
두개 config가 있음
spark = SparkSession \
.builder\
.master("local[3]")\
.appName("SparkSchemaDemo")\
.config("spark.sql.adaptive.enabled", False)\
.config("spark.sql.shuffle.partitions", 3) \
.getOrCreate()
df = spark.read.text("shakespeare.txt")
df_count = df.select(explode(split(df.value, " ")).alias("word").groubBy("word").count()
df_count_show()adaptive를 끄는 이유는 우리가 이해하기 힘든 최적화를 하는 경우도 있기 때문. 학습측면에서 도움 안됨.
text파일을 데이터 프레임으로
기본으로 주어지는 컬럼 이름은 value임 컬럼을 중심으로 공백을 기준으로 단어들의 리스트를 만들고, 각 단어를 별개의 레코드가 되게 함. 새로운 컬럼은 word로 바꾸고 나서 그 컬럼만 선택하고 count를 해 새로운 데이터 프레임을 만들었음.
.show()라는 액션을 실행함.
앞의 코드들이 실제로 실행이 됨.
csv와 다르게,
csv에선 헤더를 true로 세팅해서 잡이 하나 생겼었음. 스파크가 실제로 파일을 읽어보고 컬럼을 추측했음.
이 경우 read 자체로는 액션이 아님.
따라서 .show() 여기서만 잡이 하나 생김
그리고 그룹바이로 인해 두개의 스테이지가 생성. 각 스테이지는 내로우 디펜던시 트랜스포매이션을 함.
만일 show가 없다고 하면? 이 경우 액션이 없기 때문에 잡이 없음. 뭔가 실행은 하고 있지만 쓰이지도 않고 누구에게 보이지도 않음. 레이지 엑시큐션 장점이 쓸모없는 일을 막을 수 있음.
스파크 웹 UI를 통해 보자
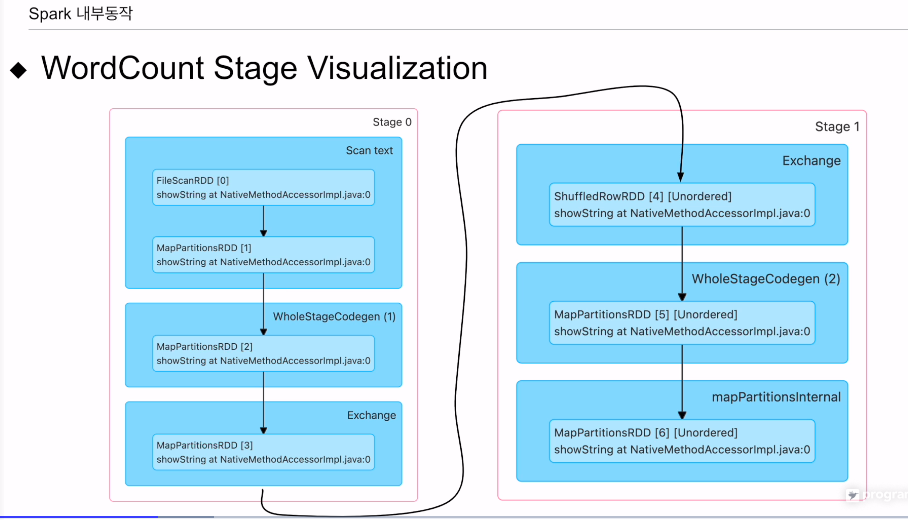
두개의 스테이지로 구성됨
그룹바이를 두고 나뉨. - 셔플링 - 익스체인지라고함
아웃풋 익스체인지
인풋 익스체인지가 있음
전체 코드(쿼리)에서 보면
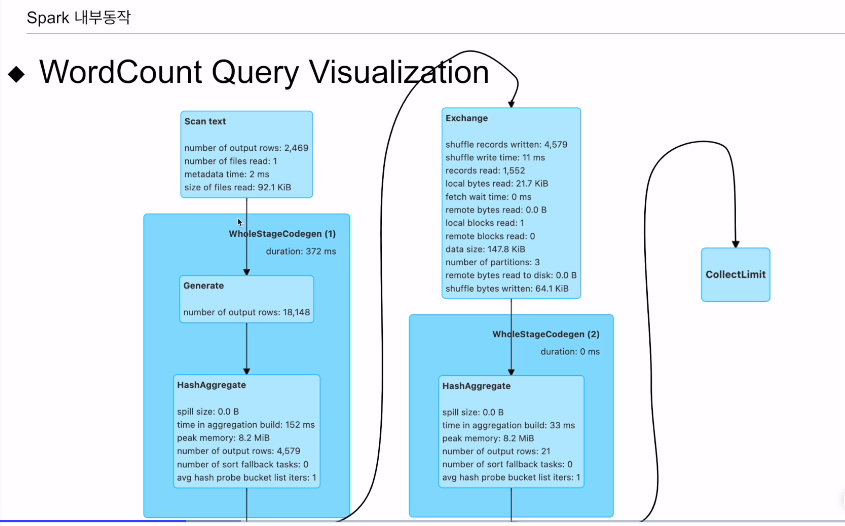
앞이 스테이지 0 뒤가 스테이지 1
최종적으로 20개 레코드를 드라이버로 보내게 됨.
