데이터베이스, 테이블이 어떻게 관리 되는지.
인메모리 카탈로그가 있음 스파크엔.
데이터 프레임을 마치 테이블처럼 만들어서 스파크 sql에서 sql문으로 처리함. 스파크세션 밑 카탈로그 밑 리스트테이블스 메소드를 불러 어떤 테이블이 있는지 확인했었음.
이 카탈로그가 인메모리 카탈로그. 스파크세션이 없어지면 사라짐. 모두 임시정보임.
persist한 정보를 필요로할 때가 있음. 디스크 기반 테이블을 구현하고자 함.
스파크에는 두종류의 테이블뷰 있음.
1. 인메모리 카탈로그 - 임시
2. 파일시스템에 저장. - HDFS 하이브와 호환되는 메타스토어 카탈로그.
하이브와 호환되는 메타스토에 알아본다.
일반적으로 데이터베이스 관리방법에 알아본다.
데이터베이스 폴더 같은거에 저장.
별다른 데이터베이스 없이 테이블을 저장을 하면 디폴트라 불리는 폴더에 저장이 될 것임.
데이터베이스를 사용함으로써 효율적 관리 가능.
etl로 데이터 웨어하우스, 레이크로 들어올 때 기본적으로 raw_data
elt를 통해 요약된 디노멀라이즈된 analytics에 저장.
데이터베이스를 정규화(또는 디노멀라이즈)한다는 것은 데이터 중복을 최소화하고, 데이터 구조를 효율적으로 만드는 과정을 말합니다. 이는 데이터베이스의 설계 단계에서 주로 이루어지며, 테이블 간의 관계를 설정함으로써 이루어집니다.
대부분의 데이터베이스 아래에 테이블이 들어감
하이브도 마찬가지.
특정한 테이블을 지칭할 때는 데이터베이스.테이블 로 지칭함.
메모리 기반 임시테이블은 많이 사용해봤다.
- 스파크세션 종료시 같이 사라짐.
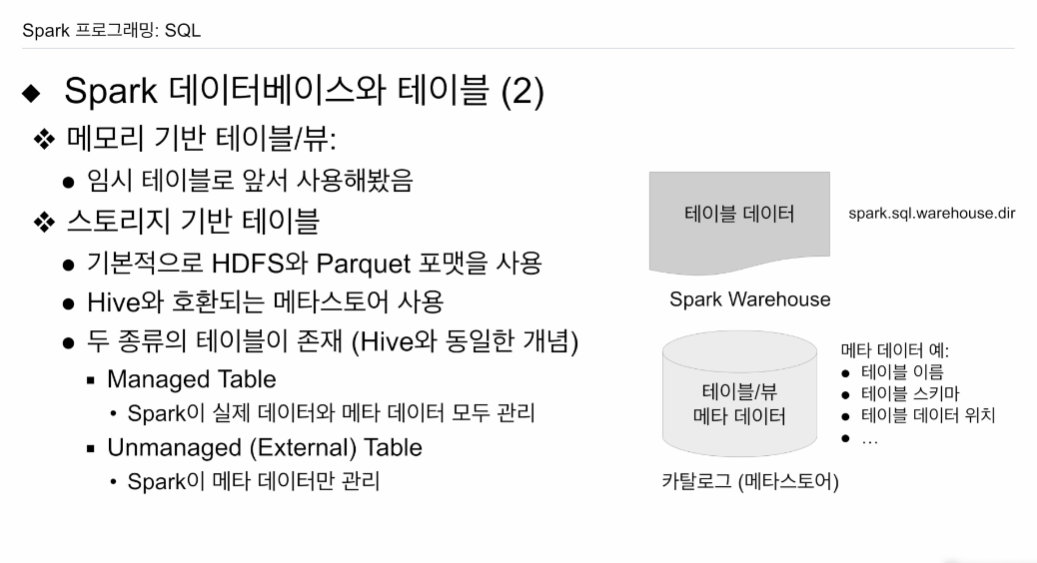
스토리지 기반 테이블
HDFS에 저장되고 Parquet 포맷 사용
메타데이터에 대한 정보가 필요함. (테이블 이름, 스키마, 정보, 등등)
- 카탈로그에 저장됨.
실제 데이터는 HDFS 어딘가에 저장이 됨.
정해주는 환경변수 spark.sql.warehouse.dir에 저장이 됨.
이따 콜랩에서 확인.
HDFS 상에 테이블을 만들 때 두가지 방법
Managed Table
스파크 카탈로그가 실제데이터, 메타데이터 다 관리함. 성능등을 봤을 때 선호됨
unmanaged
테이블은 어딘가 HDFS에 있고, 스파크가 내부테이블처럼 사용함
스파크는 메타데이터만 관리하고 실제 데이터는 관리 X
내부테이블로 만들어진 테이블들을 drop 하면 HDFS에서 사라지지만
External Table을 삭제하면 메타데이터만 삭제되고 실제 데이터는 그대로 존재.
