학습목표
- AWS - SQL 구현 완료
- (venv)pyhton - SQL 연결
- 나스닥 API로 금, 은 데이터 로드
- 장고 모델 구현
- MaterialsModel
- MaterialsPriceModel - 모델에 데이터 적재
분업
- 전처리
- 시각화
학습내용
AWS 구현하여 mySQL과 연결.
이유:
나스닥에서 데이터를 내려받은 후 이 데이터를 정적으로 관리하고자 함. 사용자가 요청이 들어올 때마다 API로 연결해서 메모리 상에서 구현할 수도 있지만 수천 수만의 유저가 요청을 한다면 매번 나스닥 API에서 전체 금, 은 데이터를 내려받는 것은 비효율적이라는 생각. 또한 지난 금, 은 데이터는 정적으로 시간이 지나도 변하지 않는 데이터이며, 가치를 상실하지 않음. 이에 한번의 작업을 통해 데이터를 mySQL에 저장하고 이를 AWS에 업로드하여 어디서든 이 적재된 데이터를 사용하고자 함.
AWS 계정 생정 후
mySQL 워크벤치에서
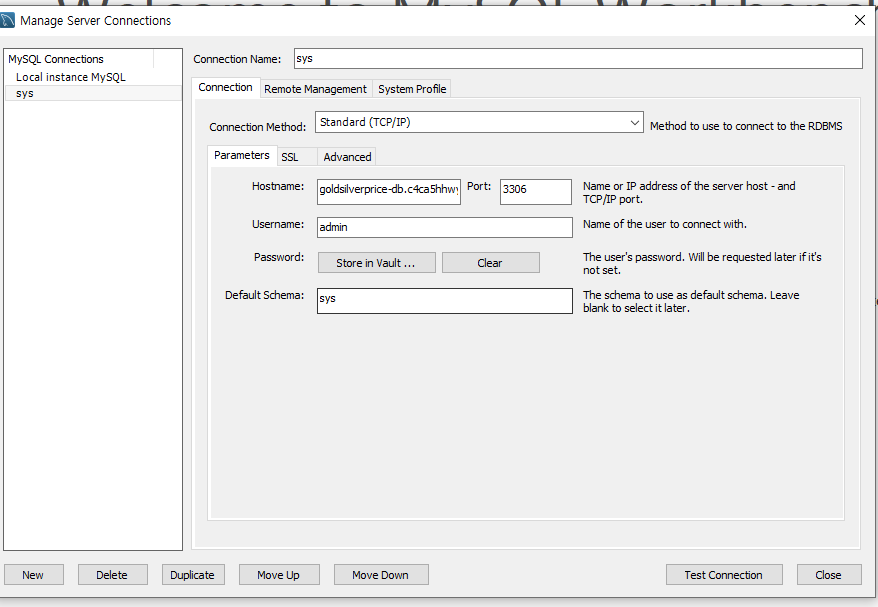
이렇게 별도로 생성함.
비밀번호만 따로 비공개인줄 알았는데, 호스트네임도 숨기는 것이 좋다는 팀원분의 의견이 있었음.
저렇게 mySQL 워크벤치에 AWS와 연결을 하고
python 가상환경에서 장고 프로젝트 (config)를 생성 후에 configuration.py를 생성하여 저 aws 관련된 값을 제공하였음.
(venv)pyhton - SQL 연결
서버와 연결된 SQL을 python 장고에 접근시키기.
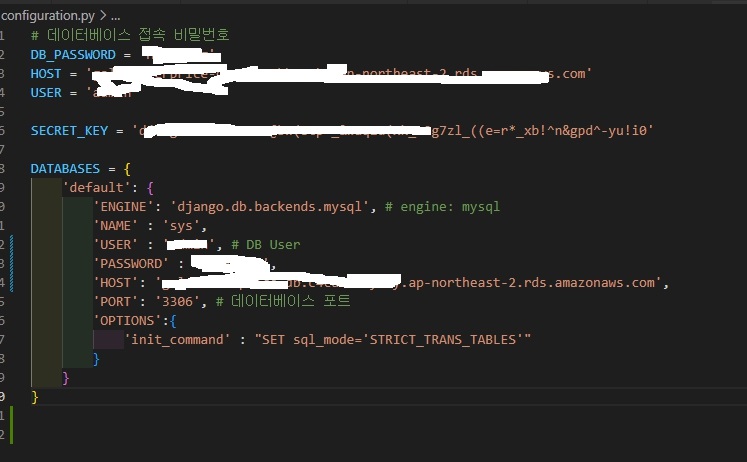
팀원분의 의견으로 보통 저런 파일은 .env로 생성하여, 값은 은닉한 뒤에 configuration.py 폴더에서 그 값을 불러오는 것으로 비공개 할 수 있다고 함.
setting.py로 넘어가
import configuration
from pathlib import Path
import pymysql
pymysql.install_as_MySQLdb()pymysql은 장고에서 모델을 저장할 때에 데이터베이스 서버로 넘기기 위해서임.
