
파티션에 대해 설명.
RDD, 데이터 프레임, 데이터 셋에 대한 설명
스파크 세션이라는 변수에 대해 설명.
개발 환경에 대해 설명 - 구글 콜랩 중심으로.
로컬 스탠드얼론 - mac 기준 설명
5개의 스파크 프로그래밍 예제를 풀어볼 예정.

시스템이 갖는 구성에 대해 간단히
처리 단위인 파티션 알아보고, 균등하지 않을 때 발생하는 이슈들에 대해 설명.
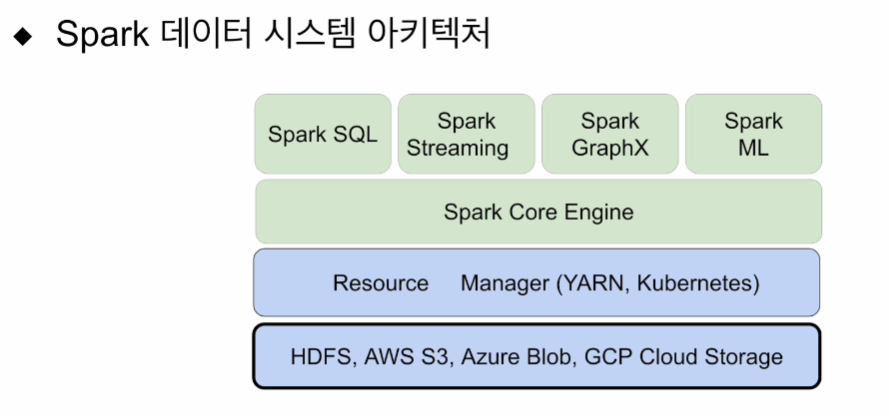
데이터 처리 관점에서 스파크를 어떻게 구성할 수 있을지 살펴본다.
스파크는 파일 시스템을 별도로 갖고 있지 않음.
기존 분산 파일시스템을 사용해야한다.
흔히 사용되는 옵션들. 그위에
이 위에 스파크가 올라간다
다양한 패키지들이 올라갈 수 있음
빅데이터 프로세싱에 관련한 종합 선물세트 같은 애임.
배치 형태로 큰 데이터를 ETL 하거나, adhoc 형태로 인터렉티브하게 쿼리 날릴꺼라면 하이브나, 프레스토 써도 상관없음. 그러나 하나의 시스템으로 다양한걸 해볼 수 있기 때문.
입력에 대한 데이터들이 있을 텐데 내부, 외부 등에 있을 수 있는데, 어떤 아키텍쳐를 가져갈 것인가가 논의되어야 함.
내부 - HDFS에 있는 파일. 스파크 로딩하는데 큰 문제 없음. 가장 최적화 잘 되어있음.
그러나 모든 데이턷가 HDFS에 있진 않음
외부 - 관계형 데이터베이스. NoSQL. 주기적으로 ETL로 HDFS로 가져옴. 내부데이터 되면 내부 프로세싱해서 가져오면 됨.
ETL 잡 스케줄링을 위해선 에어플로우를 사용함.
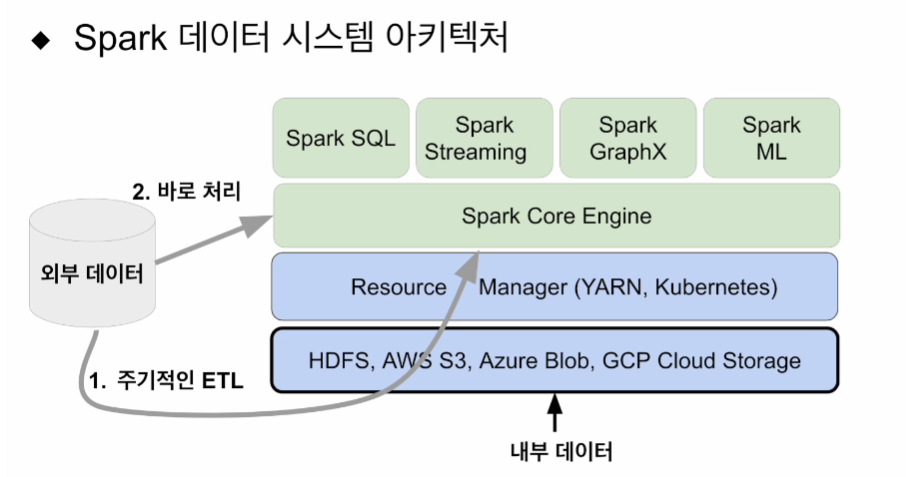
또는 스파크에서 바로 처리하는 방법이 있음. 성격에 따라 스파크 스트리밍, 아님 배치로 읽어다 스파크 SQL에서 처리.