조인 코드
# 스파크세션 생성은 동일
df_large = spark.read.json("large_data/")
df_small = spark.read.json("small_data/") # small이 충분히 작다면?
join_expr = df_large.id == df_small.id
join_df = df_large.join(df_small, join_expr, "inner")
join_df.show()
두개의 다른 데이터 프레임을 로딩하고있음
이 경우에는 잡이 3개가 만들어 질 것임
데이터 프레임이 생길 때 한번
small 생길 때 또 한번
show가 실행 됐을 때 1번
join 방식 중 셔플 해싱 조인이 사용될 것임.
두번째 데이터프레임이 굉장히 작을때 굉장한 오버헤드가 될 수 있음 - 브로드캐스트 조인 있음.
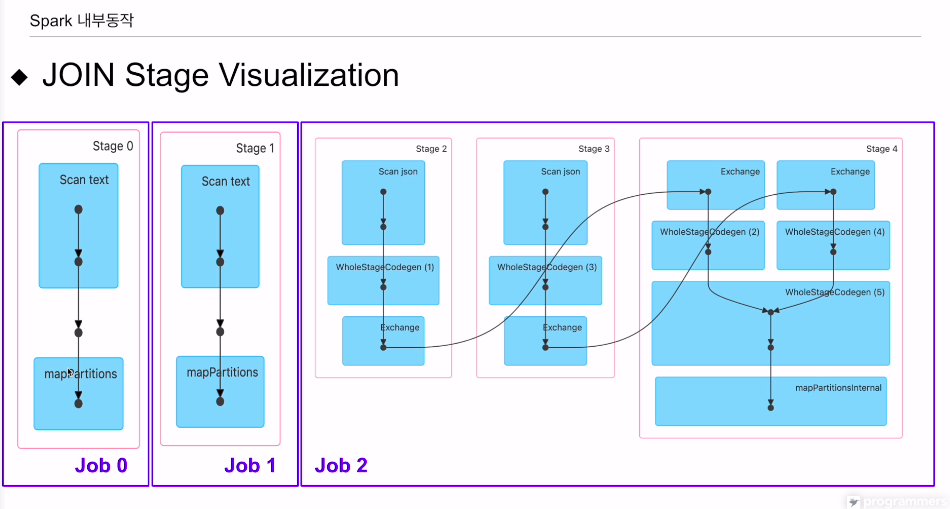
df_large 데이터 프레임
df_small 데이터 프레임
large, small 각각이 join키가 되는 아이디를 기준으로 셔플링을 하고, 인풋 익스체인지쪽에서 소팅을 하고 같은 id 갖는 레코드들을 모아줌.
