학습주제
JOIN
학습내용
!pip install ipython-sql==0.3.9

JOIN을 먼저 배우고, 숙제를 리뷰하기로 한다. (LEFT JOIN 기능도 있기 때문)
6가지 종류의 JOIN이 있음. (CROSS JOIN, SELF JOIN은 새로 듣는 개념)
NULL IF, BOOLEAN, NULL 타입 비교 등
숙제: 3가지. 설명 후 제출
JOIN

공통 필드를 가지고 머지하는데 사용.
특정 키를 기준으로 머지한다고 생각하면 됨. R 때와 유사함.
- 어떤 레코드들이 선택되는지?
- 어떤 필드들이 채워지는지?
FROM 이 왼쪽 테이블 LEFT
JOIN 오른쪽에 오는 테이블이 RIGHT
특수조인. SLEF, CROSS JOIN
INNER, LEFT JOIN을 보통 많이 씀. (95% 사용)
FULL, OUTER (5% 미만)
어떤 방식의 조인이 필요한지 떠올려야함.
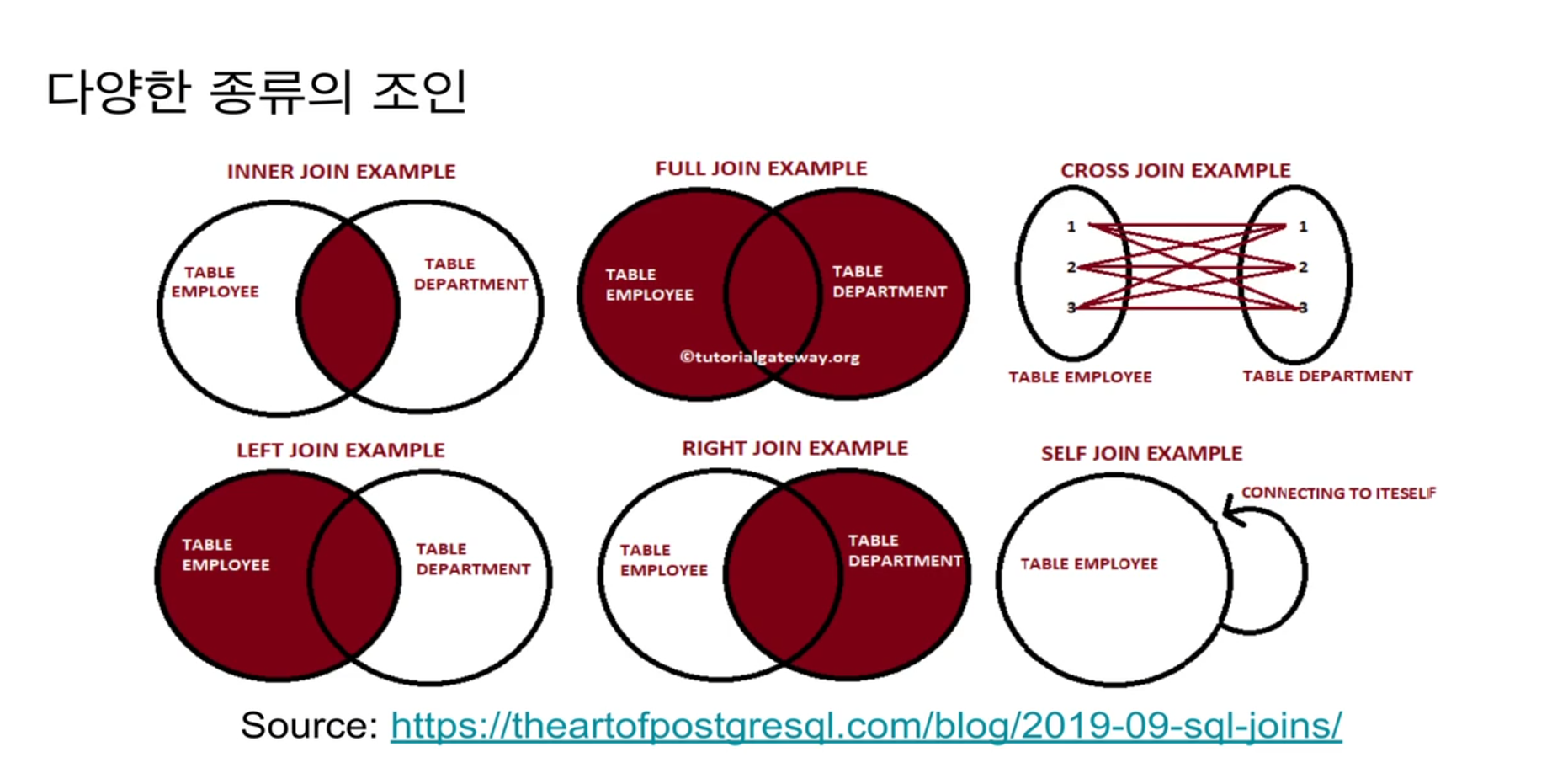
우선 그림으로 살펴본다.
INNER JOIN
INNER JOIN의 경우 보통 STAR SCHEMA에서 많이 사용함.
- TABLE EMPLOYEE에는 분명 DEPARTMENT에 관한 ID가 있을 것임.
- 이 DEPARTMENT ID를 가지고 DEPARTMENT TABLE에 접근하면 자세한 정보를 얻을 수 있음.
