
스택오버플로우 서베이 기반
개발자들이 가장 많이 알고 있는 언어,
1년에 한번씩 설문을 통해 수집함.
그 파일을 공개를 하고 있음.
그 파일을 바탕으로 어떤 언어가 가장 많이 사용되는지?
csv - 용량이 좀 됨.
필드는 2개.
사용해본언어, 배우고 싶은 언어
필드가 어래이 형태로 다수의 기술들이 나열되어 있음.
해보고싶은건, 이 딜리미터로 나눠진 리스트를
각각 리스트로 확장시킴.
필드의 경우 하나의 레코드를 각각이 하나의 레코드가 되게 만들어본다.
스파크에서 구현해보고자 한다.
pyspark, py4j
세션도 간단하게 마스터 주고, 애플리케이션 이름 주는 정도로 세팅.
개발자 설문 csv를 wget으로 받는디
ls -tl로 목록 확인
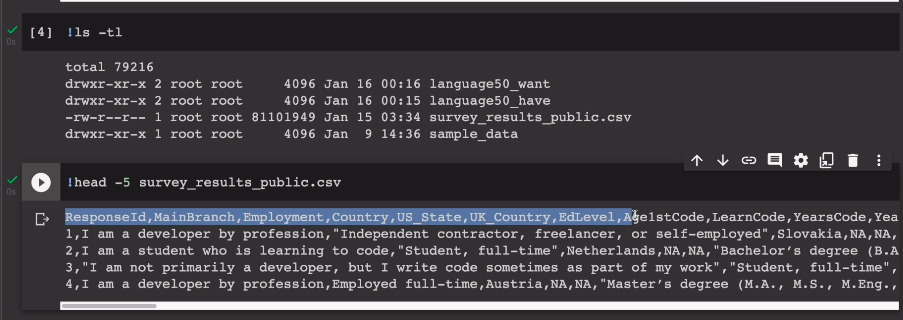
헤더가 있음
head -5 ~~.csv
굉장히 컬럼이 많음.
다 로딩하지 않고,
csv파일을 헤더 True로 로딩을 하고, 관심있는 컬럼만 가져와서 데이터 프레임을 만든다.
df = spark.read.csv("survey_result_public.csv", header=Ture).select('ResponseId, 'LanguageHaveWorkerWith', LanguageWantToWorkWith')
처음부터 데이터 프레임을 불러올 떄 select로 원하는 컬럼만 가져올 수 있음.
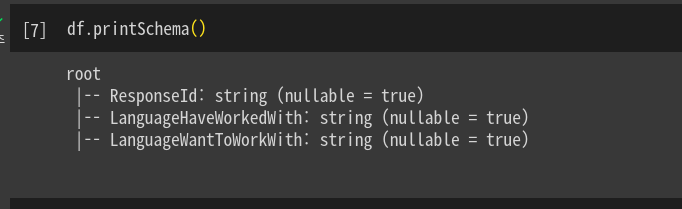
.printSchema로 보면 이렇게 목록이 뜨는 것을 확인함.
# 값을 트림하고 ;를 가지고 나눠서 리스트 형태로 language_have 필드로 설정
df2 = df.withColumn(
"language_have",
F.split(F.trim(F.col("LanguageHaveWorkedWith")), ";")컬럼단위 연산이 가능한 것을 알수 있다. col로 가져와서 앞과 뒤의 공백 제거, ;단위로 나눈걸 리스트로 저장.
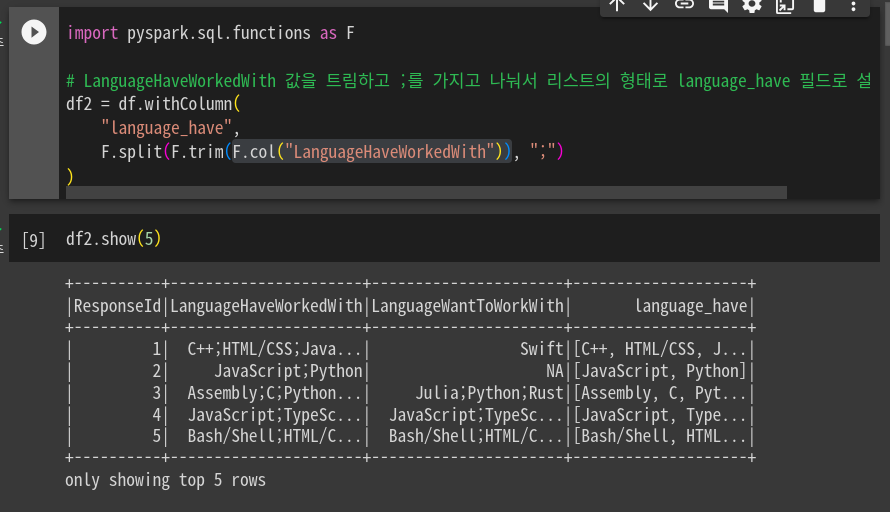
infer스키마. 추측 안해서 다 스트링으로 타입 잡힘.
