
사용자별로 처음채널, 마지막 채널.
유저세션채널, 세션타임스탬프 테이블 이용
세션이 생성된 시간을 기준으로 처음 채널과 마지막 채널
- first touch
- last touch
SQL이 생각보다 강력함

251의 방문기록을 일단 다 가져와본다
세션 ID 기준으로 조인을 하고 그 때의 ts, 채널을 가져온다.
오름차순으로 가장 오래된 ts가 처음, 가장 최근이 마지막
여기서 맨 처음을 뽑으면 first
마지막을 뽑으면 last
SELECT ts, channel
FROM user_session_channel usc
JOIN session_timestamp st ON usc.sessionid = st.sessionid
WHERE userid = 251
ORDER BY 1실습은 사용자 id마다 매뉴얼하게 하는게 아니라, sql을 작성해서 각 사용자의 처음과 마지막을 구하고자 함. sql의 윈도우 함수를 쓰면된다. ROW_NUMBER과 FIRST_VALUE,LAST VALUE -> SUM 이라는 window 함수와 곁들여서.
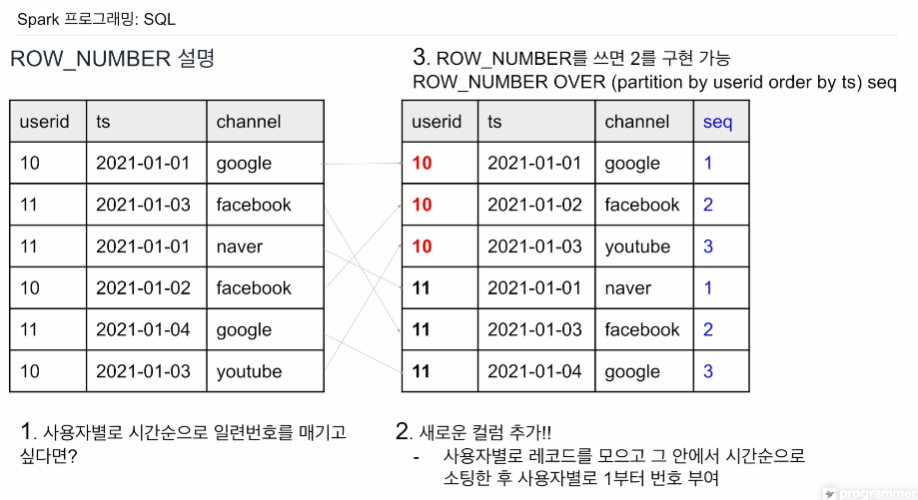
rank 함수와 비슷한 면이 있음. 이 테이블들의 레코드를 오른쪽과 같이 재정렬을 함. 같은 userid로 묶어서 (파티션이라고 함) 같은 파티션 안에선 ts를 기준으로 오래된 순으로 1~순으로 번호를 매김. 이렇게 정렬을 한 다음에 seq 넘버가 1을 뽑으면 이게 바로 first channel이 될 것임. 그리고 가장 큰값은 last channel이 될 것임. 그 큰값을 찾는건 번거롭기에, sorting을 내림차순으로 돌려서 seq 1 값을 가져가면 last를 쉽게 얻을 수 있다.
이런식의 정렬을 가능케 해주는건 ROW_NUMBER()임.
ROW_NUMBER OVER (partition by userid order by ts) seq
파티션 -> 묶음 기준이 되는 컬럼
만일 내림차순이 필요하면 ts 뒤에 desc를 적어주면 됨.
뭔가 ROW_NUMBER라는 문장이 잘 연결되지 않는 느낌이긴 하다.
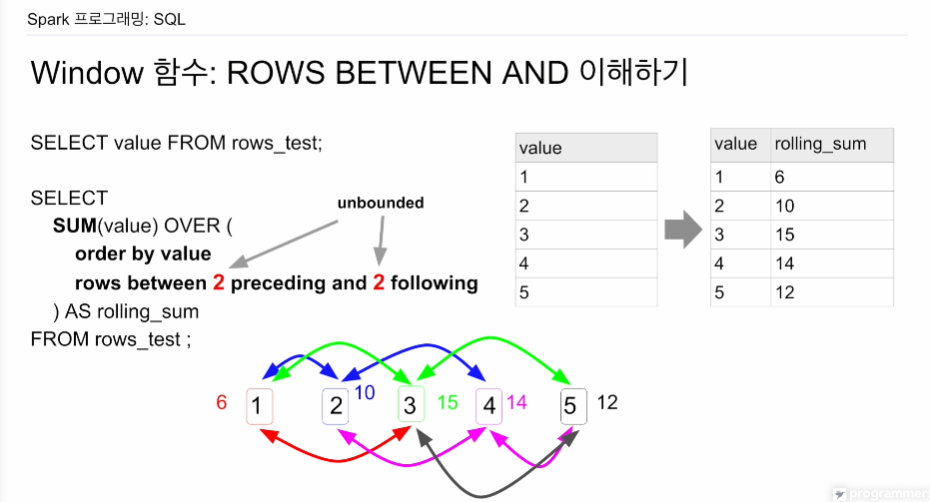
여기선 SUM을 이용해본다.
