학습주제
SELECT
학습내용
지난번 관계형 데이터베이스, SQL, 프로덕션 데이터베이스, 데이터 웨어하우스에 대해 알아보았다.
오늘은 SQL의 가장 기본이 되는 SELECT에 대해 알아본다.

지난 1일차 퀴즈 요약
데이터 웨어하우스의 특징 (프로덕션 데이터베이스와 비교)
- 처리할 수 있는 데이터의 크기가 중요
- 보통 클라우드 기반의 Redshift, BigQuery, Snowflake를 사용
- 회사 내부 직원들 (특히 데이터 팀원들)이 주 사용자다.
SQL에 대한 설명
- 1970년대 초 IBM이 개발한 관계형 데이터 질의/조작 언어
- 구조화된 데이터를 처리하는데 적합한 언어
- 데이터 일을 하는 사람이라면 반드시 알아야 할 기술
- DDL, DML
데이터 인프라의 일부
- 데이터 웨어하우스
- ETL 프로세스
- Spark과 같은 데용량 분산처리 환경
- (X) 프로덕션 데이터베이스는 데이터 웨어하우스의 소스가 됨.
클라우드의 특징
- 내가 필요한 자원을 필요한만큼 필요할 때 할당하여 사용할 수 있다.
- 운영비용 > 초기투자비용
- 고정비용 지출이 아닌 가변비용이라 재무측면에서 플래닝이 쉽지 않음.
- 서비스에 구현에 필요한 시간을 단축하여 기회비용을 최소화하는 이점이 존재한다.
관계형 데이터 베이스의 특징
- 구조화된 데이터를 테이블의 형태로 표현
- SQL을 사용하여 구조화된 데이터를 질의하고 조작
- 보통 데이터베이스 혹은 스키마라 부르는 일종의 폴더 밑에 테이블들을 생성하는 2단계 구조로 테이블들을 관리한다.
- 프로덕션 데이터베이스는 Star schema를 주로 사용 Denormalized schema는 데이터 웨어하우스에서 사용
AWS 회원가입 했다. 우측 위에 리전을 서울로 변경해준다.
서비스로 들어가 모든 서비스를 확인해본다.
거의 매달 새로운 서비스들이 추가되고 있음.
Amazon Redshift를 클릭.
하단의 Create cluster 클릭.
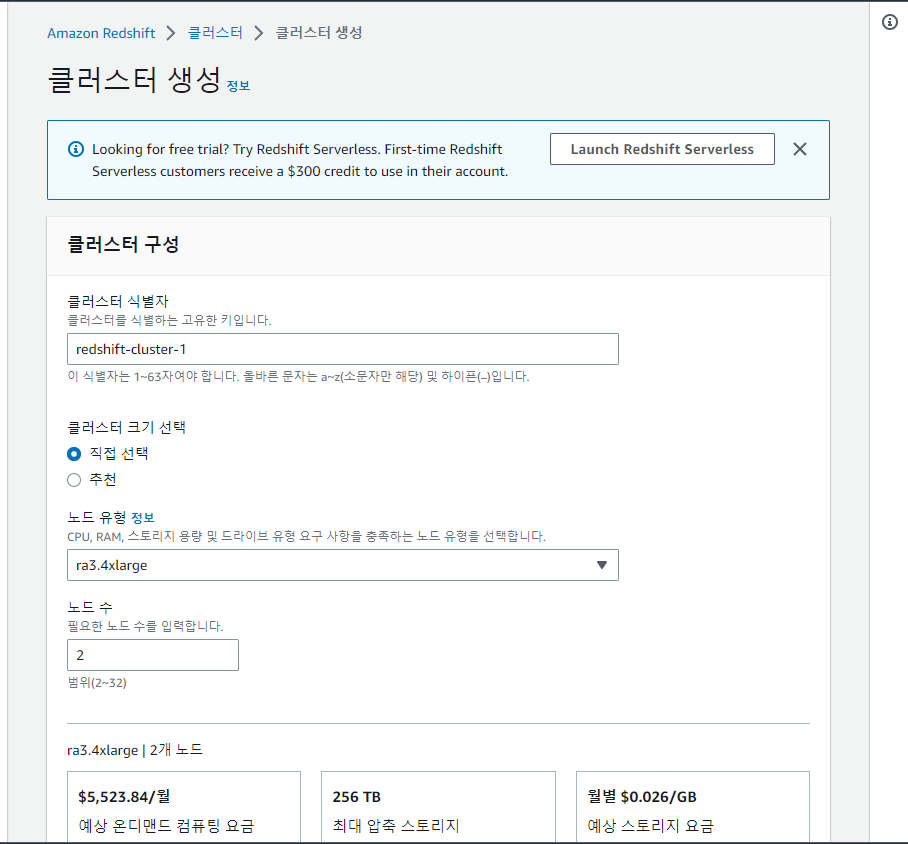
dc2.large 선택. -> 제일 저렴한 모드
시간당 30센트
서울이라 약간 비쌈. 월 216불 나옴.