# SECURITY WARNING: keep the secret key used in production secret! SECRET_KEY = configuration.SECRET_KEY 기타 비밀키도 넘겨줘야 함.
DATABASES = configuration.DATABASES 이렇게 설정해주면 db.sqlite3를 사용하지 않고 configuration에 지정된 값으로 데이터베이스를 연결함.
한김에 urls.py에서 path('PriceDashBoard/', include(PriceDashBoard.urls.py),
설정함.
나스닥 API로 금, 은 데이터 로드
GetAPI.py 로 이동
import os
import django
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'config.settings')
django.setup()현재 장고에서 인식이 안돼서 구글링으로 위처럼 코드를 써서 장고에서 인식할 수 있게함.
import nasdaqdatalink as ndl
나스닥 라이브러리 설치
# DB -> 최신 날짜가 존재하면 굳이.. 안가져와도되는 분기 (1)
# 1. query로 latest_date를 확인한다
# 2. Datetime 모듈 이용하여 오늘 날짜에 해당하는 데이터가 있는지 확인
# 3. API에서 추가가 되었다면 insert
# 4. 없다면 pass
# 제일 시간 순서대로 저장되어있다고 가정 (최신데이터의 날짜) == 오늘 날짜
# 아래가 (2)
# MYSQL DB -> 적재 (3)
뭔가 작업을 하기 전에 팀원분께서 저렇게 순서를 지정해주셨는데 논리적인 접근이라 생각되었다.
def get_price_data(item_name, start_date='2013-01-01'):
"""원자재 이름으로 가격 정보를 가져오는 함수"""
item_name = item_name.upper()
# 전체 가격 데이터를 가져옴
# 2013-01-01부터 최신까지
price_data = ndl.get(f'LBMA/{item_name}', start_date=start_date)
# 원자재 종류에 따라 추출할 데이터 columns
if item_name == 'GOLD':
price_data_from_2013 = price_data[['USD (PM)']]
price_data_from_2013.fillna(method='ffill', inplace=True)
price_data_from_2013.rename(columns={'USD (PM)' : 'USD'}, inplace=True)
else:
price_data_from_2013 = price_data[['USD']]
price_data_from_2013.fillna(method='ffill', inplace=True)
return price_data_from_2013- item_name = 우리는 gold, silver를 필요로 함.
- start_date를 기본변수로 2013-01-01로 설정하여 약 10년치의 데이터를 가져온다.
- 이후 데이터를 추가로 적재해야될 필요가 있을 경우, 위 메소드를 재사용한다.
price_data = ndl.get(f'LBMA/{item_name}', start_date=start_date)
ndl.get함수로 문자열식으로 집어넣으면 해당하는 값을 가져와준다. start_date로 추출 시작 날짜 설정.
판다스 데이터 형으로. 열은 price_data[['USD (PM)']]으로 추출.
price_data_from_2013.fillna(method='ffill', inplace=True)로 method='ffill'은 결측치 발생시 그 전=값으로 채워넣음. inplace=True는 DB에 직접 적용.
.rename(columns{'USD (PM)' : 'USD'}, inplace=True) 로 이름 변경.
return으로 데이터 프레임 반환.
장고 모델 구현
class MaterialsModel(models.Model):
material_name = models.CharField(max_length=200)
def __str__(self):
return f'{self.material_name} info'
class MaterialsPriceModel(models.Model):
material_name = models.ForeignKey(MaterialsModel, on_delete=models.CASCADE)
date = models.DateField()
price = models.FloatField()
def __str__(self):
return f'날짜: {self.date} 원자재: {self.material_name} 가격: {self.price}'
모델부는 다소 간단하다. 금, 은 등 원자재 이름을 담는 MaterialsModel 테이블과 각 이름의 id를 ForeignKey로 하는 MaterialsPriceModel 테이블이 있다. 내에는 금, 은을 지정하는 id값 필드, 날짜 필드, 가격 필드로 구성되어 있다.