매칭이 되는 레코드들만 머지가 되어 리턴됨
현업에서 실제로 데이터를 보면 EMPLOYEE 중 DEPARMENT ID가 없는 경우도 있고
EMPLOYEE 중 DEPARTMENT ID가 있어서 DEPARTMENT TABLE에 갔더니 세부정보가 없는 경우도 있음.
반대로 DEPARTMNET TALBE의 ID 중에 EMPLOYEE 테이블에선 사용하지 않는 중일 수도 있음.
기본적으로 필드들이 다 차있음.
LEFT JOIN
EMPLOYEE 테이블은 무조건 킵하고 싶음. 그 중 DEPARTMENT ID를 갖는 경우에 그 값을 추가로 업데이트함.
INNER 와 차이가 있음. 한쪽 테이블 값을 그대로 갖는 점에서 차이가 있음.
RIGHT JOIN
left의 반대임. 오른쪽 테이블 값을 모두 킵. 그 중 임플로이 테이블 중 매칭되는 것만 업데이트
FULL JOIN
양쪽의 레코드들을 모두 킵하고 싶음.
매칭이 되는 것들에 한해 완전한 값을 완성함.
CROSS JOIN
양 요소의 모든 경우의 수에 대해 머지를 함.
왼쪽에 M개, 오른쪽에 N개가 있다면
M * N의 경우의 수를 가짐
SELF JOIN
자기와 JOIN 함

SELECT A.*, B.*
FROM raw_data.table1 A
( ) JOIN raw_data.table2 B ON A.key1 = B.key1 and A.key2 = B.key2
WHERE A.ts >= '2019-01-01'
저 괄호 안에 INNER, FULL, LEFT, RIGHT, CROSS가 들어감
테이블 엘리어스는 기본.
ON 뒤에 조인 조건을 줌. 두개의 필드를 비교해 두개 필드가 같은 경우도 줄 수 있음.
SELF의 경우 JOIN 뒤에 같은 테이블이 오게됨.

가장 중요!
- 중복레코드가 없어야 함
- Pimary Key 의 uniqueness가 보장되어야 한다.
JOIN 했을 때 문제가 발생하게됨. 위의 조건을 지키지 않으면, -> 증폭이됨.
One to One - 키가 양쪽에 각 하나씩 유일하게
One to many - 한쪽 테이블에서 해당 키가 여러개 나옴.
many to many는 잘 없음
이걸 예로 들어보면
한명의 사원은 어떤 부서에 속해있다. 그러나 반대로
한 부서는 여러 사원을 갖는 관계이다.
many to one - DEPARTMENT ID 기준.
세션 아이디를 가지고 생각해볼 수 있다.
user_session_channel 과 session_timestamp는 완전한 one to one
각 테이블의 ID는 그대로 상대쪽 테이블에 그대로 존재함.
user_session_channel 과 session_transaction은 조금 다름
session_transaction의 세션 ID는 일부만 존재함.
부분집합이 되는 관계. 세션 중 매출이 있는 세션 ID만 기록한 것이기 때문.
모든 세션이 매출을 내지는 않기 때문.
그래도 서로 나타나면 1:1로 대응하기는 함.
INNER을 하냐, LEFT를 하냐 완전 다른 결과를 낳음
LEFT를 할 경우, 어떤쪽이 LEFT에 따라 생성되는 테이블이 달라짐.
- session_transaction이 LEFT일 경우
이 테이블에 없는 세션ID를 갖는 user_session_channel 레코드들은 모두 드랍됨. - user_session_channel이 LEFT일 경우
모든 테이블이 남아있음. session_transaction에 대응되는 키를 갖는 레코드만 정보가 추가됨.
One to many 잘못하면 증폭함.
order vs order_items
내가 뭔가를 주문함. 주문 엔트리 안에는 주문한 항목들이 들어있음.
보통 다수의 아이템을 주문함.
관계형 데이터베이스에서 표현하면 스타 스키마에서 order 테이블. order_items로 나뉨.
one to many
한 order 안에 여러개의 아이템이 있음
order 테이블에 중복이 들어가면
order 중복의 수만큼 order_items에서 반복해서 레코드들을 생산해냄
잘못하면 매출이 늘어난 것처럼 보일 수 있음.
생각지 못한 이슈를 만들어냄
어느 테이블을 베이스로 잡을지 (FROM으로 사용할지) 결정. LEFT JOIN을 고려함.
실제 테이블을 가지고 설명해본다.

