
입력되는 데이터가 얼마나 최적화 포맷으로 있냐에 때라 처리시간, 리소스 양 결정.
파티셔팅 - 지금의 파티션 X
파일시스템의 데이터를 특정 키를 중심으로 나눠서 저장하는 것.

버켓팅, 파일시스템 파티셔닝
두가지 모두 스파크 테이블로 관리, 데이터 저장을 향후 최적화된 방식으로 함으로써, 리소스양, 시간을 단축.
버켓팅- 셔플링을 줄이는게 목적
셔플링? 집계, window, join 때 발생. 자주 사용되는 컬럼들이 있으면, 이런 컬럼들을 미리 저장해둠으로써 이 데이터들이 파티션으로 로딩될 때 셔플링이 최소화되게끔. 지정됨 버킷 수만큼 파티션 수 결정. 조인 할때, 조인대상되는 파티션 수가 맞지 않는다면 또 셔플링 발생. 버켓팅 의미가 없어질 수 있음. 최적화 테크닉이 필요. - 나중에
파일시스템 파티셔닝.
파티션의 개념과 다름. 데이터프레임을 메모리에서 나눠저장하는 단위.
여기서의 파티셔닝은 파일시스템에 저장되는 데이터를 컬럼의 집합으로 나눠서 저장.
특정 키를 중심으로 필터링을 하는 경우가 많다. 면 첨부터 그 키를 중심으로 데이터를 저장함으로써, 로딩, 필터링 오버헤드 줄임.
나눠저장할때 중심 키를 파티션 키라고 하고 하나 이상의 컬럼이 될 수 있음.
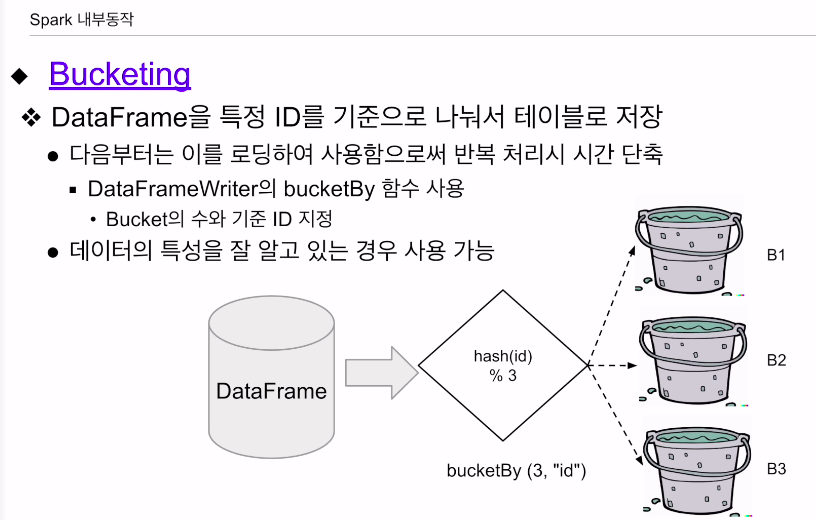
버켓팅
특정 컬럼을 기준으로 스파크 테이블로 저장.
이 때 한번 셔플링이 발생될것임. 이후 다수의 셔플링을 막을 수 있음
bucketBy 함수 사용
버킷의 수와, 기준이 되는 컬럼을 지정. 컬럼의 값을 가지고 해싱을 한 다음 버킷의 수로 나눠서 나머지를 가지고 특정 레코드가 어느 버킷으로 갈지 결정함.
HDFS쪽에 파일이 그 갯수만큼 생길 것임.
데이터 특성을 명확히 이해하고 최적화하기 위해 사용하는 것임.
데이터를 버킷에 나누는 경우, 해시 함수는 데이터를 고유한 숫자(해시 값)로 변환하고, 그 해시 값을 사용해 데이터가 어느 버킷에 속해야 할지 결정합니다. 이 때 해시 함수의 특성 상 동일한 입력값에 대해서는 항상 같은 해시값(따라서 같은 버킷)이 결정됩니다.
