
레드쉬프트에 연결해보기.
두개의 테이블을 로딩.
join해서 mau라는 지표를 계산
실제로 서비스 사용하는 사용자수
DISTINCT한 유저의 수를 카운트.
데이터 프레임으로 한번, SQL로 한번
데이터프레임에서의 JOIN은 판다스와 유사함.
left_DF.join(right_DF, join condition, join type)
join type: inner, left, right, outer, semi, anti
왼쪽 데이터 프레임으로 시작해 join 불러서 오른쪽 데이터 프레임 부르고, 조건은 어떤 필드가 같은경우, 조인 타입은 위의 6가지중 하나.
자세한 차이점은 SQL에 배울때 설명.
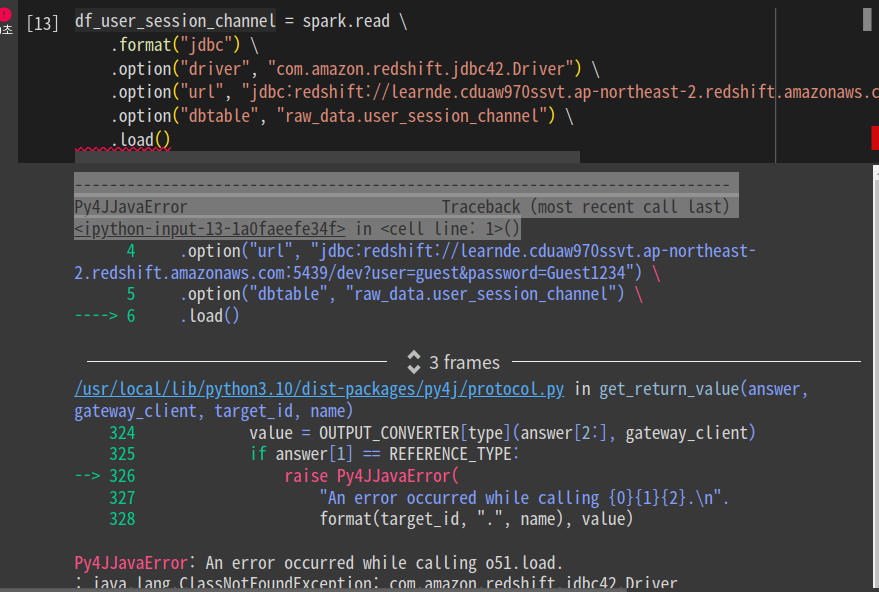
레드쉬프트에서 스파크로 2개 테이블을 로딩. JDBC를 연결
마지막 실습
pyspark, py4j를 설치.
JDBC로 연결해봄.
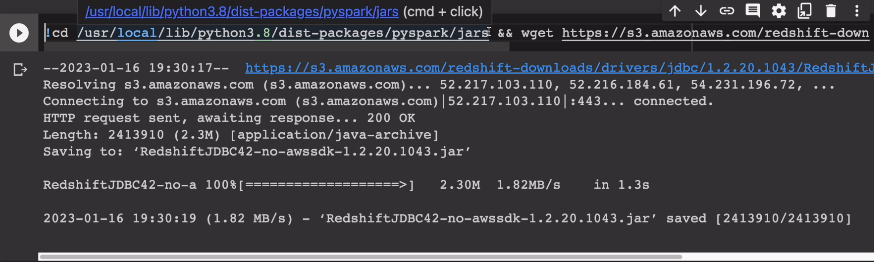
JDBC 레드쉬프트 드라이버를 받아야 한다.
!cd /usr/local/lib/python3.8/dist-packages/pyspark/jars && wget https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/1.2.20.1043/RedshiftJDBC42-no-awssdk-1.2.20.1043.jar
현재 구글 콜랩을 고려하여 저 위치에 JDBC를 설치할껀데 구글 콜랩이 업그레이드 되면 보통 파이썬 버전이 바뀜. 거기에 wget으로 아마존으로부터 받음
전처럼
스파크세션 오브젝트 1개 생성.
간단하게 이름만
그다음 레드쉬프트를 연결
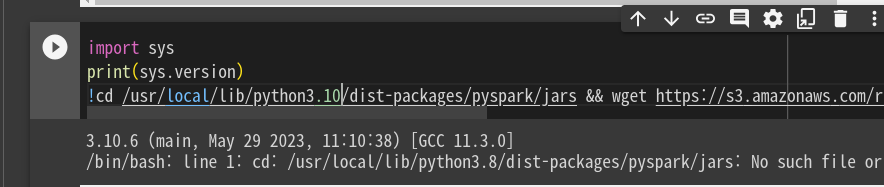
현재 8월 1일 기준으로 버전이 3.10으로 업데이트 되었음 이에 폴더 위치를 3.10으로 바꿔줘야함.