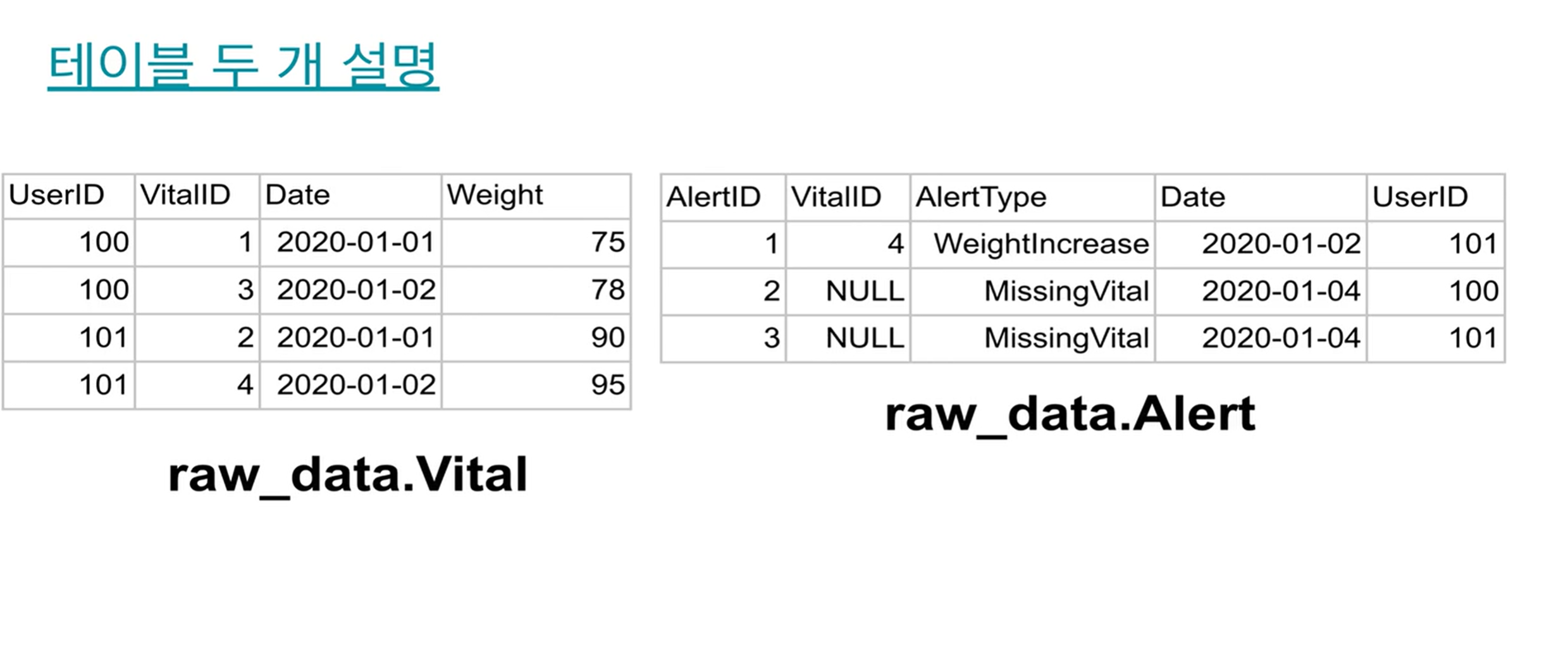
왼쪽 테이블의 경우 유저 아이디를 PK로 레코드 생성. 어떤 측정을 하게되면
VitalID 부여.
이 왼쪽 테이블이 서버로 전송되면, 서버에서는 받은 테이블 값과 머신러닝을 통해 일종의 문제가 있을지 예측을 한 경고 테이블을 만들어냄.
모든 Vital 체크가 Alert를 만들진 않음.
VitalID 4번을 보면 경고를 하나 만들어냄.
VitalID는 없는데 생긴 Alert가 있음. -> 환자들이 능동적으로 체중을 재고 서버로 보내야하는데, 환자들이 게으르면 체크할 방법이 없음. -> 이에 회사는 2일간 환자가 체중을 재지 않으면 또 경보를 만들어냄. -> 이를 테이블에서 보고 다시 환자에게 연락하게끔 함.
이때는 MissingVital이라고 한다.
JOIN을 할 때 VitalID를 갖고 한다.
one to one이나 완전한건 아닌 부분집합형이다.
alert보면 vitalID가 없는 것도 있다.

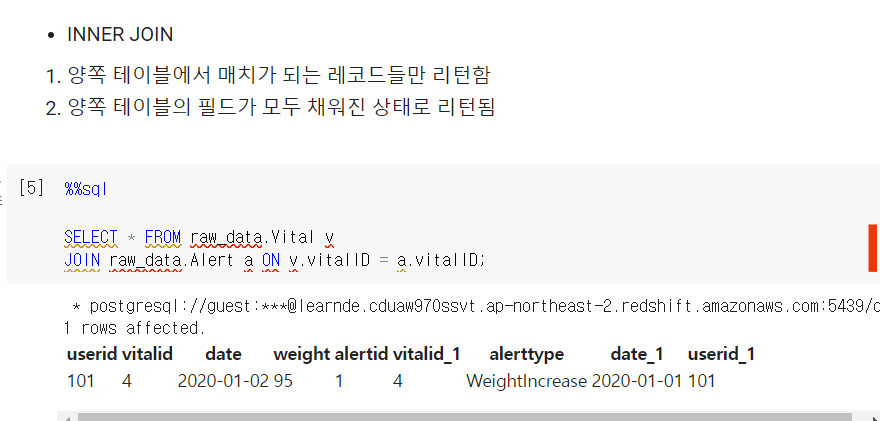
INNER JOIN
SELECT * FROM raw_data.Vital v
JOIN raw_data.Alert a ON v.vitalID = a.vitalID;집합으로 생각하면 교집합. 양쪽 테이블로부터 해당 레코드만 생성. 완전히 값이 채워진 상태.
각 vitalID가 필드에 등장하고, 값이 같은 것을 볼 수 있음.
