학습내용
MAU 복습
CTAS, CTE
!pip install ipython-sql==0.3.9
로 버전을 세팅함
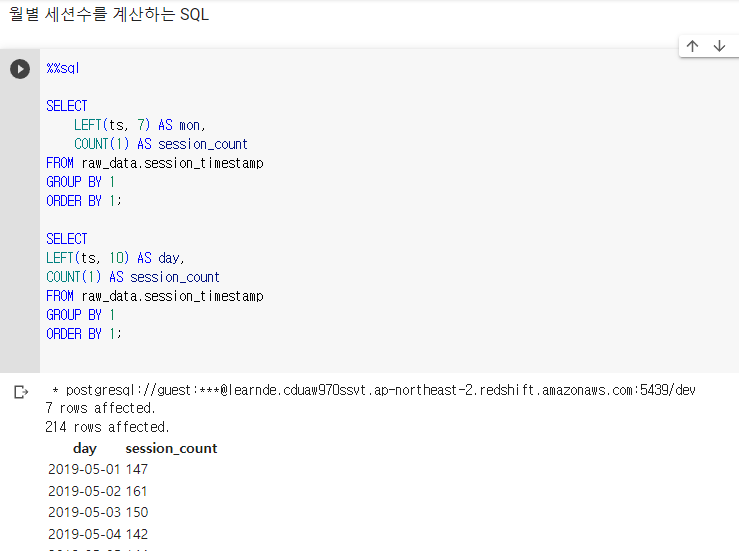
SELECT
LEFT(ts, 7) AS mon,
COUNT(1) AS session_count
FROM raw_data.session_timestamp
GROUP BY 1
ORDER BY 1만일 일별 세션수를 얻고 싶으면 LEFT(ts, 10) AS day
타임스탬프 필드를 가지고 월별로 묶은 뒤, 각 월의 세션 수를 센 모습이다. 이는 세션이 NULL이 없다고 가정할 때 사용 가능하다 (NULL에 상관 없이 세기 때문)
%%sql은 마지막 sql문을 출력,
가장 많이 사용된 채널이 무엇인가? 라는 질문이 들어오면 되물어야함
- userid의 수를 기준으로 하는지
- sessionid의 수를 기준으로 하는지
여기선 그러한 기준이 명시되어 있지 않아 모두 구해준다.
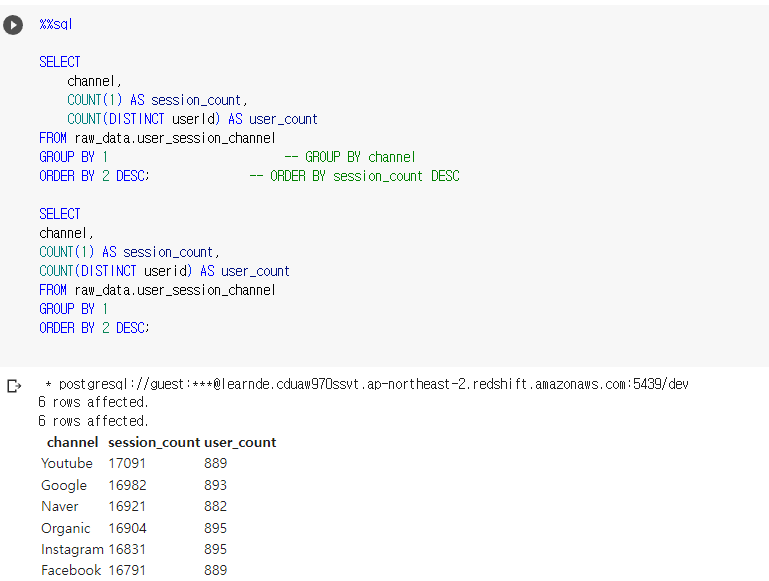
user 기준으로는 Organic과 Instagram이 많이 사용됨.
가장 많은 세션을 만들어낸 사용자 ID는 무엇인가?
그룹핑을 무엇으로 해야하는지 - userid
어떤걸 세야하는지 - COUNT(1) NULL 없으므로
LEFT 대신 TO_CHAR 사용
JOIN ~ ON 을 사용해 키가되는 값을 선택해 두 테이블을 합친 임의의 머지 테이블 생성.
SELECT
SUBSTRING(A.ts, 1, 7) AS month,
COUNT(B.userid) AS cnt,
COUNT(DISTINCT B.userid) AS mau
FROM raw_data.session_timestamp A
JOIN raw_data.user_session_channel B ON A.sessionid = B.sessionid
GROUP BY 1
ORDER BY 1 DESC;그냥 userid를 세준건 세션 수를 센서랑 똑같음.
월별 채널별 유니크한 사용자 수
그룹핑 월, 채널
COUNT (DISTINCT userid)
코드를 많이 써보는게 도움이 될 것 같다.


DROP TABLE IF EXISTS adhoc.keeyong_session_summary;
CREATE TABLE adhoc.keeyong_session_summary AS
SELECT B.*, A.ts FROM raw_data.session_timestamp A
JOIN raw_data.user_session_channel B ON A.sessionid = B.sessionid저번 시간에 배운 JOIN을 활용한 새로운 테이블을 adhoc 폴더 내에 임의의 테이블을 생성한다.
DROP TABLE IF EXISTS를 사용하여 기존에 테이블이 있으면 지우는 이유는, 이러한 테이블을 여러번 생성하고 값을 수정해야하기 때문에 기존 테이블이 있다면 밀어버리는 것이다. 만일 DROP TABLE만 사용하면, 존재하지 않는 테이블을 밀려고 하면, 에러가 남. 이를 방지하기 위해 뒤에 IF EXISTS를 붙여 테이블이 존재하는 경우에만 테이블을 삭제하도록 함.
다른 사용자도 유사하게 테이블을 만들 수 있기 때문에 기존 테이블이 있으면 충돌이 난다. 다른 사용자와의 협업을 위해 테이블을 생성할 때 앞에 꼭 자기 이름을 명시하자. jongwook_session_summary
CREATE TALBE AS 후 SELECT 이하 문으로 테이블을 생성한다.
지난번 데이터 웨어하우스는 2단계 구조로 설계된다고 했다.
- raw_data
- analytics
- adhoc
raw_data는 ETL 프로세스에 의해서 외부에서 복사된 테이블들이 들어감.
analytics는 raw_data에서 테이블들을 조합하여 쉽게 쓸 수 있는 새로운 레이어가 들어감
adhoc는 guest도 접근해서 사용 가능.
현재 40명 넘는 사람들이 같은 데이터베이스 사용중 충돌에 주의
어떨 때 쓰는가?
데이터 엔지니어들이 ETL 프로레스 구현, 데이터 웨어하우스에 테이블 형태로 저장. 데이터 웨어하우스 2단계 구조. raw_data에 저장.
- user_session_channel
- session_timestamp
만일 이렇게 조인한 새로운 테이블을 만들어준다면 매번 join 할 필요 없이. 편하게 쓸 수 있을 것이다.