어쨌든 스파크 위에 올라간 순간 동일한 데이터가 됨. 이것들을 트랜스폼 해서 내가 원하는 형태로 만든 것들은 어딘가에서 또 쓰임.
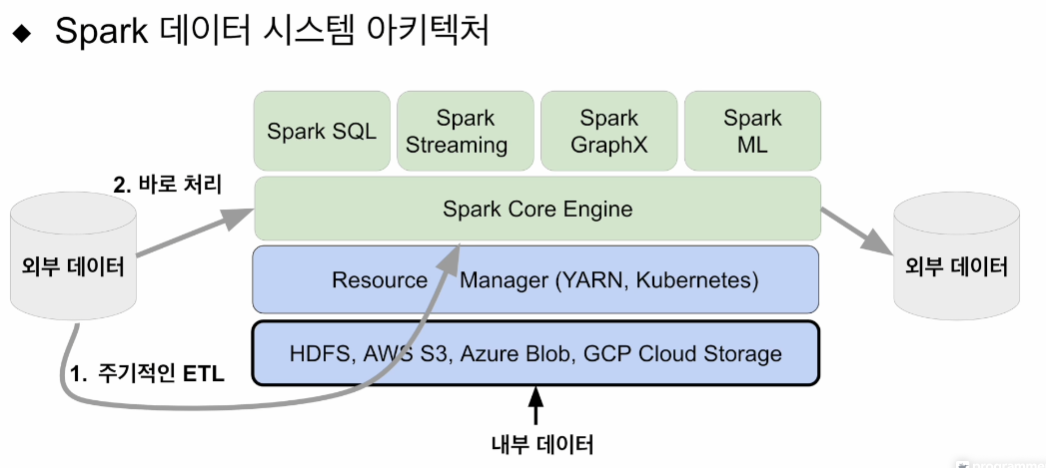
HDFS에 다시 쓰게 하거나, NoSQL로 나가거나 다양하게 쓰일 것임.
스파크에 올라간 순간 모든 데이터들이 데이터 프레임, RDD, 데이터 셋이 될 것임.
나눠진것들을 파티션이라고 함.

대용량 분산처리 시스템의 특징은 병렬처리에 있음
결국 데이터가 분산되어야 함. 분산관점에서 HDFS같은 시스템이 굉장히 좋음. 큰 파일들을 데이터 블록 단위로 나누어 저장. 레플리케이션 팩터를 통해 유실 방지 위해 팩터 수만큼 동일한 데이터블락이 다수의 서버간에 복제가 될 것임.
분산처리 하는 관점에선 블록단위로 읽어들이면 됨. 128mb은 흔히 쓰이는 크기. 내가 HDFS를 관리하고 있고, 시스템 특성상 변경하고 싶으면

여기서 조정할 수 있다.
이런 데이터를 스파크의 데이터 처리를 위해 로딩한다면 파티션이라고 함. HDFS의 데이터 블록처럼 기본 128mb. 이 역시 스파크 환경변수로 조정 가능

모든 입력에 적용이 아니라 HDFS의 경우. 보통 동일하게 맞춰주는게 좋음.
큰 데이터가 있을 때 HDFS에서 스파크로 프로세싱을 위해 로딩을 할 때 데이터 블록 하나가 그대로 파티션으로 스파크에 로딩이 됨.
데이터가 분산이되어 엑시큐터들로 로딩이 될 것이고, 알아서 병렬처리 해줄것임. 맵리듀스에선 n개의 데이터 블록 처리시 n개의 맵퍼가 실행. 맵태스크가 실행됨. 데이터 로컬리티를 실행시켜, 블록이 있는 서버에서 맵퍼를 실행케 함. 최적화 작업임. 스파크에선 이런 데이터 블록이 로딩이 될 때 파티션이라 부르고, 기본적 메모리로 로딩, 엑시큐터에 배정이 됨. 한 엑시큐터에 여러개의 테스크가 돌 수 있기 때문. 이론적으론 여러개의 파티션을 처리할 수 있음.
다이어그램으로 살펴본다
기본적으로 큰 파일이 있다고 한다 .HDFS로 가정하면 여러 블록이 있고, 이는 파티션으로 엑시큐터를 통해 처리될 것임.