.withColumn
.col
.trim
.split
지금 데이터 프레임을 랭귀지해브 컬럼 만들고, 함수의 실행결과를 넣음.
함수를 보면 복잡하게 보이지만 F.col은 그냥 이 df의 컬럼을 가리킴. 그 내용을 trim 한다. 앞이나 뒤에 빈공간 있으면 없애고, 최종적으로 split으로 ;단위로 나눈 리스트.
리스트, 어레이가 되었다.
import pyspark.sql.function as F
데이터 프레임의 레코드 5개를 보기위해
df.show(5)
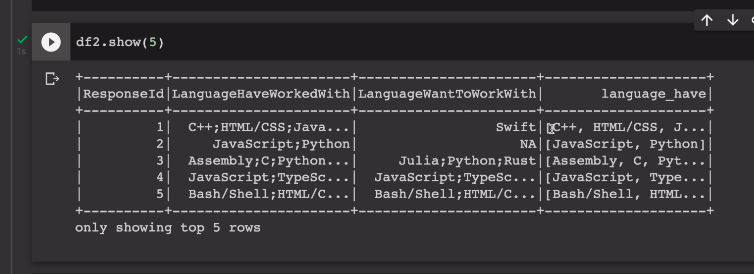
필드 내용을 보면 리스트로 들어가 있다.
이 df2에다 동일한 작업을 해본다.
그러면서 df3로 만들었음. 적층식임.
마찬가지로 F.col을 F.trim해주고, F.split, ;로 리스트화
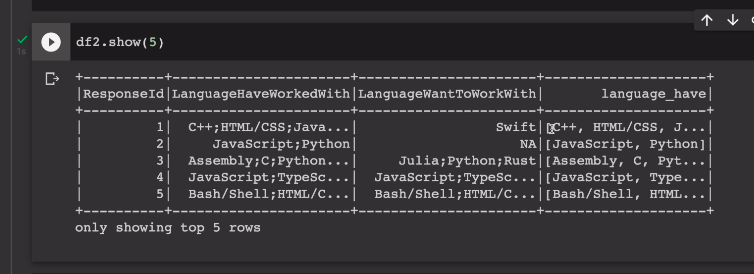
둘다 보면
array타입으로 들어간걸 볼수 있음
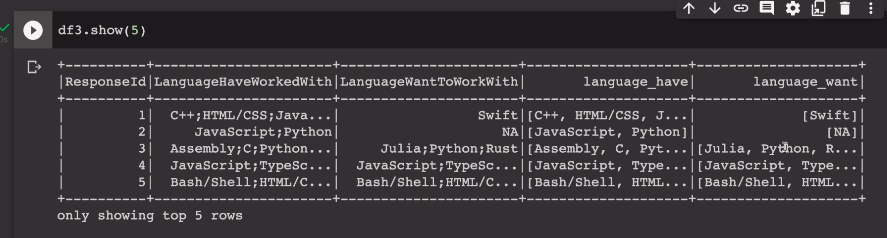
보면 오른쪽에 리스트가 들어가 있다.
특이하게도 이미 원하는, 더 잘알고싶은건지 중복값이 보임.
일단 여기까지면 준비가 끝남.
이거를 가지고 가장 많이 현재 사용되는 언어. 개발자가 가장 배우고싶은 언어 50개씩 찾아본다.
이를 위해
가장 많이 사용되는 언어를 찾아본다.
그 방법은
df3에서 두개의 필드만 셀렉트, 다른하나는
df_language_have = df3.select(
df3.ResponseId,
F.explode(df3.language_have).alias("language_have")explode는 Id가 2번을 예로, 자바스크립, 파이썬 원소로 구성된 배열임. 이를 explode하면 두개의 레코드가 만들어짐. 하나는 자바스크립트, 하나는 파이썬이 됨. 리스트 데이터를, 개별원소들을 레코드로 만들어냄. 이를 language_have로 명명
이렇게 되면 Id 2번은 2개의 레코드로 확장됨.
한번 10개정도 show 확인
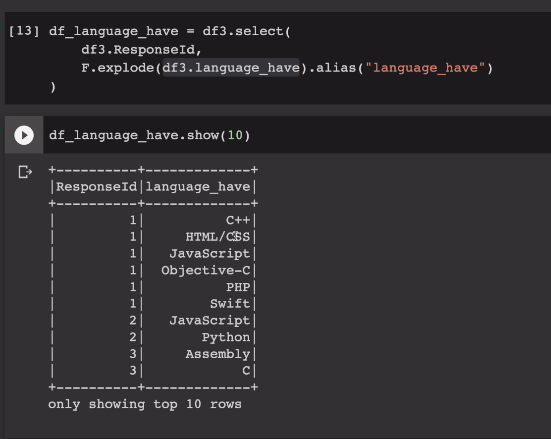
오른쪽 리스트가 개별 원소 레코드가 됨.