CTAS는 근간이 되는 테이블들을 미리 만들어두는 것.
session_timestamp에선 userid, channel 정보가 없다
따라서 두 테이블을 합쳐주면 정보가 완벽해진다.
Guest account로 접속한 상태라, 원래 analytics에 만들어야 하나, (read only라 제한됨) adhoc에 사용.
CTAS를 통해 단순히 1회성으로 끝나는게 아닌 adhoc에 테이블로써 기록하고, 이후에도 재사용함.
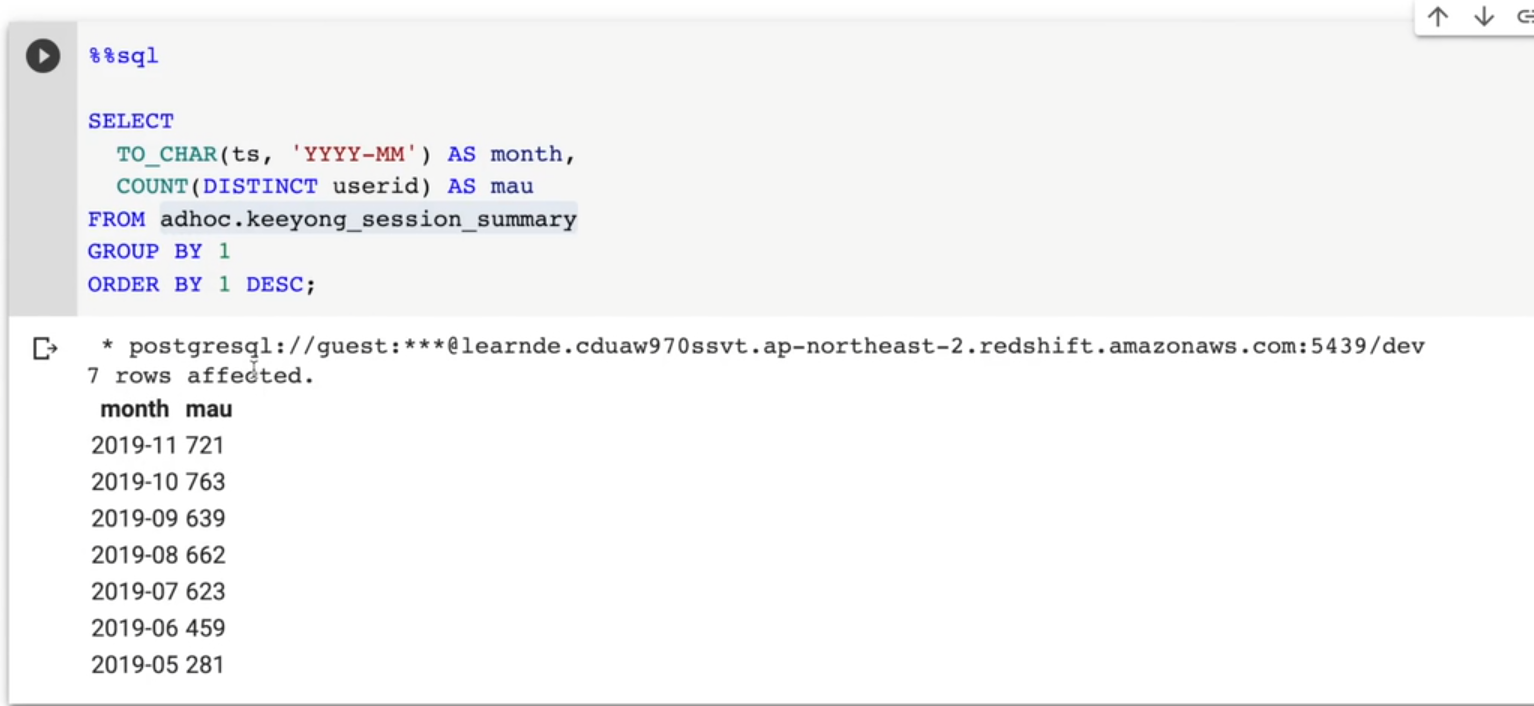
위의 방법으로 테이블을 생성했다면 월별 유니크한 사용자 수(MAU)는 sql이 좀더 간단해진다.
SELECT
TO_CHAR(ts, 'YYYY-MM') AS month,
COUNT(DISTINCT userid) AS mau
FROM adhoc.keeyong_session_summary
GROUP BY 1
ORDER BY 1 DESC;조인이 거대할 경우 매번 사용하기가 쉽지 않음. 빼먹거나 실수할 수 있기에 보통 테이블 형태로 미리 만들어 놓음.

항상 품질을 체크하려면
- 중복된 레코드들 체크하기
- 최근 데이터의 존재 여부 체크하기 (freshness)
- Primary key uniqueness가 지켜지는지 체크
- 값이 비어있는 컬럼들이 있는지 체크 (Null)
중요한 컬럼들이 비어있으면 안됨 매출액 필드가 40% 이상 비어있음.

4가지 검증을 위한 테이블을 1개 생성함.
위의 이슈가 없게끔 이미 테이블을 생성함. 그래도 다음에 테이블을 생성할 때 저런 이슈를 꼭 체크해줘야함.

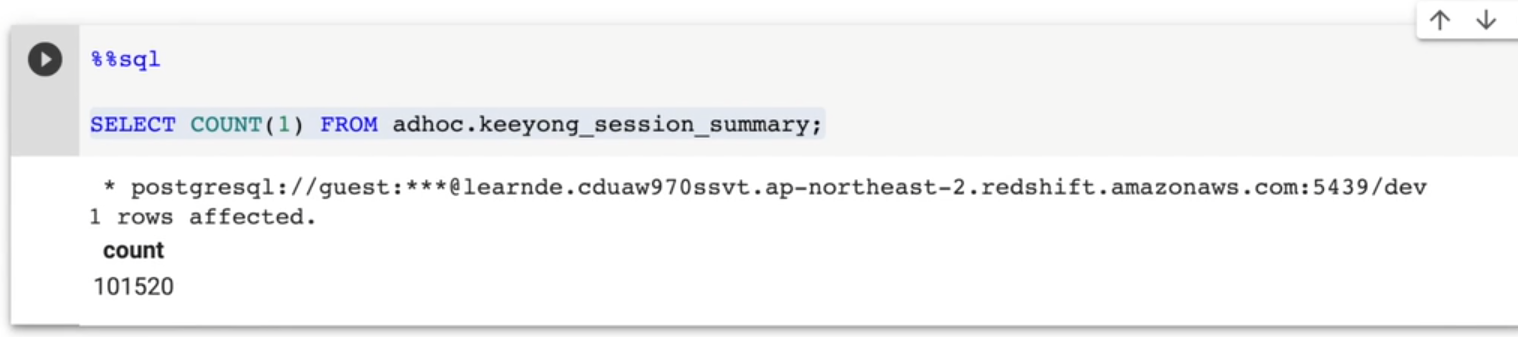
중복된 레코드들 체크하기
SELECT
COUNT(1)
FROM adhoc.keeyong_session_summary;우선 모든 레코드 수를 세준다.