데이터 소스에 따라 달라짐. HDFS가 아니라 mySQL, postgres에서 읽어야 한다면, 이는 JDBC로 연결이 됨. 별로 파라미터 세팅 없으면 기본적 하나의 파티션만 만들어냄. 관련된 문서를 찾아서 확인을 해야한다.
따라서 꼭 필요하지 않다고 하면 ETL 프로세스를 구동하여 HDFS에 저장하고, HDFS에서 스파크로 불러들이는게 가장 좋음.
유스케이스마다 적용여부가 달라질 수 있음.
스파크 클러스터에 엑시큐터가 2개, 각 CPU 1개. 2*1 로 최대 2개의 테스크만 실행 가능함. 4개의 파티션이 있지만 병렬처리는 2개의 파티션이 최대. 우선 p1, p2가 각 엑시큐터에 의해 병렬처리 됨. 그 후 p3, p4가 배정됨. 동시에 실행할 수 있는건 스파크 클러스터의 capacity
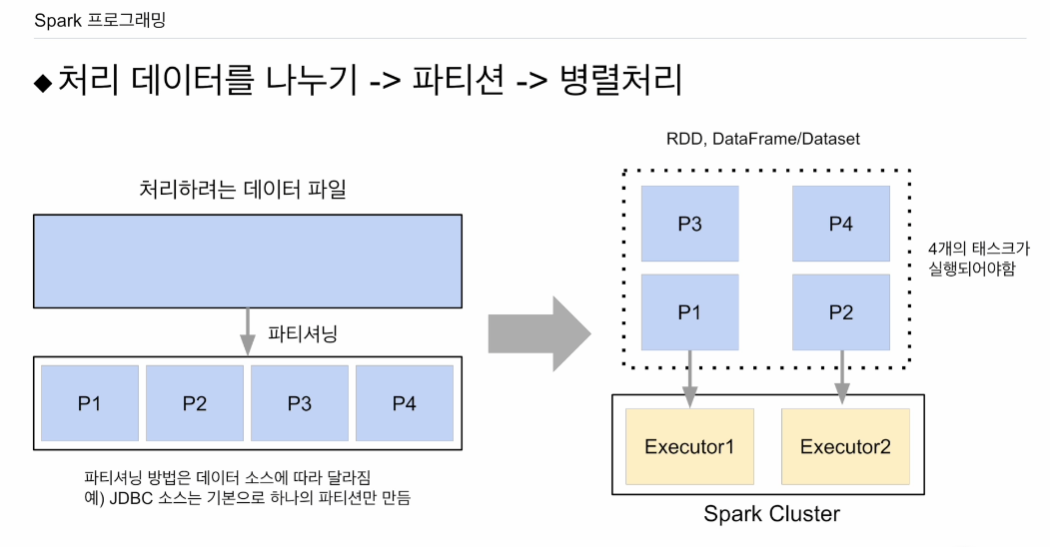
파티션은 데이터가 물리적으로 나뉜거라고 보면 됨. 이 파티션에 저장된 데이터는 RDD나 데이터 셋일 것임. 데이터프레임은 데이터 셋의 특정한 포맷이라고 보면 됨. 이에 RDD 혹은 데이터 셋임.
병렬성을 최대화 하려면, 파티션의 수를 엑시큐터 수 곱하기 엑시큐터가 갖는 CPU의 수의 합으로 해줄 수 있으면 한번에 모든게 처리가 될 것임. 이것이 병렬성을 최대화 하는 방법. 이론적으로.

논리적인 관점에서 처리 흐름 보면
판다스 프로그램을 해보면, 데이터 프레임과 같음. 차이점은 스파크에서 말하는 데이터프레임은 매우 큰 데이터. 하나의 서버에서 처리 안되고, 파티션으로 나누어서 처리. 판다스 데이터 프레임과의 차이는 결국 크기. 데이터 프레임은 한번 만들어지면 수정이 안됨. 수정하려면 새로 데이터 프레임을 만들어야 함. 스파크 데이터 처리의 흐름은
입력 데이터가 있으면 이 입력 데이터들을 데이터 프레임으로 스파크 클러스터에 로딩. 크기에 따라 여러 파티션이 있을 수 있음. 입력 데이터 프레임을 다양한 변환작업을 통해서 group by, filter, map, sort, join 등. 최종적으로 내가 원하는 데이터 프레임이 만들어졌을 때 그걸 어딘가에 저장함.