스파크 같은 빅데이터 처리 시스템에서는 레코드를 여러 노드로 나누어 처리하기 위해 해시 파티셔닝을 이용합니다. 이 경우, 일반적으로 사용자는 해시 함수를 직접 지정하지 않고, 스파크 내부에서 사용하는 기본 해시 함수를 사용하게 됩니다. 사용자는 몇 개의 파티션으로 데이터를 나눌 것인지만 지정하면 됩니다. 따라서 레코드가 어떤 파티션에 배치될지는 스파크 내부에서 결정되는 것이며, 이는 사용자가 직접 알 수 없는 부분입니다.
파일 시스템 파티셔닝
키를 중심으로 물리적으로 나눠저장
하이브에서 많이 써먹음. - 파티셔닝
로그파일이 있을때 이걸 어떻게 저장하느냐가 읽을 때 큰 문제가 될것임.
로그는 시간단위, 일단위로 기록. 처음부터 그렇게 저장하면 로딩하는데 오버헤드가 줄을것임.
ts를 기준으로 최상위 디렉토리는 연도, 그 밑에 월, 그다음에 일 기준으로 폴더를 만들고, 필요하다고 하면 시간 기준으로 폴더를 만들어서 데이터들을 나누어 저장. 관리하는것이 직관적이기에 로그파일을 많은경우 이렇게 저장함. 스파크 관점에선 데이터를 다시 재정리할 필요도 없고, 누가 만들어놓은 데이터를 external 테이블 형태로 스키마를 매핑해서 처리할 수 있는 것임.
이점. 읽기과정이 최적화. 스캐닝을 안해도 되기 때문. 데이터를 구조를 잡아서 관리를 하면 여러가지가 쉬워짐.
대표적인게 리텐션 정책. 우리는 로그파일을 1년동안 저장. 1년이 지난 날짜의 데이터들을 날리면 됨. 만일 데이터가 이렇게 저장이 되어 있지 않으면 리텐션을 적용하기 위해 다시 읽고 필터링 해서 다시 저장하기에 손해임.
어떤 데이터프레임을 저장하고싶다.
partitionBy를 사용. 데이터프레임 쓸 때만 사용. 키에 맞춰 디렉토리가 생김. 만일 키를 잘못선택하면 엄청난 오버헤드가 생김.

카디널리티 - 가능한 가변수가 낮은 쪽
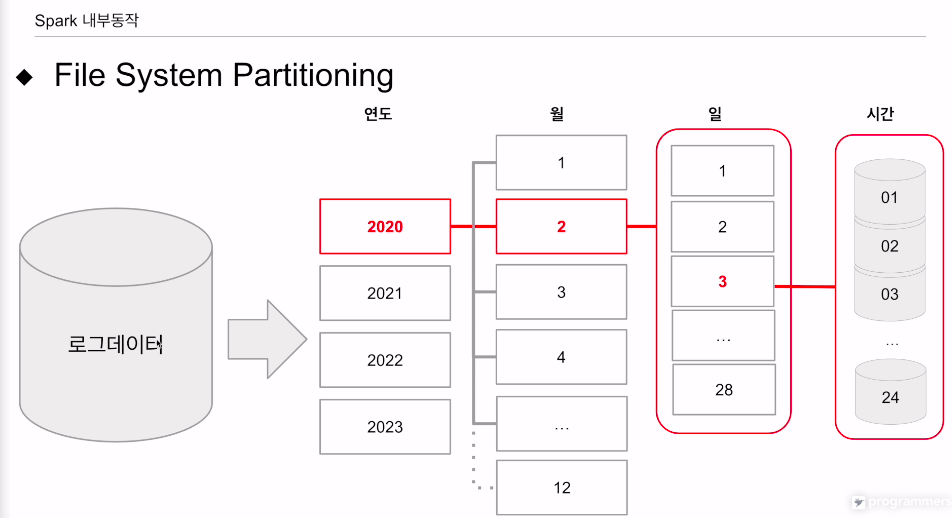
연도 월 일 시간 기준으로 나눠 저장.