미국이면 월 180불
awsuser 관리자 설정
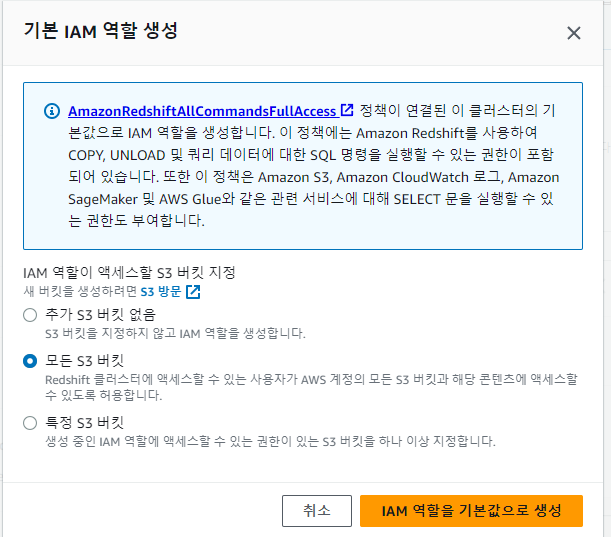
강의와 달라 모든 s3 버킷으로 선택
IAM 은 설명이 별도로 없으심. 일단 몰라도 됨.
추가구성으로, 외부에서 AWS에 접근 가능하게 해야함.
- 각자 구글 콜랩에서 가능케 해야함. 기본은 막아놓음
기본값 사용 OFF
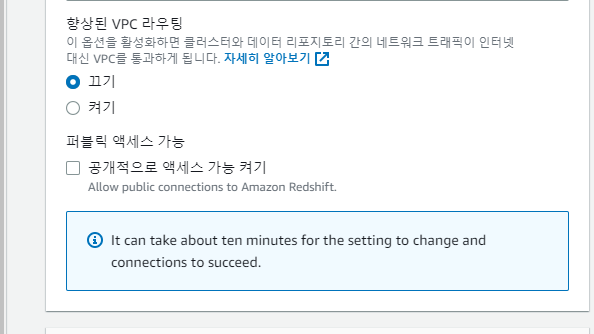
네트워크 - 퍼블릭 엑세스 가능 체크
데이터베이스 포트넘버: 5439
유지관리는 매주 한번
완료하고 클러스터 생성 클릭
-> 실패 서브넷 그룹이 없어서 임의의 서브넷 그룹을 생성함.
-> 성공함
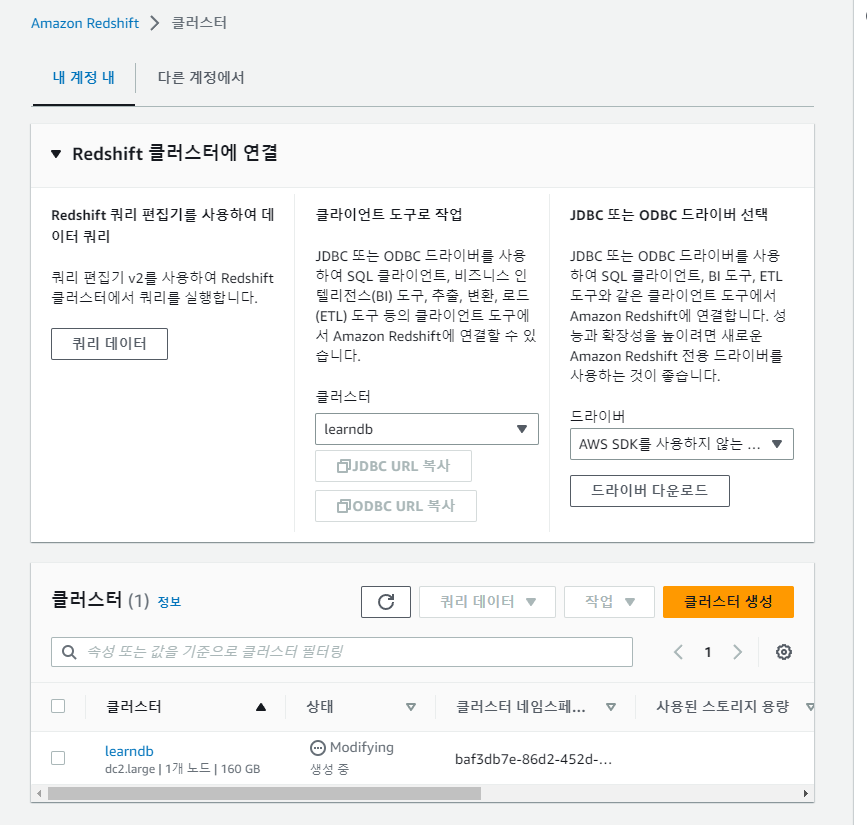
하단에 기본적인 구성정보가 나온다. 현재는 생성중.
awsuser, password를 가지고 이제 접근이 가능하다.