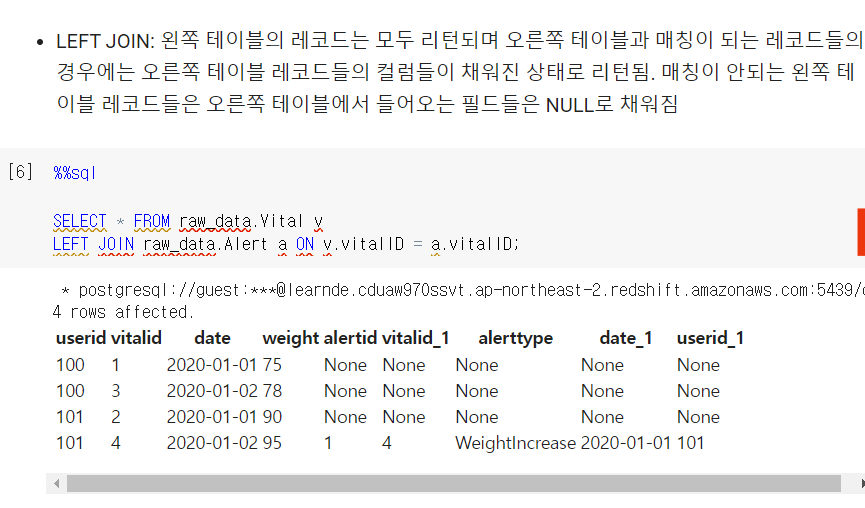
LEFT JOIN
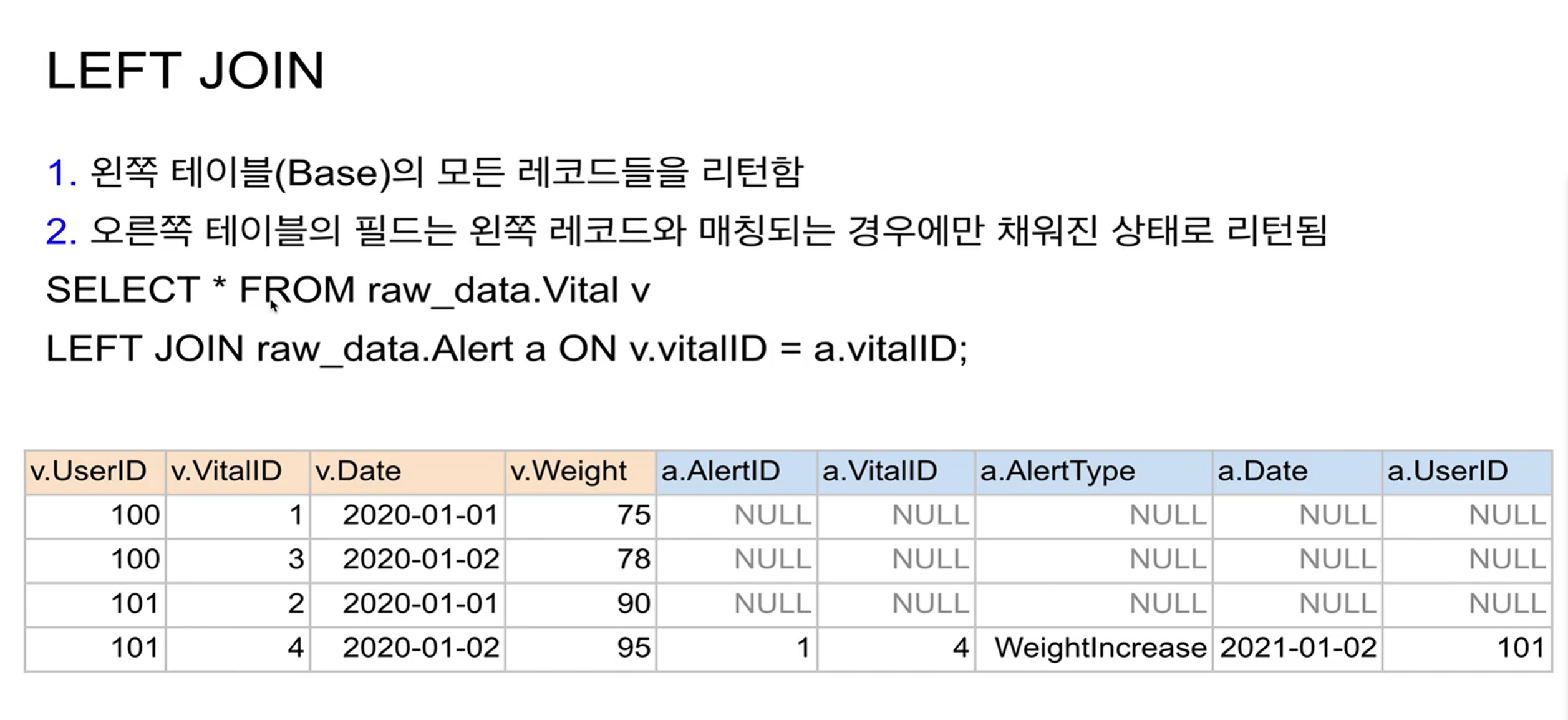
SELECT * FROM raw_data.Vital v
LEFT JOIN raw_data.Alert a ON v.vitalID = a.vitalID;매칭이 안되는 것들은 다 NULL로 채워져서 들어옴.