잡 3개로 이뤄져 있음
쿼리레벨에서 본다
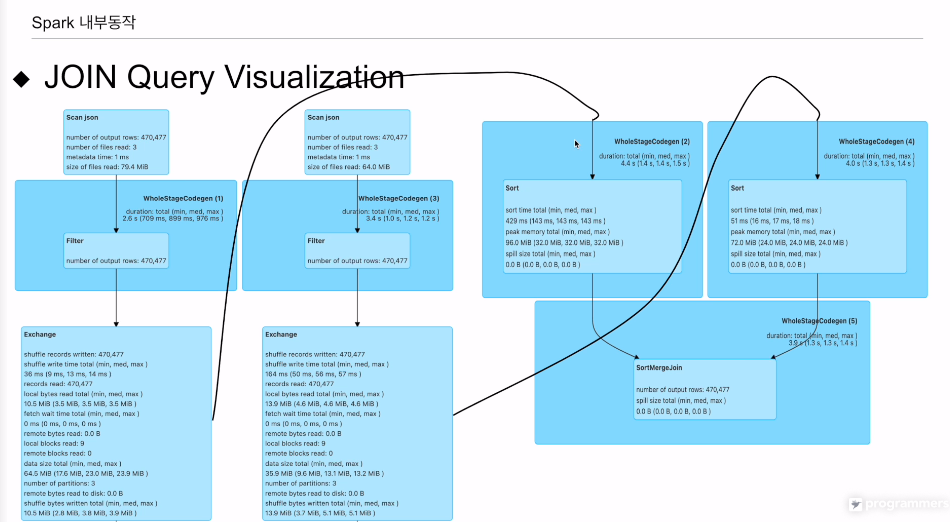
sort merge 조인을 하고 있음
한쪽이 작으면 오버헤드가 됨.
브로드캐스트 조인에 대해 알아본다

broadcast 임포트 후,
join_df = df_large(broadcast(df_small), join_expr, "inner")
브로드캐스트를 하라고 함수를 호출해줌. 그 외엔 동일함.
명시적으로 호출하지 않아도 옵션에 따라 알아서 해주기도 함.
autoBroadcastJoinThreshold의 값보다 작을 경우 브로드캐스트 함.
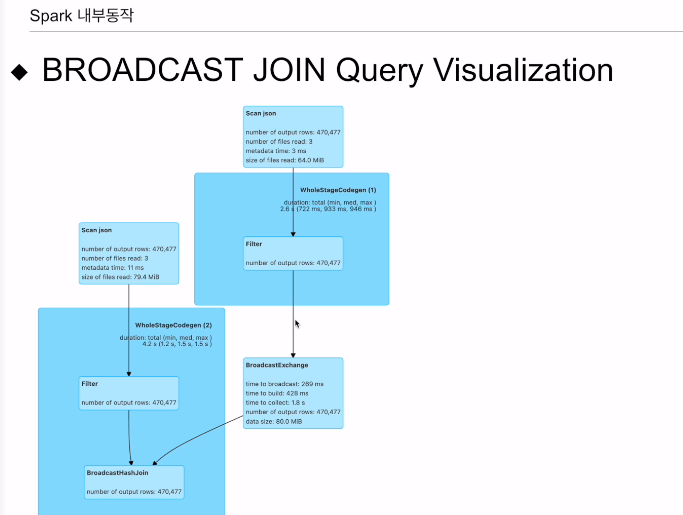
df_large가 있고
셔플조인을 하는게 아니라, 큰 데이터프레임에 작은데이터 프레임을 보냄.
시각화는 스파크 웹 UI에서 볼 수 있음
구글 콜랩이 아닌, 컴퓨터의 로컬 스탠드 얼론에서 같이 보도록 한다.
콜랩에선 웹 UI 포트를 막아놨기 때문.
실습
시각화 예를본다.
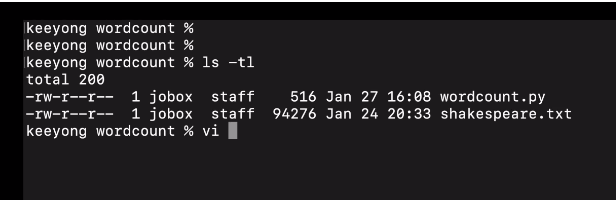
끝에 코드가 종료되지 않고 기다리게 함. 그래야 스파크가 살아있고, 웹 ui에 접근할 수 있기 때문. 외엔 동일.
spark-summit --master "local[3]" wordcount.py로 실행.