SELECT
COUNT(1)
FROM (
SELECT DISTINCT userId, sessionId, ts, channel
FROM adhoc.keeyong_session_summary
);각 필드들의 중복이 있을경우 모두 날린 뒤, 그 레코드 수를 세고 차이를 확인한다.
COUNT(userid), userId 처럼 함수 안에선 소문자로 써도 되나보다. 일단 킵
네스팅은 프로그래밍에서 괄호를 사용하여 구조를 구성하는 것을 의미합니다. 괄호는 코드 블록을 지정하거나 연산자 우선순위를 지정하는 데 사용됩니다.
FROM에서 무조건 테이블만 언급하는게 아니라 네스팅을 통해 다른 select 문을 사용할 수 있음.
이런식으로 중복 레코드를 체크했다.
이번엔
SELECT
COUNT(1)
FROM (
SELECT DISTINCT userId, sessionId, ts, channel
FROM adhoc.keeyong_session_summary
);방식 외에 CTE개념에 대해 설명한다.

With ds AS(
SELECT DISTINCT userId, sessionId, ts, channel
FROM adhoc.keeyong_session_summary
)
SELECT COUNT(1)
FROM ds;FROM 안에 네스팅을 통해 SELECT문을 썼는데, 이를 위로 빼낼 수도 있음. 이를 CTE라고 함.
With 새로운 테이블 이름 AS(SELECT) SELECT이하 필드가 새로운 테이블 이름으로 임시 테이블이 생성됨. 현재는 ds라는 임시테이블로 생성됨. 일전의 FROM 이하의 테이블과 똑같이 동작함.
차이점은 로직은 FROM 안에, 하나는 위로 빼내 임의의 테이블로 생성함. 후자가 좀 더 나음. 임시로 만든 테이블을 재사용할 수 있기 때문.
-> With를 사용한 sql 예제 풀어볼 예정.
CTE -> 재사용 가능한 임시테이블 사용
구글 콜랩의 경우도 마찬가지로, CTE는 해당 셀을 기준으로 실행됩니다. CTE를 정의한 셀 이후의 쿼리에서 해당 CTE를 참조할 수 있습니다. 이는 CTE를 실행하는데 필요한 데이터를 셀 상에서 정의하고, 이를 참조하는 쿼리를 다른 셀에서 작성할 수 있음을 의미합니다.
최근 데이터 존재 여부 체크 (freshness)

- 내가 관심있는 테이블의 timestamp 필드가 있는지 보고 (created, modified 등등)
- 스캔을 시도. 가장 큰 값, 작은 값
- 언제부터 언제까지의 레코드를 갖고 있는지 알 수 있음
SELECT MIN(ts), MAX(ts)
FROM adhoc.keeyong_session_summary;PK uniqueness가 지켜지는지 체크

SELECT sessionId, COUNT(1)
FROM adhoc.keeyong_session_summary
GROUP BY 1
ORDER BY 2 DESC
LIMIT 1세션 아이디가 PK가 됨. userId는 불가함. channel, timestamp 마찬가지.
세션 아이디를 가지고 GROUP BY로 묶고 COUNT해봄.
이 COUNT를 기준으로 내림차순 해보고 레코드를 하나만 읽어보면 이 값이 1보다 크면 중복이 있다는 뜻임.
중복이 없으면 COUNT 값이 1임.
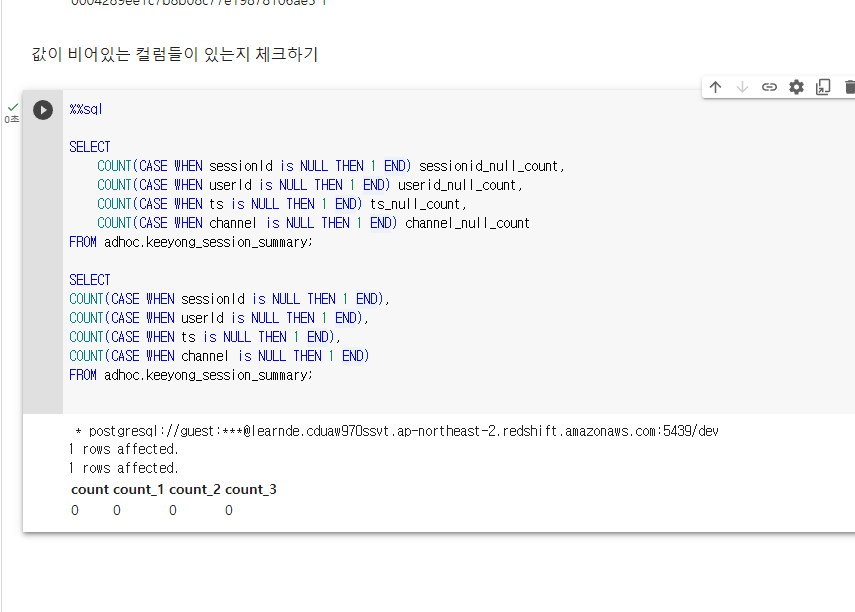
값이 비어있는 컬럼들이 있는지 체크

ELSE를 안넣으면 NULL이 리턴됨. COUNT의 경우 NULL은 세지 않음. END 뒤가 없네 원래 필드 이름 지정이었는데 COUNT 함수와 바로 쓴다고 저렇게 사용하나 보다.
SELECT
COUNT(CASE WHEN sessionId is NULL THEN 1 END) session_null_count,
COUNT(CASE WHEN userId is NULL THEN 1 END) userid_null_count,
COUNT(CASE WHEN ts is NULL THEN 1 END) ts_null_count,
COUNT(CASE WHEN channel is NULL THEN 1 END) channel_null_count
FROM adhoc.keeyong_session_summary;현업에서 실제로 만들어보면 비어있는 필드들이 나옴.
그러한 레코드들이 너무 많고, 중요한 필드가 NULL이 많으면 문제임.
구글 콜랩으로 실습

누군가 새로운 테이블을 사용하라고 하면 바로 사용하는게 아닌 검증을 해봐야 함.
