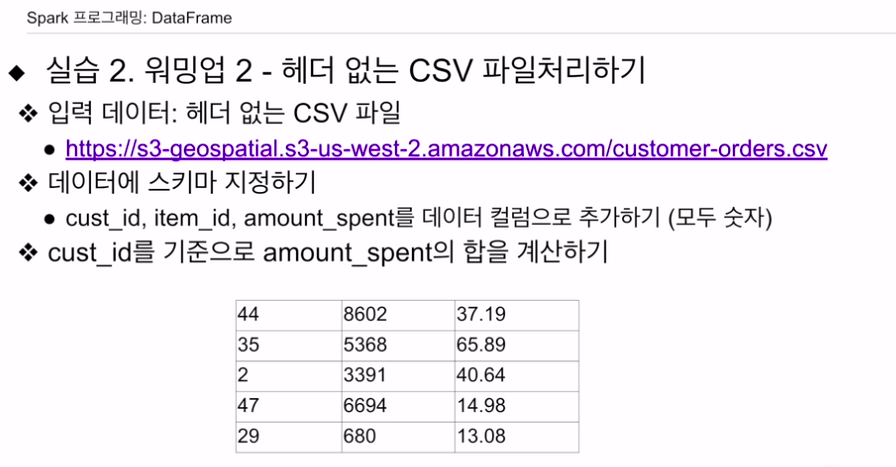
첫번째 실습의 반복.
입력의 csv 파일이 있음. 헤더 없음. 앞에서 배웠던 스키마를 적용해볼 것.
pyspark, py4j 설치.
spark 세션 생성
wget 다운
from python.sql import SparkSession
spark = SparkSession.builder\
.master("local[*]")\
.appName('PySpark DataFrame #2')\
.getOrCreate()마찬가지고 스트럭트타입을 사용하여 스트럭트필드를 채워넣음
schema = StructType([\
StructField("cust_id", StringType(), True), \
StructField("item_id", StringType(), True), \
StructField("amount_spent", FloatType(), True)])df = spark.read.schema(schema).csv("customer-orders.csv")
df.printSchema()
head -5 ~~~.csv의 결과를 통해 현재 컬럼이 3개인 것을 확인. 이에 스트럭트필드를 3개를 부여함.
True는 널값 허용.
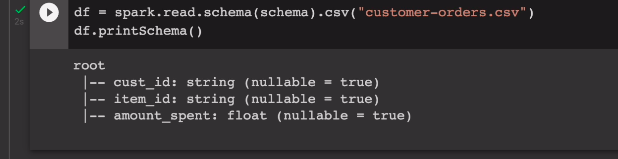
우리는 id별로 amount_spent의 총합을 구할 예정임.
df_ca = df.groupby("cust_id").sum("amount_spent")
df_ca.show()
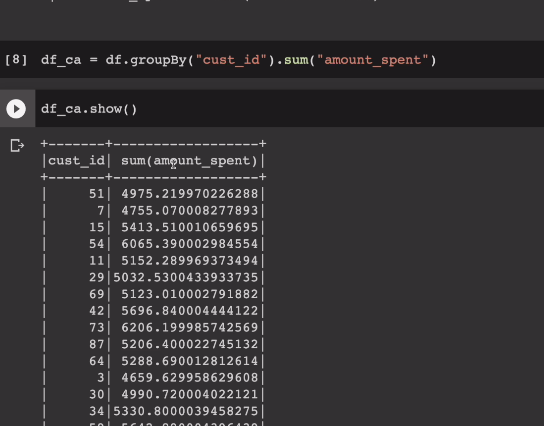
필드의 이름이 좀 거슬려보인다. 이걸 다른 이름의 필드로 rename, alias 앨리아스를 준다.
여러 방법이 있음.
2가지 설명.
.withColumnRenamed("sum(amount_spent)", "sum")으로 개명함.
또 다른 방법으로는 .alias함수를 사용.