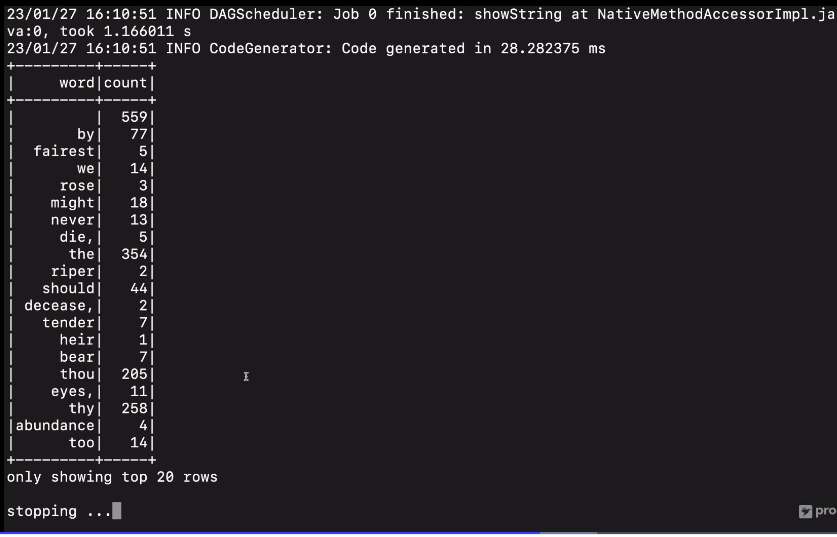
실행 종료가 안되고 대기하는 중.

프린트스키마도 나오는 것을 확인.
스파크 웹 UI를 브라우저로 들어가본다.
SQL 데이터프레임 메뉴가 있음. 전체 애플리케이션에서 날린 쿼리들을 볼 수 있음
순서별로 잘 나옴
하나의 잡으로 구성되어 있고, 파일 로딩
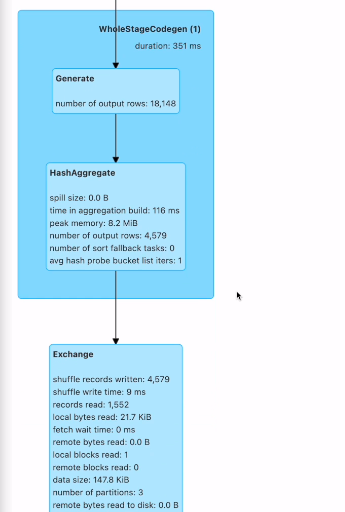
spilit, explode가 내로우 디펜던시라 스테이지 한개에서 작업
그룹바이 - 와이드가 되면서
스테이지가 하나 더 생김
스테이지 별로 보고싶으면
jobs에 들어가서
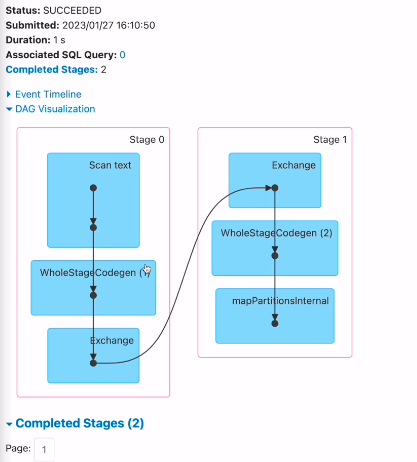
이렇게 두개의 스테이지가 있다는 것을 확인함.
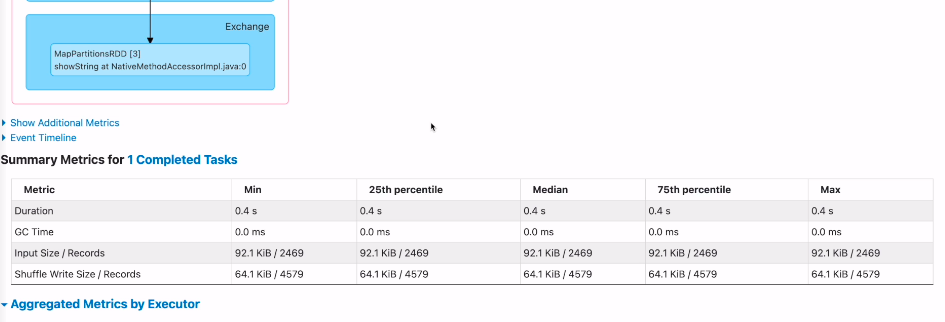
특정 시간이 오래걸린다고하면 보면서 최적화 가능성을 찾을 수 있다.
