https://colab.research.google.com/drive/1TH8oQCynggPCvHN0ltYhlAbk-Kn-e7Zq
https://github.com/naver/d2codingfont
폰트 바꿔보려고 한다
설치함.
이쁨.
Spark Session 생성
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark UDF")\
.getOrCreate()
데이터프레임에 UDF 적용.
파이썬에서 만들어서 데이터 프레임쪽으로 출력.
columns = ["Seqno", "Name"]
data = [("1", "john jones"),
("2", "tracey smith",
("3", "amy sanders")]
df = spark.createDataFrame(data=data, schema=columns)
df.show(truncate=False)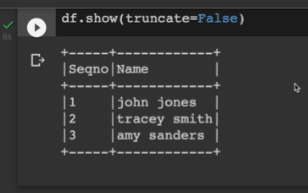
그다음으로 upperUDF 함수를 만들어 이를 갖고 새로운 컬럼 curated name으로 만들어본다.
람다함수로 대문자로 만들어주고 이를 udf 등록해준다.
인스턴스를 withColumn에 넘겨줌.
import pyspark.sql.functions as F
from pyspark.sql.types import *
uppderUDF = F.udf(lambda z:z.upper())
df.withColumn("Curated Name", upperUDF("Name")) \
.show(truncate=False)
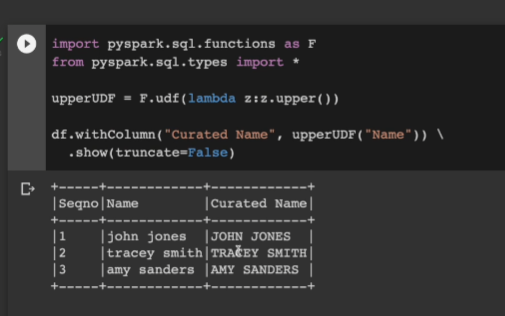
대문자화 됨.
다음으로 이번에는 람다가 아닌 파이썬 함수로 돌려본다. udf로 등록을 하면서 (register 아님) 리턴 타입을 StringType()으로 지정. 디폴트가 스트링타입이기에 명시적으로 써줄 필요는 없으나 적어봄.
이 레퍼런스를 upperUDF로 받아서, withColumn에서 똑같이 적용하고 .show로 출력
def upper_udf(s):
return s.upper()
uppderUDF = F.udf(upper_udf, StringType())
df.withColumn("Curated Name", upperUDF("Name")) \
.show(truncate=False)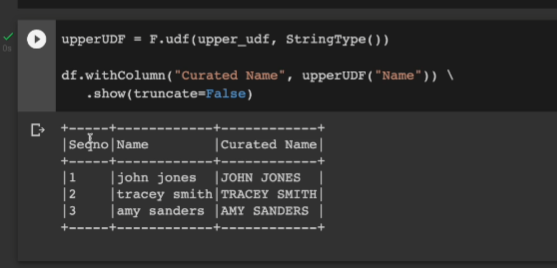
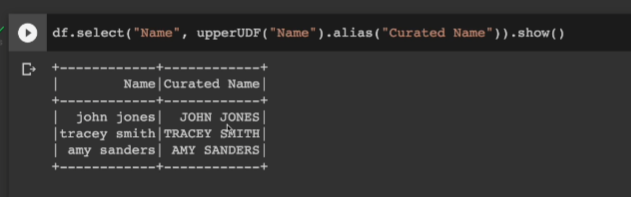
이번엔 withColumn 말고 select를 써서 보기로 한다. 사용법은 동일함. 컬럼을 인자로 udf를 주면 된다. 새로운 컬럼의 이름이 그대로고, 이를 고치려면 .alias("Curated Name")으로 하면 변경됨.
df.select("Name", upperUDF("Name")).show()
똑같은 함수를 이번엔 판다스 UDF로 만들어본다. 입력으로 레코드가 하나씩 들어왔던 전에 비해 이번엔 레코드 별이 아닌 레코드 집합이 들어옴. 판다스 시리즈인 집합단위로 들어오기에 퍼포먼스가 좋음.