앞의 레코드 두개, 뒤의 레코드 두개의 합을 구하고 싶다면.
1은 1 + 2 + 3 = 6
5는 3 + 4 + 5 = 12
없으면 제외하고 있으면 자기 포함해서 더하면 됨. window함수는 집계함수가 아님. 기존 레코드에 새로운 레코드를 붙이는 식임.
SUM을 부르고 OVER를 호출함.
(order by vlaue -> 오름차순
rows between 2 preceding and 2 following -> preceding은 앞에 있고, following은 뒤에있음
value 값을 가지고 sorting 그리고 최대 5개의 레코드의 value 값을 SUM 해라.
예를들어 앞에 5개 뒤에 5개면 저 2 위치의 숫자를 고치면 된다.
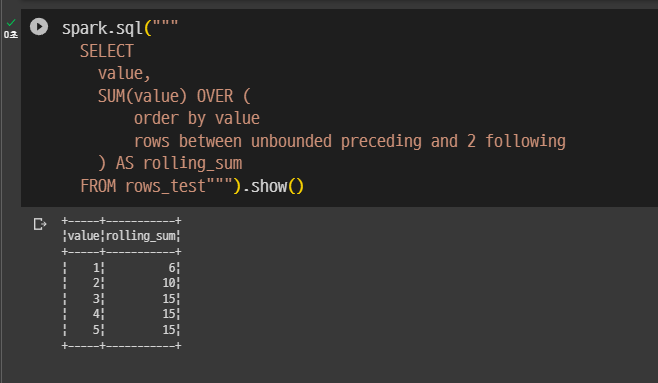
다 더하고 싶다면 unbounded를 숫자 위치에 적으면 됨.
SUM 자리에 FIRST_VALUE, LAST_VALUE를 쓸수 있는데 그럼 저 집합 중에 처음 채널, 마지막 채널을 구할 수 있음.
그럼 userid로 묶어서 그 파티션에서 구하는 거 같은데..
실습
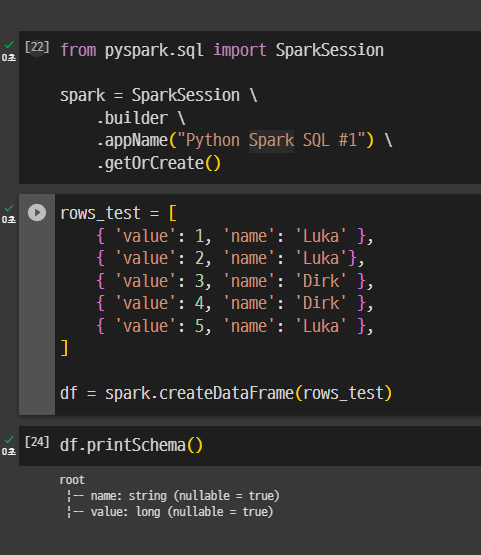
테스트 프레임 생성
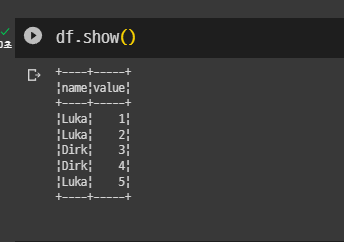
임의 테이블 생성
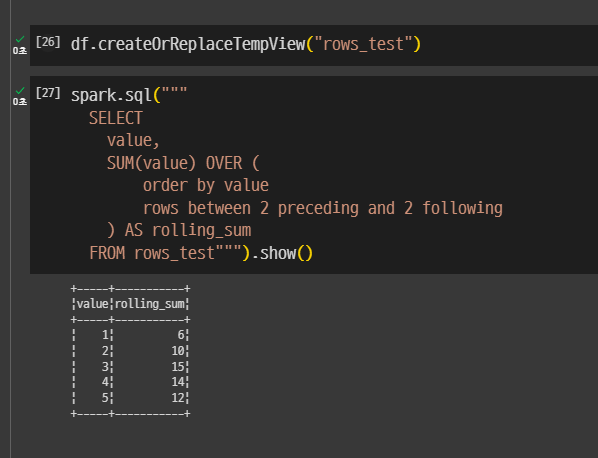
spark.sql("""
value,
SUM(value) OVER (
order by value
rows between 2 precedding and 2 following
) AS rolling_sum
FROM rows_test""").show()보면 SUM 에 대한 처리가 자기 위치의 각 레코드마다 적용된다.
preceding을 unbounded로 한 모습.