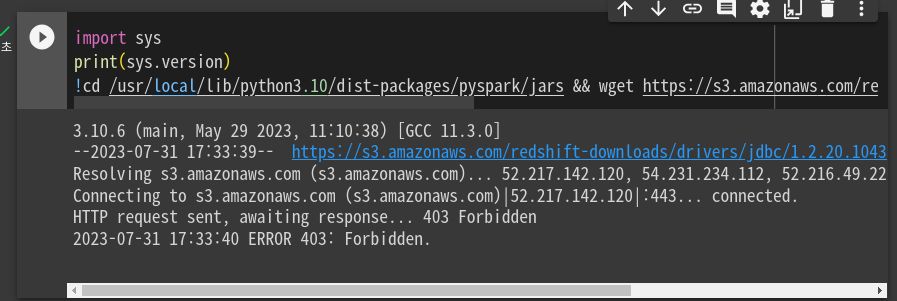
3.10으로 하니 연결되었다고 한다.
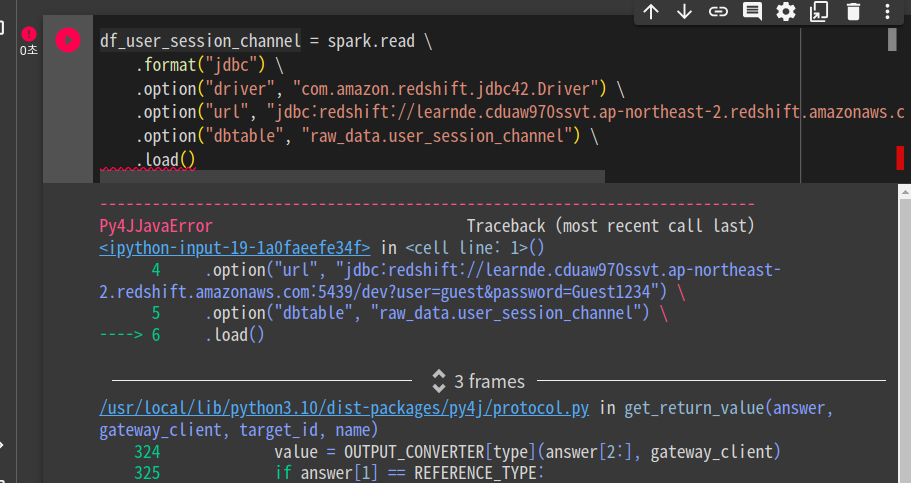
여전히 에러를 냄.
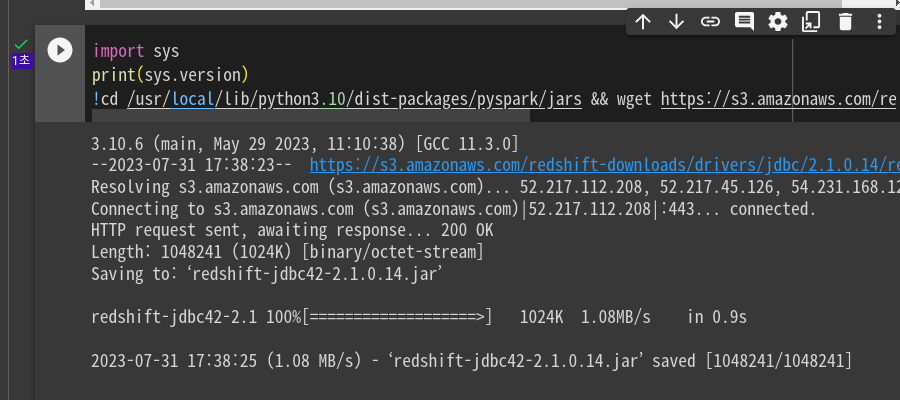
슬랙에서 다른분 해결 참고함. jdbc 버전도 바꿈
여전히 에러가 남. 이전에 설치한 JDBC와의 충돌 예상되어, 구글 콜랩의 연결을 모두 해제하고 다시 설치해봄.
