
이번엔 파티션에 들어가는 실제 프로그래밍 대상인 자료구조에 대해 설명
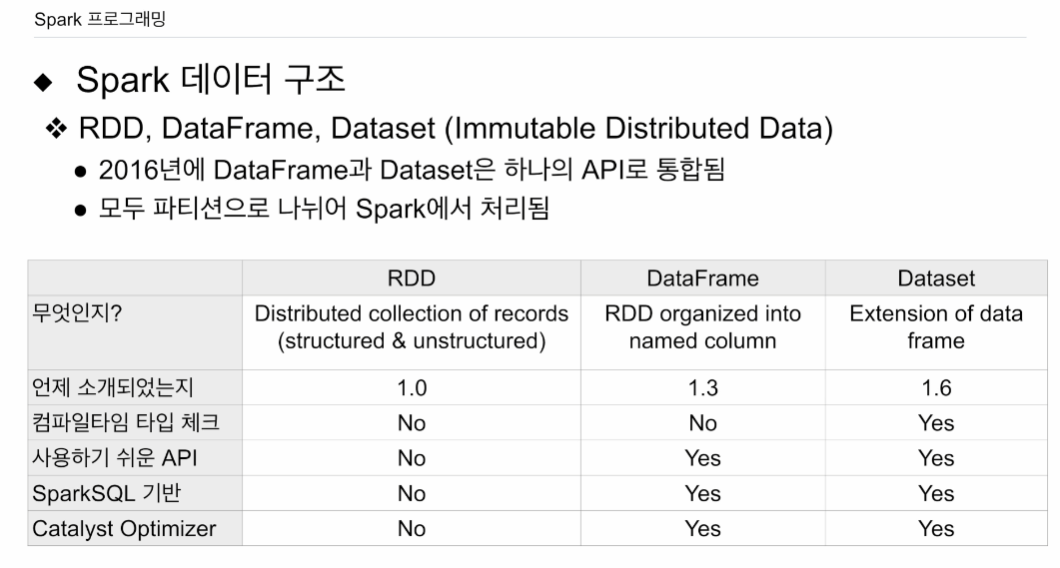
RDD, 데이터 프레임, 데이터 셋이 있음.
우리는 주로 데이터 프레임 사용.
RDD, 데이터 셋도 조금 살펴봄
공통: immutable distributed data
변경 X, 분산된
RDD가 가장 밑바닥. 로우 레벨
그 위에 데이터 셋, 데이터 프레임 올라감. 보다 하이 레벨
RDD로 할수 있는 일은 많지만 생산성이 떨어짐. 대부분의 경우 파이썬 코딩 경우 데이터프레임, 스칼라 자바의 경우 데이터 셋
구조화된 데이터를 가지고 데이터 오퍼레이션할 때 스파크 SQL이 가장 일반적임.
RDD는 가장 밑바닥 로우 레벨 데이터 구조, 구조, 비구조의 분산된 데이터 집합
데이터 프레임: 조금 더 구조화됨. 레코드에 필드들이 있음. 꼭 타입이 있지는 않음
데이터 셋: 타입이 있고, 타입 체크가 가능함.
RDD가 먼저, 그다음 데이터 프레임, 데이터 셋 순 만들어짐
지금은 데이터 프레임, 데이터 셋을 동일하다고 봄. 데이터 셋의 특수한 형태를 데이터 프레임.
우리는 데이터 프레임 쓸꺼임.
데이터 셋은 타입 정보 지정.
스파크SQL 기반. 프레임. 셋. 쿼리를 물리적 RDD 오퍼레이션으로 바꿀 때. 오퍼별 비용을 계산하여 가장 경제적인 엑시큐션을 선택함. 프레임 셋 모두 SQL 위에서 돌아감.

RDD:
로우 레벨 , 스파크 클러스터 내에 엑시큐터 내에 서버에 분산된 데이터(파티션)을 지칭. 딱히 스키마가 있지 않아도 됨. 구조, 비구조 모두 지원. RDD 위에 만들어진게 데이터 셋, 데이터 프레임 (필드정보 있음)
프레임, 셋
적어도 구조는 있음. 테이블.