- 중복된 레코드들 체크하기
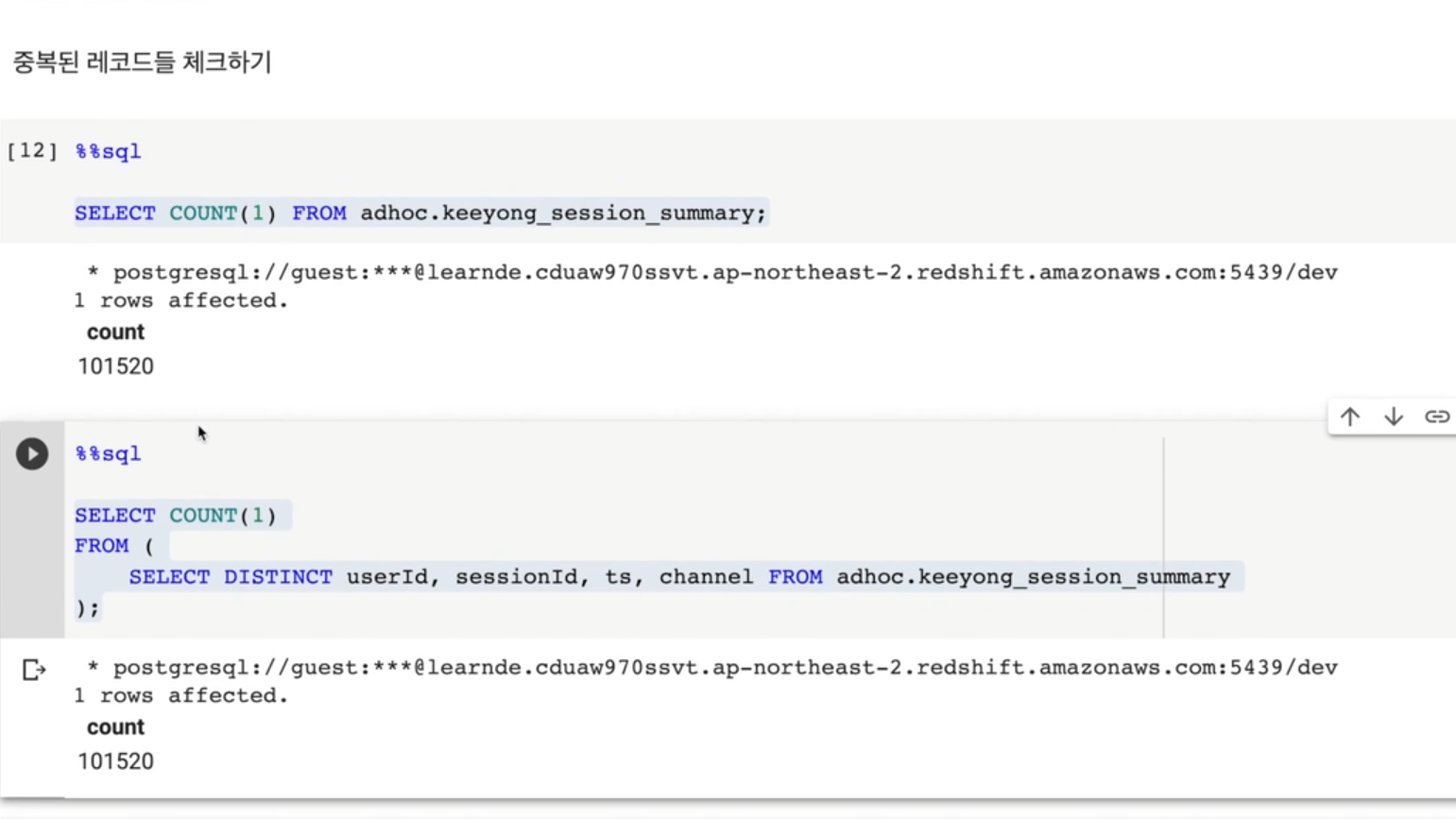
중복 레코드는 없는 것으로 확인.
또는
SELECT COUNT(*)
FROM (
SELECT userId, sessionId, ts, channel
FROM adhoc.keeyong_session_summary
GROUP BY userId, sessionId, ts, channel
);
중복이 있다면 그룹으로 묶어서 하나로 셈. -> DISTINCT와 유사함.
이렇게 모든 필드를 그룹으로 묶어서 세는 것도 방법
CTE로 구현 구글 콜랩 기준 하나의 셀에서 테이블을 재사용 가능.
-
최근 데이터 존재 여부 체크
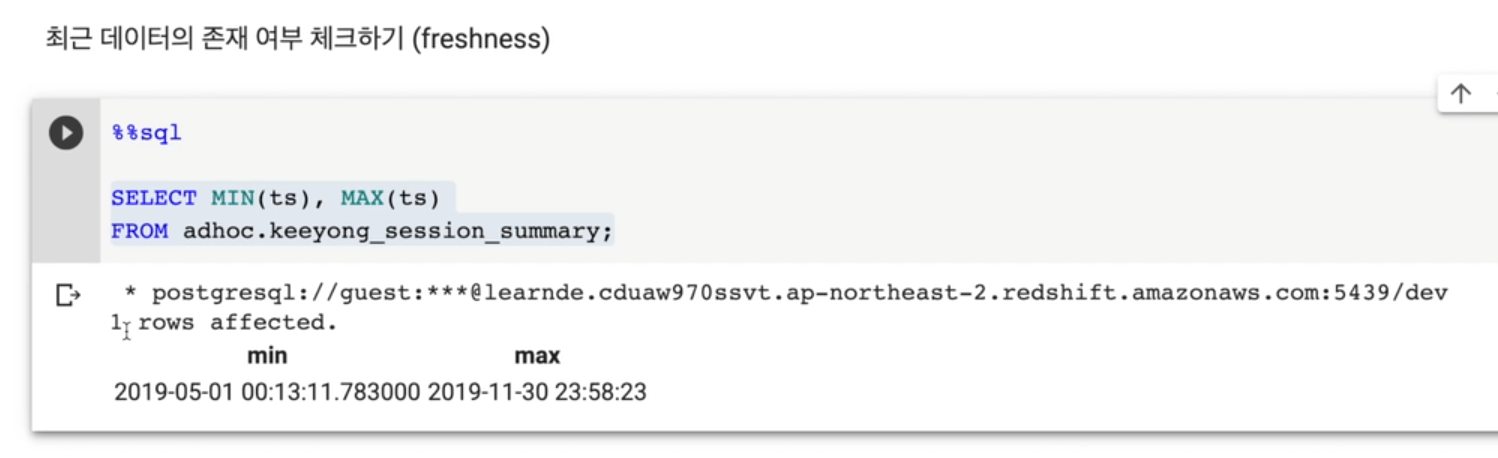
-
PK uniqueness 지켜지는지 체크
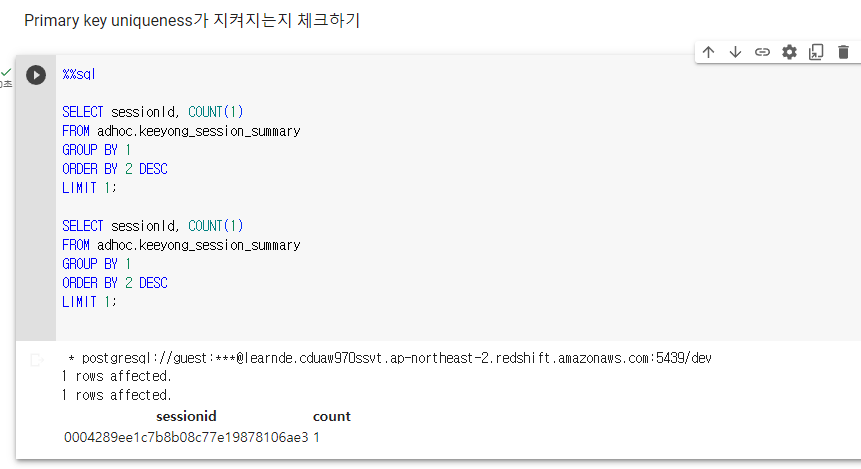
세션 아이디를 기준으로 그룹핑, COUNT 후 1보다 큰게 있는지 확인. -
값이 비어있는 컬럼들이 있는지 체크
-
CASE ~ is NULL 사용

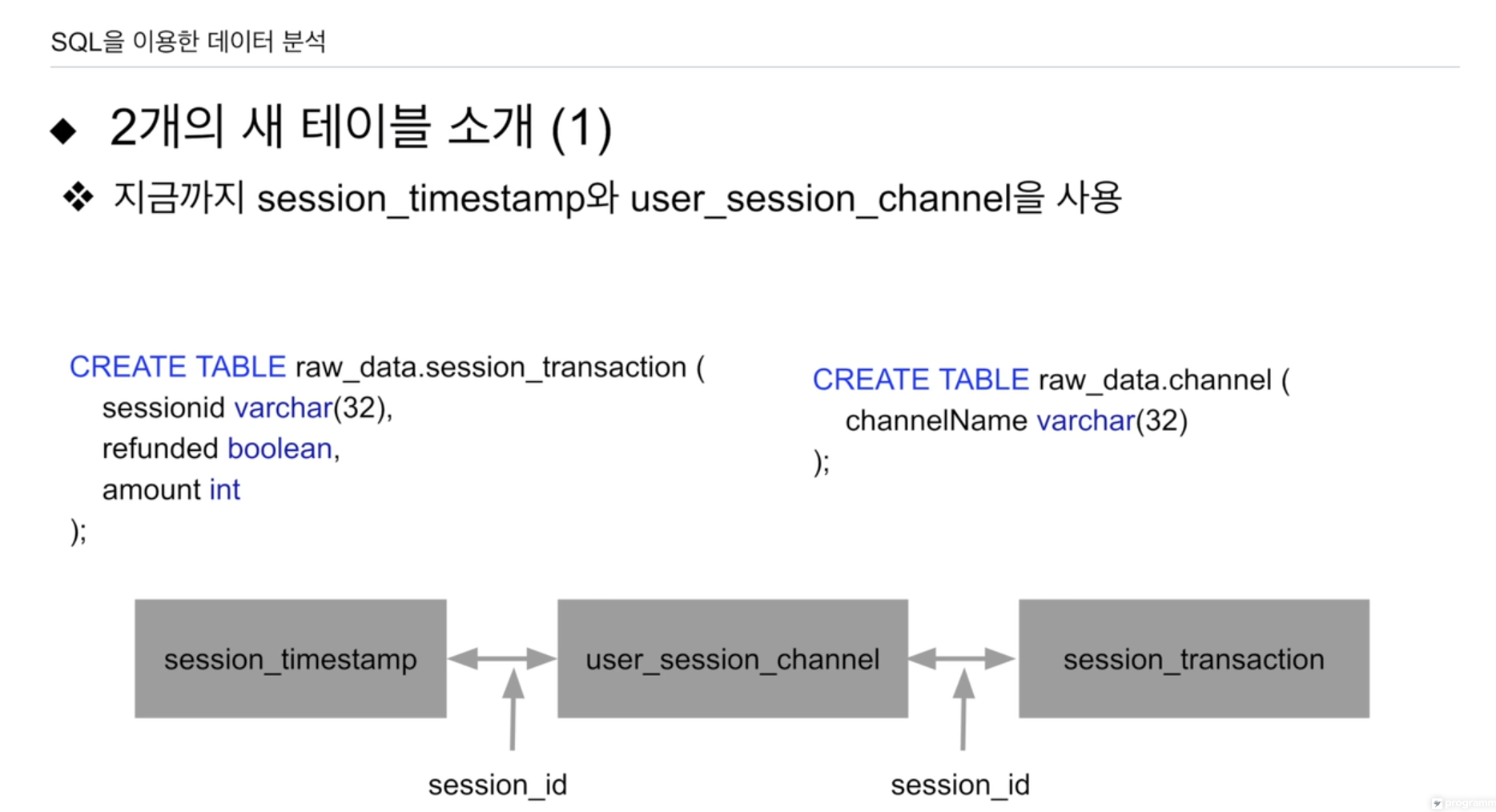
session_transaction 이렇게 생성된 세션을 통해 구매가 이뤄졌는지.
기여도 분배 방식에 따라 first touch, last touch, 멀티 터치,linear 모델 등이 있었다.
구매 정보가 있어야 함.
모든 세션이 트랜잭션을 만들어내진 않음.
일부의 세션만 이 트랜젝션 기록이 있음
아마존 방문 할 때마다 세션이 생성.
- sessionid PK로 제공, JOIN 가능
- refunded TRUE를 하면 반환함. FALSE 반환 X 구매한 물건을.
- amount 구매 가격