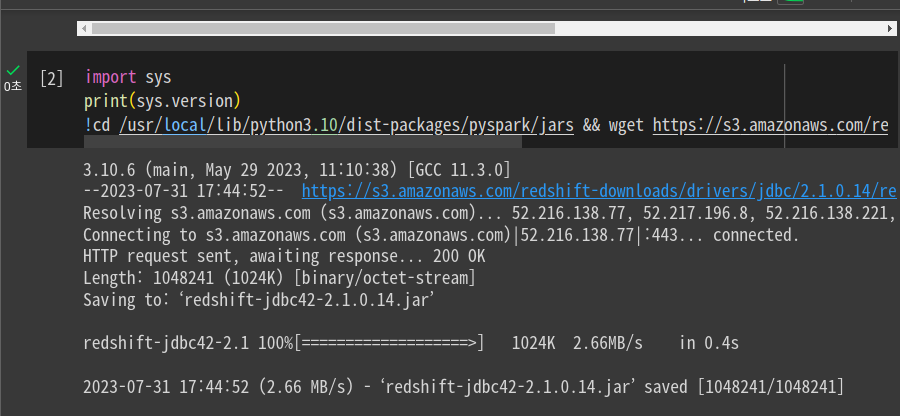
성공함. 전에 설치한 JDBC로 인해 설치가 잘 안되었음. (중복파일로 2로 생성됨)
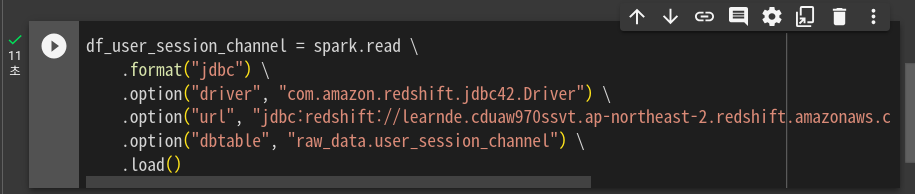
잘 됨.
user_session_channel을 다운로드 받음
두번째. session_timestamp를 받음
raw_data 스키마 밑에 있는 테이블들을 받음.
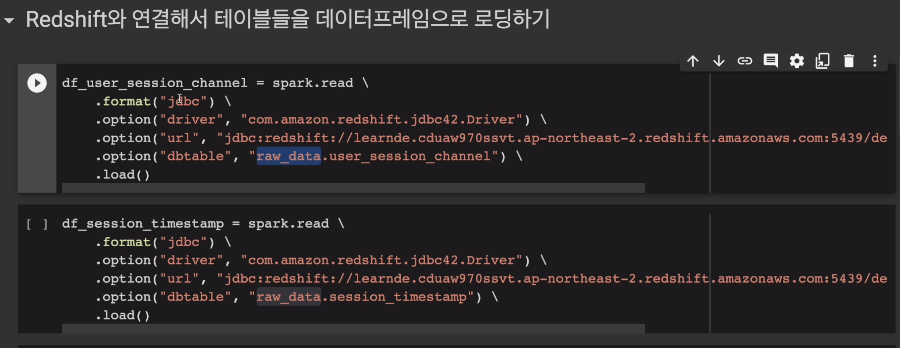
포맷을 jdbc로 줌.
옵션을 여러번 불러서, jdbc와 관계된 세팅을 함.
드라이버가 뭐냐 --> 레드쉬프트 드라이버
앞에
여기서 이 폴더에서 찾게되어 있음.
스파크 서밋으로 잡을 실행시킬 때 jar를 넘겨줌.
나중에 클라우드 옵션 때 설명. 지금은 한대짜리 서버라 바로 그냥 카피함.
url. 레드쉬프트가 어디에 있는지, 어떻게 엑세스할 것인지. 실제 클러스터 주소, 포트넘버 지정. 디폴트 데이터베이스, 유저아이디, 패스워드도 모두 지정함.
최종적으로 dbtable을 통해, 어떤 테이블을 받아서 업로드할지 지정함.
두번째 테이블로 똑같은 형태로 진행이 됨. 두개의 데이터프레임의 스키마를 본다.
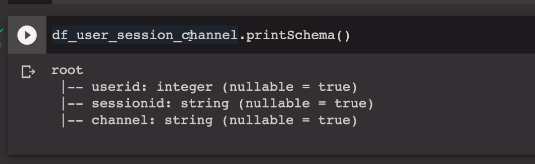
3개의 필드가 있는걸 확인.
