
미리 런타임을 돌리니 저번과 같은 JDBC 문제가 발생함.
!cd /usr/local/lib/python3.10/dist-packages/pyspark/jars && wget https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/2.1.0.14/redshift-jdbc42-2.1.0.14.jar
이걸로 버전 바꿔주고 나중에 구글 콜랩 버전이 또 업데이트 되면 바꿔줘야함.
또한 다시 실행하기 전에 런타임 연결 해제 및 삭제 하기.
총매출의 기준은 리펀드 여부를 관계하지 않음.
환불 신경쓰지 않고, amount를 기준으로 합이 가장 큰 사용자를 찾겠다.
위는 원하는 테이블 포맷임.
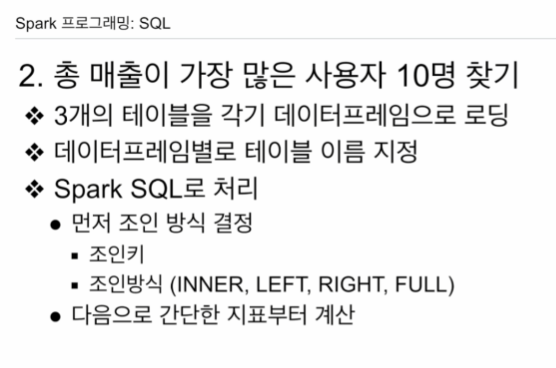
3개의 테이블 로딩.
SQL 테이블 이름 지정
SQL로 처리 시도.
테이블들을 JOIN 해야함.
그 다음 매출액을 계산함.
구글 콜랩으로 실습 진행.
파이스파크, 파이4j 설치.
레드쉬프트와 연결을 위한, JDBC jar 파일을 설치하기 위해 특정 디렉토리 확인.
그다음으로 스파크세션 오브젝트 생성.
다음은
3개의 테이블을 각각 데이터 프레임으로 로딩을 함.
jdbc url 스트링 만들어주고,
jdbc 이용해서 포맷, 드라이버, 테이블들을 데이터프레임으로 로딩.
# Redshift와 연결해서 DataFrame으로 로딩하기
url = "jdbc:redshift://learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com:5439/dev?user=guest&password=Guest1234"
df_user_session_channel = spark.read \
.format("jdbc") \
.option("driver", "com.amazon.redshift.jdbc42.Driver") \
.option("url", url) \
.option("dbtable", "raw_data.user_session_channel") \
.load()
df_session_timestamp = spark.read \
.format("jdbc") \
.option("driver", "com.amazon.redshift.jdbc42.Driver") \
.option("url", url) \
.option("dbtable", "raw_data.session_timestamp") \
.load()
df_session_transaction = spark.read \
.format("jdbc") \
.option("driver", "com.amazon.redshift.jdbc42.Driver") \
.option("url", url) \
.option("dbtable", "raw_data.session_transaction") \
.load()세개 데이터 프레임을 테이블을 만들어본다 각기 레코드를 살펴본다.
df_user_session_channel.createOrReplaceTempView("user_session_channel")
df_session_timestamp.createOrReplaceTempView("session_timestamp")
df_session_transaction.createOrReplaceTempView("session_transaction")
총매출 가장 많은 사용자 10명
먼저 왼쪽, 오른쪽 테이블 있어야함. 유저 id, 매출금액이 필요함.
매출금액 session_transaction의 amount 필드
usc와 str을 sessionid로 조인함.
어느 조인을 해도 차이가 안남. 어차피 세션이 없는 경우는 없음.
마지막으로 LIMIT 10으로 수 자름.
top_rev_user_df = spark.sql("""
SELECT userid,
SUM(str.amount) revenue,
SUM(CASE WHEN str.refunded = False THEN str.amount END) net_revenue
FROM user_session_channel usc
JOIN session_transaction str ON usc.sessionid = str.sessionid
GROUP BY 1
ORDER BY 2 DESC
LIMIT 10""")policy 컨벤션.
SUM(CASE WHEN str.refunded = False THEN str.amount ELSE 0 END) net_revenue
CASE WHEN ~ THEN ~ ELSE ~ END 문
top_rev_user_df2 = spark.sql("""
SELECT
userid,
SUM(amount) total_amount,
RANK() OVER (ORDER BY SUM(amount) DESC) rank
FROM session_transaction st
JOIN user_session_channel usc ON st.sessionid = usec.sessionid
GROUP BY userid
ORDER BY rank
LIMIT 10""")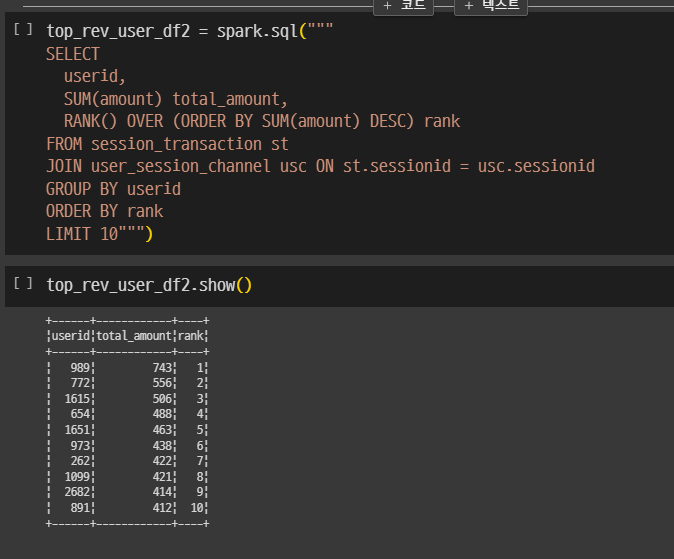
RANK() OVER (ORDER BY SUM(amount) DESC) rank
똑같은 작업을 데이터프레임으로 할수도 있으나 복잡함. 리더빌리티도 떨어짐.