위에선 그룹바이 하고, sum 했으나, agg 함수 안에. sum이라는 함수를 불러내는 형태로 간다. 보통 집계함수를 하나만 부르진 않기 때문. 전처러 빌드업패턴으로 갈수도 있지만, 이러면 가독성이 떨어짐
df_ca = df.groupBy("cust_id") \
.agg(f.sum('amount_spent').alias('sum'))agg 안에 functions를 f로 하여 호출함. 안에 필드이름 주고. 이 결과의 필드이름을 sum으로 개명. 다른 agg함수를 붙여나갈 수 있음. sum 말고 max, avg값도 구해볼 예정.
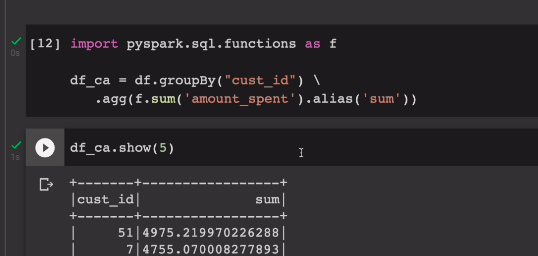
sum, max, avg값도 붙여본다.
df.groupBy("cust_id")\
.agg(
f.sum('amount_spent').alias('sum'),
f.max('amount_spent').alias('max'),
f.avg('amount_spent').alias('avg')).collect()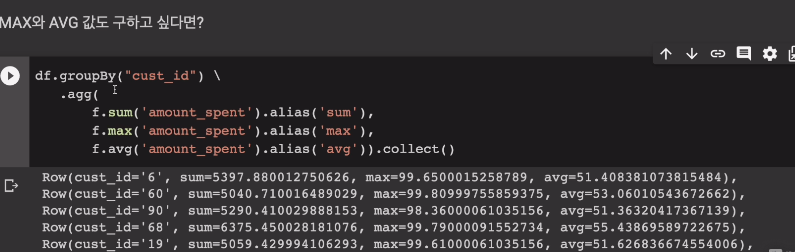
결과들이 파이썬 드라이버로 Row 타입으로 출력
나중에 UDF 써볼 예정.
스파크 SQL
더 간단해짐
df.createOrReplaceTempView("customer_orders")
spark.sql("""SELECT cust_id, SUM(amount_spent) sum, MAX(amount_spent) max, AVG(amount_spent) avg
FROM customer_orders
GROUBY BY 1""".head(5)그룹핑 하고, sum, max, avg 값
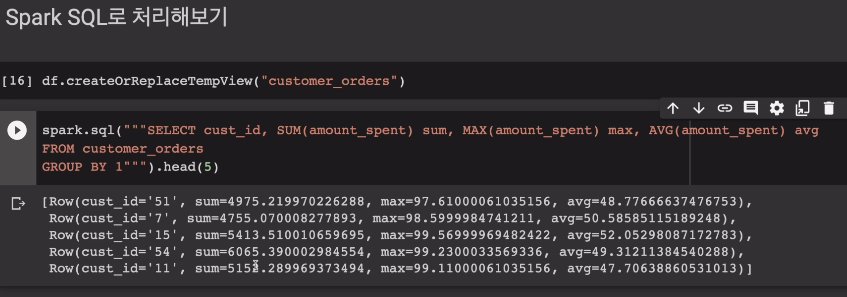
구조화된 데이터는 스파크 sql쓰는게 훨씬 간단함.
메모리에 테이블을 만든 형태임.
인메모리 카탈로그를 써서, 다양한 테이블들을 관리함.
테이블들을 보려면,
spark.catalog.listTables()
실행시켜봄

만일 내가 이런 테이블들을 영속적으로 저장하고 싶다면
하이브 메타스토어
스파크세션 설정할때 설정해주면 됨.
internal external table 등.
스파크 SQL에서 추가로 다룰 예정.