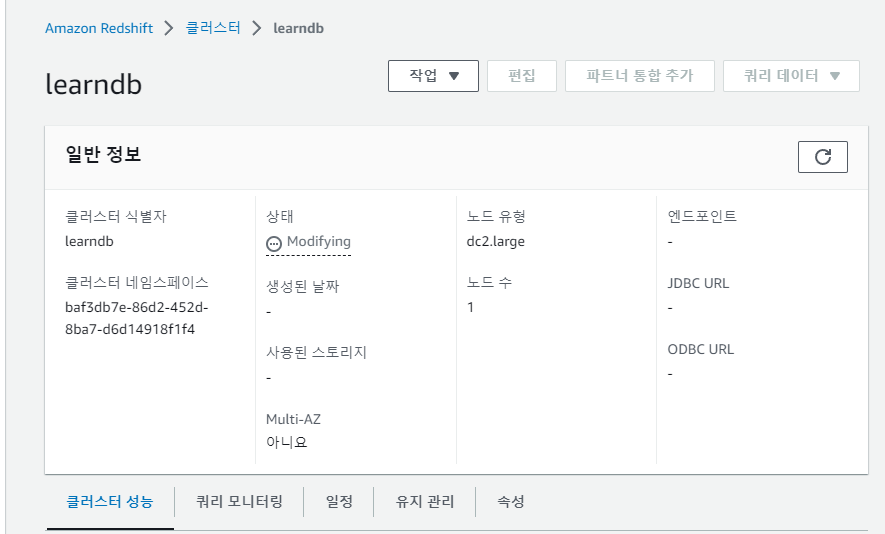
클러스터 생성이 완료되면 엔드포인트 값이 생성되고, 우리는 이를 가지고 클러스터에 엑세스가 가능해진다. 실제 엑세스는 구글 콜랩을 가지고 할 것임. 만들어진 테이블 사용예정.
Google Colab은 구글에서 제공하는 클라우드 기반의 무료 Jupyter 노트북 환경입니다. 이 환경에서는 Python 코드를 작성하고 실행할 수 있으며, GPU와 같은 고성능 하드웨어 자원을 이용하여 대용량 데이터를 처리할 수 있습니다.
Google Colab은 구글 드라이브와 연동되어 있으며, 브라우저에서 쉽게 사용할 수 있습니다. 이를 통해 사용자는 개인 노트북이나 컴퓨터의 자원을 사용하지 않고도 머신러닝, 딥러닝 등 다양한 분야에서 데이터 분석 및 모델링을 수행할 수 있습니다.
Google Colab은 Python 코드뿐만 아니라, 마크다운 문서와 그림, 수식 등을 함께 작성할 수 있습니다. 이러한 기능을 통해 데이터 분석 결과를 보다 효과적으로 공유할 수 있습니다. 또한, 다른 사용자들과 공유할 수 있는 공개 노트북을 생성하거나, 개인적으로 사용할 수 있는 비공개 노트북을 생성할 수도 있습니다.
raw_data 폴더 밑에 몇개의 예제 테이블을 로딩. 이를 가지고 analytics로 만들어볼 예정.

Host는
- 내가 정의한 클러스터 이름
- 고유한 아이디 값
- 지역정보
- redshift.amazonaws.com
포트넘버: 5439
데이터베이스 이름: dev
구글 콜랩에서 이 정보를 가지고 실습시 연결할 예정.
사용할 Guest account을 따로 만든 후 이를 공유 받아서 할 예정.

의미있는 주제를 가지고 예제 테이블을 생성함.

웹서비스를 만든다 가정하면, 사용자마다 ID를 부여하게 됨. 숫자, 랜덤한 문자 시퀀스 등. 유니크한 ID. 사용자의 활동을 tracking하기 위한 ID, 세션마다 유일한 ID부여. 사용자가 우리 웹서비스를 방문할 때 그것을 논리적인 단위로 나눔. 세션의 정의는 구글 애널리틱스의 정의를 따른다.
- timebound: 사용자가 방문한 순간 생성. 방문 후, 아무것도 안하다 나가면 세션이 종료되고 ID가 부여됨. 이후 다시 들어와서 뭔가를 하면 세션이 생성되고 ID가 부여
- 외부 링크를 타고 오면 생성.(유튜브, 광고) 이미 이 사이트에 방문을 했고, 30분이 지나지 않더라도 광고를 통해서 왔다고 하면 또 세션을 생성함 -> 이런걸 통해서 사용자가 어떻게 이 사이트를 발견해서 방문을 했는지 tracking을 하고 싶기 때문. 마케팅 기여도 분석에 큰 도움.