중요한 포인트는
이렇게 하면 굉장히 빠를거 같다. 데이터 프레임이 파티션의 집합으로 구성. 각 파티션을 각 엑시큐터 안의 태스크가 처리하기에 병렬성이 유지되어 굉장히 빠를 것 같지만 우리가 하려는 모든 작업이 파티션간의 데이터 이동 없이는 안됨. map, filter. 한 파티션 데이터가 다음 파티션의 데이터로 만들어질 때 물리적으로 다른 서버로 이동될 일이 없음. 그 파티션 안에 있는 데이터 만으로 충분.
그러나 group by, sort의 경우 새로운 파티션을 만들어야 함. 즉 데이터 이동이 필요함 그 과정에서 네트워크를 타고 데이터 전송이 이뤄짐 그 과정에서 새로운 파티션들 간에 데이터가 균등하지 않을 수 있음.
group by, sort. 데이터 이동 필요.

이를 셔플링. 새로 파티션을 만들고 데이터 이동이 일어남. 네트워크를 타고 데이터 송 수신 일어남.
셔플링은?
- collase 등으로 파티션을 바꿈.
- 특정 키값을 기준으로 같은 파티션으로 묶기
- 기존 파티션으로는 데이터가 작업을 할 수 없는 경우, 앞에서의 group by, sort같은.
셔플링이 생기면 네트워크의 데이터 이동이 일어남.
- 셔플링 발생했을 때 새로 생기는 데이터프레임은 몇개의 파티션? 파라미터가 결정함. 모든 셔플링 이후에 파티션 수가 무조건 200개가 되는건 아님.
- 오퍼레이션에 따라 결정. 200이라는 값보단 클 수 없음.
- 랜덤하게, 특정 키값을 보고 해싱으로 같은 키값이면 같은 파티션(group by), range는 키 분포를 보고 새로 파티션을 만듦(sort)
예를들어 df 프레임이 p1, p2, p3로 구성. 여기에
df2=df.sort("age") 새로운 데이터 프레임을 만들었음. sort는 기존 파티션 내로는 전체 sort가 안되어 데이터 이동이 필요함. range partition 사용됨. 데이터 프레임의 키값. age의 분포를 봄. 전체를 다 뒤져서 보기엔 너무 오래걸릴 수 있기에 샘플링을 함. 적당히 샘플링을 해서 이 키값이 갖는 range를 보고 파티션을 새로 만듦. 최대 200개. 3개의 range로 결정되면 3개의 파티션이 만들어지고 age라는 키값에 따라 데이터가 분배됨. 만일 range가 잘못되면 데이터스큐 발생. 특정 파티션이 데이터가 많음
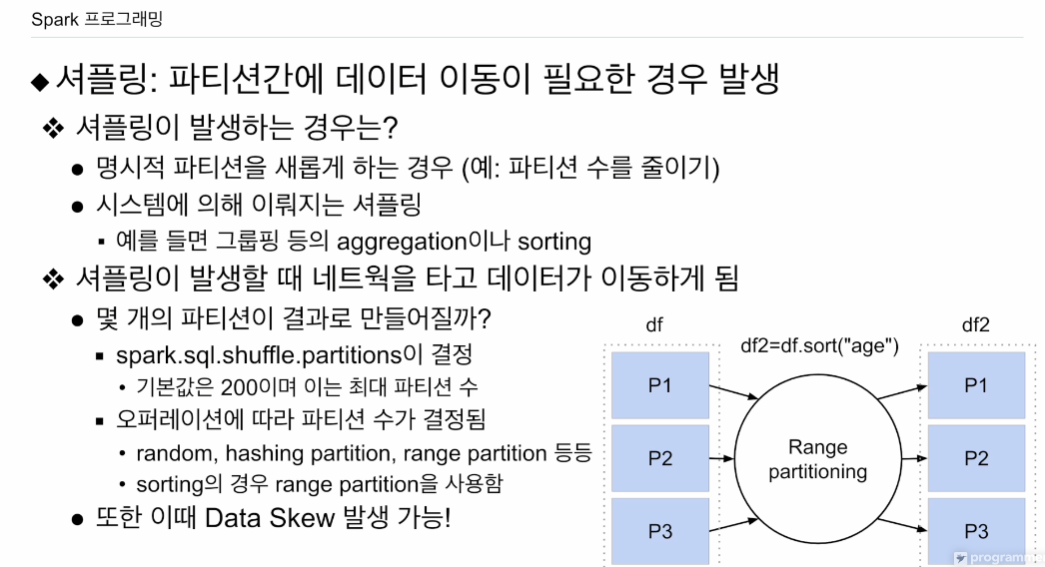
셔플링 후에 데이터 스큐가 생길 수 있음
hash는 집계 때 사용.