셋은 타입 정보 꼭 있어야 함. 컴퍼일 언어인 스칼라, 자바에서 사용 가능
파이스파크에선 데이터 프레임만 - 인터프리터
가장 기본 RDD
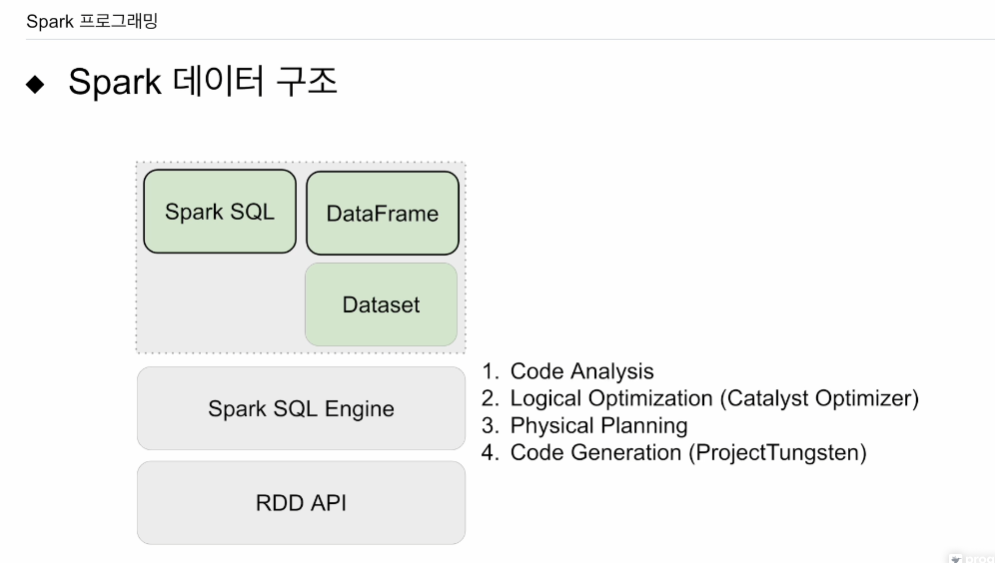
RDD 위에 스파크 엔진이 올라가서. RDD 오퍼레이션을 최적화하는데, 스파크 엔진 힘을 빌리려면 상위레벨 API를 사용(셋, 프레임). 프레임하는 일이 일반 SQL 처리가능하면 스파크 SQL 쓰면 됨. RDD를 써서 프로그래밍 하는 일은 거의 없음. 파이썬 쓰면 셋 못사용. 구조화된 데이터 SQL은 데이터 프레임도 안쓰고 스파크 SQL을 쓰게 될 것임.
이 스파크 SQL 엔진이 어떤 컴포넌트? 우리가 작성한 데이터 프레임 코드, 스파크 SQL 코드를 최적화해서 RDD 오퍼레이션으로 만들어주고 최종적으로 자바 코드로 만들어줌.
- 코드를 분석. 어떤 테이블 쓰이고, 어떤 컬럼 쓰이고(사용자가 타입으로 없는걸 쓰면 에러냄)
- 코드를 실행할 수 있는 여러 방안들은 만들어냄 (catalyst Optimizer 방안마다 비용을 계산해서 최종적으로 얼마나 비용이 필요한지 파악. 그 과정에서 스탠다드 SQL 최적화 방식을 사용함. 여러개 안을 만들어냄)
- 비용이 가장 싼걸 골라 RDD 오퍼레이션들로 실제 만듦.
- RDD 오퍼 코드를 자바 바이 코드로 바꿈. 프로젝트 텅스턴, MPV 테크닉을 써서 코드를 더 최적화 함. ? 잘 모르겠음.