사용자 ID
세션 ID
하나의 사용자는 여러개의 세션을 가질 수 있음. - 아침에 들어와서 이것저것 하다, 아무것도 안하다 이후 30분 뒤에 뭘 했다. -> 세션 2개 생성.
- 두번째 생성 때 페이스북 광고를 보고 우리 사이트에 또 방문했다면,(외부링크를 타고 들어왔으므로 30분이 지나지 않더라도) 세션을 또 생성한다.
이미 아는 사이트가 아닌, 직접 주소를 쳐서 들어온 경우 direct-visit (직접방문) 접점이 없음. 인스타, 유튜브 광고를 보고 실행을 시켜 방문을 한다면 접점이 생김.
처음 광고를 낼때 어떤 매체에 내야할지 잘 모름. 사용자가 주로 어떤 경로로 유입하는지 모르기 때문에. 세션을 가장 많이 만들어 내는 채널이 뭔지 알게됨. 그럼 마케팅 담당자는 보다 집중할 광고 매체를 선택할 수 있게 됨.
이러한 데이터 로깅은 매우 중요함. -> 이번 실습 테이블
세션이 생길 때
- 세션 ID
- 세션을 소유한 사용자의 ID
- 세션 생성 시간
- 세션을 만들어낸 채널 정보
가 기록됨.
어느 채널을 통해 가장 많은 세션이 생성되는지는 금방 알 수 있음. 이렇게 온 사람들이 얼마나 회원가입을 했고, 얼마나 서비스를 구매했는지가 중요함. 마케팅 관련 기여도 분석 Marketing channel attribution. 어느 채널에서 가장 많은 매출을 일으키냐가 중요해짐. 트래픽은 많이 보내주지만 매출과는 연관이 떨어지는 채널들이 있을 수 있음. 채널을 통해 들어온 방문자의 수, 세션만 볼 것이 아니라 매출로 얼마나 이어졌는지 까지 보는게 좋음.

일련의 지표설정이 가능해짐
사용자 트래픽 관련 일별(DAU), 주별(WAU), 월별(MAU) Active User(그 기간동안 한번이라도 우리 사이트를 방문한 사람) 여기서 특별한 유저만 카운트함. 어떤 사용자가 1달에 4번 방문했다면 MAU에서 1개의 유저.
DAU, WAU, MAU는 SQL로 Group BY 로 간단하게 알 수 있음.
마케팅 관련
이 세션을 만들어낸 경유지(채널) 이를 바탕으로 지난 일주일 동안 세션을 많이 만들어준 채널이 무엇인지. 우리에게 가장 많은 매출을 만들어준 채널을 분석할 수 있음.
이런정보들은 프로덕션 데이터베이스에 존재. 구글 애널리틱스등에 존재.
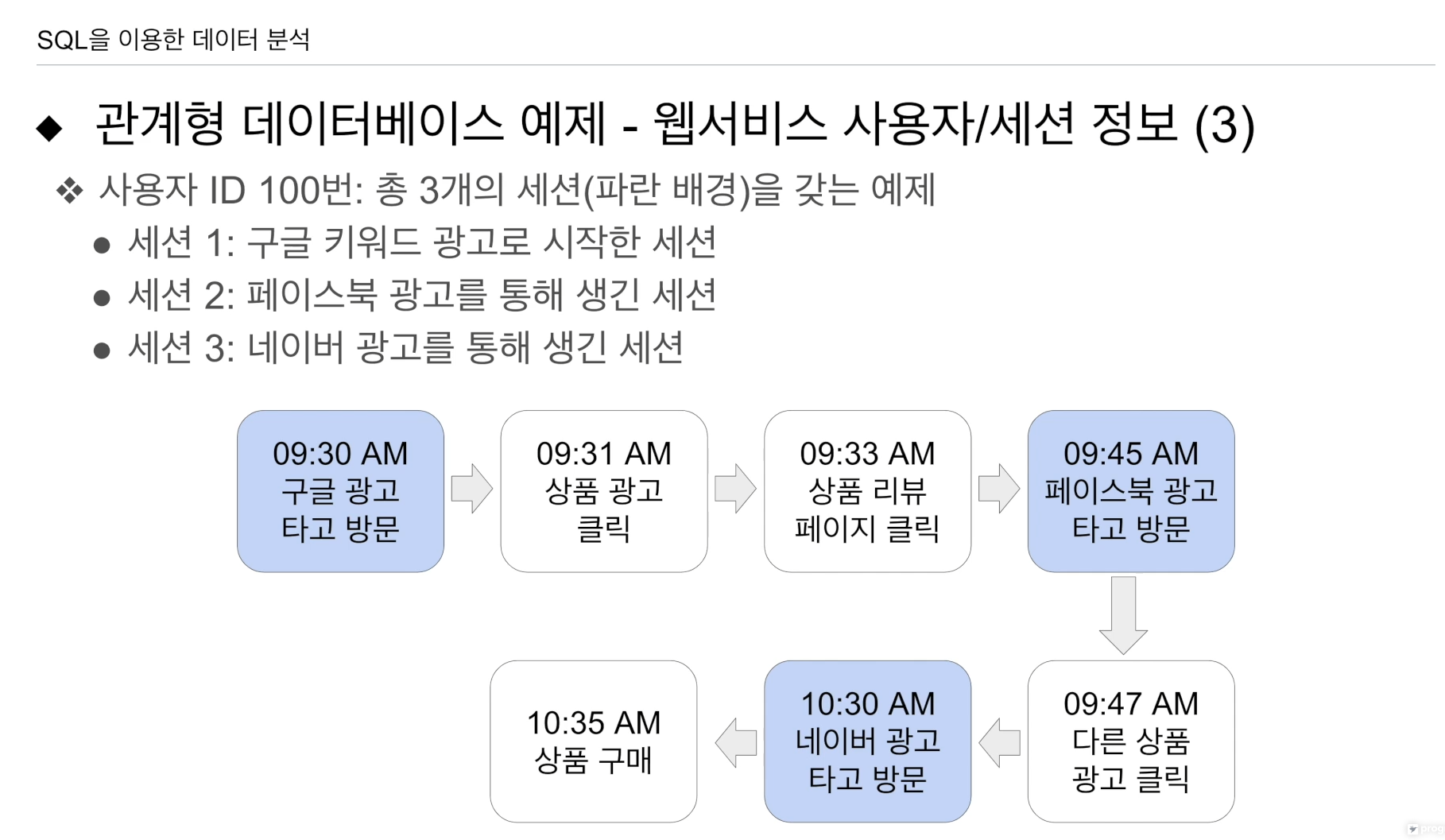