조인, 브로드캐스트 조인, 웹 UI
바로 스파크 서밋을 통해 실행해본다
spark-summit --master "local[3]" ~~.py
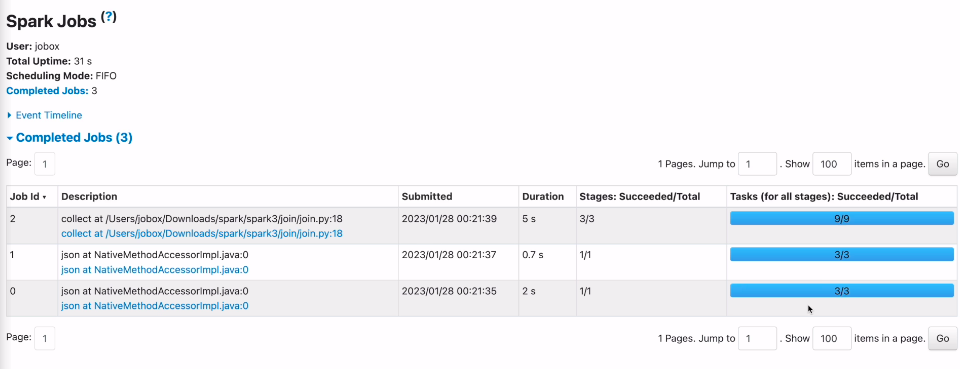
각 스테이지는 3개의 태스크 실행.
3개의 파일 - 3개의 파티션 - 3개의 태스크
json 파일로딩은 바로 액션임. - 읽기전에는 스키마를 모름.
join 에는 3개의 스테이지가 필요. 총 9개의 태스크가 필요했음.
각각의 잡들을 빠르게 본다.
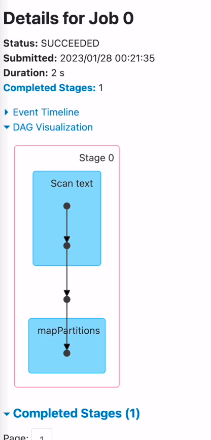
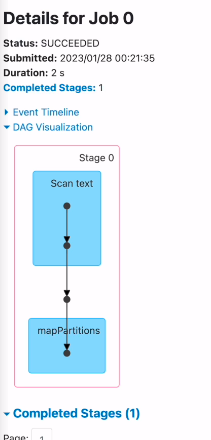
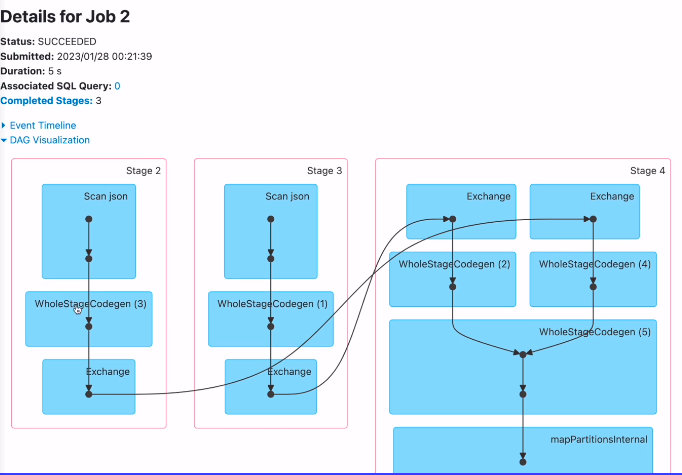
id를 가지고 셔플링을 하고, 마지막 스테이지에서 셔플해준걸 가지고 조인을 수행함.
최종적으로 콜렉트 때문에 결과를 한군데로 모음.
셔플조인의 전형적인 모양.
브로드캐스트도 보도록 한다.