adhoc 밑에 적당히 CTAS로 테이블 생성.
주의: session_transaction은 모든 세션이 갖진 않음.
sessionId를 가지고 JOIN할 때 조심해야함.
LEFT JOIN을 사용해야함.
uniqueUsers (총방문사용자) mau임.
paidUsers는 session_transaction에 등장한 세션 Id를 갖는 고유한 사용자
- 주어진 달, 주어진 채널에 구매가 이뤄진 유저를 따로 체크함.
위의 두 필드를 가지고 conversionRate이라는 새로운 필드 생성.
주의: 위의 두 필드는 INT 타입이라 나눗셈을 사용할 때 type casting으로 float 형이라 명시해줘야 함.
GROUP BY, SUM 사용
grossRevenue - amount 필드를 사용해 누적 합 refund 미고려
netRevenue - amount 필드를 사용해 누적 합 refund 고려 -> amount를 0으로 계산함.
아이디어.
- With을 사용한 임의의 JOIN 테이블 ds 생성.
- ds를 가지고 새로운 테이블 jongwook_channel_monthly_revenue
- 요구하는 필드 생성
- month, channel은 GROUP BY로 묶어서 생성.
- uniqueUsers는 DISTINCT로 구현 -> GROUP BY로 한번 더 묶음
- paidUsers는 session_transaction내 세션 id를 갖는 사용자로 구성
- -> refunded, amount가 not null
- conversionRate은 위의 필드 단순계산. 정수끼리의 나눔이므로 ::float
- grossRevenue amount 합
- netRevenue amount 합, refund FALSE만
우선 ds로 어떤 필드값이 생성되는지 확인해본다.
