- window가 어려워 보임.
모두 JOIN을 사용.
3. groupby 외에 다양한 연산자 사용
4. window 오퍼레이터 사용.

사용자가 회원등록을 하면 ID가 유일하게 생성.
사용자가 웹 서비스를 방문하면, 논리적으로 방문을 하면 세션 ID가 생성.
마케팅을 하면 사용자가 어느 사이트에서 왔는지 관심이 있음. 채널, 터치포인트라고 함.
뭘 보고 링크를 타고 왓는지, 그 어디를 채널, 터치포인트라고 함.
유튜브, 구글, 네이버 등이 있음.
이런 특정 채널을 통해 방문하는 경우, 거기마다 새로운 ID를 부여.
새로운 세션이 생기는 기준은 2개임.
1. 한번 방문하고 30분동안 아무것도 안하면 세션 하나
2. 30분 안쪽이라도 어떤 링크를 타고 새로 왔다면 생성
채널 정보 외에도, 어떤 캠페인을 보고왔는지, 캠페인 정보, 세션 생성 시간 기록.
어디에 돈을 쓰는게 효율적인지 알게됨.
어느 채널을 사용해야 하는지 등
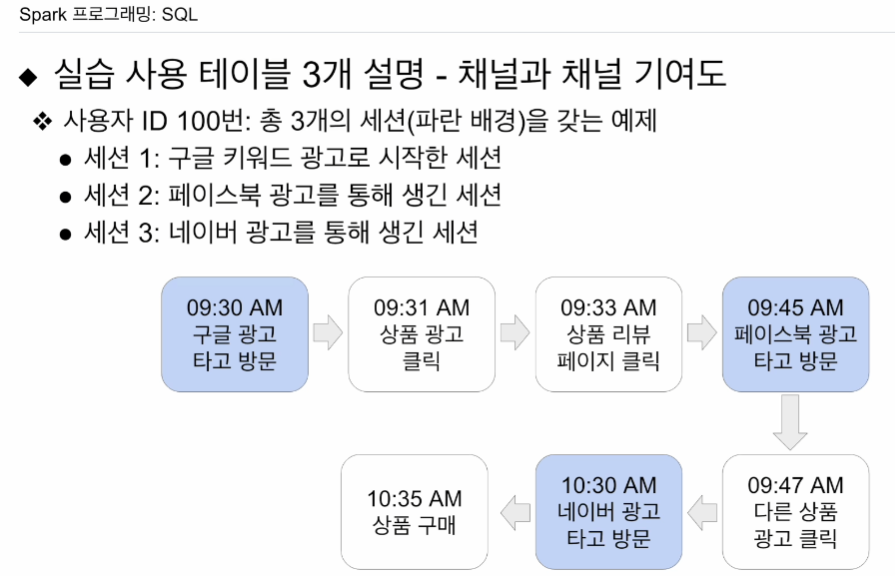
하늘색 - 세션이 만들어짐.
마지막 행동으로부터 30분이 지나지 않아도 세션이 생성됨.
매출 기여도 분석.
fist touch - 구글에게 크레딧 제공
last touch - 네이버에게 크레딧 제공
multi touch - 균등뷴배, 가장 최근, 마지막 등 여러 방식이 있음.
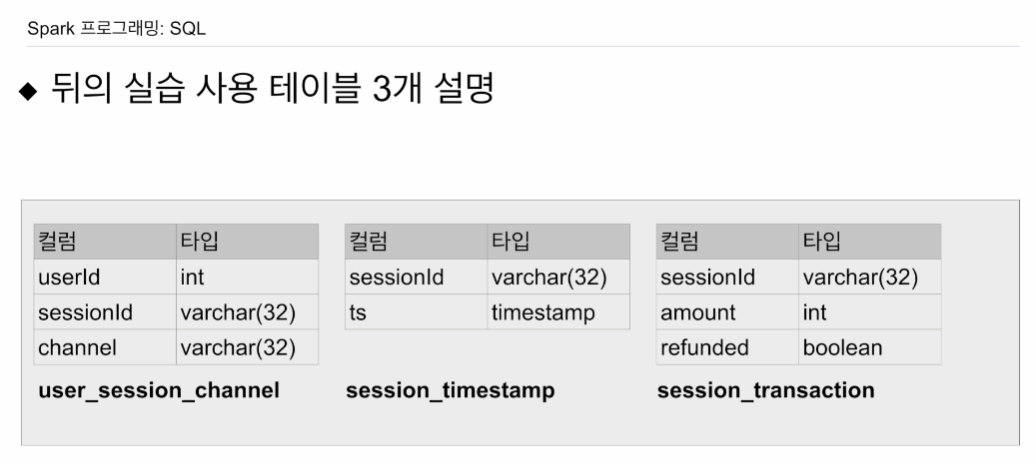
세션이 생길때마다 두개의 테이블에 나눠서 저장됨. 실습용.
이 테이블을 레드쉬프트로부터 스파크로 로딩해서 써볼 예정

JOIN을 실습해볼것. 6가지 JOIN이 있었는데, 구글 콜랩에서 실행하고 결과 본다.