upper를 어노테이션으로 씌움
register로 판다스 UDF를 등록함
from pyspark.sql.functions import pandas_udf
import pandas as pd
# Define the UDF
@pandas_udf(StringType())
def upper_udf_f(s: pd.Series) -> pd.Series:
return s.str.upper()
# 위에서 정의한 파이썬 upper 함수를 그대로 사용
upperUDF = spark.udf.register("upper_udf", upper_udf_f)
spark.sql("SELECT upper_udf('aBcD')").show()
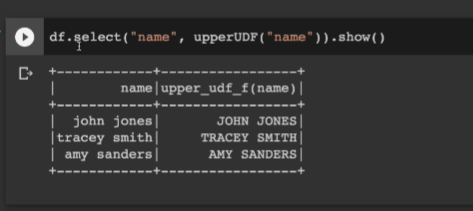
# 받은 인스턴스를 사용
df.select("name", upperUDF("name")).show()
df.createOrReplaceTempView("test")
spark.sql("""
SELECT name, upper_udf(name) 'Curated Name' FROM test
""").show()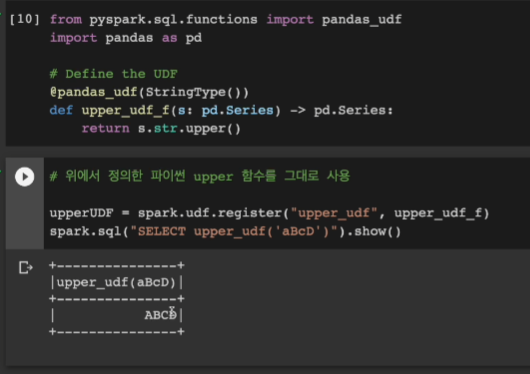
판다스 UDF는 퍼포먼스가 좋음.
스파크 SQL에선 레퍼런스를 쓰는게 아닌 register에 등록된 이름으로 사용한다. upper_udf
두 숫자의 합 UDF
F.udf(lambda x, y: x + y)("a","b")에서 ("a", "b")는 UDF에 의해 반환된 함수에 전달되는 인자입니다. 이 UDF에 "a"와 "b"를 인자로 넘기면, "a" 컬럼의 값과 "b" 컬럼의 값이 각각 x와 y에 바인딩되어, 이들을 더하는 연산이 수행됩니다.
저거 헷갈렸음. udf 기능이라고 한다.
data = [
{"a": 1, "b": 2},
{"a": 5, "b": 5}
]
df = spark.createDataFrame(data)
df.withColumn("c", F.udf(lambda x, y: x + y)("a","b")).show()람다가 아닌 파이썬 함수로 하고, plus를 줘본다.
def plus(x,y):
return x + y
plusUDF = spark.udf.register("plus", plus)
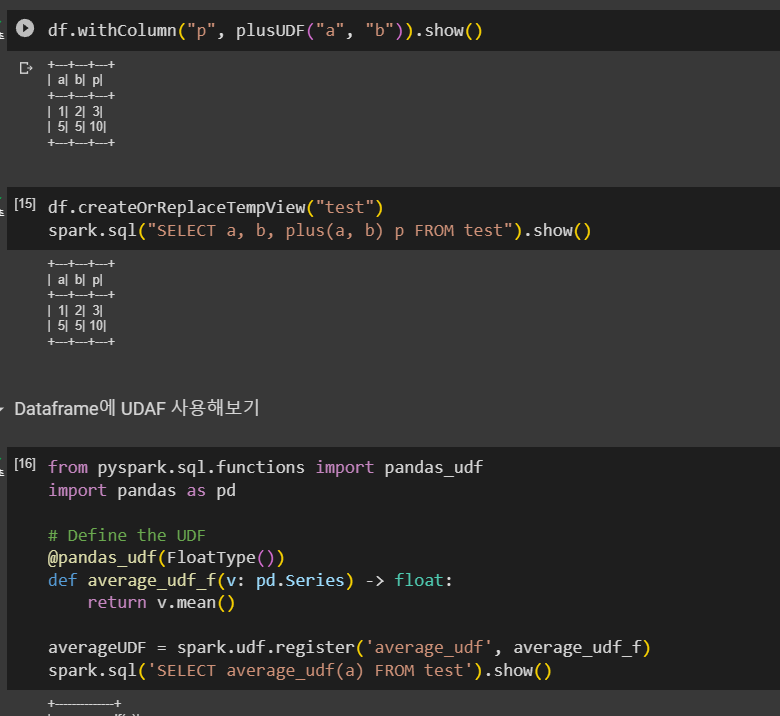
spark.sql("SELECT plus(1,2)").show()데이터 프레임은 리턴됐던 plusUDF로 지정
df.withColumn("p", plusUDF("a","b")).show()
SQL로 실행시켜본다
df.craeteOrReplacteTempView("test")
spakr.sql("SELECT a, b, plus(a, b) sum FROM test").show()
데이터프레임에 UDAF 사용
판다스 시리즈를 입력으로 받아 출력은 float, 함수 안에선 시리즈함수로 mean으로 평균 구함.
이걸 average_udf로 등록. -> sql에서 사용가능
averageUDF로 레퍼런스 받음 -> 데이터프레임에서 사용 가능.