자바 바이코드로 만들어 주는게 스파크 SQL
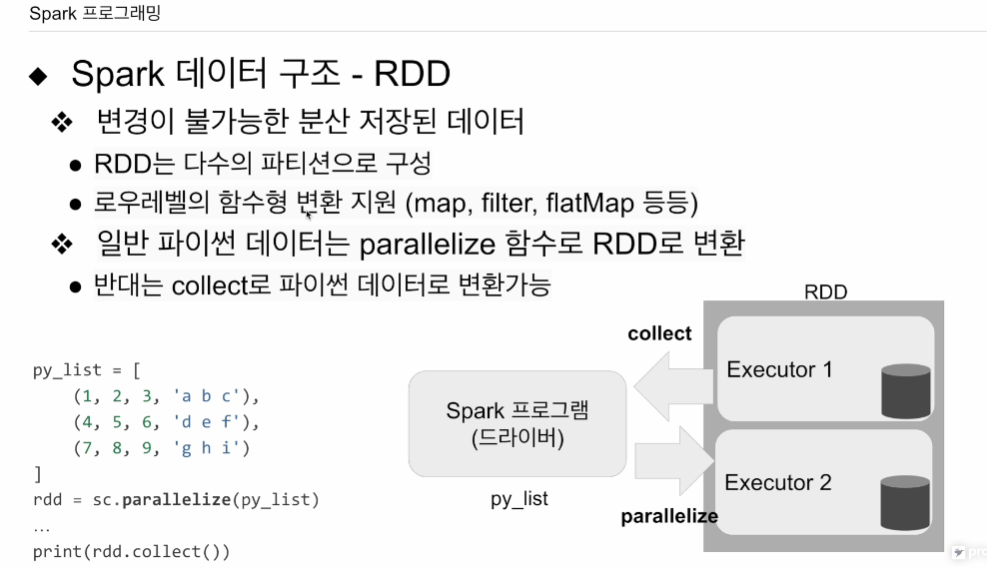
RDD 변경 불가능.
데이터 셋, 데이터 프레임에 적용. RDD 위에 적용
로우레벨로 함수형 변환 지원. 맵, 필터, 플랫맵 등
스파크 드라이버 프로그램. 파이썬 자료구조 같은걸 스파크 컨텍스트: 스파크 세션 밑에 있는 프로퍼티
SparkContext: SparkContext는 Spark 애플리케이션의 진입점으로 볼 수 있습니다. SparkContext는 클러스터에 대한 연결을 나타내며, 이를 통해 Spark 클러스터에서 RDD(Resilient Distributed Dataset) 등의 다양한 연산을 수행합니다. SparkContext는 Spark 애플리케이션당 하나만 존재할 수 있습니다.
SparkSession: Spark 2.0 이상에서는 SparkContext 대신 SparkSession을 사용하여 DataFrame 및 Dataset API를 사용합니다. SparkSession은 사용자가 SQL, DataFrame, Dataset 등을 통해 처리하려는 데이터에 쿼리를 수행할 수 있는 진입점을 제공합니다. 또한, SparkSession은 내부적으로 SparkContext를 포함하고 있으므로 RDD와 같은 low-level API도 사용할 수 있습니다.
그걸 이용해 페러렐라이즈 함수 불러주면, 인자로 주어진 리스트와 같은 자료구조를 RDD로 바꿔줌. 이런 리스트가 RDD 파티션으로 스파크 클러스터 위에 로딩이 됨. 페러렐라이즈를 쓰면 파이썬 자료구조를 스파크 클러스터 RDD에 올릴 수 있음. 올라간 RDD를 데이터 프레임으로 바꿀 수 있음. 컬럼(스키마)를 지정해줘야 함.(포맷) RDD로 계산을 다 끝내고 드라이브(파이썬 메인)으로 가져오고 싶다면 collect 함수를 사용하면 스파크 상의 자료구조가 아닌, 파이썬에서 엑세스할 수 있는 자료구조로 다운로드 됨. RDD의 크기가 굉장이 크다고 하면, collect 사용하면 메모리 부족 에러가 날 것임. 굉장히 작은 최종 데이터를 만들고, 드라이브에서 한다고 할 때 사용.

데이터 프레임 설명.
RDD처럼 변경이 불가능한 분산저장 데이터. 차이점은 테이블, 판다스 데이터 프레임처럼 컬럼이 있음. 기본은 타입정보 불필요. 개발자가 명시적으로 타입 지정 가능. 앞의 데이터 샘플링해서 타입 추측도 가능. 판다스 데이터프레임을 참고해서 만들었음. 오퍼를 보면 굉장히 흡사함. 다양한 데이터 소스들 지원. HDFS, 하이브, JDBC 결과, RDD 내용을 가져올 수 있음. (스키마 지정해줘야 함)
이번 강의에선 데이터 프레임을 사용해볼 예정.
그 뒤에 스파크 SQL을 사용해 데이터 오퍼레이션 사용 예정.

감사합니다. 이런 정보를 나눠주셔서 좋아요.