이제 FIRST_VALUE, LAST_VALUE를 써본다.
ROW_NUMBER OVER (partition by userid order by ts) seq
파티션 전체에서 볼것인지, rollingwindow에서 볼것인지. 나는 같은 파티션 레코드들이라면 다 넣고 처음값, 마지막값 보겠다 - unbounded.
보면 FIRST, LAST 이렇게 두개가 있음.
luka 125
Dirk 34
이렇게 값을 가짐.
window함수는 레코드 수를 줄이는게 아니라, 컬럼만 늘려나가는 식임.
spark.sql("""
*,
FIRST_VALUE(value) OVER (
partition by name
order by value
rows between unbounded preceding and unbounded following
) AS min_value,
LASE_VALUE(value) OVER (
partition by name
order by value
rows between unbounded preceding and unbounded following
) AS max_value
FROM row_test""").show()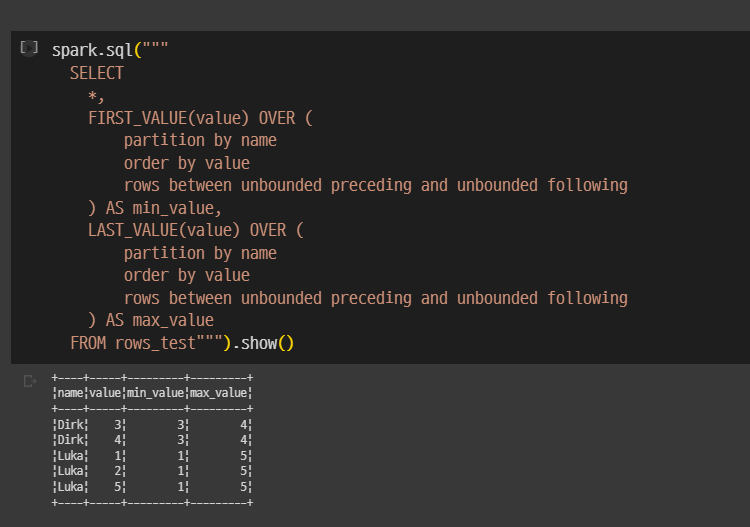
사용자별로 처음 채널과 마지막 채널 알아내기
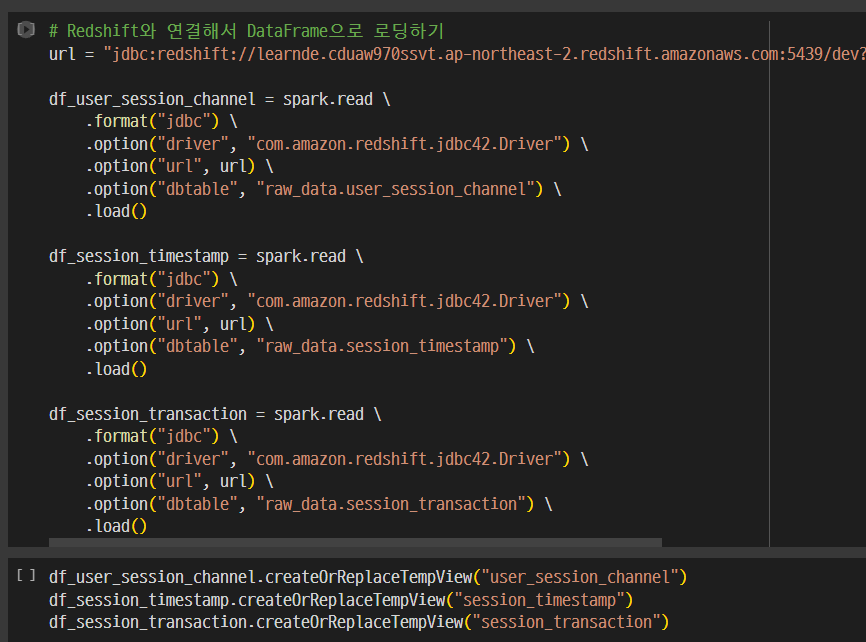
테이블들 로딩.