With ds AS (
SELECT A.ts, B.*, C.refunded, C.amount
FROM raw_data.session_timestamp A
JOIN raw_data.user_session_channel B ON A.sessionid = B.sessionid
LEFT JOIN raw_data.session_transaction C ON B.sessionid = C.sessionid
)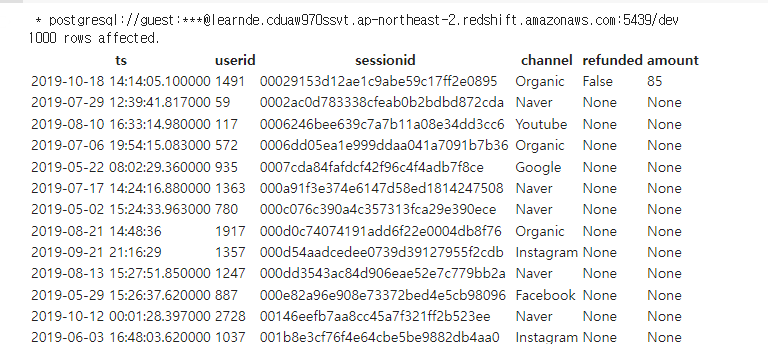
ds 필드를 살펴본다.
refunded와 amount의 경우 LEFT JOIN으로 없는 세션 id의 경우 None, 즉 Null로 채워진 것을 확인함.
이제 이 ds를 가지고 요구사항에 맞는 테이블을 생성한다.
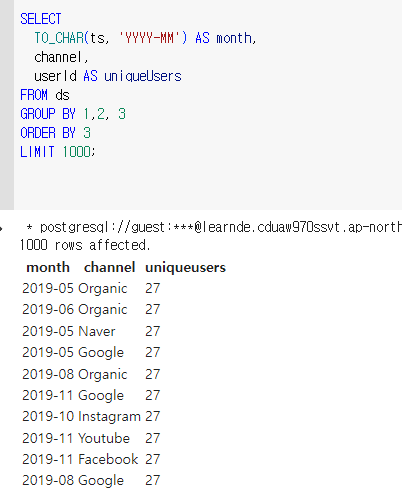
이제 월, 채널별로 고유한 id만 가진다. id가 27일 때, 월, 채널이 모두 다른 것을 확인 할 수 있다.
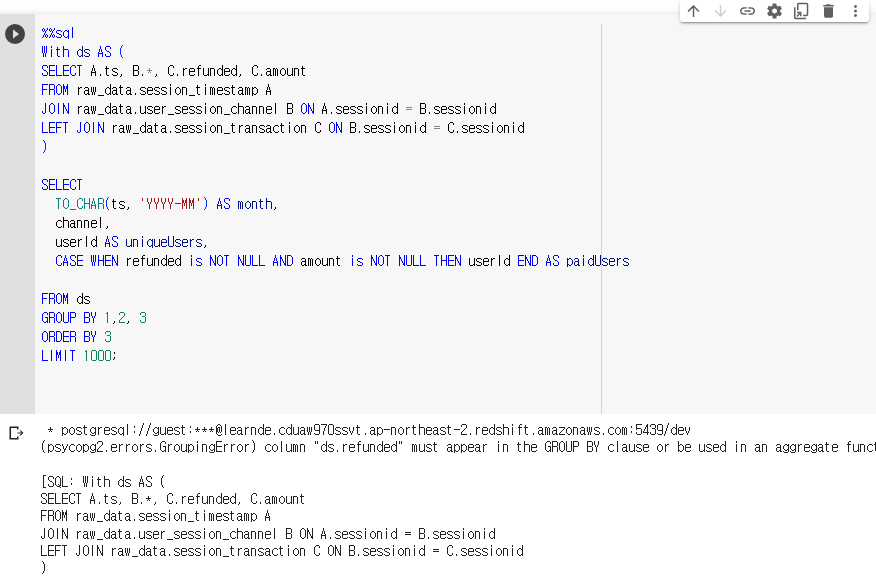
paidUsers를 GROUP BY로 묶어주지 않았떠니 오류가 났다. -> 왜냐하면 같은 달, 같은 채널로 사용자가 여러번 구매했을 수도 있기 때문이다. GROUP BY 4를 해주면
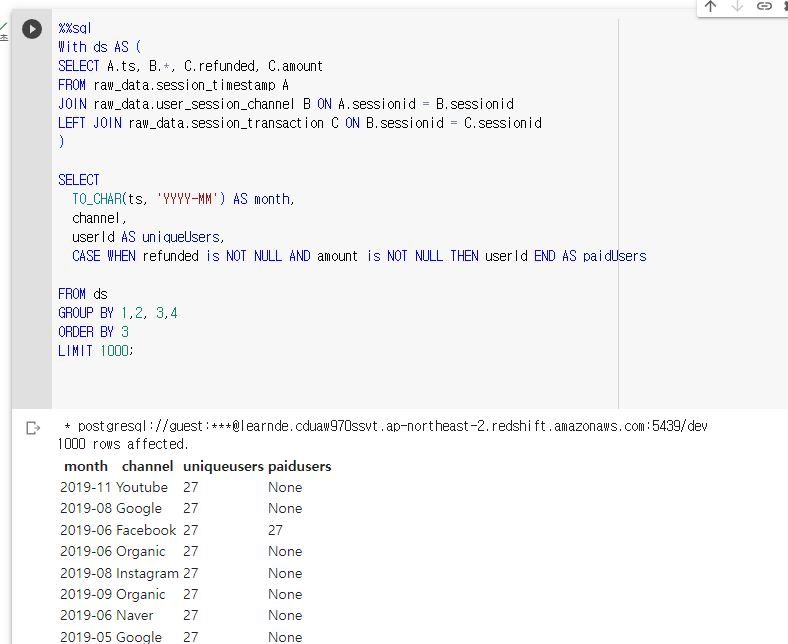
정상적으로 뜨는 것을 확인할 수 있다. 27번 유저는 19년 6월에 Facebook 채널로 1번 이상 물건을 구매한 사람이다.
paidUsers가 헷갈린다.
내가 아는 정의는 같은 달, 같은 채널 내에서서 paidUsers의 수/uniqueUsers의 수의 값을 내는 걸로 이해됨.
월, 채널로 그룹핑 되었다고 가정하고 COUNT(paidUsers), COUNT(uniqueUsers)로 해보았는데, 해당 id의 수가 나온다. -> 맞는거 같음.
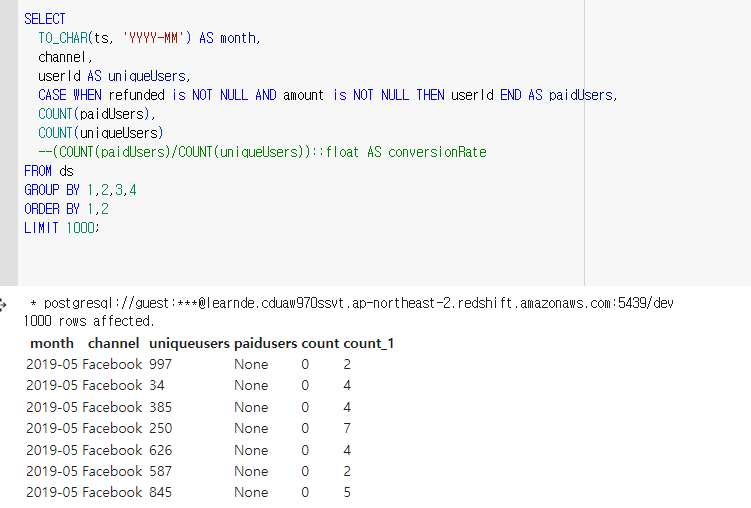
저 계산식이라면 COUNT(paidUsers)/COUNT(uniqueUsers)인데 한 사용자를 기준으로 평가할 수 있음.