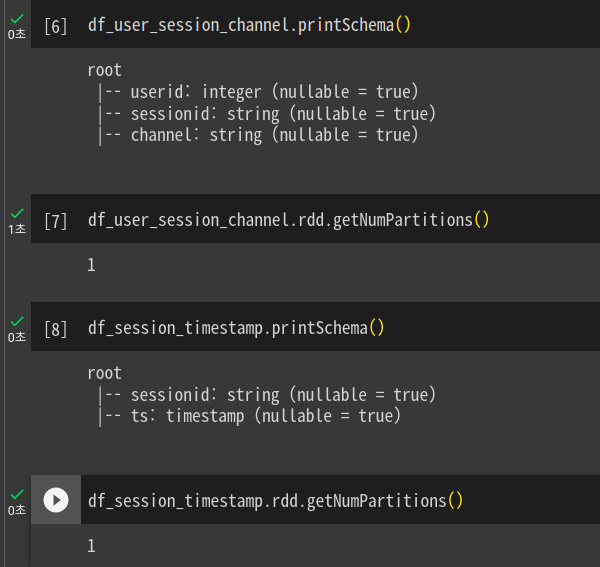
각기 파티션은 1개를 갖고있음. 데이터가 크지 않음.
데이터프레임 join
조인 컨디션에 대해 알아본다. sessionid의 공통 필드를 갖고 조인.
조인 익스프레션, 또는 조인 컨디션은
join_expr = df_user_session_channel.sessionid == df.session_timestamp.sessionid
session_df = df_user_session_channel.join(df_session_timestamp, join_expr, "inner")
이런식으로 조인을 한다. 신기했다.
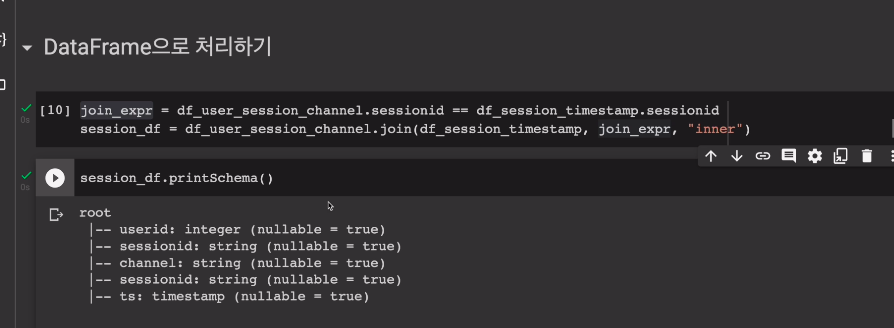
두개의 테이블의 컬럼들이 들어옴.
그러다보니 세션ID가 2개 들어옴.
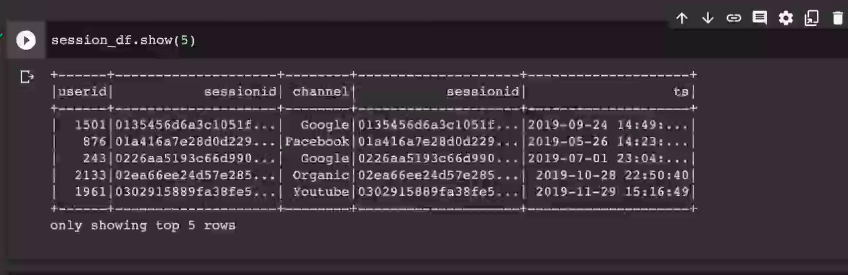
세션id가 두번 나옴. 이러면 select 때 문제가 됨.

에러가 남
뭘 선택해야할지 모르기에.
이에 데이터 프레임 이름을 써서 이름의 레졸루션을 명확히. df_user_session_channel.sessionid, 이렇게.

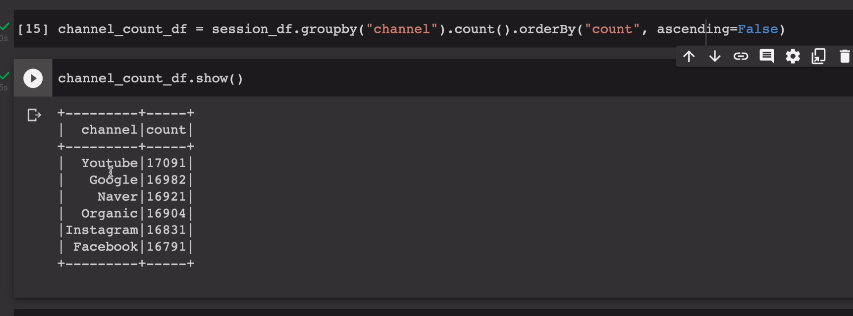
마찬가지로 채널의 숫자를 내림차순으로 세본다
channel_count_df = session_df.groupby("channel").count().orderBy("count", ascending=False)
mau를 데이터프레임에서 계산. 연도월을 중심으로 그룹바이. 현재는 타임스탬프라 이를 변환시켜야함. 변환? withColumn. month이름으로, date_format함수를 사용해서 ts를 7자리 형태의 잘짜로. 그리고 month로 묶어서, agg함수를 써서, 월별 유저를 distinct하게 세줌. 앨리어스로 이름을 mau로 변경. 그다음 sort를 하는데 month필드를 기준으로 오름차순. orderby를 써도 상관 없을 듯 함.
