
스파크 세션이라는 오브젝트 생성이 시작.
여기에 다양한 환경설정을 하게 됨.
이 디테일에 대해 알아본다.
세션을 만드는게 시작.
스파크 클러스터와 통신하는 엔트리포인트.
한 프로그램에 하나만 생성: 싱글톤
2.0 처음 소개. 이전에는 어떤 데이터 소스와 일하냐에 따라 컨텍스트를 만들어서 작업했음. 복잡도가 있었는데, 그 모든걸 묶어서 스파크 세션 하나를 통해 다양한 기능을 사용.
다양한 데이터 소스를 하나의 엔트리 포인트로 프로그래밍 가능.
데이터 프레임, SQL 등 다 이용
config 메소드를 이용해 한번에 다 설정, build 디자인 패턴으로 한번에 하나씩 설정할 수도 있음.
RDD 작업은 세션 밑 컨텍스트 오브젝으로 RDD를 생성하고, 관계된 오퍼레이션 실행 가능.
세션 기능이 굉장히 많음. 레퍼런스 링크 참고.

from pyspark.sql import SparkSession
# SparkSession은 싱클턴
spark = SparkSession.builder\
.master("local[*]")\
.appName('PySpark Tutorial')\
.getOrCreate()
...
spark.stop()
local[*]는 Spark 애플리케이션이 실행될 마스터를 설정하는 값입니다. 이 설정은 Spark 애플리케이션이 어디에서, 어떻게 실행될지를 결정합니다.
local[*]에서 local은 Spark 애플리케이션을 현재 머신의 로컬 모드에서 실행하라는 것을 의미합니다. 즉, 클러스터 모드가 아니라 단일 머신에서 멀티 스레드로 실행되게 하라는 것입니다.
[*]는 이 로컬 모드에서 사용할 수 있는 모든 코어를 사용하라는 것을 의미합니다. 이 부분에 특정 숫자를 넣으면 해당 숫자만큼의 코어를 사용하게 됩니다. 예를 들어, local[4]는 4개의 코어를 사용하라는 것을 의미합니다.
따라서,local[*]는 현재 머신에서 모든 가능한 코어를 사용해 Spark 애플리케이션을 실행하라는 설정입니다. 이 설정은 개발이나 테스트 환경에서 주로 사용됩니다.
스파크 세션인데? 왜 sql 밑에서 임포트 했냐?
2.0이 나오면서 스파크세션이 처음으로 소개됨. 앞장에서 설명처럼 데이터 프레임, 셋, SQL 모두가 스파크 SQL 엔진 위에서 돌아가는걸로 바뀜. 그래서 pyspark.sql에서 가져옴

임포트된 스파크 세션을 이용해 객체를 생성함.
빌더 디자인 패턴을 이용해 생성
.을 붙이고 한번에 하나씩 설정
master 어떤 리소스 매니저 쓰는지, 로컬 스탠드얼론을 사용. 괄호 안엔 모든 쓰레드 사용
appName 이름
이후 하나씩 설정해 나갈 수 있음.
최종적으로 getOrCreate을 사용, 한 프로그램에 하나만 있으면 되는 싱클톤임.
만약 오브젝트가 있으면 기존에 있는걸 가져옴. 여러번 호출한다고 해서 계속 만들어지지 않는다는 의미. 스파크세션이 제공하는 API를 호출하고 가져다 씀
stop을 써서 모른 리소스들이 리턴되고 끝남
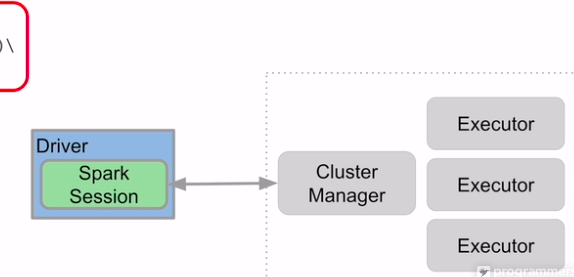
드라이버 안의 코드는 위의 파이썬 코드. 여기서 스파크 세션을 열어 클러스터 매니저와 통신, 명령을 내림

