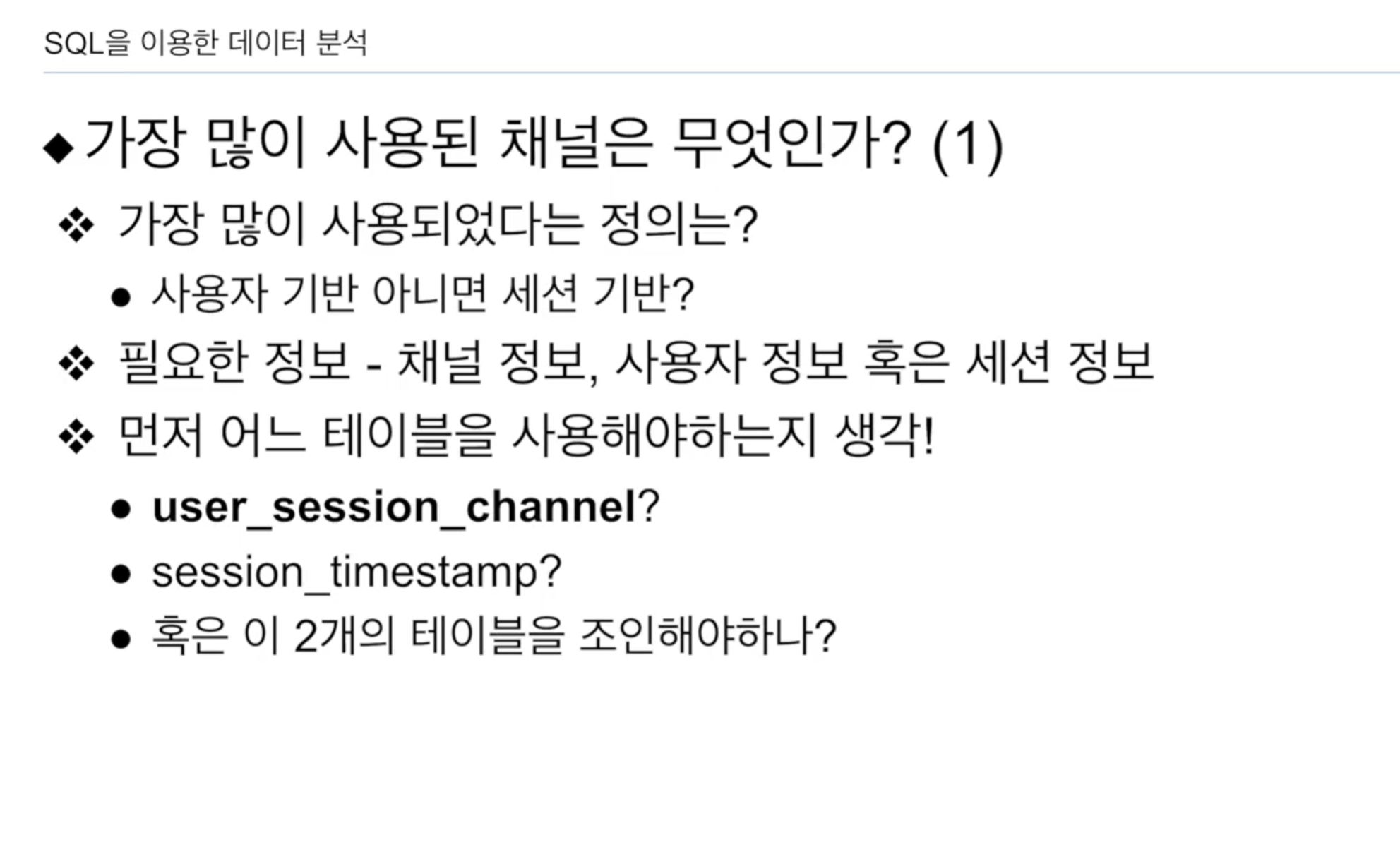
만일 인터뷰 질문이었다면, 다시 질문해야함. 가장 많다는 기준이 불문명하기 때문.
- 유니크한 사용자가 많은 것인지.
- 사용자 상관없이 세션만 많은 경우인지.
원하는 정보는 user_session_channel에 있음