이를 그룹바이해서 count하면, 그리고 내림차순으로 sorting하면 가장 많이 쓰이는 언어 확인.
df_language_have.groupby("language_have").count().show(10)
sorting은 아직 안함.
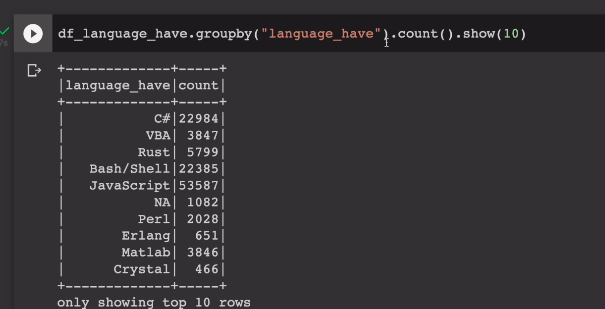
count값을 기준으로 sorting하는걸 알아본다
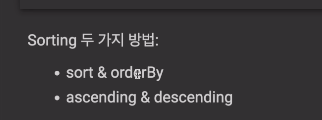
sort, orderby 메소드 사용
오름차순, 내림차순 결정
.sort(F.desc("count")).collect()
sort의 인자로 F.desc를 주면서 count필드를 기준으로 함.
이렇게 하면 큰거부터 나오는 데이터프레임이 나옴.
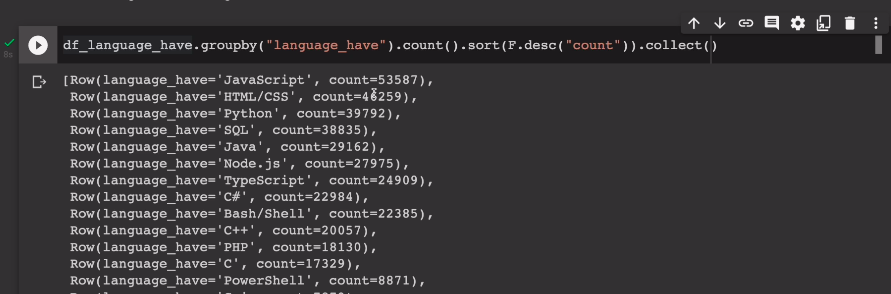
자바스크립트가 가장 많이 쓰임.
이번엔 orderby
.orderBy('count', ascending=False).collect()
나는 저게 더 익숙함.
최종적으로 명령들을 가져다 쓰고,
마지막에 .limit(50)
df_language50_have = df_language_have.groupby('language_have')\
.count()\
.orderBy('count', ascending=False)\
.limit(50)이 결과를 HDFS에 저장해본다
mode를 써서 overwrite 덮어쓰기. 폴더가 존재하고 있으면 덮어써라.
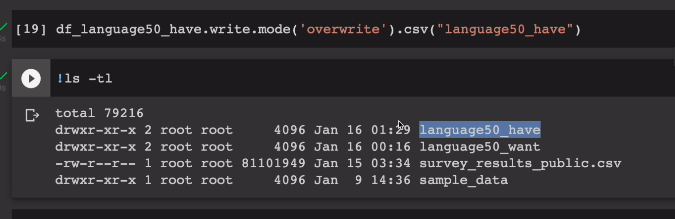
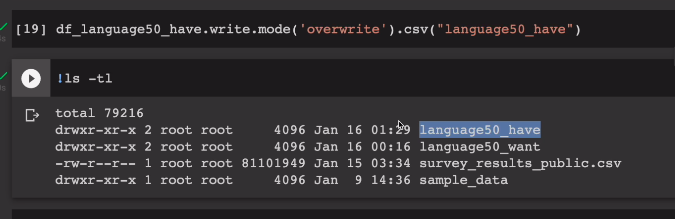
part로 시작하는 파일 확인.
이 내용을 cat으로 보면
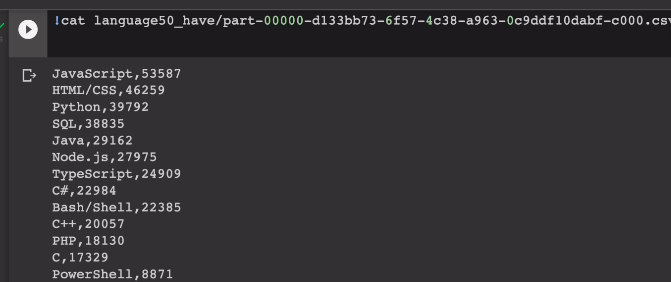
이를 SQL로 계산하기엔 약간 복잡함.
가장 배우고 싶은 언어들 찾기. - 반복임
F.explode(df3.language_want).alias("language_want")
df_language_want = df_language_wnat.groupby("language_want").count().orderBy('count', ascending=False)
.write.mode('overwrite').csv('language_want')
head, cat으로 확인하면, 알수 있음.