FULL JOIN
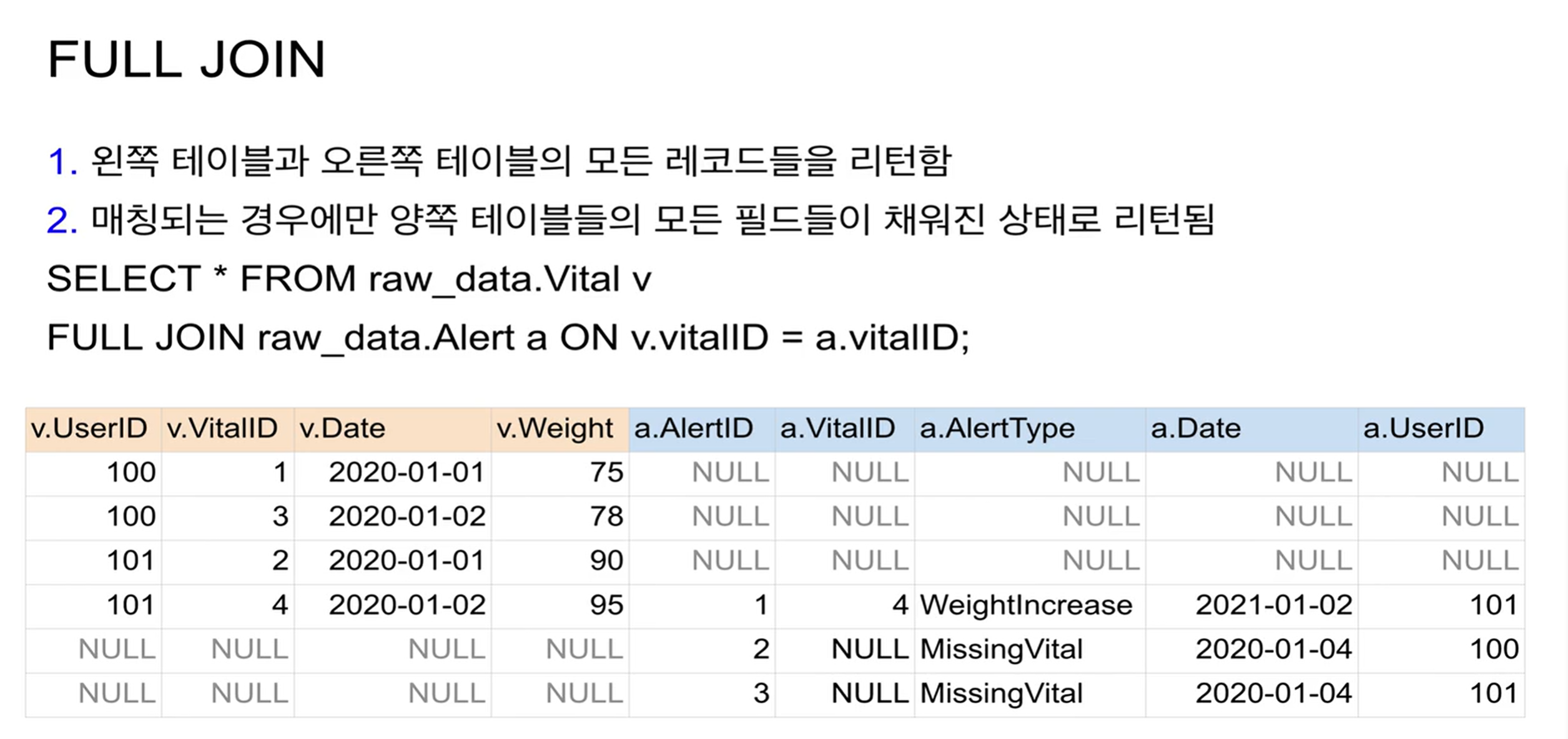
SELECT * FROM raw_data.Vital v
FULL JOIN raw_data.Alert a ON v.vitalID = a.vitalID;매칭이 안되는 것들은 각 테이블에서 NULL로 채워진 후 머지됨.
모든 레코드가 손실 없이 들어온 것을 볼 수 있음.
FULL JOIN은 가끔 쓸 때 유용한 경우가 있음.