모델에 데이터 적재
최초 비어있는 모델에 데이터를 일괄적으로 bulk 한다.
LoadPriceData_To_DB로 이동
import pandas as pd
from PriceDashBoard.models import *
from GetAPI import get_price_data
from django.db import transaction모델, API 수집 모듈, 그리고 이를 가공할 pandas, transaction
"with transaction.atomic()"은 Django 웹 프레임워크에서 데이터베이스 트랜잭션을 사용하는 코드 블록입니다. 이 코드 블록 내에서 실행된 모든 데이터베이스 쿼리는 하나의 트랜잭션으로 묶이게 되며, 이 중 어느 하나라도 실패하면 전체 트랜잭션을 롤백합니다. 이를 통해 데이터의 일관성과 무결성을 보장할 수 있습니다.
상당히 중요한 개념인 것 같다. 이 역시 팀원분께 배웠다.
price_data_list = []
for index, row in price_dataframe.iterrows():
price_data = MaterialsPriceModel(material_name=material_id,
date=index,
price=row['USD'])
price_data_list.append(price_data)
MaterialsPriceModel.objects.bulk_create(price_data_list)price_dataframe은 get_price_data에서 리턴된 데이터 프레임. .iterrows()를 하면, index, 이를 제외한 나머지 레코드가 출력됨. 각 열의 이름도 갖고 있음. 아까 ndl.get을 하면 1열인 date가 index로 자동 지정. price_data_list에 원소가 MaterialsPriceModel인 값들을 한번에 집어넣음.
전처리
import os
import sys
from django.core.files import File
sys.path.append(os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__)) + '/app')))
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'config.settings')
import django
django.setup()
from PriceDashBoard.models import MaterialsPriceModel, MaterialsModel
import pandas as pd
import numpy as np
def data_processing_feature(df):
df['20MA'] = df['price'].rolling(window = 20).mean()
df['60MA'] = df['price'].rolling(window = 60).mean()
df['120MA'] = df['price'].rolling(window= 120).mean()
df['200MA'] = df['price'].rolling(window= 200).mean()
df.dropna(inplace=True)
upper_20 = np.where(df['price'] > df['20MA'], 1, 0) # 1 = 매수, 0 = 매도 signal
upper_60 = np.where(df['price'] > df['60MA'], 1, 0) # 1 = 매수, 0 = 매도 signal
regular_array = np.where((df['20MA'] > df['60MA']) & (df['60MA'] > df['120MA']) & (df['120MA'] > df['200MA']), 1, 0)
df['upper_20'] = upper_20
df['upper_60'] = upper_60
df['regular_array'] = regular_array
df.drop(['20MA','60MA','120MA','200MA'], axis=1, inplace=True)
return df
def data_preprocess(material_id):
"""
데이터 전처리 함수
parameter = material_id (model에 들어간 원자재 id)
return = 원자재 id, 가격, 분석지표(매수=1, 매도=0)들을 담은 JSON file
"""
# queryset
qs = MaterialsPriceModel.objects.filter(material_name_id=material_id)
data = pd.DataFrame.from_records(qs.values())
data.drop('id', axis=1, inplace=True)
data.set_index('date', inplace=True)
data = data_processing_feature(data)
result_json = data.iloc[-1].to_json(orient='columns')
print(data.iloc[-1].to_json(orient='columns'))
return result_json
# 최종 목적
# JSON 뱉어내는 것
# {'date' : 2023-04-28, '분석1':1, '분석2':1, '분석3':0}저 상단에 sys.path는 앱 폴더 내에 현 파일을 생성했음에도 불구하고, 장고에서 인식이 안되어 구글링으로 달았음. 현재는 잘 동작함.
이동평균선을 이용한 매수/매도 여부를 1, 0으로 반환
이를 위한 20선, 60선, 120선, 200선을 생성(선택일 기준으로 xx일 전까지의 평균)
df['price'].rolling(window = 20).mean() rolling과 window를 사용하면 그
이후 넘파이 조건문인 np.where(df['price'] > df['20MA'], 1, 0)
이동평균은 rolling 함수를 활용하여 계산하며, 이를 통해 매수/매도 신호를 생성하는데 사용되는 upper_20, upper_60, regular_array 변수를 생성
마지막으로 이동평균 관련 컬럼들은 삭제
data_preprocess 함수는 material_id를 parameter로 받아 해당 id에 해당하는 MaterialsPriceModel instance queryset을 받아 데이터프레임으로 변환
이후, data_processing_feature 함수를 사용해 데이터프레임을 전처리하고, 가장 최근의 데이터만 추출하여 JSON 형태로 변환한 뒤, 이를 반환
최종적으로, data.iloc[-1].to_json(orient='columns') 코드를 통해 가장 최근의 데이터를 JSON 형태로 변환
테스트
unittest를 사용하면, 실제 DB에는 적용되지 않는줄 알았는데, 아니었다.