SELECT
channel,
COUNT(1) AS session_count
COUNT(DISTINCT userId) AS user_count
FROM raw_data.user_session_channel
GROUP BY 1
ORDER BY 2 DESC -- ORDER BY session_count DESC채널을 그룹핑한 상황에서 각기 두개의 카운트를 함.
DISTINCT userId를 하면 고유한 사용자의 수를 채널별로 셈. DISTINCT를 빼면, 위의 COUNT(1)과 같게됨. userId가 NULL이 아닌 모든 레코드를 셈. (userId는 NULL이 없는 상황)
만일 session_count로 내림차순을 하고 싶으면
ORDER BY 2 DESC ordinal num 사용
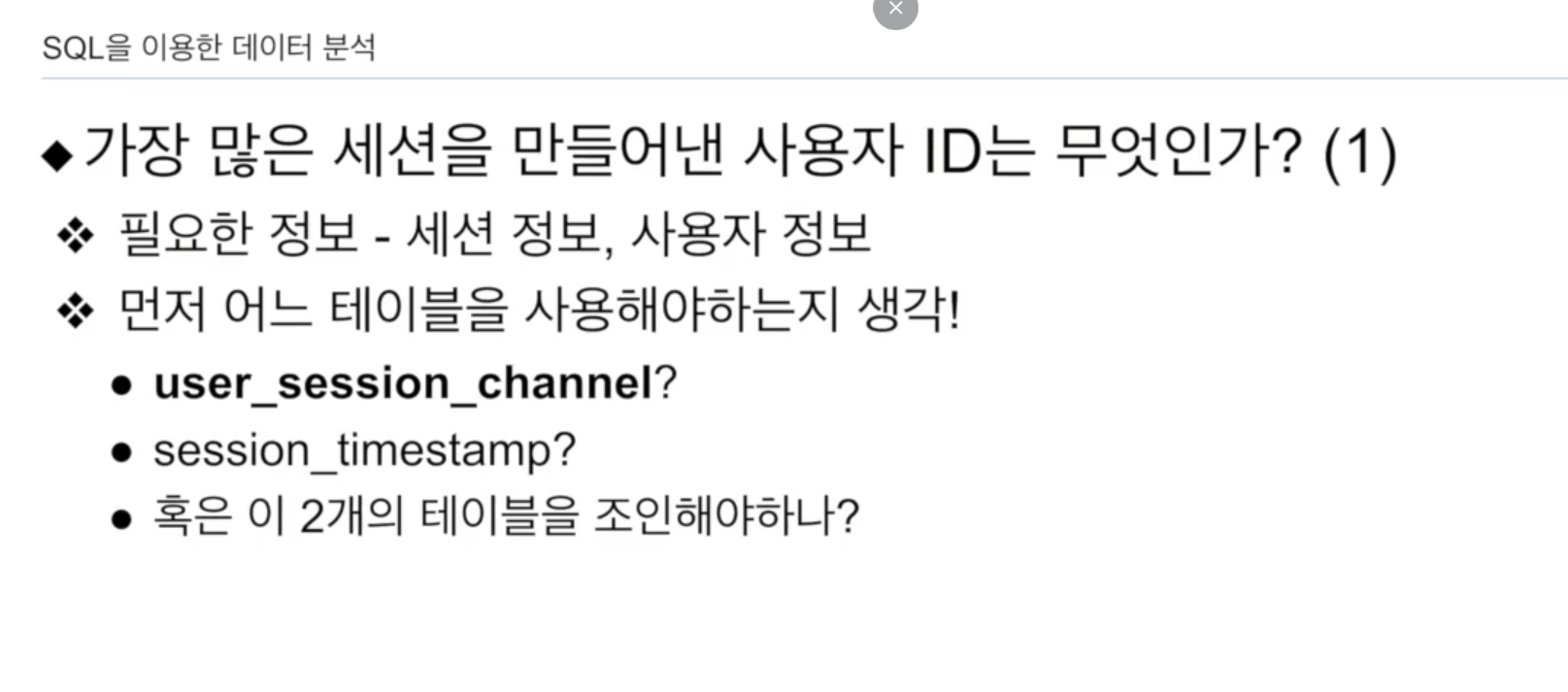
사용자 ID를 가지고 그룹핑, 세션 수를 세어야 함.