사용자가 총 3개의 세션을 만들어냄.
세션1: 구글 검색으로 나온 광고를 보고 사이트에 처음 방문.
- UserID 100, session ID 1, channel Google AD, 시간
세션2: 페이스북에서 다시 들어옴(외부에서 링크를 타고 새로 들어왔기 때문.) - UserID 100, session ID 2, channel facebook, 시간
세션3: 네이버 광고를 타고 들어옴 - UserID 100, session ID 3, channel naver, 시간
가장 좋은 상태(물품 구매) 세션 3 상태에서 일어남.
구글, 페이스북, 네이버 모두 세션을 만들어줌.
그럼 어떤 채널이 이 상품구매에 가장 기여했는가?
보통은 사용자가 채널 하나 만들고 끝나는 경우가 90%임. 그러나 물건이 비쌀수록 여러형태로 리서치를 하고, 여러 채널을 통해 들어오는 것이 기록이 됨.
그럼 어느 채널에 크레딧을 줄 것인가?
방법론.
First channel attribution: 해당 사이트를 처음 발견하게 해준 채널에게 크레딧(기여도)를 몰아줌.
Last channel 상품구매를 만들어낸 마지막 채널에게 몰아줌.
Multi channel 조금씩 채널들에게 나눠줌.
이러한 분석을 SQL 분석을 통해서 조금씩 해볼 예정.
사용자 ID, 세션 ID, 세션 생성 시각, 채널 정보

이를 하나의 테이블에 저장할 수 있겠지만, join 등을 고려해 2개의 테이블로 나눔. star schema 형태로 생성.
user_session_channel
- 사용자의 ID
- 세션 ID
- 이 세션 ID와 연관된 channel
- 언제 세션이 만들어졌는지? -> 생략됨.
session_timestamp - 세션 ID
- timestamp: 세션이 만들어진 날짜와 시간이 기록.
merge를 하는 것을 join, join 키가 필요함.
PK 어떤 레코드를 유일하게 지칭해주는 필드. (주민번호, 이메일, 사용자 ID)
User ID는 PK가 될 수 없음. 하나의 사용자는 여러 세션 ID를 가질 수 있기에.
sessionId가 PK가 됨.
sessionId를 가지고 join하게 될 것임.
테이블들을 가지고 요약하면 marketing 폴더를 생성해서 그 아래 테이블을 만들 수 있음.
