학습주제
view 추가 구현
보고서 작성
ppt 작성
학습내용
지난 작업 test 구현
모듈 별 class로 테스트 클래스 작성. 세부적으로 메소드 별로 테스트 메소드 정의
class GetAPITest(unittest.TestCase):
def test_get_price_data(self):
# 데이터를 dictionary 형태로 정의합니다.
data = {'Date': ['2013-01-02'], 'USD': [1693.75]}
# 데이터프레임을 생성합니다.
df = pd.DataFrame(data)
# 인덱스를 'Date' 열로 지정합니다.
df.set_index('Date', inplace=True)
df.index = pd.to_datetime(df.index)
# 컬럼 이름을 'USD'로 변경합니다.
df.columns = ['USD']
output = get_price_data("gold")
#처음 시작이되는 날짜 인덱스의 레코드와 비교
self.assertTrue(output.head(1).equals(df)) 단순히 데이터 프레임 형식을 가진 데이터 레코드 1개와, 서버에 적재된 값을 변수 output으로 참조하여 마지막 값과 비교하는 테스트이다. 보기에 간단한 코드였지만 pandas를 모르는 나로썬 상당한 시행착오가 있었다.
self.assertTrue(output.head(1).equals(df))
현재 배운 testcase는 assertEqual, assertTrue라. 이걸 최대한 활용하는쪽으로 하몄다.
처음 self.assertEqual(output.head(1), df)이런식으로 하였는데, 잘 안되었다. ndl.get을 하게되면 인덱스로 1번째 열값인 date를 갖고, 열은 USD 열 한개만 가져오게 되어있다. 사실상 열은 1개, 인덱스 1개. 처음 이 개념도 몰라서 헤맸다.
assertEqual은 값, 데이터 형식이 모두 같아야 같다고 해준다. 일단 head(1)을 했는데도 인식이 잘 안되어 판다스 내부모듈을 이용한 output.head(1).equals(df) 로 서로 비교하고 불린 값을 리턴하게 한다.
class GetLatestDateFromDBTest(unittest.TestCase):
def test_is_gold_silver_same_date(self):
after_n = 3
gold_latest = MaterialsPriceModel.objects.filter(material_name_id=1).latest('date')
silver_latest = MaterialsPriceModel.objects.filter(material_name_id=2).latest('date')
# 금, 은 날짜가 같은 날 고시되었는지 확인.
self.assertEqual(gold_latest.date, silver_latest.date)
프로젝트 진행 당시엔 나스닥 데이터의 금, 은 데이터가 같은날 고시된다고 가정하고 진행하였으나, 추후 각 데이터의 고시 날짜라던가 누락이 있을 경우, 그 데이터만 확인하고자 위의 테스트 코드를 구현하였다. 지금 프로젝트는 금, 은 중 아무 날짜라도 최신일 경우 작동하지 않는 에러가 있음.
# 데이터가 기록된 최신 날짜
latest = MaterialsPriceModel.objects.last()
latest_date = latest.date금, 은 중 하나만 최신데이터가 들어오면 다른 하나만 있는지, 없는지 체크가 되지 않음.
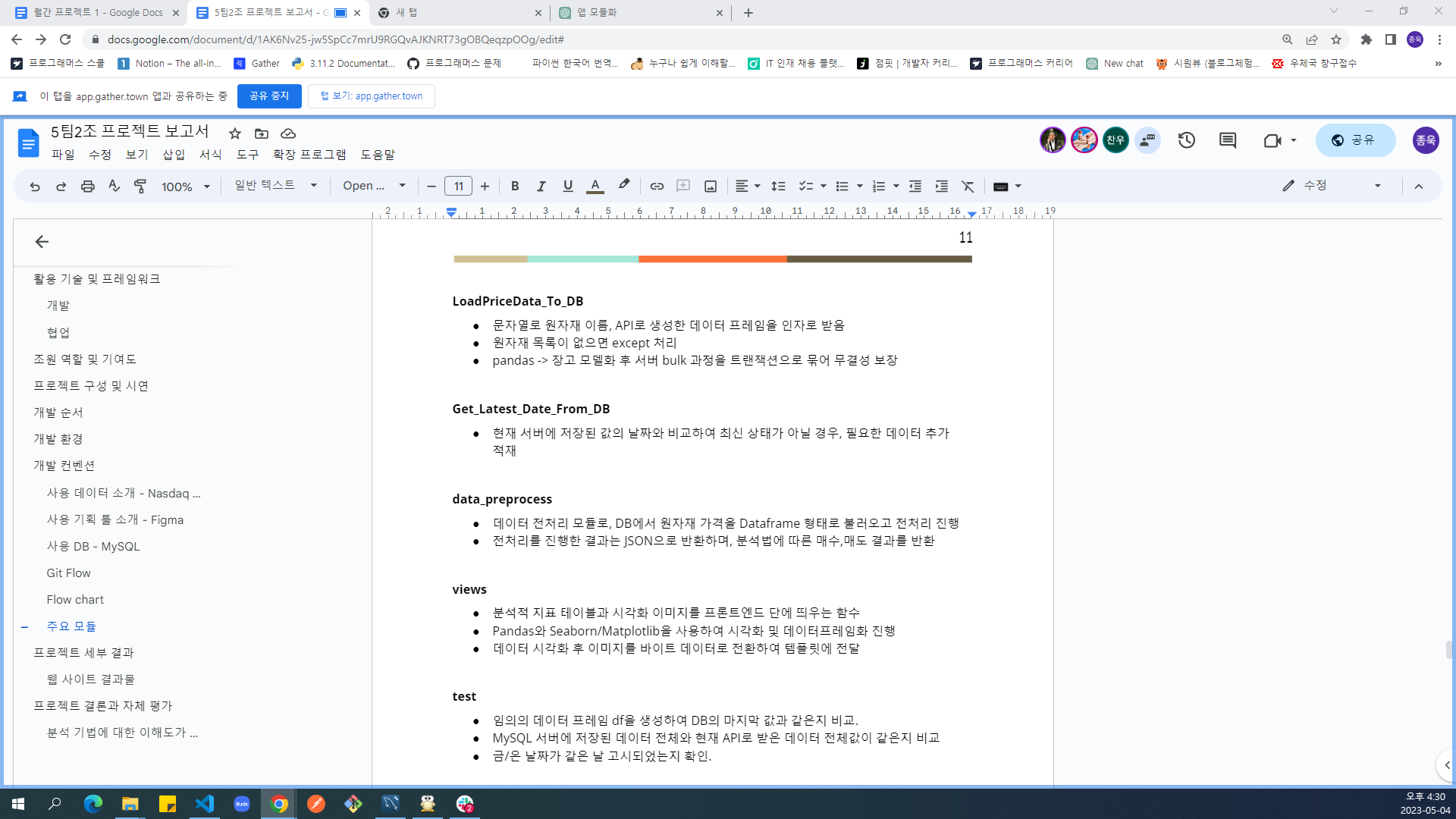
class LoadPriceDataToDBTest(unittest.TestCase):
def test_True_bulk_price_data(self):
# 적재된 모델과, 나스닥에서 받아온 데이터 프레임이 일치하는지 확인.
yesterday = datetime.now() - timedelta(days=1)
yesterday = yesterday.date().strftime("%Y-%m-%d")
gold_price_data = get_price_data('gold')
silver_price_data = get_price_data('silver')