SELECT
userId,
COUNT(1) AS count
FROM raw_data.user_session_channel
GROUP BY 1 -- GROUP BY userId
ORDER BY 2 DESC -- ORDER BY count DESC
LIMIT 1;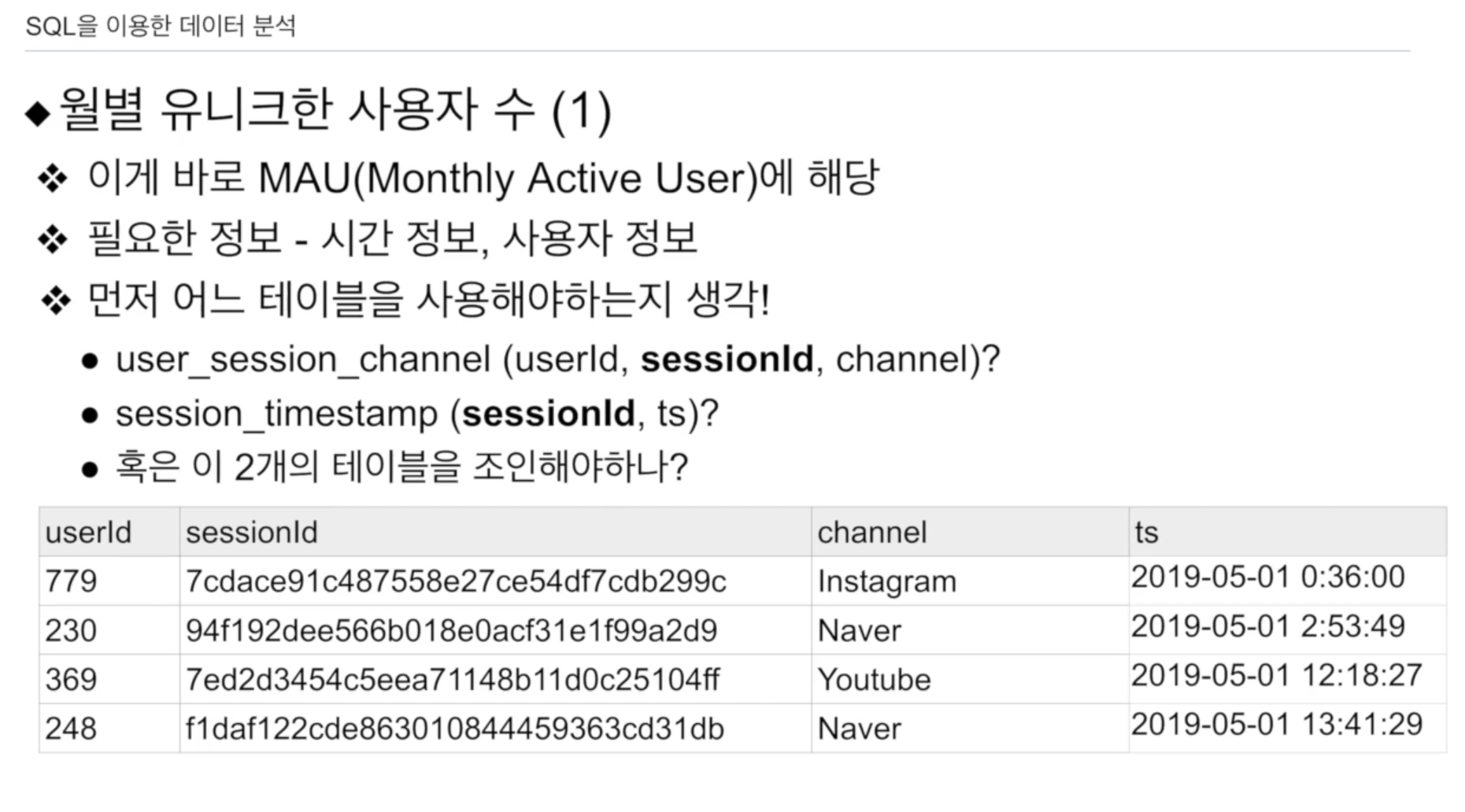
MAU - 사용자가 10번이든 100번이든 1번만 카운트해줌
user_session_channel(userId, sessionId, channel)으로 유저는 있으나 타임스탬프 없음.
session_timestamp(sessionId, ts) 타임 스탬프는 있으나 userId 없음
공통적으로 sessionId로 연결되어 있음.
두개의 테이블을 merge -> join함