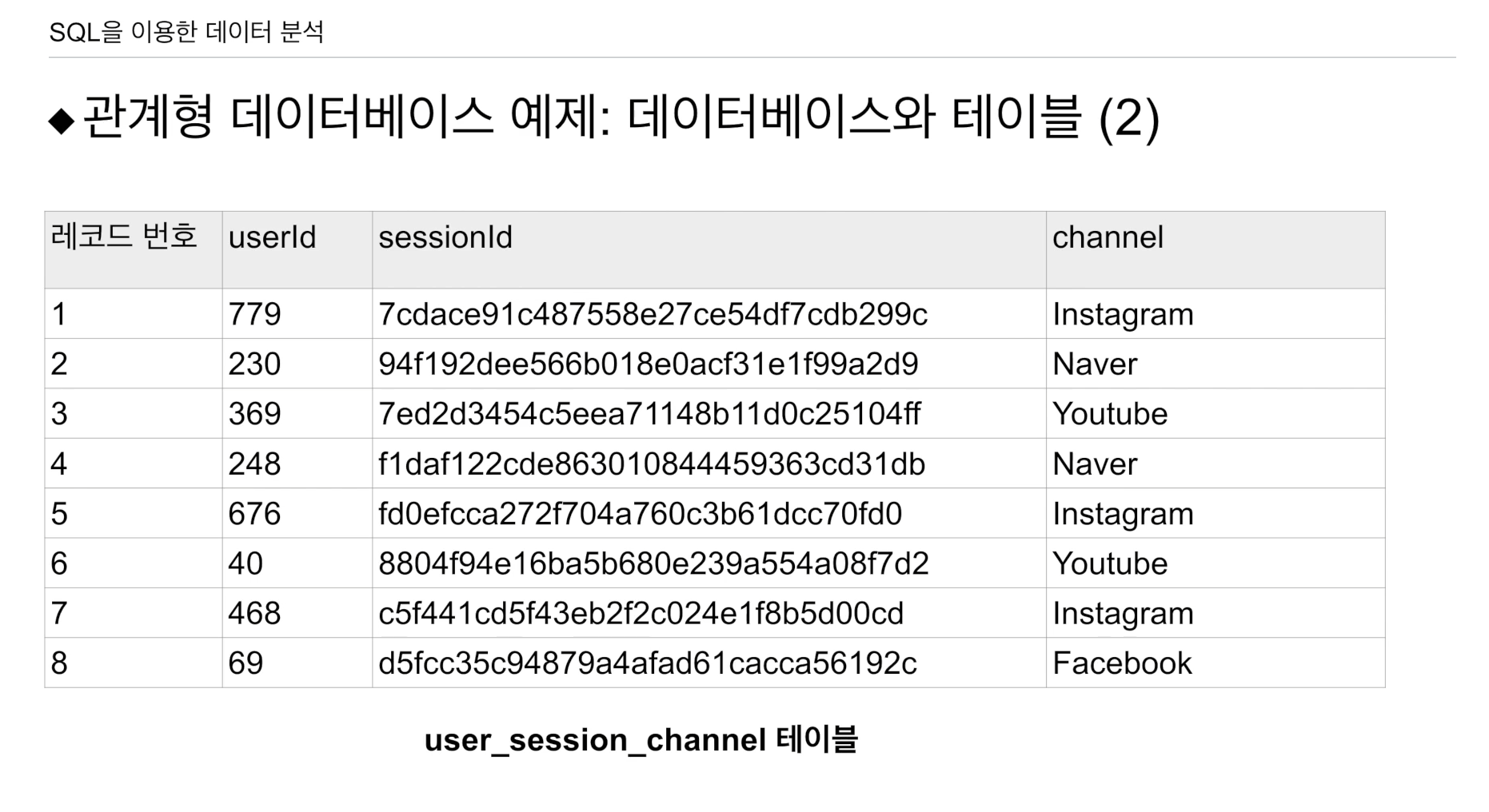
실제 필드는 아님.
이 테이블에서는 timestamp를 알 수는 없다.