A 유저가 4월, 구글을 통해 10번 방문하여 3번 구매. 30%
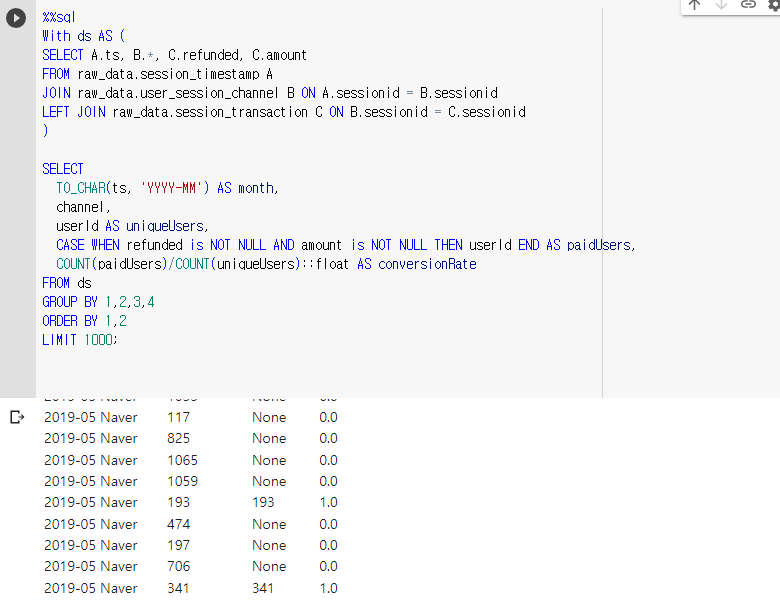
세부적으로 보고싶어 WHERE conversionRate > 0을 했는데 집계함수에서 못쓴다고 오류가 남. GROUP BY를 사용했기 때문에 HAVING으로 접근하니까 됐음.
지금 현재 계산식으로 conversionRate을 하니 0 < 값 < 1인 레코드가 하나도 없음.
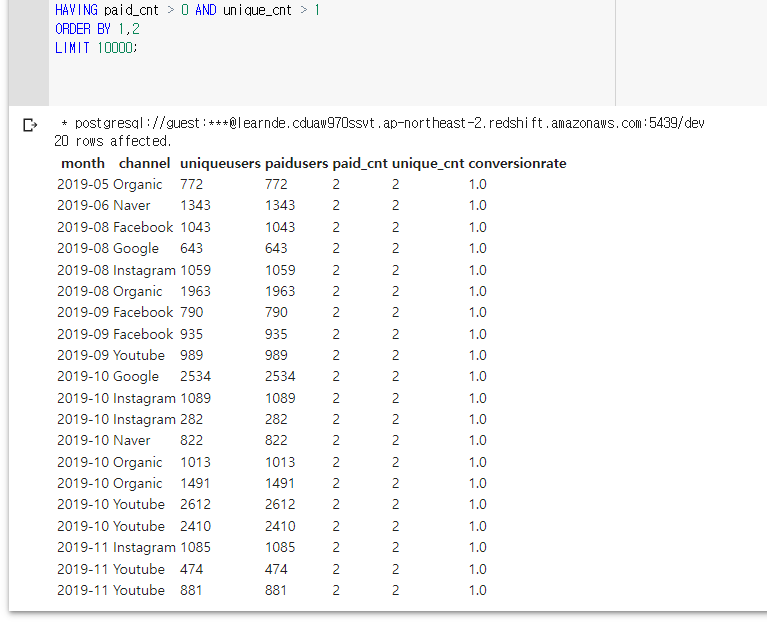
HAVING을 이용해 unque 유저의 총 수가 1보다 크고, paid 유저가 1 이상인 경우를 필터링 했는데 전부 unique가 1보다 클때 무조건 구매로 이어진 것을 확인할 수 있었다.
이렇게 되면 conversionRate의 값은 0.0 아니면 1.0 두개 밖에 없음을 알 수 있다.
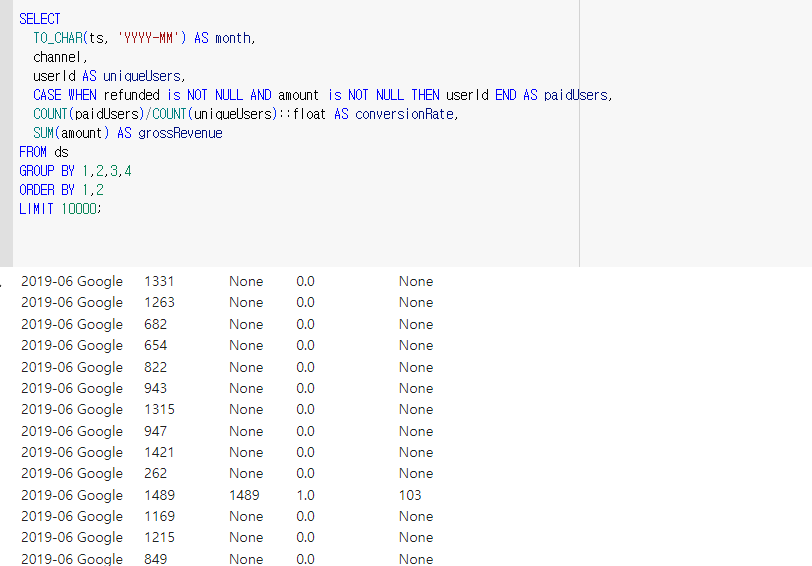
grossRevenue는 단순 집계함수 SUM을 사용하여 paidUsers의 합을 구하였다.
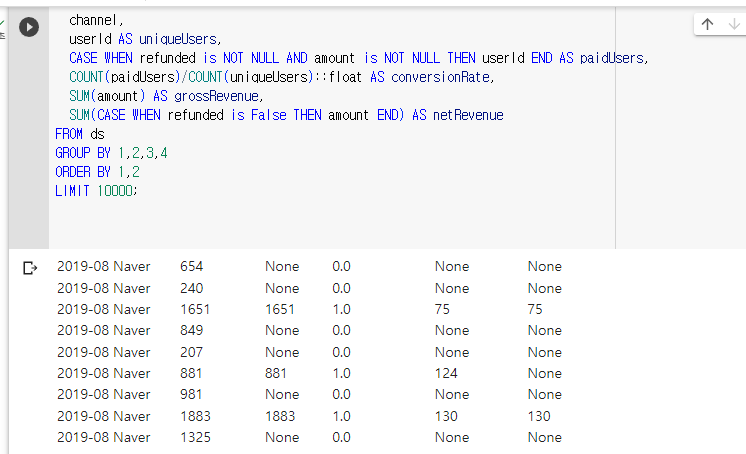
CASE ~ refunded is False 조건을 이용하여 값을 구하였다. 이때 SUM은 NULL을 계산하지 않는 점을 이용하였다.
