다양한 스파크 데이터프레임 실습
1번째. 워밍업 - 헤더 없는 csv -> 스파크 데이터프레임 로딩
세션 만들 때 sparkconf 사용
필터링 해보고 키로 값 구해본다.
헤더가 없는걸 확인. 스키마 만들어본다.
파이스파크를 설치해본다.
모듈 받고,
판다스 데이터 프레임, 스파크 데이터 프레임, 스파크 SQL 순으로 처리해본다.
py4j도 설치
wget으로 csv 받고
잘 들어옴
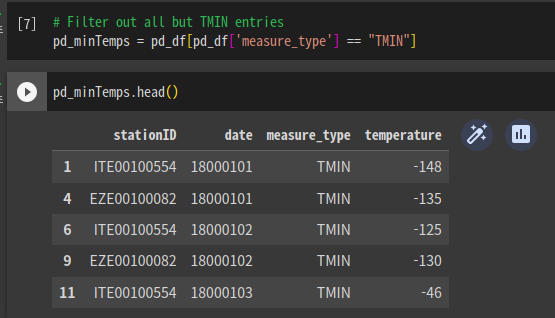
1800의 5개 값만 출력
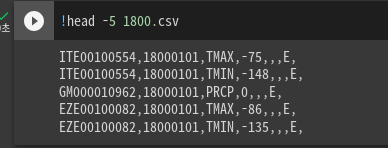
헤더가 없는 것을 확인. 8개의 컬럼이 있는데 그중 우리는 3개만 쓸 것임.
처음 4개의 컬럼만 로딩해보자 한다.
판다스 - 4개
스파크 - 8개 로딩
import pandas as pd
pd_df = pd.read_csv(
"1800.csv",
names=["stationID", "date", "measure_type", "temperature"],
usecols=[0, 1, 2 ,3]
)usecols로 처음 4개 컬럼만 쓰겠다 선언. 0부터
names로 컬럼 이름 지정.
pd_df.head()로 처음 5개 레코드 추출
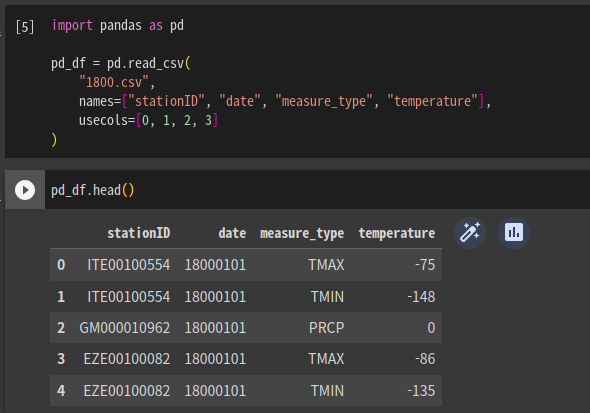
레코드를 확인할 수 있다.
measure_type이 TMIN인 값 중,
stationID별로 temp가 최소인 값을 구하고자 한다.
그걸 하기 위해 mesure_type이 TMIN인 값만 필터링
pd_minTemps = pd_df[pd_df['measure_type'] == "TMIN"]
대괄호 안에 조건을 넣으면 해당하는 값이 출력되는 것 같음.
새로운 데이터 프레임이 생성되었음.
2개 컬럼만 추출
pd_stationTemps = pd_minTemps[["stationID", "temperature"]]
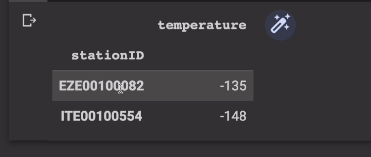
ID로 그룹묶어서 그 레코드 중 temp의 최솟값만 출력
pd_minTempsByStation = pd_stationTemps.groupby(["stationID"]).min("temperature")
pd_minTempsByStation.head()
로 상위 5개 레코드 출력
결과가 2개만 나옴.
이제 스파크로 처리해본다.
차이점은 데이터 크기의 차이. 스파크는 다수의 서버로 구성된 프레임워크. 처리 데이터가 훨씬 큼. 판다스는 한대의 서버에서 돌아가는 모듈. 처리 데이터 크기가 작음. 작은경우 훨씬 효율적이긴 함.
스파크는 그 이외에도 기능이 많음.
conf로 환경설정할 것임
얘도 별도로 오브젝트 만들고, 환결설정 이름, 값을 집어넣음.
from pyspark.sql import SparkSession
from pyspark import SparkConf
conf = SparkConf()
conf.set("spark.app.name", "Pyspark DataFrame #1")
conf.set("spark.master", "local[*]")
spark = SparkSession.builder\
.config(conf=conf)
.getOrCreate()conf에 이름, master를 설정하였다. 로컬로 엑시큐터에 모든 쓰레드를 할당함
config 메소드 안에 conf 파라미터에 conf 인스턴스 할당함
df = spark.read.format("csv").load("1800.csv")
데이터프레임을 로딩할 것임. 여러 방법이 있겠지만 짧은 방법, 긴 방법이 있음.
