
맵리듀스 프로그램 실행을 살펴본다
bin 밑에 하둡설치 하고 하둡 커맨드 생김
yarn도 있고 같은 뜻이라 생각하기
jar 파라미터 주고, jar는 키에 해당
jar 파일을 뒤에 주는 것
코드가 들어있는 jar 파일을 지정
코드들 중에 어느 코드를 실행할 것인지 이름을 주고, 예상하는 파라미터를 주면 됨.
하둡 예제프로그램임 wordcount는
첫번째 파라미터는 input 입력. hdfs 디렉토리 안의 모든 파일들의 워드
output 두번째 파라미터. 리듀스의 결과를 출력. 정확히는 디렉토리. 이 디렉토리에 파일들 생성.
hdfs 커맨드를 쓰면서 dfs라는 서브 커맨드 -ls 실제 파일 시스템 관계된 커맨드. 리눅스와 매우 유사. -mkdir 등등.
앞서 우분투 서버, 의사분산모델 하둡 설치함.
맵리듀스를 실행해본다.
하둡에 딸려온 예제프로그램 중 워드카운트 그대로 사용
input 되는 디렉토리를 hdfs상에 만들고 파일을 업로딩 그 워드를 카운팅
결과는 output 출력 디렉토리 지정.
input이 될 폴더를 만들기 전 몇가지를 해야함

하둡 디렉토리로 이동해
hdfs를 사용 유저 퍼미션에 따라 admin, 자기 디렉토리 읽기 쓰기 권한, 다양한 권한 조정이 이뤄짐.
input 디렉토리를 만들 예정인데, 원래는 input 디렉토리를 만들면 될 것 같지만,
bin/hdfs dfs -mkdir input

에러가 남
위에 보면 네임노드, 유저 밑에 이런 폴더가 없음
아까 hdfs를 이니셜라이저만 하고 폴더를 만들지 않았음

이에 폴더를 만들고 서브 폴더. 리눅스의 홈디렉토리를 만듦

이번엔 잘 되는걸 알 수 있음
-ls 해보면

input이라는 폴더가 만들어짐. 내 user/hdoop 밑에 만들어짐.
입력이되는 파일을 하나 로컬에 만들어본다.
vi words.txt를 열어서
예로 설명을
저장을 한다
이 파일을 아까 만들었던 input 디렉토리에 업로드를 한다
-put

hdfs 상의 폴더이름을 지정하면 이동시켜줌.
-ls input으로 목록을 보면

업로드가 잘된게 확인이 됨.
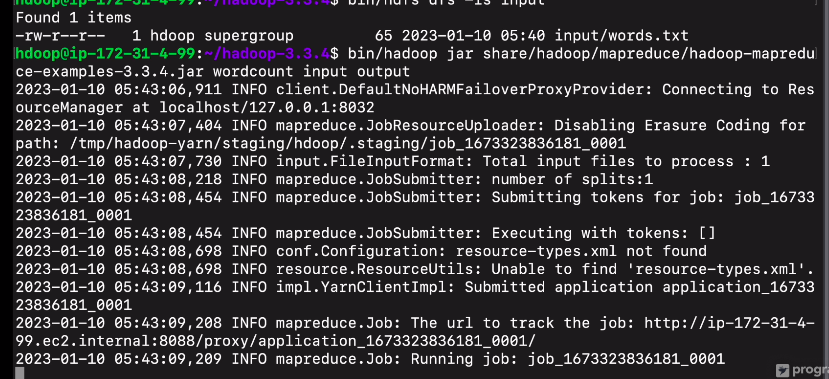
워드카운트 프로그램을 실행해보는데
빈 디렉토리 밑에 보면
hadoop이라는 커맨드가 있음
jar이라는 파라미터를 주고
예제프로그렘 위치

실행되어야 하는 메인 코드 wordcount 지정. jar 파일에 있는 wordcount 프로그램이 어떤 파라미터를 예상? input output
input - hdfs 패스
ouput - 결과 저장될 폴더
이 실행하는 사람의 홈디렉토리를 path로 설정하였음.
/user/hdoop 밑에 input, output
매퍼, 리듀스 뜨고, 지정해던 아웃풋 디렉토리 밑에 저장됨.