프로세싱이 굉장히 편해짐.
두개의 간단한 데모를 통해 어떻게 사용하는지 실습을 해본다
구글콜랩에서 하지 않고, 엑시큐션 플랜을 UI로 보기 위해
로컬스탠드 얼론에서 진행.
스파크세션 열어서
autoBroadcastJoinThreshold, -1
spark.sql.adaptive.enabled, False
두개의 변수를 꺼줌. 최적화를 해버리면 엑시큐션 플랜이 어떻게 도는지 알기 어려워서임.
레드쉬프트 관계된 JDBC 세팅을 함.
그 후.
레드쉬프트 테이블을 불러오고,
inner join을 함. usc, st
여기까지 액션이 3개.
데이터 프레임 로딩,
두번째 데이터프레임 로딩,
세번째 show
이것들을 버켓팅을을 이용

managed table 형태로 bucketBy를 함. 존재하는 경우엔 동작하지 않기에 만일 이 테이블들이 존재하면 삭제하게끔.

두개가 writing이기에 액션이 있음
이후 읽어서 데이터프레임 2개를 만들어 또 조인을 해본다
그럼 두 조인간의 차이는?
1. 앞은 분포가 랜덤함.
2. 오버헤드가 더 적음 세션id를 기준으로 정리했음.
웹 UI에서 결과를 확인해본다.
엑시큐션 플랜이 어떻게 됐는지 본다.
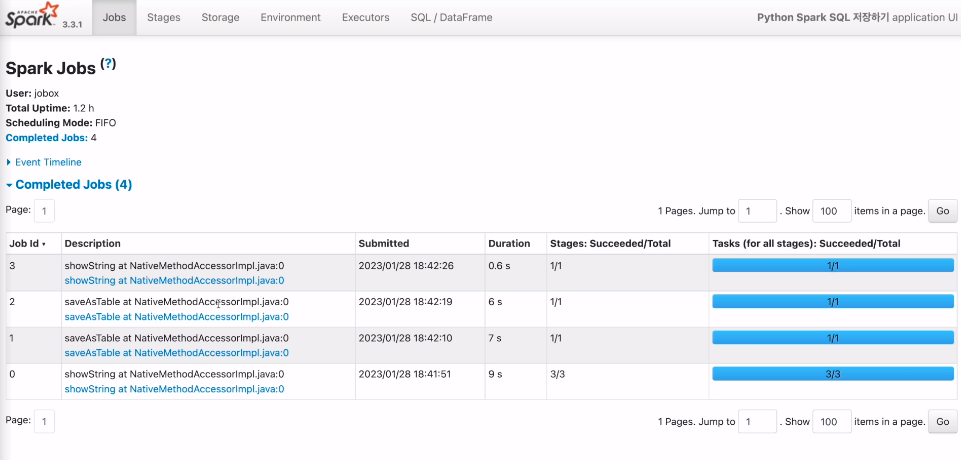
4개의 잡이 생성됨.