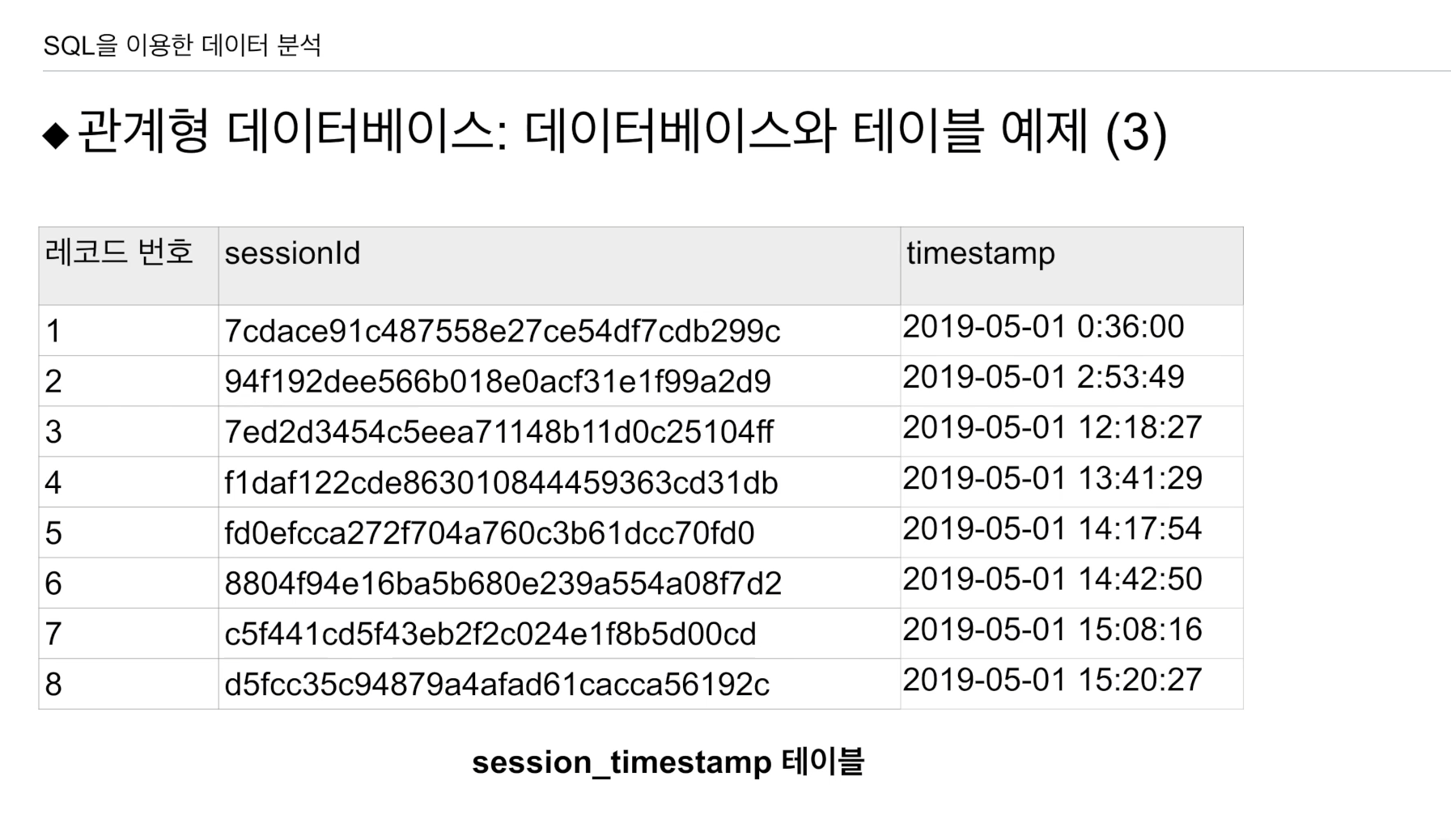
이후에 테이블들을 추가할 예정.

Redshift라고 SQL 문법이 크게 다르지 않음. Postgresql 8과 호환됨.

- 다수 sql 동시실행 시 ;
- --로 주석 사용
- 여러줄 주석 /* */
- SQL 지원 키워드들 (SELECT, FROM, TABLE)은 나름 규칙 (예를들어 대문자 사용)
- 테이블/필드이름의 명명규칙을 정하는 것이 좋음. 우리팀은 단수형, 캐멀케이스 사용 이렇게.

DDL 부터 살펴본다. 테이블의 구조를 정의해준다. SQL은 대부분 2단계. 폴더 - 데이터베이스, 스키마 아래에 테이블이 존재함. 스키마 를 생성해주는 것도 DDL에 포함.
(필드 이름, 필드 타입) 으로 집어넣는다.
CREATE TABLE raw_data.user_session_channel)
userid INT,
sessionid VARCHAR(32) PRIMARY KEY,
channel VARCHAR(32)
);보면 PRIMARY KEY가 지정되어 있으나, 무시된다.
프로덕션 DB에서는 PRIMARY KEY를 지정해주면 Unique을 자체적으로 보장해줌. 그러나 DW에서는 대량의 레코드를 매번 unique를 확인해주게 되면 효율이 떨어져버려 무시해버림.
따라서 저기 쓰는건 일종의 주석처럼 나중에 개발자가 보고 따로 작업을 해라하고 인식하는 정도.
위의 생성은 테이블의 구조만 만들어둔 상태고 레코드는 미입력된 상태.
INSERT INTO는 한줄씩 입력이라 오래걸림. bulk를 지원해주는 COPY를 사용함.
csv -> S3 업로드 -> 원하는 테이블로 bulk 업데이트
CTAS: 테이블을 만듦과 동시에 내용까지 채우는 것.