예를 들어 df1 데이터 프레임은 3개. name 필드에 적당한 내용.
name을 기준으로 df2=df1.groupBy("name") 이름이 같을 경우 같은 파티션으로 모으고자 함. 그 경우 해싱 파티셔닝을 함. 키로주어진 필드의 값을 해싱 함수에 넘김.
이름종류0~6이고 파티션이 3개면 나머지 값을 통해 어느 파티션에 넣을지 결정함.
데이터 프레임이 충분히 크다면 수가 파티션 수가 200개. 그게 아니면 훨씬 작을 수 있음.
나머지연산에서 분모가 2가 됨. 해싱값을 2로 나눠서 나머지 값에 따라 0,1.
같은 이름을 갖는 레코드는 같은 파티션으로 들어간다.
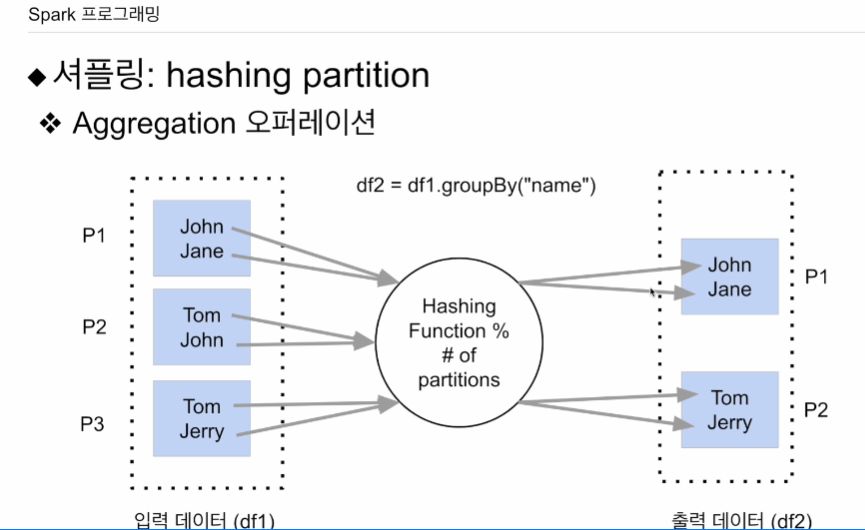
데이터 스큐
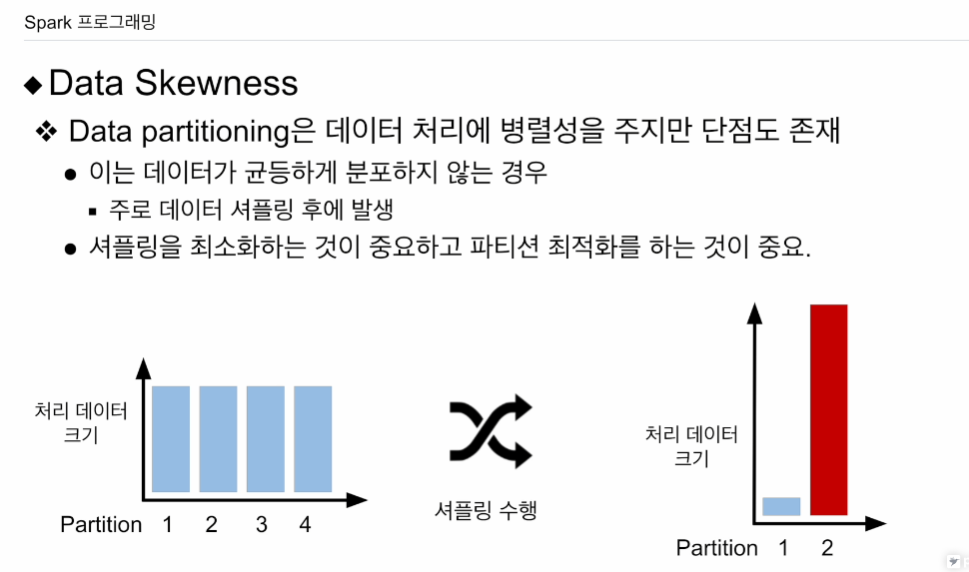
데이터 파티셔닝을 하면 셔플링 이후에 본의 아니게 특정 파티션이 커지는 일들이 생김. 데이터가 균등하게 분포하지 않음으로써. 셔플링이 끝나면 분포가 파티션의 수가 줄어들었지만, 특정 파티션이 데이터가 많음.
파티션을 새로 만들 때 파티셔닝 방식을 최적화 할 수 있느냐. 나중에 스파크 잡 최적화 때 설명.