session_df.withColumn('month', date_format('ts', 'yyyy-MM')).groupby('month').\
agg(countDistinct("userid").alias("mau")).sort(asc('month')).show()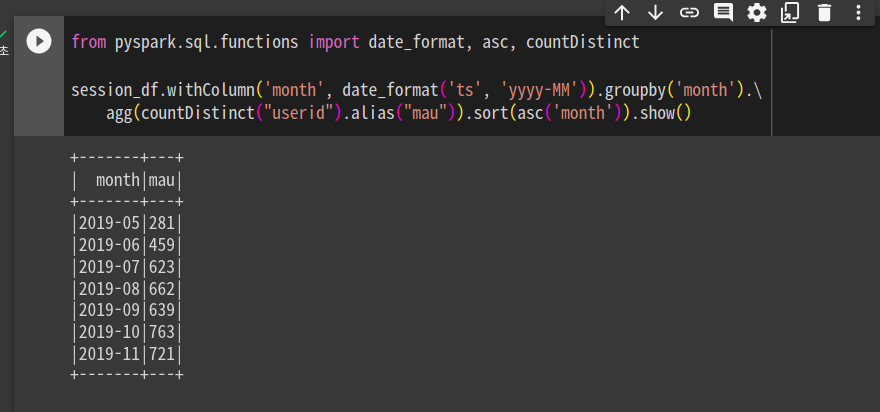
지금까지 데이터 프레임을 통해 문제를 풀었고, 이제 스파크 SQL로 풀어본다.
우선 테이블을 2개 생성한다.
df_user_session_channel.createOrReplaceTempView("user_session_channel")
이하 동문.
SQL문으로 작성한다.
channel_count_df = spark.sql("""
SELECT channel, count(distinct userId) uniqueUsers
FROM session_timestamp st
JOIN user_session_channel usc ON st.sessionID = usc.sessionID
GROUP BY 1
ORDER BY 1같은 채널을 갖는 레코드들을 카운트 하는데, distinct한 유저를 카운트함. 서로다른 유저의 수를 구함.
결국 앞에서 만들어봤던 데이터 프레임과, 동일한 데이터 프레임이 생성이 됨.
스파크 클러스터에 있는거기에 별다른 정보 안뜸. 드라이버로 가져와야함.
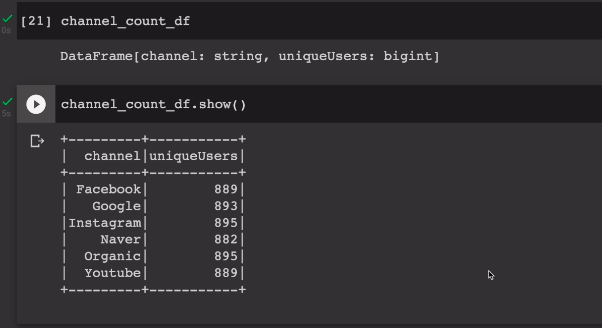
차이점은, 앞에서는 count 중심으로 소팅, 여기선 채널을 중심으로 소팅. 레코드들의 값은 동일함.
우리가 원래 풀고싶었떤 mau 를 풀어본다.
mau_df = spark.sql("""
SELECT
LEFT(A.ts, 7) AS month,
COUNT(DISTINCT B.userid) AS mau
FROM session_timestamp A
JOIN user_session_channel B ON A.sessionid = B.sessionid
GROUP BY 1
ORDER BY 1 DESC""")출력은 collect()
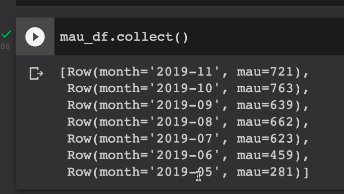
전반적으로 스파크 SQL이 간편한 것을 알 수 있으나, 몇몇의 경우 데이터프레임에서의 처리가 간편한 경우가 있었다.