CREATE TABLE table_name AS SELECT
네, "AS" 키워드는 생략하여 CTAS를 사용할 수 있습니다. 즉, 아래와 같이 SQL문을 작성할 수 있습니다. 하지만, "AS" 키워드를 생략하면 SQL 구문의 가독성이 떨어질 수 있으므로, 일반적으로는 "AS" 키워드를 사용하여 CTAS를 작성하는 것이 좋습니다
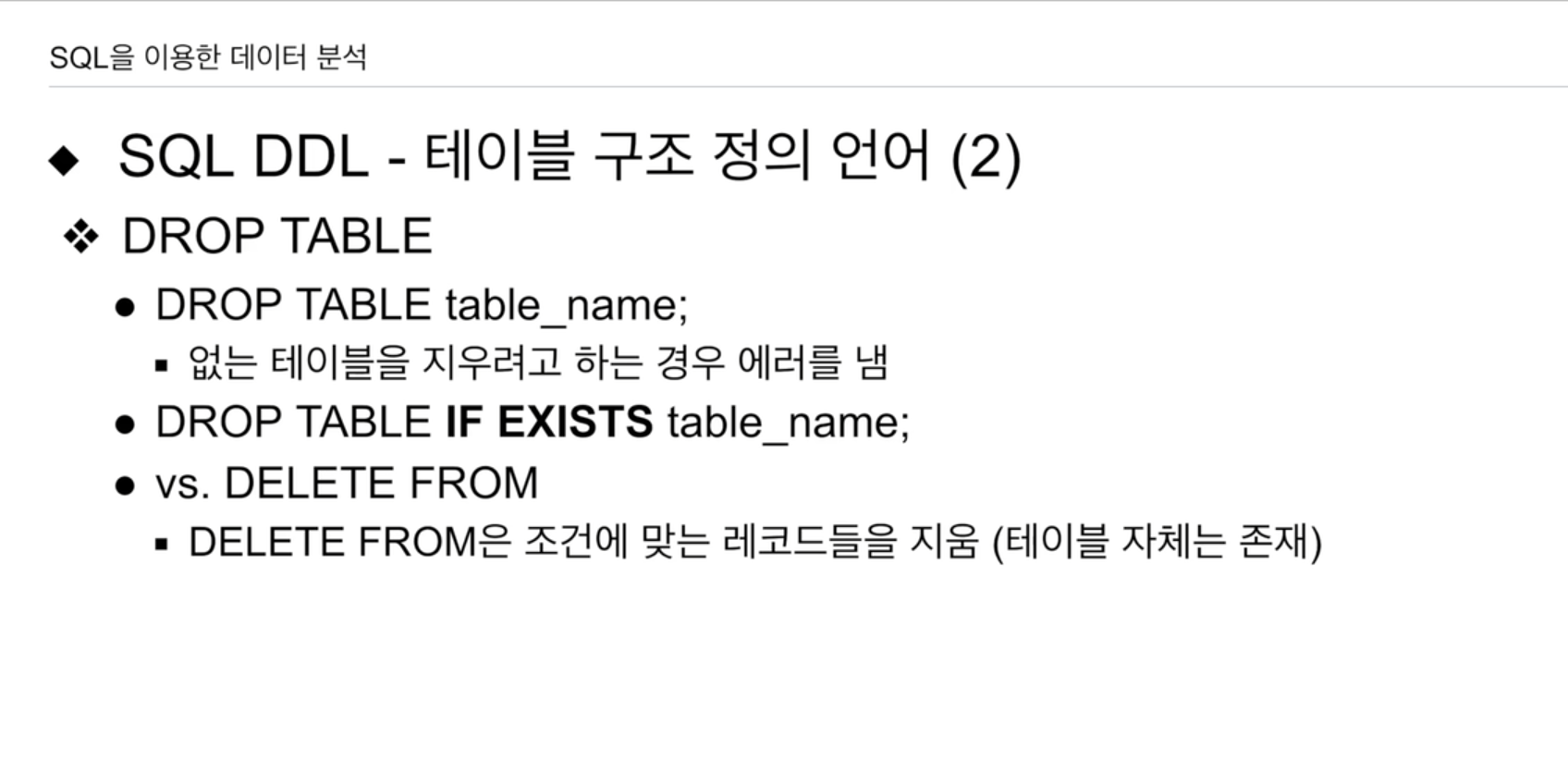
DROP TABLE -> 테이블 대상으로 수행.
없는 테이블을 지우려할 때 에러를 냄. 이게 좀 번거로우면
DROP TABLE IF EXISTS table_name;DELETE FROM 의 경우 테이블은 보존함. (한줄 한줄 지우기에 상당한 시간)
TRUNCATE TABLE도 보존 (매우 빠름)

새로운 컬럼 추가
ALTER TABLE table_name ADD COLUMN field_name CHAR(5);기존 컬럼 이름 변경
ALTER TABLE table_name RENAME old_field TO new_field;기존 컬럼 제거
ALTER TABLE table_name DROP COLUMN field_name;테이블 이름 변경
ALTER TABLE old_table RENAME TO new_table;