셔플링하고, 소팅하고, 리듀스가 100으로 변함.
관계된 통계 정보들 출력
결과를 보기위해
bin/hdfs dfs -ls output

디렉토리 밑에 두개의 파일이 있음
success는 플래그임 성공했다는
실제 내용은 part-r-00000에 들어감
bin/hdfs dfs -cat output/part-r-00000
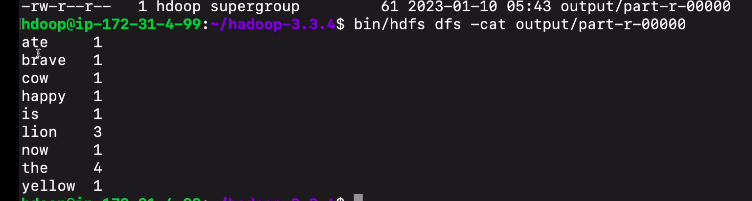
키 단어, 밸류 카운트 형태로 결과가 들어가 있다.
방금 실행시킨 프로그램에서
매퍼로 인풋파일 들어가서, 텍스트 라인을 토큰나이저, 단어별 1식 카운트, 셔플링 해서 리듀서에 보냄. 시스템이 머지를 해서 모든 카운트를 합해 리스트를 만들어냄.
맵 - 리듀스 사이 소팅이 있음
spark에도 동일한 동작 있음
하둡 맵리듀스 데모를 마친다
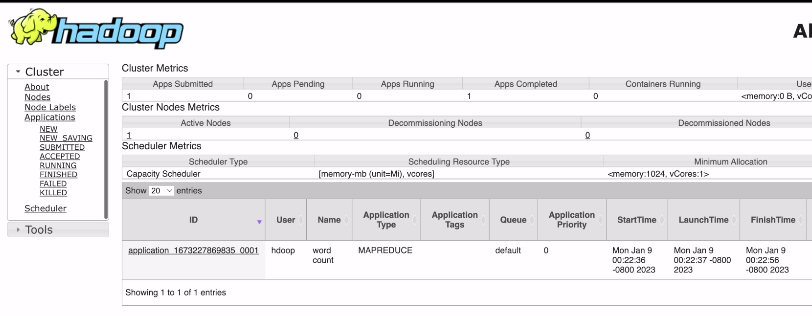
그 결과가 이 안 리소스매니저 UI에서 어떻게 보이는지본다
얀 위에서 앱이 뭐있는지 보인다
저게 워드카운트