집계함수라 agg함수 안에서 사용해야함. 보통 앞에 그룹바이를 쓰지만 전체에 대해 지금은 수행함.
from pyspark.sql.functions import pandas_udf
import pandas as pd
# Define the UDF
@pandas_udf(FloatType())
def average_udf_f(v: pd.Series) -> float:
return v.mean()
averageUDF = spark.udf.register('average_udf', average_udf_f)
# SQL
spark.sql("SELECT average_udf(b) FROM test").show()
# 데이터프레임
df.agg(averageUDF("b").alias("count")).show()데이터프레임 explode 사용
스택오버플로우 개발자 설문조사 때 써봤었다.
3개의 컬럼.
schema로 별도로 컬럼이름 넘겨줌.
arrayData = [
('James',['Java','Scala'],{'hair':'black','eye':'brown'}),
('Michael',['Spark','Java',None],{'hair':'brown','eye':None}),
('Robert',['CSharp',''],{'hair':'red','eye':''}),
('Washington',None,None),
('Jefferson',['1','2'],{})]
df = spark.createDataFrame(data=arrayData, schema = ['name','knownLanguages','properties'])
df.show()
먼저 explode 함수를 임포트. 그다음 컬럼을 셀렉트, 두개 컬럼만 선택해봄. 그리고 컬럼은 explode 함수의 인자로 제공함.
# 필드를 언어별로 잘라서 새로운 레코드로 생성
from pyspark.sql.functions import explode
df2 = df.select(df.name,explode(df.knownLanguages))
df2.printSchema()
df2.show()스미카를 보면 네임과 컬럼 두개가 나옴. col인 이유는 alias 안써서 기본값. 보면 값들이 별개의 레코드로 떨어진 것을 확인함.
앞에서 오더 아이템 관련 csv를 받는다
처음 레코드 5개를 본다
id가 있고, 아이템에는 3개의 컬럼이 있는 것을 확인할 수 있다.
이걸 스파크 데이터 프레임으로 로딩해본다
옵션으로 딜리미터, 헤더, csv 패스를 지정.
from pyspark.sql.functions import *
from pyspark.sql.types import StructType, StructField, StringType, ArrayType
order= spark.read.options(delimiter='\t').option("header","true).csv("orders.csv")
order.show()
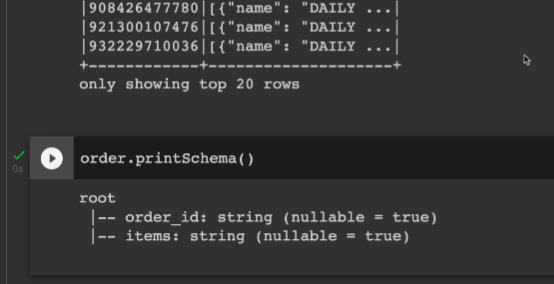
order.printSchema()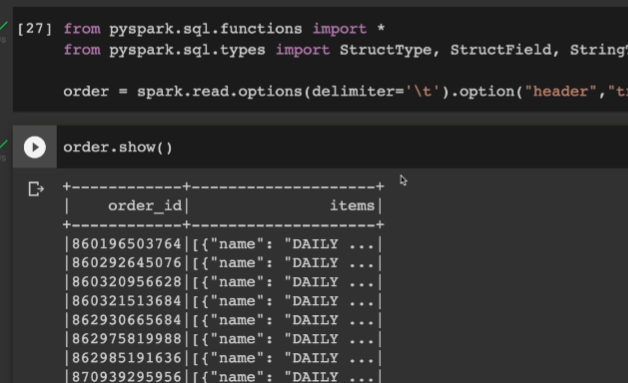
두번째 컬럼은 사실 리스트이나, 스트링으로 인식이 됨.
두번째 컬럼의 스키마를 잡으면서, 리스트의 항목을 나눠보기로 한다.
어레이 타입 안에, 스트럭트 타입이 있고, 각 필드를 정의함
# 데이터프레임을 이용해서 해보기
struct = ArrayType(
StructType([
StructField("name", StringType()),
StructField("id", StringType()),
StructField("quantity", LongType())
])
)그러고 explode를 하는데, withColumn으로 호출, 기존 레코드는 json이기에 from_json함수를 쓰고, 스키마는 만들어두었던 struct를 넣어준다 그러면서 explode를 함.
그럼 아이템이라는 새로운 컬럼 밑에 item.name, item.id, item.quantity라고 생김
nest된 스트럽쳐가 잡힘
order.withColumn("item", explode(from_json("items", struct))).show(truncate=False)
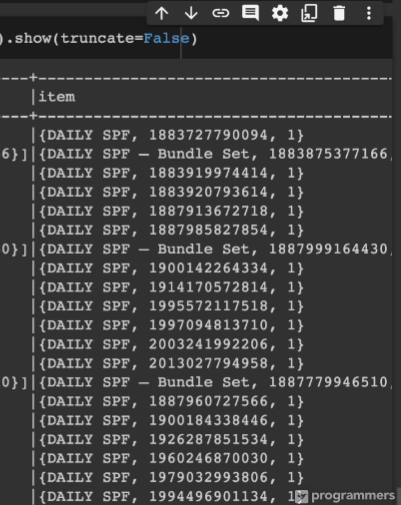
각기 생기긴 했으나, .show로는 안보임. 그래서 스키마를 찍어봐야함.
items가 존재하다보니 .drop한다.