CROSS JOIN
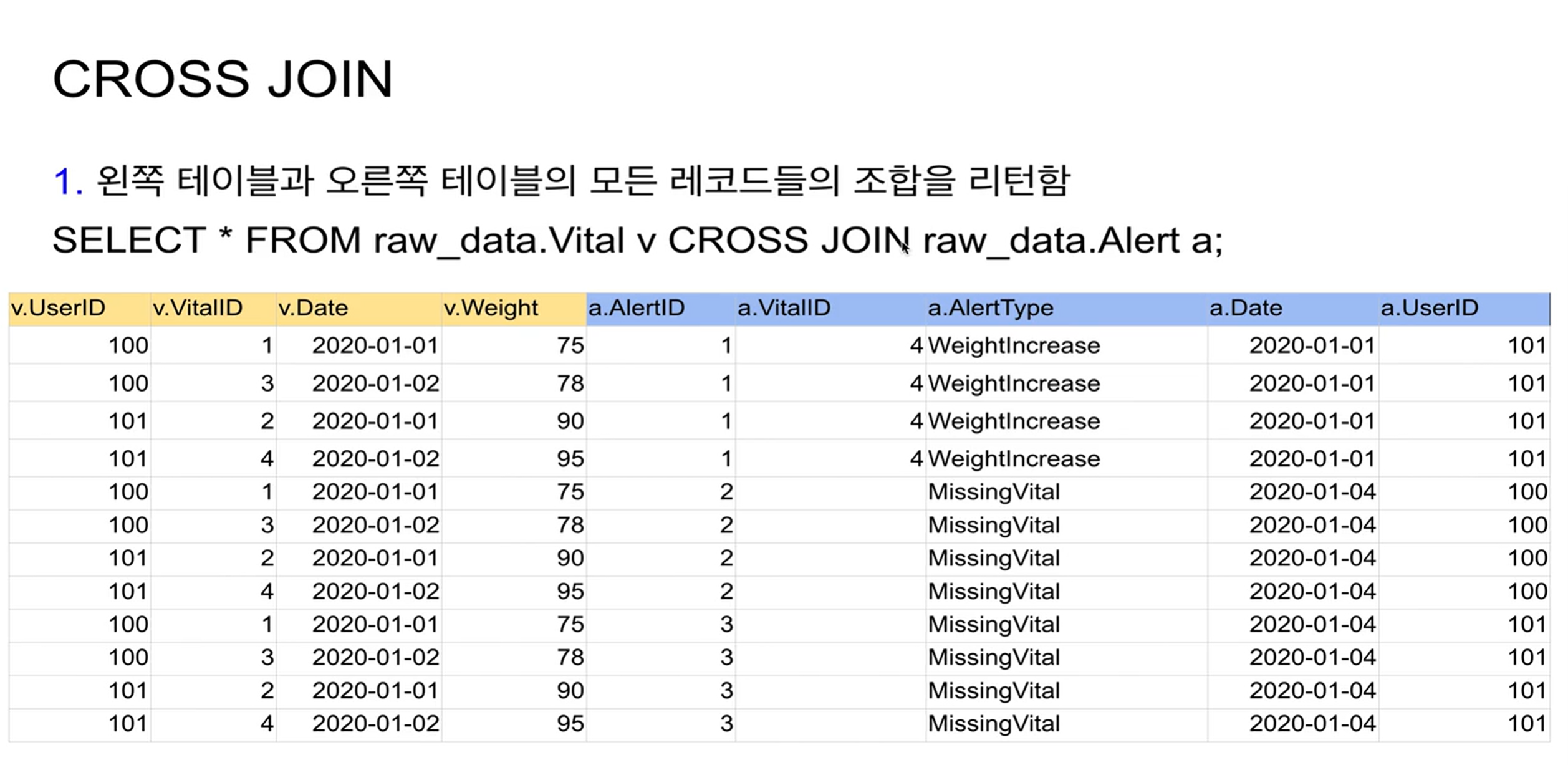
가능한 조합대로 모두 만들어 냄
-> 기준이 되는 필드가 필요하지 않음. 조합으로 만들어내기에
총 12개의 레코드가 생성됨.
SELF JOIN
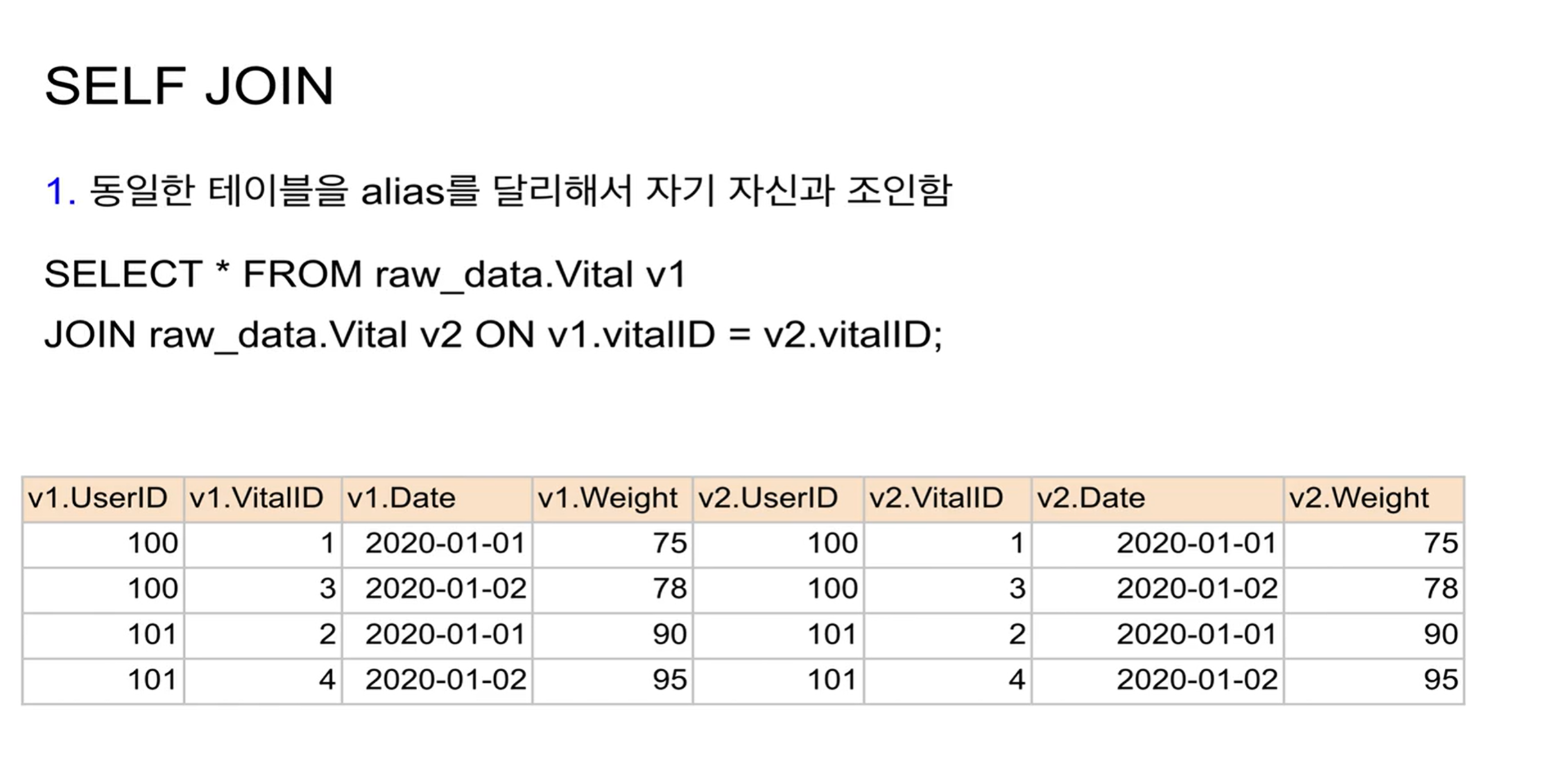
같은 테이블을 엘리어스만 다르게 해서 JOIN 시킴
보면 키값을 v1.vitalID = v2.vitalID로 했는데, SELF JOIN을 할 땐 이렇게 쓰진 않음.