SELECT
TO_CHAR(A.ts, 'YYYY-MM') month,
COUNT(DISTINCT B.userid) AS mau
FROM raw_data.session_timestamp A
JOIN raw_data.user_session_channel B ON A.sessionid = B.sessionid
GROUP BY 1
ORDER BY 1 DESC;필드이름에 alias 붙이는 것처럼. 테이블에도 이름을 붙일 수 있음.
아까는 LEFT(ts, 7)로 했었는데, TO_CHAR(A.ts, 'YYYY-MM') 사용
JOIN의 방식엔 여러가지가 있음. 지금으 INNER JOIN 양쪽에 같은 세션이 존재하는 경우만 남기고 나머지는 다 버림. LEFT, RINGT FULL JOIN등이 있음.
현재는 모두 매칭이 되게 만들어 놓음.
TO_CHAR (A.ts, 'YYYY-MM')
LEFT(A.ts, 7)
DATE_TRUNC('month', A.ts)
SUBSTRING(A.ts, 1, 7)DATE_TRUNC('month', A.ts) 여전시 시간과 날짜를 나타내주는 timestamp 타입. 첫번째 인자로 원하는 값. 그 단위에 맞게 리턴해줌. 예를들어 2019-01-03 이하 시간의 timestamp 값을 넣어주면
2019-01-01로 뒤 일 값을 1로 고정시켜버림. 시간은 날려버림. 이런식으로 비교가 가능하게 해줌.
조인을 하게 되면 임의의 통합 테이블이 생성됨. 그러나 각 필드에 접근하기 위해선 그 원본이 되는 테이블.필드로 접근해야함.

DISTINCT를 통해 유저를 유니크하게 만들어주고 그 사용자 수를 세줄 수 있게 함.

JOIN 앞에 아무것도 안쓰면 INNER JOIN.
매칭이 안되는 레코드들은 다 날려버림.
매칭에 상관 없는 레코드들도 모두 포함하려면 OUTER JOIN.

Alias를 테이블에도 사용함. AS는 필수가 아님.
특히 JOIN을 쓸 경우 필드까지 접근하려면 테이블 이름을 언급하기 번거롭기 때문에 Alias를 적극 사용.

GROUP BY. SELECT에서 1번째 필드를 기준으로 묶음. AGGREGATE 함수와 연동됨.
1, month, TO_CHAR(A.ts, 'YYYY-MM')
이번엔 채널별이 추가됨. 이전 코드에서 GROUP BY가 1개 더 추가됨. channel

보면 두번째 필드로 channel이 추가되었고
GROUP BY 1,2로 그룹을 두번 지정해준다.
SELECT
TO_CHAR(A.ts, 'YYYY-MM') AS month,
channel,
COUNT(DISTINCT B.userid) AS mau
FROM raw_data.session_timestamp A
JOIN raw_data.user_session_channel B ON A.sessionid = B.sessionid
GROUP BY 1, 2
ORDER BY 1 DESC, 2;그럼 두번의 그룹핑으로 월별에서 묶이고 끝나는 게 아니라, 월 아래 채널별로 묶인다. 채널엔 여러 사용자들이 있을텐데, userid를 DISTINCT로 유일한 사용자로 제한하여 세주면 채널 별로 유일한 사용자의 수만 집계된다.
ORDER BY로 월별로 오름차순, 같은 월에선 채널로 내림차순.
생각보다 어려운 개념은 아니나, 저렇게 구조적으로 바로 쓸 수 있으려면 코드를 많이 써봐야 할 것 같다.
-> 숙제도 적극적으로 혼자 풀어보기.
INNER JOIN시 JOIN 테이블과 기본 테이블을 바꾸어 써도 상관 없음.