말 그대로 외부테이블이기 때문. 마치 내 테이블처럼 쓴거지 실제 주인은 아닌 느낌.

메타스토는 어떻게 쓸까.
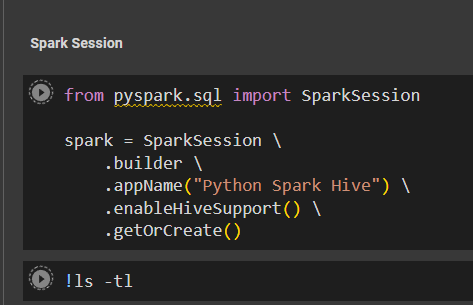
세션을 생성할 때
.enableHiveSupport()
default라는 데이터베이스 (폴더)가 생성됨.
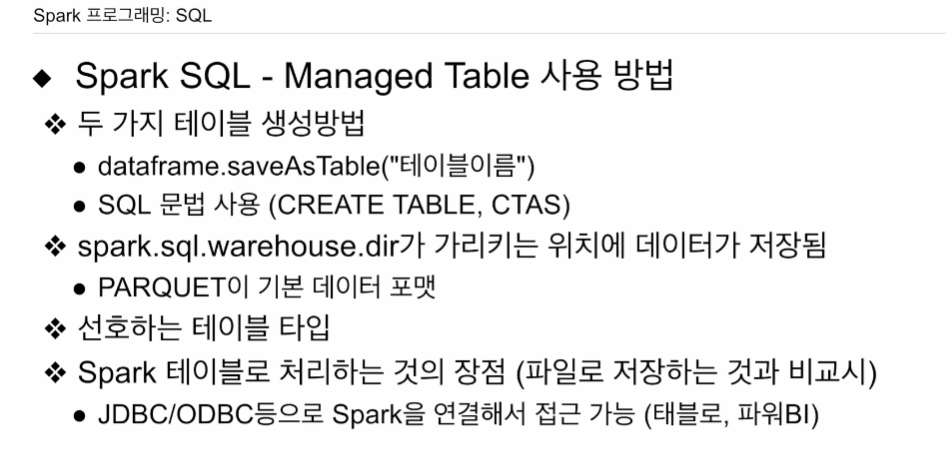
데이터프레임에서 제공하는 saveAsTable("테이블이름")
HDFS에서 테이블 이름으로 지정된 데이터베이스에 저장.
SQL 문법. CREATE TABLE 해도 HDFS에 저장됨. 어느 위치에 저장은
spark.sql.warehouse.dir이 가리키는 위치
Parquet 포맷 사용.
여러 측면에서 좋음. 가능하면 managed 사용하는게 좋음.
엄연한 데이터베이스임. 외부에서 JDBC 등으로 스파크에 연결.
태블로, powerBI에서 백엔드DB로 차용할 수 있음
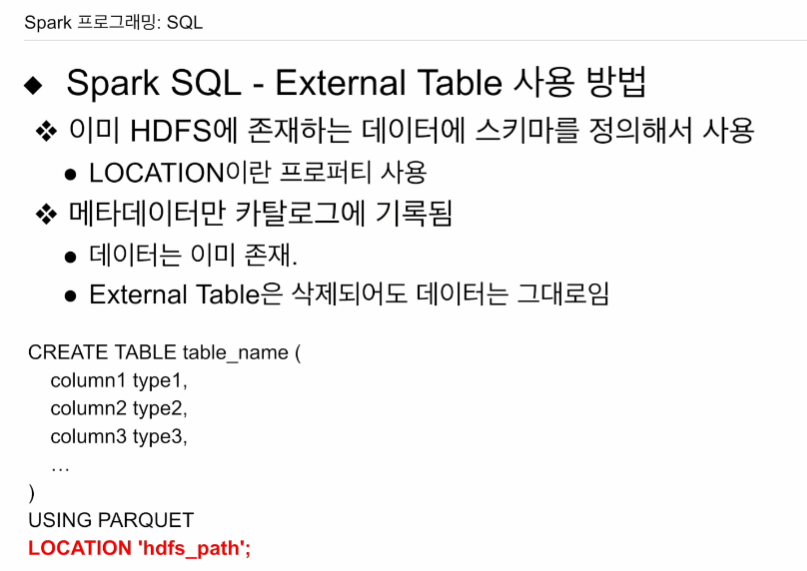
이미 HDFS에 데이터가 저장되어 있고,
스키마 알고있고, 엑세스 권한
LOCATION 프로퍼티를 씀으로써, 내가 가리키는 위치를 갖고 테이블을 만들겠다.
테이블에 대한 정보(메타데이터, 카탈로그에 저장)만 다루게 됨.
external table을 drop해도 그래도 남아있음 HDFS엔.
실습
Managed로 저장
default 말도 데이터베이스 CTAS로 써봄
실습용 csv 받음.
스파크 세션 오브젝트 만듦.