로컬파일을 읽기 때문에 1800.csv로 바로 주면됨.
정석은 format으로 형태를 입력, load하고 파일주소 입력.
또는
df = spark.read.csv("1800.csv")
이게 더 쉬워보임.
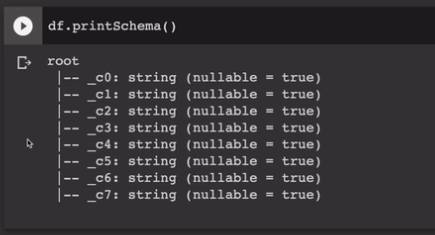
이 파일은 헤더가 없음. 그럼 데이터프레임은 스키마를 어떻게 이해할까?
df.printSchema()
임의로 컬럼이름을 만들고 타입도 임의로 지정함.
이에 필드 이름부터 지정. 간단한 방법부터 알아본다,
동일한 방법으로 마지막에 toDP함수를 호출해서, 컬럼이름을 8개를 지정함.
`df = spark.read.format("csv")\
.load("1800.csv")
.toDF("stationID","date","measure_type","temperature",...)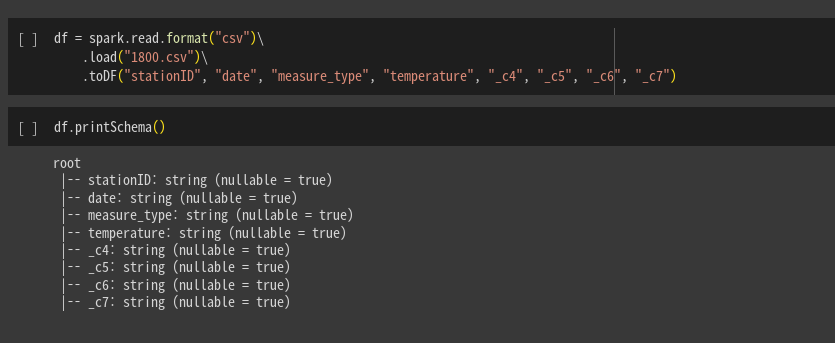
스키마 출력해보면 컬럼 이름이 지정되었다. 그러나 여전히 타입은 맞지 않음. 그냥 다 스트링으로 때려넣어짐.
이걸 조금 더 바꿔서 .option을 걸어줌. inferShcema, 그값을 True로 함.
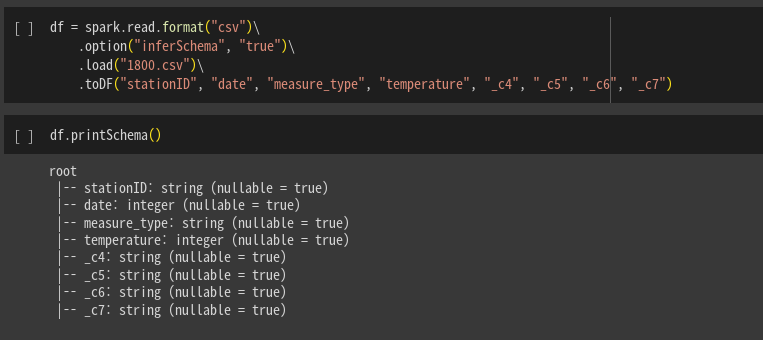
몇개 integer로 타입 변환이 이뤄짐.
type을 임포트해서 반영해본다
from pyspark.sql.types import StringType, IntegerType, FloatType
from pyspark.sql.types import StructType, StructField
schema = StructType([ \
StructField("stationID", StirngType(), True), \
StructField("date", IntegerType(), True), \
SturctFielf("measure_type", StringType(), True),\
StructField("temperture", FloatType(), True)])이번엔 명시적으로 지정해서 스파크에게 알려줌. 먼저 스트럭트타입으로 시작, 이 안에 스트럭트 필드들을 반복해줘서 스키마를 정해줌. 스트럭트필드는 3개 인자, 첫번째 이름, 타입, True면 널값이 가능함. 순서대로 stationID Integer True이렇게 들어가게 된것이다.
이러한 타입 외에 굉장히 많은 타입들이 있음. 뒤에 별도의 슬라이드로 정리해본다.
다시 스파크 데이터프레임을 로딩하는데, 스키마 메소드를 부르면서, 스키마 인스턴스를 넘겨줌. 명확하게 지정해줌.