맵 리듀스 타입,
의사 분산 모델이라
노드가 1개밖에 없음
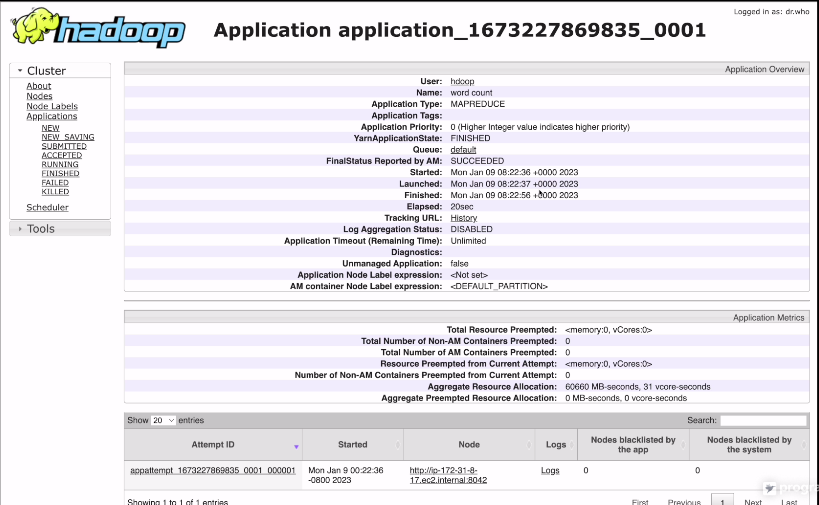
세부정보를 보면
언제 실행, 언제 마무리 등등이 나옴.
몇번 시도를 했는지도 나옴, 재시도 횟수도 나옴
컨테이너가 3개가 들었다는 걸 확인
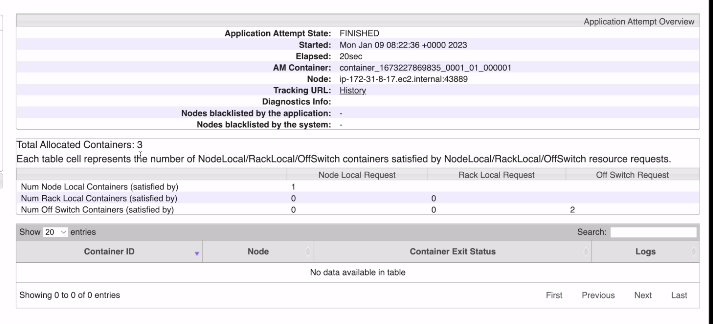
프로그램을 관장하는게 1개
맵리듀스 프로그램이 인풋이 작기에 맵퍼가 하나
리듀스는 디폴트로 1개로 세팅
총 3개의 컨테이너가 사용됨
간단하게 하둡 설치과 맵 리듀스 실행 데모를 마친다
맵리듀스 문제점
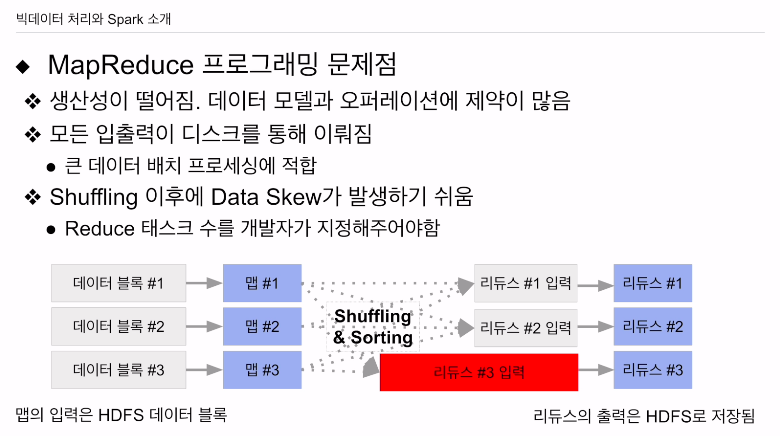
spark도 여전히 갖고 있는 문제가 있음
데이터 프레임 API, 스파크 SQL을 지원해 생산성을 높임.
IO가 디스크로 이뤄짐. 규모가 작은 데이터를 빠르게 처리하는데는 문제가 있음 쓰루풋을 최대화하는데 초점, 로우 레이턴시는 포기
메모리, 디스크를 공용하는 형태로 시스템 구성
마지막 이슈 데이터스큐.
스파크에서도 있는 문제.
데이터 스큐 문제를 해결하는데 대부분 초점.
리듀스의 인풋이 상대적으로 큰것들이 생김.
리듀스가 몇개여야 되느냐 -> 최적화 문제. 시스템이 알아서 못하고 개발자가 매뉴얼하게 설정해줘야 함.
데이터의 패턴이 달라지면 리듀스의 입력의 크기도 굉장히 상이할 수 있는데, 매번 설정할때 예외적인 케이스가 발생할 수 있다는 것이 암시됨.
스파크도 이러한 문제가 있음.
해결하기 위한 솔루션 존재.
hdfs 데이터블럭 -> 맵태스크 하나의 입력. 블록 수만큼 맵 테스크가 만들어짐. (최대한 단순하게 봤을 때) 맵 단에서 들어가는 입력의 크기는 대동소이함. 하지만 셔플링, 소팅이 끝난 후에 리듀스에 입력이 되는 크기는 굉장히 다를 수 있음. 리듀스 태스크 숫자, 어떤 갑을 기준으로 맵이 키밸류 페어를 만들어내냐에 따라도 달라짐. 보면 리듀스 3의 경우 훨씬 처리량이 많음. 여기서 데이터 스큐가 발생. 이 경우 셔플링 소팅을 통해 데이터가 이동을 하는데 데이터 크기에 따라 시간이 걸리게 됨. 리듀스가 출력한 결과가 다시 hdfs에 저장이 됨. 한번 스큐가 생기면 맵이 읽어야할 때도 문제가 생김. 한번 스큐가 생기면 임팩트가 계속 가게됨. (맵리듀스를 여러번 돌려야 하기 때문에)
