
하둡은 1세대 빅데이터 처리기술
스파크는 2세대 빅데이터 처리기술
거의 모든회사들이 쓰는 표준이라 할 수 있다

상용적인 부분은 데이터 브릭스가 주도
자체 분산환경도 있지만, 얀 위에서, 쿠버네티스 위에서도 동작 가능
스칼라로 작성됨
가장 큰 장점: 빅데이터 처리 관련된 다양한 기능을 하나의 패키지에 제공
3.0 써볼 예정
다양한 분산환경 위에서 동작
얀을 가장 많이 씀
얀 위에 앱
스탠드얼론은 개발용 정도
k8s 정도 쓰임
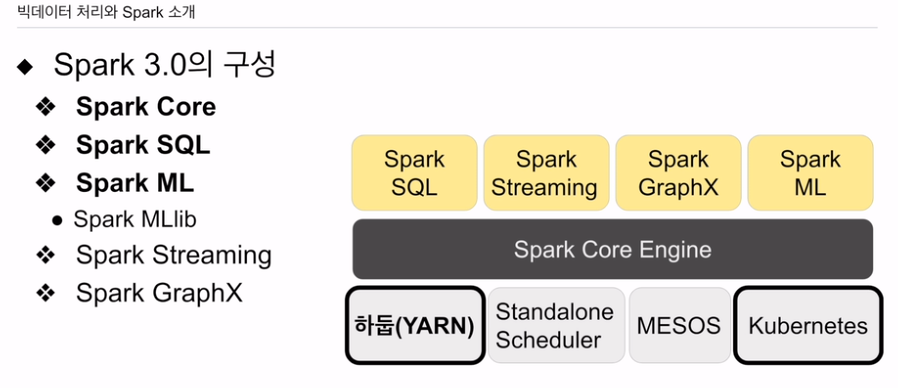
분산 컴퓨팅 시스템. 코어 엔진 위에 SQL 처리기능, 스트리밍, 머신러닝 처리, 그래프 데이터 처리기능이 제공됨. 코어 엔진 데이터프레임 중심으로 오늘강의. SQL도 좀 알아본다.
ML, MLlib
lib rdd 데이터 스트럭쳐 기반/ 없어지는 중.
ml 쓰면 됨.

큰데이터, 쓰루풋은 높음. 로우 레이턴시가 아님.
요즘은 메모리가 부족해지면 디스크도 씀
데이터가 안크면 스파크가 훨씬 빠르게 동작
맵리듀스는 하둡 위에서만
스파크는 다른 분산컴퓨팅 환경 있음. k8s, 메소스
맵리듀스 제약성. 지원하는 데이터 포맷이 키밸류.
스파크는 판다스 데이터프레임 데이터구조 지원. 훨씬 융통성 있음 작업 양도 많음
스파크는 배치처리 외에 다양한 형태 데이터 처리 가능

세가지 스파크 모듈
API
세종류 API
RDD
- 로우레벨, 세밀제어 가능. 너무 로우라 생산성 떨어짐. 많지 않음
데이터 프레임 - 판다스와 개념적으로 동일. 실제에서도 많이 쓰임. 판다스 쓰면
데이터 셋 - 스칼라, 자바 사용 시.
테이블과 같은 구조화된 데이터이고 그걸 통해 어그리게이션, 조인 할때, 스파크 SQL을 사용하는게 직관적이고, 유지보수 좋고, 여러 장점 있음.
언제 이런 API 필요한가?
머신러닝 관계해서 SQL만으로 계산 못하는 피쳐, 유저 정의 함수, frame, set에서 조작할 때. API를 사용해야 함.

sql을 스파크에서 사용 가능케 함.
데이터 프레임을 테이블처럼 사용. 조인을 한다던가 그룹바이를 한다던가. 간단해짐.
데이터 프레임, 셋과같은 API를 통해 할 수도 있지만 코드가 복잡해짐.
SQL로 가능하면 굳이 코딩 노.
가독성 높, 유지보수도 좋음
판다스에도 동일 기능 있음. 프레임을 SQL을 써서 하는게 있음.
하이브가 처음 맵 리듀스 위에서 디스크 기반으로 돌다보니 큰 데이터를 ETL 처리할 땐 좋고, 빠르게 처리할 땐 성능이 나오지 않았음. 얀 위에서 하이브가 다시 작성되면서 태저라는 엔진 위에서 돌아감. 이는 메모리, 디스크 둘다 사용. SQL 기술들을 보면 스파크SQL, 하이브, 프레스토가 시작점 달라도. 결국 다 비슷해짐.
메모리 기반. 빠르다. 로우 레이턴시를 보장한다.
요새는 메모리, 디스크 병용하는 쪽으로 다 가고 있음.
스파크 장점은 하이레벨 api, 스트리밍, 그래프 등 패키지 지원

머신러닝 관련 라이브러리 제공
딥러닝 지원은 없다고 보면 됨.
lib는 RDD 기반
ml은 데이터프레임 기반
lib는 rdd라 생산성이 떨어지고 더이상 업데이트 안됨.
항상 spark.ml을 임포트 하기