.enableHiveSupport()
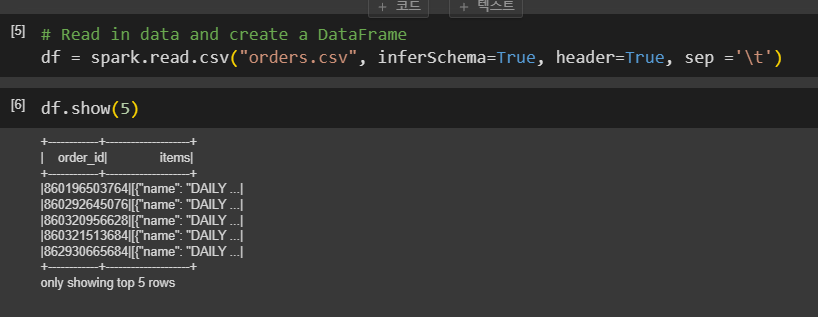
csv를 데이터 프레임으로 불러와본다.
df = spark.read.csv("orders.csv", inferSchema=True, header=True, sep='\t')
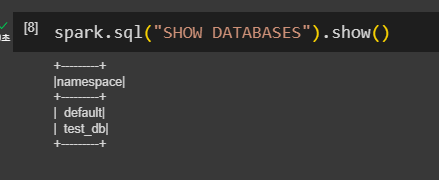
데이터베이스를 만들어본다
그 전에 기존 데이터베이스를 SHOW DATABASES로 볼 수 있다.
데이터 베이스 생성
spark.sql("CREATE DATABASE IF NOT EXITSTS TEST_DB")
spark.sql("USE TEST_DB")
이제 test_db 사용
대문자로 쓰더라도 결국 다 소문자로 쓰임.
ls -tl
로컬 스탠드얼론임. HDFS가 없음. 로컬을 HDFS로 사용
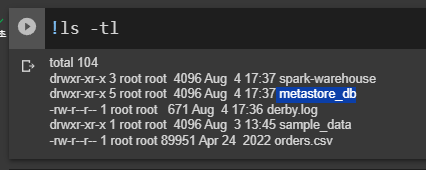
요 metastore_db 스파크 메타스토어고 하이브 메타스토어와 호환. 그리고 spark-warehouse가 생겼는데 이게 HDFS 폴더에 해당함. 스파크에서 managed table 만들면 웨어하우스 밑에 저장이 됨.
df.write.saveAsTable("TEST_DB.orders", mode="overwrite")
이러면 웨어하우스 밑에 저장이 됨.
제대로 저장됐는지 확인하기 위해.
ls -tl spark-warehouse/test_db.db/orders

파일이 생성되어있고 parquet 포맷으로 됨.
레코드를 읽어본다
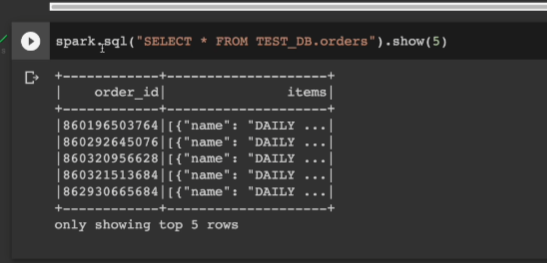
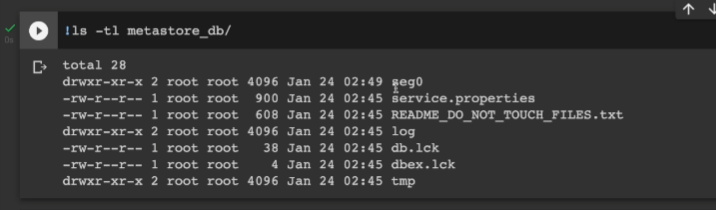
메타스토어 내에 여러 파일들이 있음.
spark.catalog.listTables()
HDFS에 영구적으로 저장되는 메타스토어임.

managed, Fasle 확인
CTAS를 써서 테이블 만들어본다.
만들려는 테이블이 이미 존재하면 에러나기에 드랍해봄
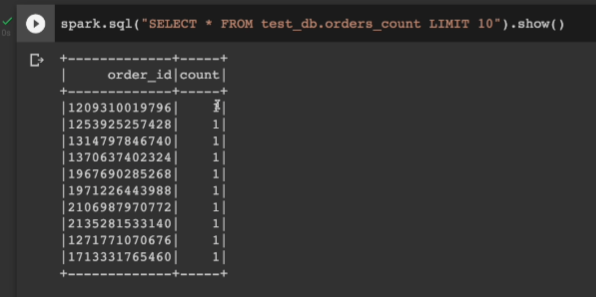
DROP TABLE IF EXISTS TEST_DB.orders_count;
CRETAE TABLE TEST_DB.orders_count AS
SELECT order_id, COUNT(1) as count
FROM TEST_DB.orders
GROUP BY 1
managed로 만들어진거 확인.

테이블 확인