첫번째 잡
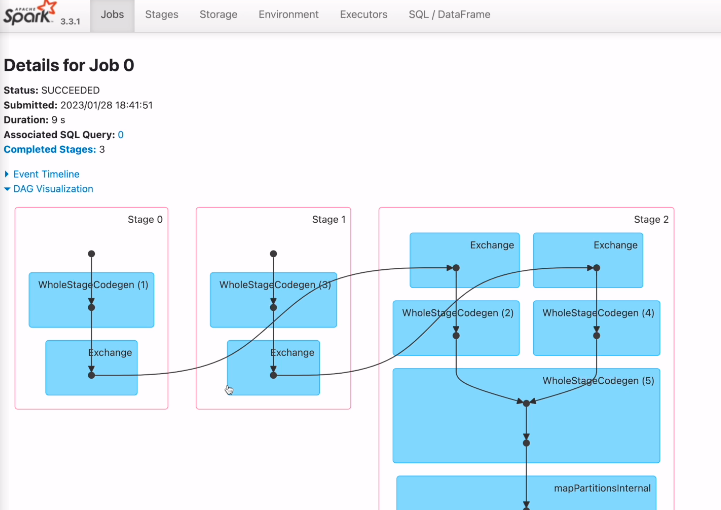
읽어서 조인 후 show
전형적인 셔플 조인 exchange가 있음
두번째 잡
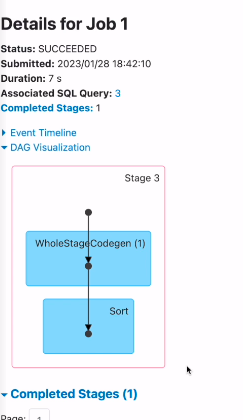
버켓팅을 하면서 스파크 데이터테이블로 저장
세번째 잡
버켓팅을 하면서 테이블로 저장
마지막 잡
버켓팅된 테이블을 로딩해서 조인 후 show
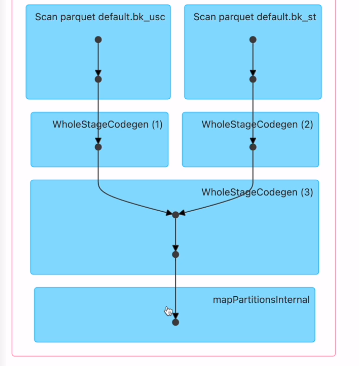
exchange가 없는걸 보임. 셔플링이 없음
HDFS에 저장될 때 어떤 모양을 갖는지 확인해봰다. 로컬모드이기에
spark-warehouse에 저장
/bk_st
/bk_usc
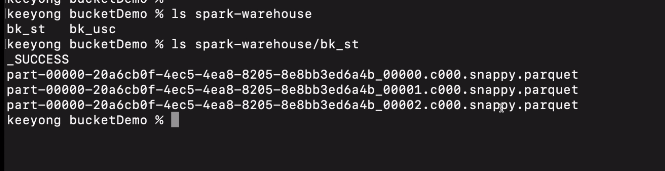
3개의 parquet 파일로 저장.

3개의 버킷으로 저장된걸 확인.
Partitioning
파이4j 설치
스파크세션 오브젝트 설치
하이브서포트 언급.
전에 쓴적있는 애플주식csv 활용
연도와 월을 기준으로 파티션을 만들어서, 스파크 managed table로 저장.

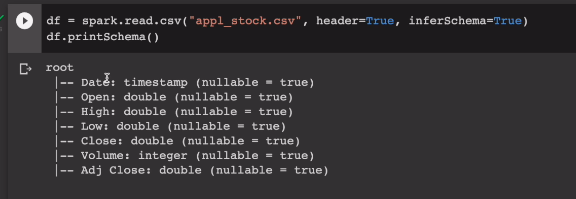
Date 기준으로 새로운 컬럼 만들고 managed로 저장
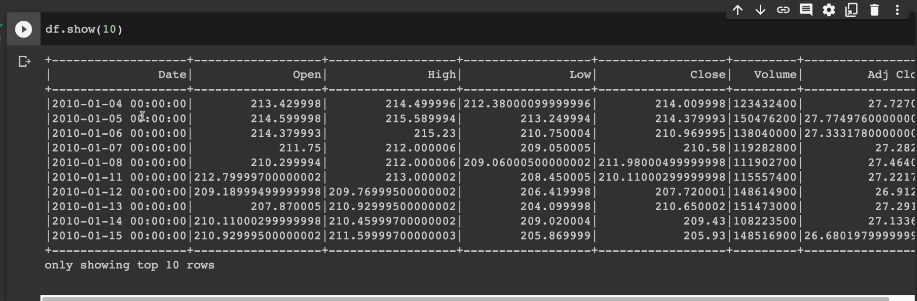
연도와 월을 잘라내서 새로운 컬럼들을 만들 예정.