머신러닝 관련을 한 장소에서 처리
다른 모듈들 데이터프레임, sql, 다양한 소스들을 로딩해 전처리가 가능.
이 모델을 만드는 과정을 파이프라인으로 자동화
서빙도 가능
end to end
사이킷 런과 같이 서버 1대 돌아가는 것과 비교했을 때 차이점 있음

스파크를 사용해 대용량 데이터를 활용해 배치처리, API 쓰던지, SQL을 사용하는게 일반적
스트림 데이터 처리. 스파크 스트림 사용. 대용량 훈련 데이터로 훈련, 배포 구현
세번째 예는 나중에 ml 설명 때 설명
배치 프로세싱 - ETL, ELT
피쳐를 미리 계산, 데이터 생성될 때 바로 계산 가능
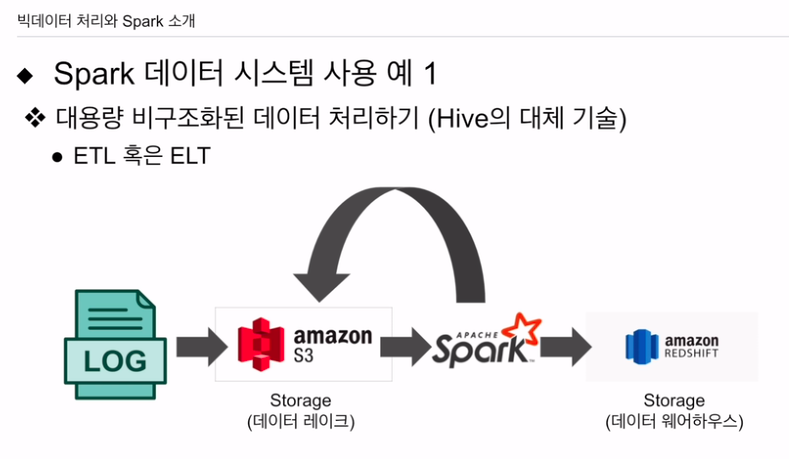
하이브나 프레스토를 대체하는 용도
로그데이터가 있고 aws라면 s3에 로그데이터
이 스토리지를 (데이터 레이크라고도 볼 수 있다) 스파크 같은 기술로 SQL이 될 수도 있고 데이터 프레임이 되고, 읽어다 프로세싱, 정제해서 데이터 웨어하우스에 적재. 아니면 다시 S3에 쓰는 용도
ETL, ELT 하이브나 프레스토 써도 됨.
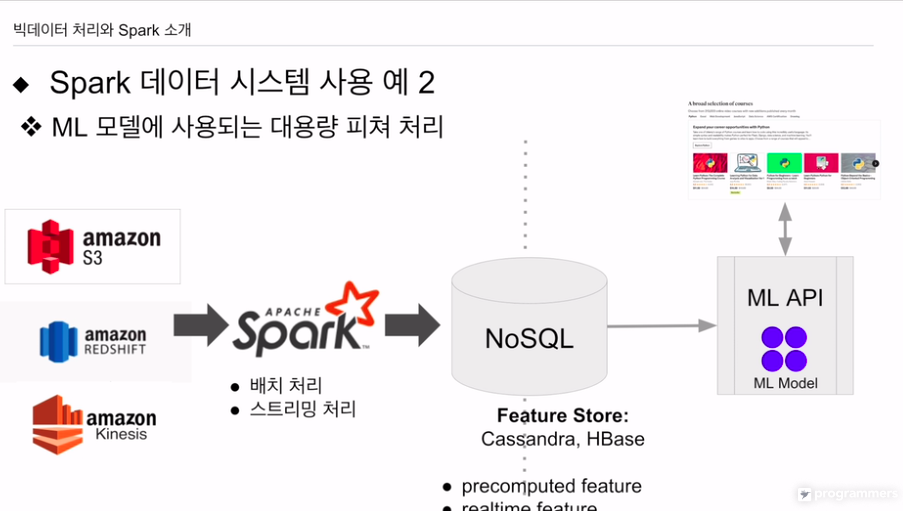
유데미에서도 사용
로그인 하면 강의 추천이 뜸
우리가 기록을 갖는 사용자면 과거 행동에서 피쳐를 계산, 지금 들어와서 무슨행동했는지 계산하여 리얼타임으로 피쳐 계산. 뒤에서 별도 시스템이 계산하는데 이걸 스파크ml을 사용함
다양한 소스 정보를 가져다 sql 데이터 프레임 사용하여 집계하여 피쳐쳐를 만들고 nosql에 저장함. 데이터가 작으면 redis 사용
카프카, 키네시스로 기록 다른 정보와 조인. 스파크 스트리밍으로 피쳐 계산. nosql에 저장.
추천모델 API 부를 때 파라미터로 넘어감.
실제로 많이 쓰이는 패턴임.