위처럼 쓰면 같은 필드가 한번 더 반복될 뿐임.
JOIN 조건을 다르게 주게 됨.
실습
Guest 계정은 raw_data에 쓰기 권한 없음.
참고만.
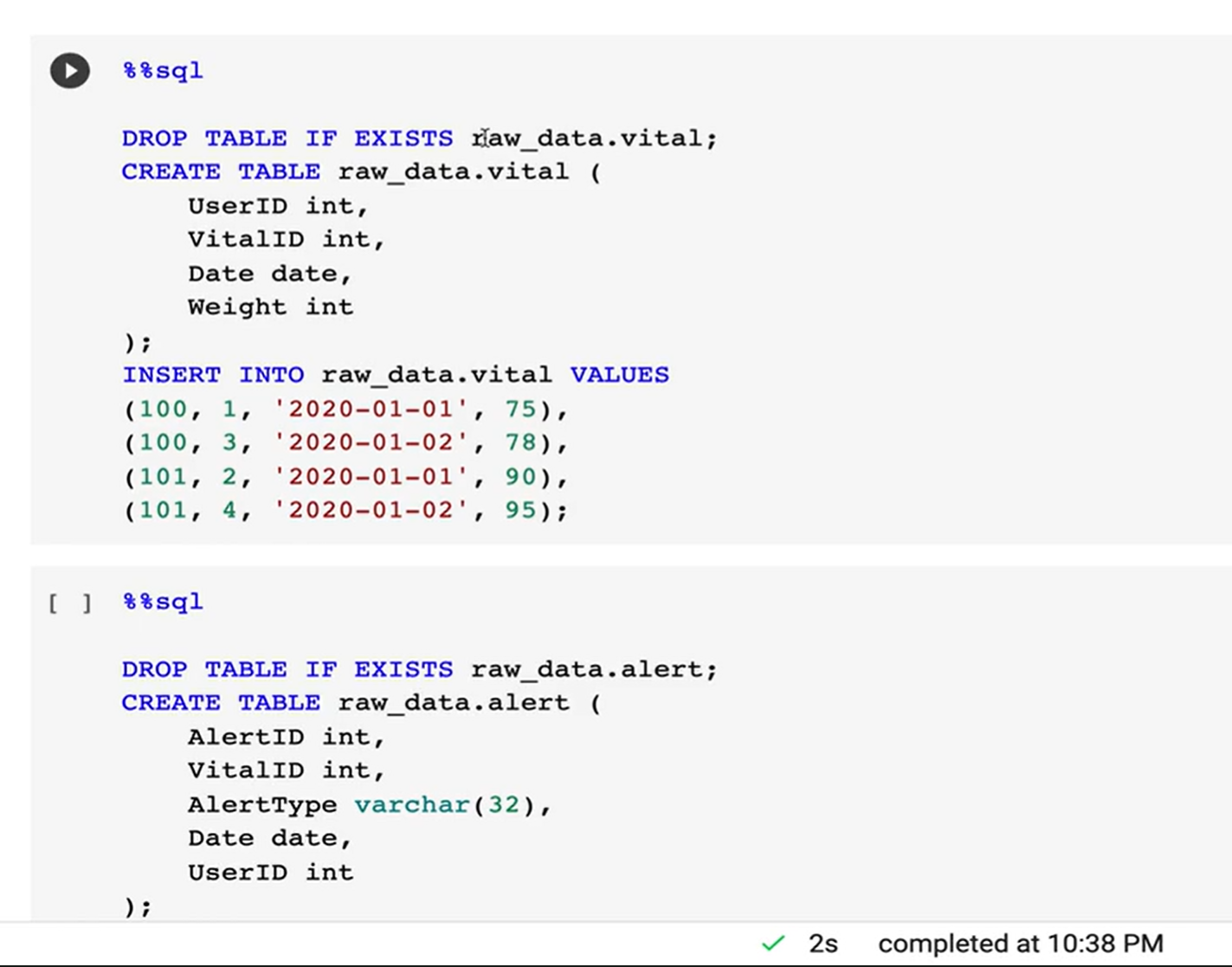
vital에 4개의 레코드 추가됨.