사고를 쳤다. models.object.create, delete를 하면 실제 데이터의 값의 변형이 생긴 것이다.
이걸 모르고 test 케이스에 모델을 생성하고 지우는 작업을 했었다.
수정 전
from django.test import TestCase
from GetAPI import get_price_data
from Get_Latest_Date_From_DB import bulk_data_after_latest_date
from LoadPriceData_To_DB import bulk_price_data
from datetime import datetime, timedelta
from PriceDashBoard.models import MaterialsModel, MaterialsPriceModel
import pandas as pd
import unittest
class GetAPITest(unittest.TestCase):
def test_get_price_data(self):
# 데이터를 dictionary 형태로 정의합니다.
data = {'Date': ['2013-01-02'], 'USD': [1693.75]}
# 데이터프레임을 생성합니다.
df = pd.DataFrame(data)
# 인덱스를 'Date' 열로 지정합니다.
df.set_index('Date', inplace=True)
df.index = pd.to_datetime(df.index)
# 컬럼 이름을 'USD'로 변경합니다.
df.columns = ['USD']
output = get_price_data("gold")
print(output.index)
print(df.index)
print(output.columns)
print(df.columns)
#처음 시작이되는 날짜 인덱스의 레코드와 비교
self.assertTrue(output.head(1).equals(df))
class LoadPriceDataToDBTest(unittest.TestCase):
def setUp(self):
self.data = {'Date': ['2013-01-02'], 'USD': [1693.75]}
self.df = pd.DataFrame(self.data)
self.df.set_index('Date', inplace=True)
self.df.index = pd.to_datetime(self.df.index)
self.df.columns = ['USD']
def test_True_bulk_price_data(self):
# 적재된 모델과, 나스닥에서 받아온 데이터 프레임이 일치하는지 확인.
output = bulk_price_data(self.df,'Gold')
print("아웃풋입니다.",output)
print("데이트입니다.",self.data['Date'])
self.assertEqual(output.date, self.date['Date'])
class GetLatestDateFromDBTest(unittest.TestCase):
def test_is_gold_silver_same_date(self):
after_n = 3
gold_latest = MaterialsPriceModel.objects.filter(material_name_id=1).latest('date')
silver_latest = MaterialsPriceModel.objects.filter(material_name_id=2).latest('date')
print(gold_latest)
print(silver_latest)
# 금, 은 날짜가 같은 날 고시되었는지 확인.
self.assertEqual(gold_latest.date, silver_latest.date)
def test_True_bulk_data_after_latest_date(self):
# 데이터를 불러와야할 경우
today = datetime.datetime.now()
target_date = today - datetime.timedelta(days=4)
# 메소드 수행, 정상수행일 경우 True 반환
self.assertEqual(bulk_data_after_latest_date(),True)
def test_False_bulk_data_after_latest_date(self):
self.assertEqual(bulk_data_after_latest_date(),False)
에서 다시 코드를 전반적으로 수정함.
전체 수정 후
from django.test import TestCase
from GetAPI import get_price_data
from Get_Latest_Date_From_DB import bulk_data_after_latest_date
from LoadPriceData_To_DB import bulk_price_data
from datetime import datetime, timedelta, date
from PriceDashBoard.models import MaterialsModel, MaterialsPriceModel
import pandas as pd
import unittest
class GetAPITest(unittest.TestCase):
def test_get_price_data(self):
# 데이터를 dictionary 형태로 정의합니다.
data = {'Date': ['2013-01-02'], 'USD': [1693.75]}
# 데이터프레임을 생성합니다.
df = pd.DataFrame(data)
# 인덱스를 'Date' 열로 지정합니다.
df.set_index('Date', inplace=True)
df.index = pd.to_datetime(df.index)