gold_price_data = gold_price_data.loc[:yesterday]
silver_price_data =silver_price_data.loc[:yesterday]
# 판다스 데이터 프레임을 장고 모델로 변환
gold_data_list = []
gold_material = MaterialsModel.objects.get(pk=1)
for index, row in gold_price_data.iterrows():
price_data = MaterialsPriceModel(material_name=gold_material,
date=index,
price=row['USD'])
gold_data_list.append(price_data)
silver_data_list = []
silver_material = MaterialsModel.objects.get(pk=2)
for index, row in gold_price_data.iterrows():
price_data = MaterialsPriceModel(material_name=silver_material,
date=index,
price=row['USD'])
silver_data_list.append(price_data)
# 어제까지 적재된 Model을 불러옴
queryset = MaterialsPriceModel.objects.filter(date__lte=yesterday)
gold_set = queryset.filter(material_name=gold_material)
silver_set = queryset.filter(material_name=silver_material)
# 각 값을 list 형식으로 Date, value 추출
# GOLD
gold_queryset_dates = list(gold_set.values_list('date', flat=True))
gold_queryset_prices = list(gold_set.values_list('price', flat=True))
gold_data_list_dates = list(price_data.date.date() for price_data in gold_data_list)
gold_data_list_prices = list(price_data.price for price_data in gold_data_list)
self.assertEqual(gold_queryset_dates, gold_data_list_dates)
self.assertEqual(gold_queryset_prices, gold_data_list_prices)
# SILVER
silver_queryset_dates = list(silver_set.values_list('date', flat=True))
silver_queryset_prices = list(silver_set.values_list('price', flat=True))
silver_data_list_dates = list(price_data.date.date() for price_data in silver_data_list)
silver_data_list_prices = list(price_data.price for price_data in silver_data_list)
self.assertEqual(silver_queryset_dates, silver_data_list_dates)
self.assertEqual(silver_queryset_prices, silver_data_list_prices)
GetAPITest의 경우 1개의 값만 비교하여 단순한 서버 -> SQL 저장 여부만 확인했다면. LoadPriceDataToDBTest(unittest.TestCase):는 현재까지 저장되어 있는 모든 데이터와, 현재를 기준으로 나스닥 서버에 저장되어 있는 JSON 값이 일치하는지 확인한다. 데이터가 매우 클 경우 소요되는 시간이 많아 무식한 방법일 수 있으나, 하나라도 누락된 값이 있다면 찾아낸다는 점에서 정밀 검사라는 생각이 되었다. 인덱스 별로 비교하기에 시간 복잡도는 레코드의 행 수에 비례한다. O(n).