세션과 관계된 설정을 자세히 알아본다
어떤 리소스 매니저에 따라 쓸수 있는 변수, 없는게 있음. YARN을 쓰느냐 등.
엑시큐터 별 메모리. spark.executor.memory 기본 1Gb
엑시큐터 별 cpu. 얀에선 기본 1
드라이버 메모리. 1기가 기본
셔플 후에 파티션의 수가 변하는데, 그 숫자를 변경하고 싶다면, shuffle.partitions (기본값 최대 200). 무조건 파티션 200개 되는건 아님


admin 같은 사람이 이 클러스터 전반의 기본값을 세팅. 저 파일에 설정할 수도 있음.
개발자가 건드리진 않음.
커맨드라인을 써서 설정 - 나중에 설명
내 프로그램 코드 안에 스파크 세션을 만들 때 지정. builder 디자인 패턴, 또는 sparkConf라는 클래스를 만들어, 여기서 설정값을 지정하고, 스파크 세션 생성 시, 파라미터로 넘기는 방법이 있음.

무엇이 우선순위가 되는가?
제일 아래가 우선순위.
똑같은 환경변수가 설정되었다면, 만들때가 우선

빌더 디자인패턴을 사용한다면 다음과 같음
config라는 범용 메소드, 두개의 파라미터를 호출하는데 하나는 환경변수 이름이고, 두번째는 그 환경변수의 값. 내가 원하는 만큼 불러감.
세션 만들 때, 이전 환경변수 설정 방식들이 우선순위에 맞춰 현재 세션 만들 때 이미 정리가 된 상태임. 그 위에 내가 새로운 환경을 오버라이딩 함

sparkConf 오브젝트 만들어 환경 설정 해주고, 한번에 넘겨줄 수도 있음.
객체를 만들어 set이라는 메소드를 만들어, 변수 이름과 값을 지정
spark.app.name
spark.master
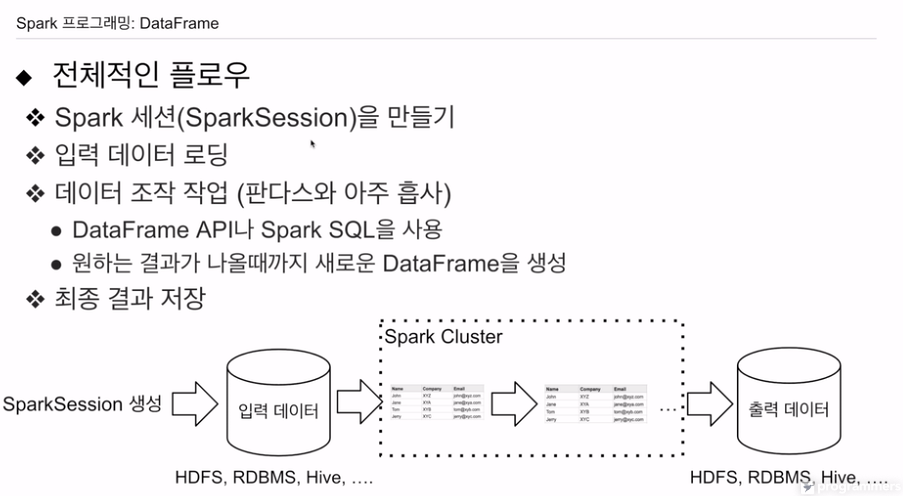
세션 만들고,
환경 설정하고
API를 이용해, 다양한 소스를 로딩
데이터 프레임, SQL로 데이터 프레임 만듦.
과정 반복
그 결과를 어딘가 저장. HDFS, 관계형 데이터베이스, 하이브의 테이블.
스파크에서 사용할 수 있는 입력, 출력 데이터 소스에 대해 알아본다

리더를 지원하는 소스라면, 로드 가능. wirter를 지원하는 소스라면 쓸 수 있음
HDFS
- csv, json, 바이너리도 있음
- 하이브. HDFS위에 파일 형태로 존재.
관계형 데이터 베이스를 읽고 쓸 수 있음. JDBC로 연결가능하면 입출력 가능함.
DW. 레드쉬프트, 빅쿼리, 스노우플레이크 지원
키네시스, 카프카 같은 스트리밍 시스템도 지원함.