# 컬럼 이름을 'USD'로 변경합니다.
df.columns = ['USD']
output = get_price_data("gold")
#처음 시작이되는 날짜 인덱스의 레코드와 비교
self.assertTrue(output.head(1).equals(df))
class LoadPriceDataToDBTest(unittest.TestCase):
def test_True_bulk_price_data(self):
# 적재된 모델과, 나스닥에서 받아온 데이터 프레임이 일치하는지 확인.
yesterday = datetime.now() - timedelta(days=1)
yesterday = yesterday.date().strftime("%Y-%m-%d")
gold_price_data = get_price_data('gold')
silver_price_data = get_price_data('silver')
gold_price_data = gold_price_data.loc[:yesterday]
silver_price_data =silver_price_data.loc[:yesterday]
# 판다스 데이터 프레임을 장고 모델로 변환
gold_data_list = []
gold_material = MaterialsModel.objects.get(pk=1)
for index, row in gold_price_data.iterrows():
price_data = MaterialsPriceModel(material_name=gold_material,
date=index,
price=row['USD'])
gold_data_list.append(price_data)
silver_data_list = []
silver_material = MaterialsModel.objects.get(pk=2)
for index, row in gold_price_data.iterrows():
price_data = MaterialsPriceModel(material_name=silver_material,
date=index,
price=row['USD'])
silver_data_list.append(price_data)
# 어제까지 적재된 Model을 불러옴
queryset = MaterialsPriceModel.objects.filter(date__lte=yesterday)
gold_set = queryset.filter(material_name=gold_material)
silver_set = queryset.filter(material_name=silver_material)
# 각 값을 list 형식으로 Date, value 추출
# GOLD
gold_queryset_dates = list(gold_set.values_list('date', flat=True))
gold_queryset_prices = list(gold_set.values_list('price', flat=True))
gold_data_list_dates = list(price_data.date.date() for price_data in gold_data_list)
gold_data_list_prices = list(price_data.price for price_data in gold_data_list)
self.assertEqual(gold_queryset_dates, gold_data_list_dates)
self.assertEqual(gold_queryset_prices, gold_data_list_prices)
# SILVER
silver_queryset_dates = list(silver_set.values_list('date', flat=True))
silver_queryset_prices = list(silver_set.values_list('price', flat=True))
silver_data_list_dates = list(price_data.date.date() for price_data in silver_data_list)
silver_data_list_prices = list(price_data.price for price_data in silver_data_list)
self.assertEqual(silver_queryset_dates, silver_data_list_dates)
self.assertEqual(silver_queryset_prices, silver_data_list_prices)
class GetLatestDateFromDBTest(unittest.TestCase):
def test_is_gold_silver_same_date(self):
after_n = 3
gold_latest = MaterialsPriceModel.objects.filter(material_name_id=1).latest('date')
silver_latest = MaterialsPriceModel.objects.filter(material_name_id=2).latest('date')
# 금, 은 날짜가 같은 날 고시되었는지 확인.
self.assertEqual(gold_latest.date, silver_latest.date)
일단 모든 테스트가 정상적으로 통과하는 것을 확인하였다. conflict를 방지하기 위해
main 아래에 feature/test라는 브랜치를 생성, 그곳에 push 하였다.
PR(pull request)는 내일 팀원 회의 때 의견 수렴 후 갱신할 예정이다.
쓰다보니 코드가 너무 길어졌다.
특히 DB에 저장된 데이터와, 나스닥에서 받아온 데이터 프레임이 일치하는지 날짜, 가격별로 확인하였고, 원자재 금, 은 별로 확인하였다.
Pandas가 익숙하지 않아 여러번 검색하면서 찾아봤는데, R 때 배웠던 것처럼 나름의 함수 규칙성이 있고 대응할 수 있다는 것을 알았다. 우선 먼저 배운 장고, 장고 rest framework을 익숙하게 쓴 뒤, 다른 업무를 배우면 또 비슷하게 흐름을 이해하기 쉬울 것 같다.
- unittest라도 model에 직접 create, delete를 하면 원본이 변경됨.
이를 막기위해 model의 데이터 생성과, 삭제를 시도하지 않았음. unittest라도 확실하게 DB를 건드리지 않는다는 조건 하에서만 다루기. 오늘 오후에 나도 모르는 사이에 DB가 지워져서 찬우님이 너무 고생하였다. 나도 인지한지 한참이 지난 후라 찬우님도 본인의 하던 view 작업이 안되는 것이었다. 아.. 앞으로 이런 일은 없도록 정말 신중해야겠다.