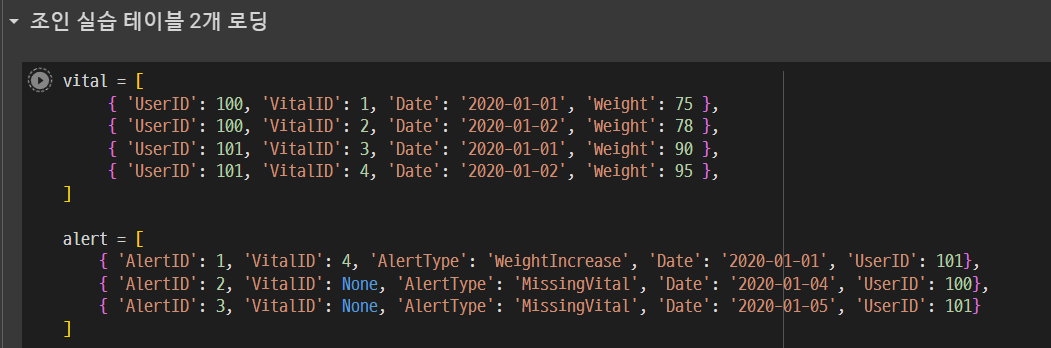
세션을 만들고
리스트를 데이터프레임으로 로딩
.paralleize로 RDD로 로딩한다음
그걸 .toDF로 데이터프레임으로 만들어본다.
Q -> 바로 데이터프레임으로 만들어도 될꺼같은데?
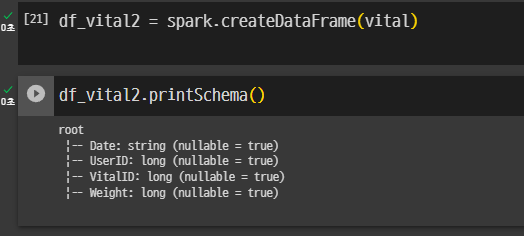
되는거 확인.
JOIN by DataFrame
.join 방식을 사용
join_expr로 별도로 어떤 키를 중심으로 할지 확인.
# INNER JOIN
join_expr = df_vital.VitalID == df_alert.VitalID
df_vital.join(df_alert, join_expr, "inner").show()
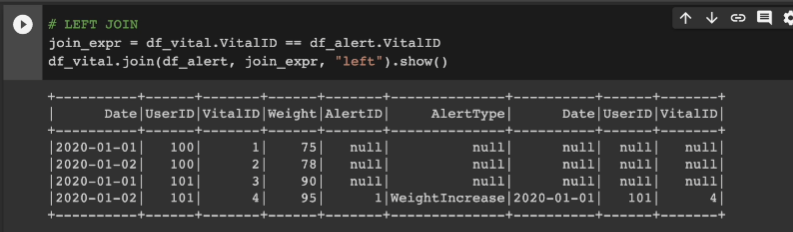
널로 채워진 것을 확인.
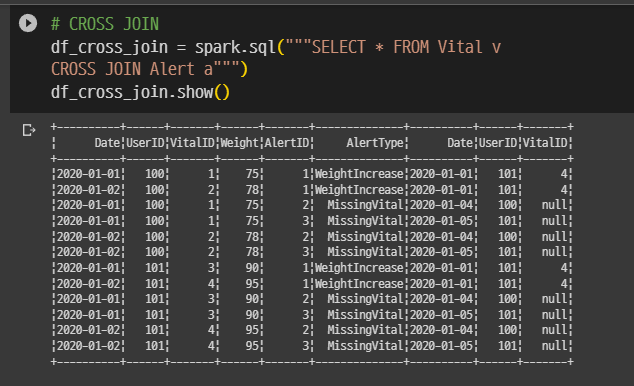
# CROSS JOIN
df_vital.join(df_alert, None, "cross").show()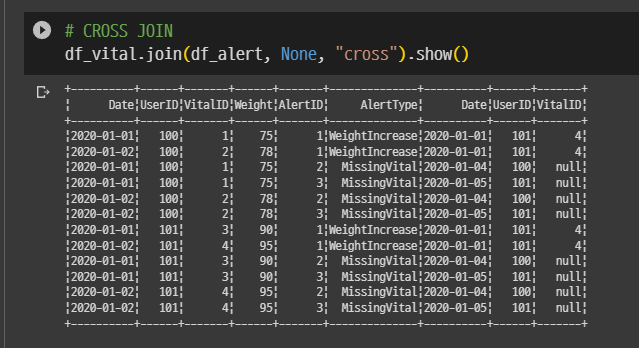
# SELF JOIN
join_expr = df_vital.VitalID == df_vital.VitalID
df_vital.join(df_vital, join_expr, "left").show()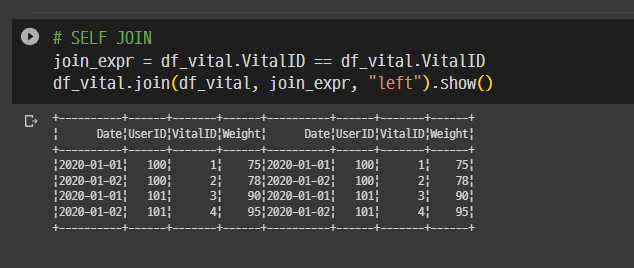
JOIN by SQL
df_vital.createOrReplaceTempView("Vital")
df_vital.createOrReplaceTempView("Alert")# INNER JOIN
df_inner_join = spark.sql("""SELECT * FROM Vital v
JOIN Alert a ON v.vitalID = a.vitalID;""")
df_inner_join.show()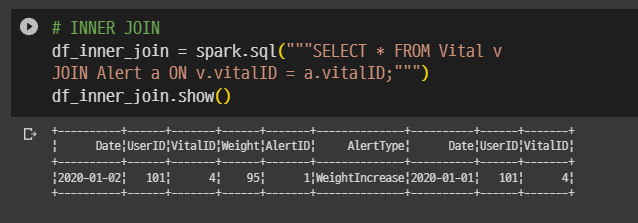
# CROSS JOIN
df_cross_join = spark.sql("""SELECT * FROM Vital v
CROSS JOIN Alert a""")
df_cross_join.show()