우선 두 원자재를 나스닥 API로 불러온다. datatype은 pandas dataframe이기에 models의 쿼리셋형태와 비교가 안된다. 이를 맞춰주기 위해 models 타입과 대응시키기 위해. 반복문을 돌려서 list를 model을 요소로 갖게 한다.
그 후 ChatGPT의 힘을 빌려 리스트에서 각 요소 date, price를 추출함.
model도 각 요소를 추출함.
그 후 assertEqual에서 각 데이터 리스트 비교.
처음에 ChatGPT는 추출한 집합으로 set을 권하였으나, set은 순서가 없고, 중복이 없는 집합이라 부적절함. 우리는 순서, 중복을 필요로 하기에 list로 변경함.
확실히 어떤 기능을 필요로 하는건 알겠는데 이걸 코드로 구현하기가 난해한 경우가 있다. 이걸 ChatGPT의 도움을 받으면 쉽게 해결할 수 있었다. 그리고 나 같은 경우 해설지를 외워서 써먹는 게 더 낫겠다는 생각이 들었다. 어찌되었던 어느정도 몸에 익은 코드 작성이 있는게 앞으로 팀프로젝트에서도 괜찮을 것 같다는 생각을 했다.
프로젝트
성일님의 view 추가.
내 test 코드 Github의 git flow 정책에 따라 feature/test로 브랜치 작성 후 push. 팀원분들께 PR 요청함.
google docs로 내 드라이브에 공유폴더 생성 후 공동작업.
초안 완성.
Figma를 활용하여 다양한 시각적 표현 구현함
https://www.figma.com/file/HMS0JUEo4HUrlLkebDYxF8/Devcourse_5team_2?node-id=0-1&t=Bzl4MsSDYLF4u89N-0
보고서를 작성하다보니 기존에 작성되었던 코드를 다시 읽어보게 되고, 어떤 내용을 담아야 필요한 내용만 전달할 수 있을 지 고민할 수 있는 좋은 기회라 생각된다. 어떤 프로젝트를 완성해도 다른 부서 내지는 유관 부서에게 우리의 프로젝트가 얼마나 괜찮은 지 알릴 수 있는 방법은 보고서, ppt라고 생각이 된다. 오늘 중으로 ppt도 완성 예정.
아직 발표자는 미선정. 다른 분들이 선호하지 않으면 내가 해도 큰 상관은 없을 것 같다.
문제
나스닥 JSON 데이터를 보여주려고 로그인을 하였는데, 저번부터 로그인이 안되는 현상 발생. 원인을 모르겠음.
models.create, delete을 쓰면 직접 모델 데이터베이스에 접근하게 되어 값이 변경됨. 이거 수업 내용 복습하면서 다시 확인해보려고 함.
목표
- 이번 프로젝트 때 Trello 툴을 사용하지 못하였음. 개인적으로 trello로 써보면서 익숙케 하기.
- GitHub가 익숙하지 않아, pull을 했는데 자꾸 에러가 나서, fetch으로 내 로컬을 무시하고 계속 새로 내려받기를 했었다. 학진님이 올려주신 인프런 깃허브 강의 완독하기.
- 팀원 분들이 짜준 시각화 부분을 코드 복기. 주석 요청함.
- numpy 기초강의 듣기. (주말 활용)
- 지금까지 배운 내용 전체적으로 한번 훑기.
- 멘토님 정규표현식 수업
- SQL 코딩테스트 연습 -> 나중에. SQL 기본부터 공부.
그래도 이 프로그래머스를 코스에 참여하게 된건 나에게 큰 기회라고 생각한다. 정말 많은걸 배우고 있다는 생각이 든다. 너무 조급해 하지 말기.
그리고 팀원분들. 멘토님이 알려주시는 정보를 좀 더 유용하게 활용하려면 기초를 더 닦아야겠다.