이렇게하면 별도로 이름, 추측 안시켜도 됨.
df= spark.read.schema(schema).csv("1800.csv")
df.printSchema()

measure type 추출 3가지 방법
데이터프레임의 filter 메소드 사용. -> 데이터 프레임 생성.
minTemps = df.filter(df.measure_type == "THIN")
minTemps.count()
그다음으로 where라는 메소드 사용. 2가지 방법으로 조건 지정 가능. filter와 동일한 형태로 지정. boolean 형태로 지정.
minTemps = df.where(df.measure_type == "THIN")
또는 시퀄 익스텐션. 문자열을 지정. WHERE조건 지정하듯이 = 사용.
minTemps = df.where("measure_type = 'THIN'")
레코드 수는 동일함
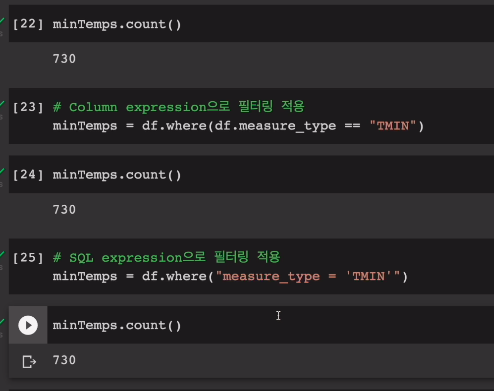
중요 포인트는 이러한 컬럼 이름을 지칭하는 방법이 여러가지가 있다는 것임. col함수로 지정할 수도 있음.
최종적으로 우리가 원하는건 그룹바이를 stationID에 지정. temp의 최솟값만 추출하고 이를 보여주는 것임.
minTempsByStation = minTemps.groupby("stationID").min("temperature")
minTempsByStation.show()
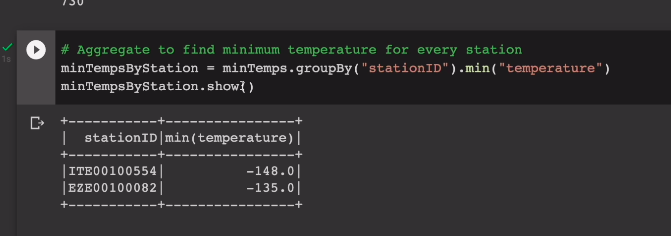
잘 뜨는 것을 확인.
show 메소드는 최대 20개까지 보여줌. 결과가 2개밖에 없음.
특정 컬럼 추출
데이터 프레임의 방법과 동일
stationTemps = minTemps[["stationID", "temperature"]]
원하는 리스트를 인덱스 형태로 지정.
레코드 개를 .show(5)로 볼 수 있다.
또 select를 사용 가능
stationTemps = minTemps.select("stationID", "temperature")
마찬가지로 동일하게 나오는 걸 확인.
minTempsByStation.collect()을 불러가지고 파이썬으로 받아와 본다.
results = minTempsByStation.collect()이건 리스트임.
이를 루프를 돌면서 프린트해본다.
근데 스키마를 포함되지 않은듯 하다.
for result in results:
print(result[0] + "\t{:.2f}F".format(result[1]))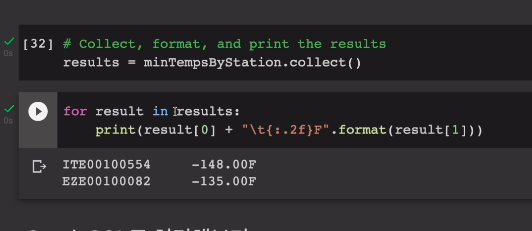
result는 사실 Row type임. 이것도 나중에 다뤄봄.
Spark SQL 처리
input 데이터를 임의의 테이블로 생성.
df.createOrReplaceTempView("station1800")
그전의 작업들을 SQL로 만들어본다.
results = spark.sql("""SELECT stationID, MIN(temperature)
FROM station1800
WHERE measure_type= 'THIN'
GROUP BY 1""").collect()이 sql 문을 spark.sql에 넣으면 데이터 프레임이 만들어짐.
이를 파이썬 드라이버 쪽으로 받아옴.
이를 하니씩 찍어보면,
for r in results:
print(r)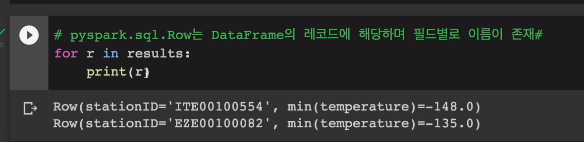
파싱 안하고 그대로 찍어봤다. Row 타입으로 표시되고 두개의 엘리멘트가 있고, 컬럼 이름이 각각 나와있다. 그리고 뒤에 값도 있음. 따로 이름을 지정하지 않아 그대로 나온 것을 확인함.
데이터프레임. 컬럼별로 명확한타입 없어도 처리 됨.
데이터 셋. 명확해야함.
타입들

인티저, 플로트, 스트링, 불린, 타임스탬프, 데이트, 리스트, 스트럭트타입(레코드 정의. 스트럭트필드의 집합), 스트럭트필드(컬럼), 딕셔너리같은 맵타입

필터 메소드 쓸 때 col, column있는데 똑같음.
select를 쓸때,
스트링,
col,
column,
데이터프레임.컬럼이름
모두 동일표현임.