이렇게 된다 정도.
INNER는 생략 가능.

LEFT JOIN
FULL JOIN
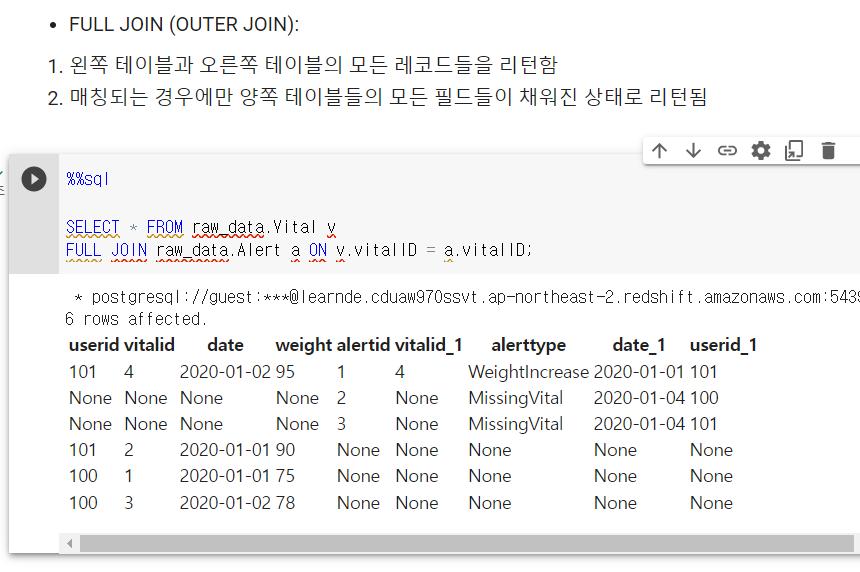
총 6개 리턴됨
제일 첫줄에 머지된 레코드
다음 단락은 한쪽에 존재하는 레코드
CROSS JOIN
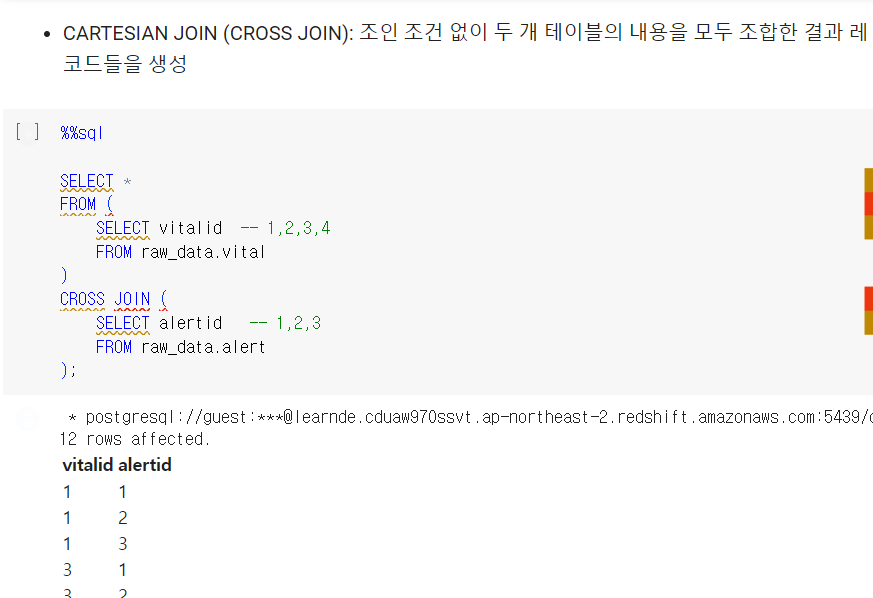
ID 필드만 추출해 CROSS JOIN 해보면 모든 경우의 수를 만들어낸다.
조건이 없는 점이 특징.
SELF JOIN
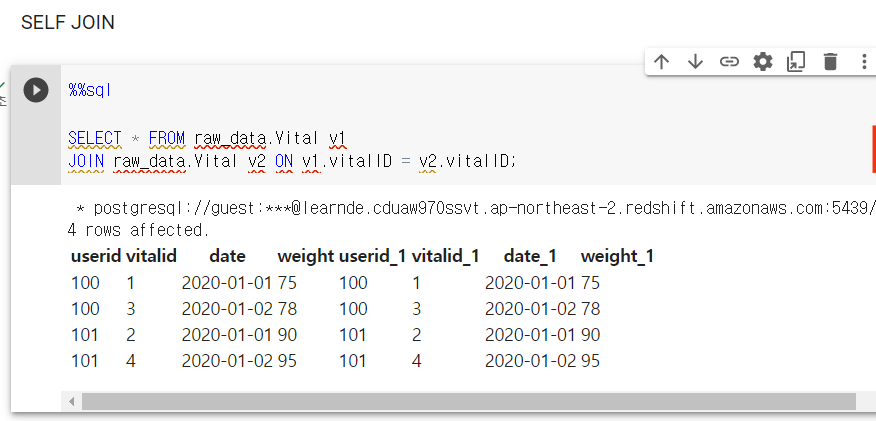
실무에선 ON 조건에 다르게 넣고 씀.
지금은 원래 테이블이 한번더 복사되어 붙은 느낌.