with AS 문법으로 임시테이블을 만들고, 그 임시테이블을 FROM과 INNER JOIN, 셀프조인을 함
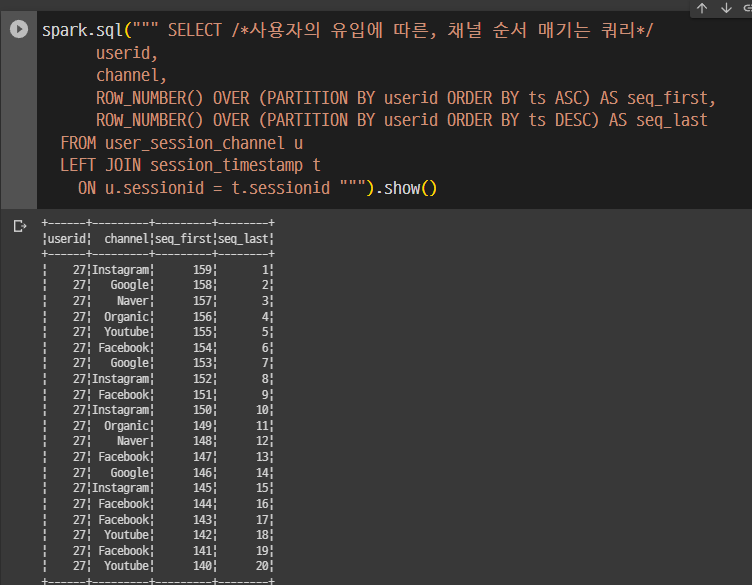
셀프조인 이유 -> 모든 경우의 수를 만들고 그 중, seq_first =1, seq_last = 1 인 경우만 뽑아내기 위함. 결국 한 유저에서 first 1개, last 1개의 레코드 생성됨.
SELFJOIN 을 써야한다는 점을 유념.
WITH AS . 레코드 두개를 셀프 조인으로 섞음
ROW NUMBER 두번 적용. 첫번째, 마지막 채널
first_last_channel_df = spark.sql("""
WITH RECORD AD (
SELECT /*사용자의 유입에 따른, 채널 순서 매기는 쿼리 */
userid,
channel,
ROW_NUMBER() OVER (PARTITION BY userid ORDER BY ts ASC) seq_first,
ROW_NUMBER() OVER (PARTITION BY userid ORDER BY ts DESC) seq_last
FROM user_session_channel u
LEFT JOIN session_timestamp t ON u.sessionid = t.sessionid
)
SELECT
f.userid,
f.channel first_channel
l.channel last_channel
FROM RECORD f
INNER JOIN RECORD l ON f.userid = l.userid
WHERE f.seq_first = 1 and l.seq_last =1
ORDER BT userid
""")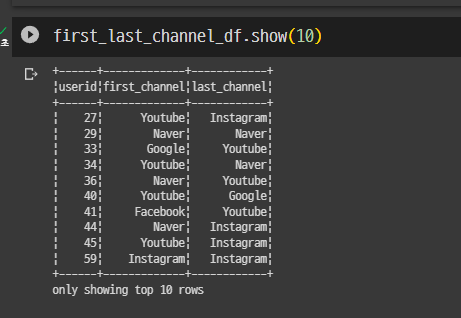
사용자 아이디별로 first, last가 나온 것을 확임.
FIRST_VALUE, LAST_VALUE를 써봄
rows between -> ㅇ롤링 윈도우를 어떻게 가져갈지를 결정하는 기준.
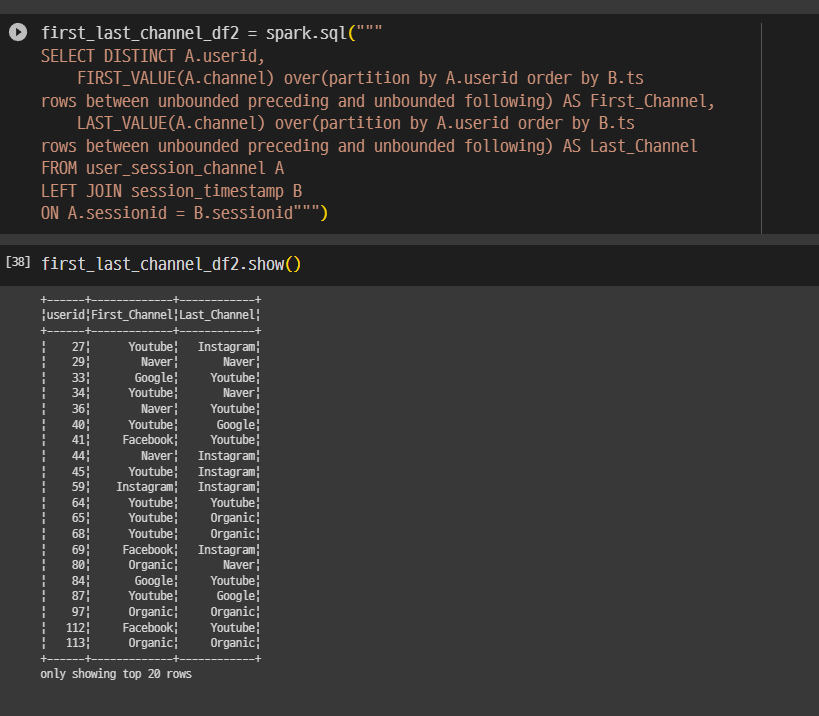
나중에 프로젝트 때 써먹으면 좋을 것 같음.
sql 고급.