df = df.withColumn("year", year(df.Data)) \
.withColumn("month", month(df.Date))파티션으로 나눠 저장한다
df.write.partitionBy("year","month").saveAsTable("appl_stock")
파티션을 연도와 월로 저장함.
에러가 남.
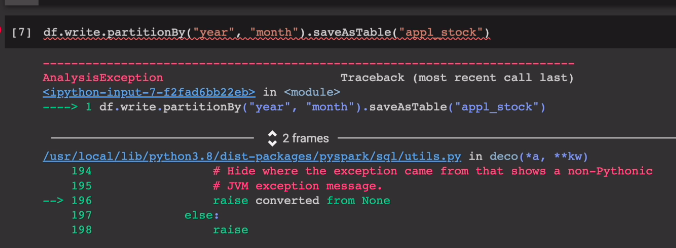
앞에 데모에서 이미 만들어서 오류가 난 것임. DROP도 없는 테이블을 삭제하려고 하면 에러남
spark.sql("DROP TABLE IF EXISTS appl_stock")
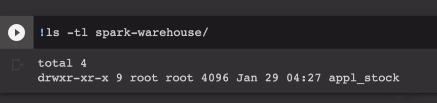
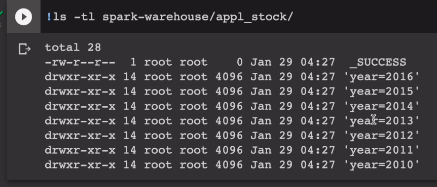
탑 레벨 폴더로는 연도가 있음. year=2016 이런 형태로 폴더가 생김. 나중에 쿼리를 할 때도 사용을 해야함.
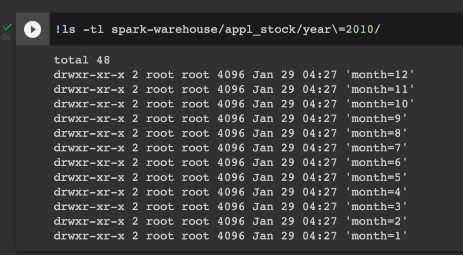
그중 12월을 골라서 들어가본다

파일이 생성된 것을 확인 할 수 있다.
데이터를 읽으려면
df = spark.read.table("appl_stock").where("year=2016 and month = 12')
오버헤드가 없음
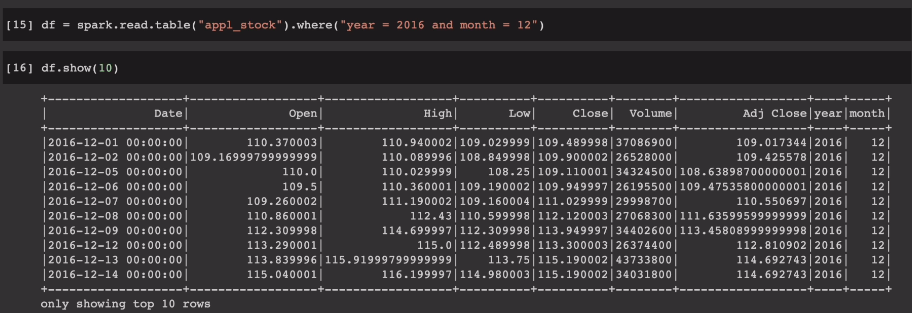
spark.sql("SELECT * FROM appl_stock WHERE year = 2016 and month = 12").show()
동일한 결과를 얻울 수 있음.
약간 추가적으로 파일 관리의 느낌임.