레코드를 보면 124 구매한 유저가 환불을 하여, 우측 netRevenue가 0이 된 것을 볼 수 있다.
어느정도 나온거 같으니, AWS 데이터베이스에 저장을 시도한다.
-> 실패함
%%sql
-- 임시 테이블 ds 생성
WITH ds AS (
SELECT A.ts, B.*, C.refunded, C.amount
FROM raw_data.session_timestamp A
JOIN raw_data.user_session_channel B ON A.sessionid = B.sessionid
LEFT JOIN raw_data.session_transaction C ON B.sessionid = C.sessionid
)
-- 기존 테이블을 삭제 (있으면)
DROP TABLE IF EXISTS adhoc.jongwook_channel_monthly_revenue;
-- 새로운 테이블을 생성하고 데이터를 채움
CREATE TABLE adhoc.jongwook_channel_monthly_revenue AS (
SELECT
TO_CHAR(ts, 'YYYY-MM') AS month,
channel,
userId AS uniqueUsers,
CASE WHEN refunded IS NOT NULL AND amount IS NOT NULL THEN userId END AS paidUsers,
COUNT(CASE WHEN refunded IS NOT NULL AND amount IS NOT NULL THEN userId END)::float / COUNT(userId)::float AS conversionRate,
SUM(amount) AS grossRevenue,
SUM(CASE WHEN refunded IS False THEN amount END) AS netRevenue
FROM ds
GROUP BY 1, 2, 3, 4
ORDER BY 1, 2
);
* postgresql://guest:***@learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com:5439/dev
(psycopg2.errors.SyntaxError) syntax error at or near "DROP"
LINE 10: DROP TABLE IF EXISTS adhoc.jongwook_channel_monthly_revenue;
^DROP 명령어가 실행이 되지 않음.
죄송합니다. 제가 제안한 방법은 표준 SQL에서 흔히 사용되지만, Amazon Redshift에서는 동작하지 않을 수 있습니다. Redshift에서는 CREATE TABLE AS SELECT 구문을 사용하여 쿼리의 결과를 바로 새 테이블에 저장할 수 있습니다.
하지만 문제는 WITH 절 (CTE, Common Table Expressions)를 사용하는 쿼리를 CREATE TABLE AS SELECT 구문에 바로 사용할 수 없다는 것입니다. 이는 Redshift의 제한 사항으로 보입니다.
대신, 두 단계로 작업을 나눌 수 있습니다:
먼저 임시 테이블을 생성하고 WITH 절을 사용한 쿼리의 결과를 저장합니다.
그런 다음 임시 테이블의 내용을 최종 테이블로 복사합니다.
아래에 예시를 제시하겠습니다.
%%sql
-- 임시 테이블을 생성하고 쿼리의 결과를 저장
CREATE TEMP TABLE temp_table AS
WITH ds AS (
SELECT A.ts, B.*, C.refunded, C.amount
FROM raw_data.session_timestamp A
JOIN raw_data.user_session_channel B ON A.sessionid = B.sessionid
LEFT JOIN raw_data.session_transaction C ON B.sessionid = C.sessionid
)
SELECT
TO_CHAR(ts, 'YYYY-MM') AS month,
channel,
userId AS uniqueUsers,
CASE WHEN refunded IS NOT NULL AND amount IS NOT NULL THEN userId END AS paidUsers,
COUNT(CASE WHEN refunded IS NOT NULL AND amount IS NOT NULL THEN userId END)::float / COUNT(userId)::float AS conversionRate,
SUM(amount) AS grossRevenue,
SUM(CASE WHEN refunded IS False THEN amount END) AS netRevenue
FROM ds
GROUP BY 1, 2, 3, 4
ORDER BY 1, 2;
-- 기존 테이블을 삭제 (있으면)
DROP TABLE IF EXISTS adhoc.jongwook_channel_monthly_revenue;
-- 임시 테이블의 내용을 최종 테이블로 복사
CREATE TABLE adhoc.jongwook_channel_monthly_revenue AS SELECT * FROM temp_table;
-- 임시 테이블 삭제
DROP TABLE temp_table;해결됨!!!!
임시테이블 temp_table을 사용했더니 됐다.
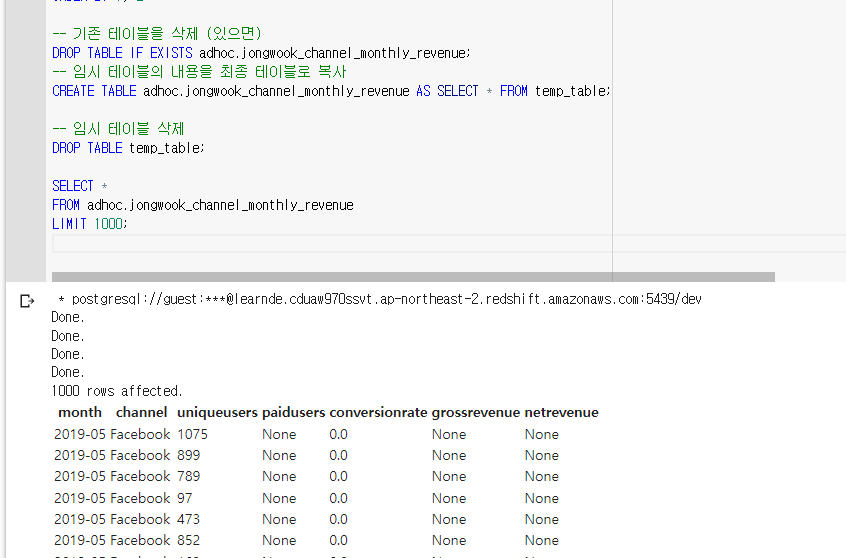
CREATE TEMP TABLE과 CREATE TABLE의 차이에 대해 물어보았다.
네, 그렇습니다. CREATE TEMP TABLE로 생성된 임시 테이블은 세션 종료 시 자동으로 삭제되므로, 명시적으로 DROP TABLE을 사용하여 삭제할 필요는 없습니다.
그러나, 세션 내에서 동일한 이름의 임시 테이블을 여러 번 생성해야 하는 경우에는 DROP TABLE을 사용하여 이전 임시 테이블을 삭제하고 새로운 테이블을 생성하는 것이 필요할 수 있습니다.
따라서 DROP TABLE temp_table;이 필요없는 것은 맞지만, 임시 테이블을 사용하는 전체적인 맥락에 따라 이 명령어가 필요한 경우도 있습니다.
AWS에서 정상적으로 불러오는 것까지 확인함.
상당히 과제가 재밌었다.