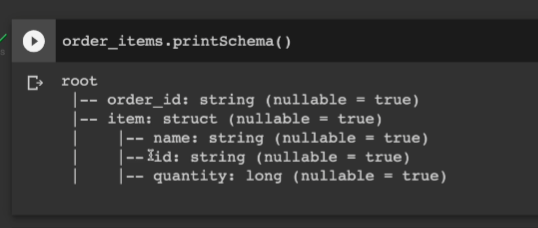
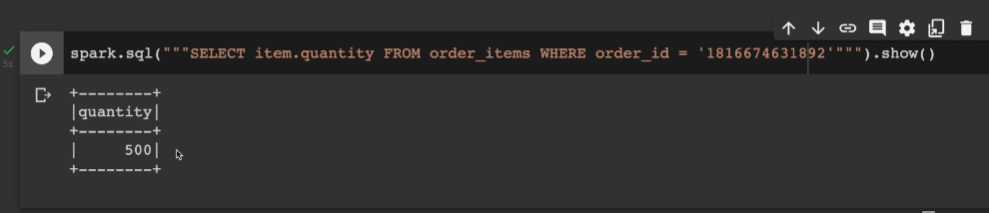
보면 아이템이 스트럭트 형식이고 그 밑에 3개의 컬럽이 들어가 있음 이걸 가지고, 앞에서 만들어본 avg구하는 udf 한번 quantity 필드에 적용해본다.
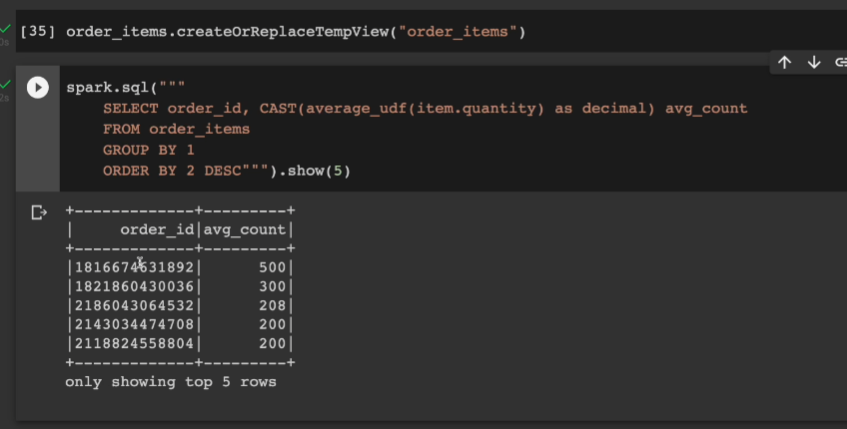
order id 별로 평균 quantity가 가장 높은 5개 찍어본다.
스파크에서 'struct'는 구조체를 의미하며, 여러 필드를 한 번에 묶을 수 있는 복합 데이터 타입입니다. 구조체는 여러 개의 다른 타입의 데이터를 하나로 묶는 역할을 합니다.
구조체는 특정 데이터를 하나의 단위로 관리할 때 유용합니다. 예를 들어, '이름', '아이디', '수량'과 같은 서로 다른 데이터를 'item'이라는 하나의 구조체로 묶어서 관리할 수 있습니다. 이렇게 함으로써 'item'을 하나의 데이터로 취급할 수 있으며, 'item' 내부의 각 필드에 접근할 수도 있습니다.
이 'struct' 타입은 SQL에서의 'Table'과 비슷한 개념으로 이해할 수 있습니다. 'struct' 내부에는 다양한 필드가 존재하고, 각 필드는 별도의 데이터 타입을 가질 수 있습니다. 이를 통해 다양한 데이터를 효율적으로 관리할 수 있습니다.
스파크에서 테이블 하나 만들어서, id 기준으로 그룹바이하고, 같은 id 레코드에서 quantity의 평균을 udf 함수로 계산. 그거를 소수점이 많을 경우 깨끗하게 출력하게 CAST as decimal로 십진수로 만들고 이걸 avg_count라 명함. avg_count로 내림차순
order_items.createOrReplaceTempView("order_items")
spark.sql("""
SELECT order_id, CAST(average_udf(item.quantity) as decimal) avg_count
FROM order_items
GROUP BY 1
ORDER BY 2 DESC""").show(5)
spark.catalog.listTables()로 목록 확인
for f in spark.catalog.listFunctions():
print(f)