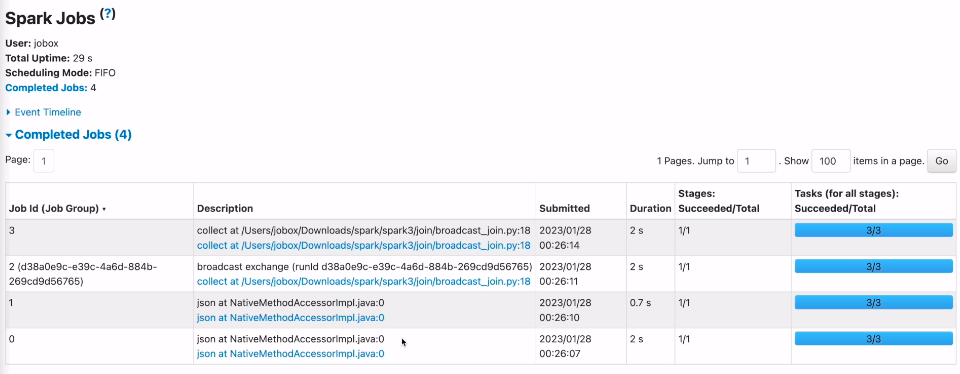
잡 4개가 생김.
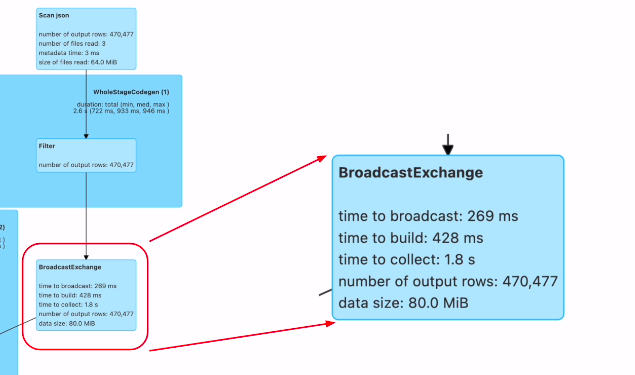
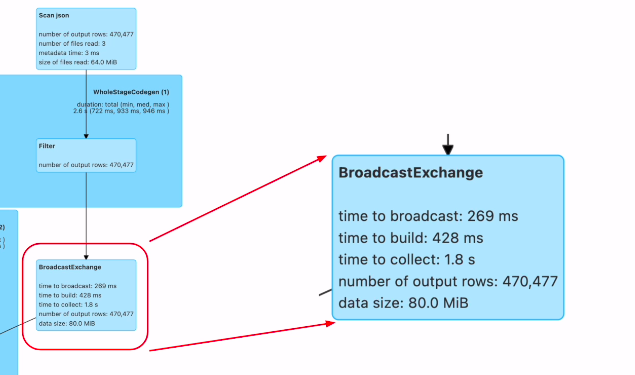
브로드캐스트를 하는 부분이 별도의 잡으로 실행이됨. 브로드캐스트 조인을 하게되면, 대상이되는 데이터프레임이 드라이버로 왔다가 다시 스파크로 가게 됨 (액션이 됨)
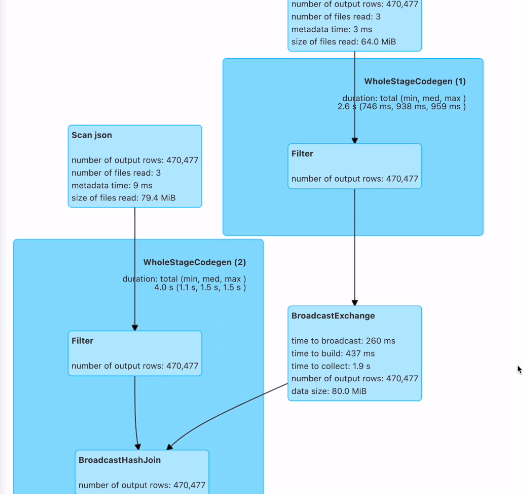
조인 과정을 보면
두번째 데이터 프레임은 브로드캐스트가 되어서 그다음 조인이 이뤄짐. 아까 셔플과는 다름.
