
1) 개요
PV 데이터는 가격(price)과 거래량(volume)에 관련된 정보를 포함함. 주가 예측에 핵심적인 요소인 ‘가격’ 자체를 포함하고 있기 때문에, 함수를 처음 만들 때 가장 유용한 데이터 유형 중 하나에 해당함. 즉, 함수 설계를 시작할 때는 거시지표나 복잡한 대체데이터보다 기본적인 가격·거래량 데이터(PV)가 가장 직관적이고 효과적인 출발점이 될 수 있음
2) 특징
2-1) Trading Frequencies
Turnover 증가의 가장 큰 원인
이론적으로만 보면,거래 빈도가 높아질수록 통계적으로 샤프 비율이 개선될 가능성이 존재함. 이는 독립·동일분포 가정 하에서 거래 횟수가 증가하면 표본표준편차가 감소하기 때문이며, 평균 수익이 유지된다는 가정 하에서는 변동성 감소로 인해 샤프 비율이 이론적으로 증가하게 됨
그러나 실제 시장에서는 Trading Frequency로 인한 Turnover 증가가 샤프 비율에 악영향을 미칠 영향이 큼
- 거래비용 증가
- 노이즈 트레이딩 (의미없는 거래)가 될 수 있어서, 평균 수익 자체가 유지되지 않고 떨어질 수 있음
그러나 Turnover를 지나치게 낮추기 위해 포지션을 오래 유지하면 신호의 반감기(signal decay) 문제로 인해 알파의 예측력이 빠르게 약화될 수 있음. 즉, PV 기반 전략에서는 “높은 Turnover → 거래비용 증가”와 “낮은 Turnover → 신호 노후화 → 예측력 감소”라는 두 가지 상반된 효과가 동시에 존재하며, 신호의 유효 기간과 거래비용 사이에서 최적의 균형을 찾는 것
2-2) 심리적 요인 고려
컴퓨터가 아닌 휴먼 트레이더들의 성향을 이용한 알파 아이디어를 찾아볼 수 있음.
- 소수가 아닌 정수로 매수/매도 주문을 하는 경향성
- 상승보다 손실에 더 민감하게 반응하는 경향성
- 손실 포지션은 너무 오래 유지하고, 이익 포지션은 너무 빠르게 청산하는 경향
이런 성향에 대한 정량적 분석 자료나 관련 연구가 있다면, 그런걸 전략에 반영하면 좋을듯
2-3) Data
PV function을 만들 때, PV Data만 쓰기보다는 다른 데이터를 섞어보자!
여러 종류의 데이터를 활용하더라도, 매수·매도 의사결정의 핵심 신호가 PV data에 기반한다면 해당 전략은 본질적으로 PV 기반 전략으로 분류할 수 있음. 다만 데이터가 과도하게 혼합되거나 특정 데이터 유형의 기여도가 불분명해지면, 전략의 금융적 해석 가능성과 일관성이 약화될 수 있으므로 이를 주의해야 함.
예를 들어서, 시가총액데이터인 cap은 Brain 플랫폼 상에서 pv section에서 찾아볼 수 있는데, 기업가치 데이터인 ev는 수식 상으로 시가총액 + 부채 + 기타등등임에도 불구하고 다른 section에 존재하기 때문에 너무 한 데이터 섹션 내에서 해결해야한다는 생각은 버리자!
3) Data
PV 기반 Function에서 주로 사용하는 데이터필드 정리
여려 유형의 Data들이 있지만 그들의 공통적인 Source는 Chart라는 것을 기억하자!
3-1) 가격 데이터
- open
- close
- vwap (volume weighted average price)
- etc
3-2) 거래량 데이터
- volume
- adv20 (20일치 거래량을 평균낸 데이터)
3-3) 그 외의 기술적 지표
- 이미 실무에서 널리 쓰이는 것들 (필요할 때마다 검색)
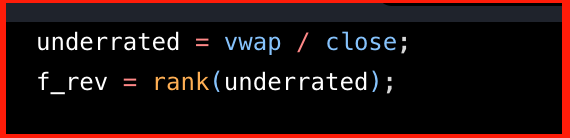
- 특정 주식의 자금 흐름 강도를 표현하는 지표가 있으면 좋을 것 같은데? → 거래량과 vwap를 곱하면 반영할 수 있다는 사실을 찾음 →
volume * vwap
- 특정 주식의 자금 흐름 강도를 표현하는 지표가 있으면 좋을 것 같은데? → 거래량과 vwap를 곱하면 반영할 수 있다는 사실을 찾음 →
- 기존 지표나 데이터들을 조합해서 새로운 지표 개발
- volume 다룰 때 20일치가 아니라 15일치 평균값 기준으로 다루고 싶은데? →
ts_mean(volumne, 15)
- volume 다룰 때 20일치가 아니라 15일치 평균값 기준으로 다루고 싶은데? →
🚨 필독
필요한 지표가 있다면 먼저 해당 지표가 브레인 플랫폼 내 datafield로 이미 존재하는지 확인하고, 존재하지 않을 경우에는 내 컨셉과 비슷한 지표가 이미 정립이 되어있는지를 검색을 통해 조사함. 정립이 되어있다면 이에 따라 operator와 datafield를 조합하여 구현하며, 별도의 구현 방식이 없는 경우에는 문제의 목적에 맞게 적절한 datafield와 operator를 직접 설계하여 지표를 구성함.
예를 들어서, 20일치의 volumne을 평균낸 값을 adv20으로 바로 불러올 수 있는데, ts_mean(volume, 20)으로 굳이 작성할 필요없음
또한, 거래량만 가지고 진짜 주식의 영향력을 파악하기 힘들다고 생각한다면 나만의 지표를 만들어낼 수 도 있겠지만, 보조지표의 계산식을 검색을 통해서 찾고, 그걸 그대로 브레인에 이식할 수도 있음.
팩터와 다르게 지표 자체는 널리 알려진걸 씀으로 해서 손해볼 게 전혀없고 오히려 정확하게 계산하는게 중요할 수 있다는 걸 염두에 두면 좋을듯! 나만의 지표를 만들게 된다면 무의미한 연산이나 숫자 변경보다는 그 지표가 정말 내가 원하는 어떤 정성적인 맥락을 대표할 수 있는지 판단해볼 것
4) 모멘텀과 리버전
🚨 주의
모멘텀과 리버전은 시계열 데이터의 "추세가 지속될 것이다" vs "평균으로 되돌아올 것이다"와 같은 행동 가설이기 때문에, PV function을 설계할때만 쓸 수 있는 전략은 아님! 예를 들어서, 모멘텀 컨셉을 News function 설계에 사용한다면 최근 긍정 뉴스가 반복적으로 발생한 종목은 추가적인 상승 압력이 존재한다고 가정하여 long 포지션을, 반대로 부정 뉴스가 지속적으로 축적되는 경우에는 하락 압력이 이어질 가능성을 반영해 short 포지션을 취하는 식으로 확장할 수 있음. 여기서는 pv에 한해서 다룸.
4-1) Momentum
값이 클수록 좋은 지표 A를 정의한 뒤, 추세는 분리해 해석하면 됨. 추세가 이어진다고 보면 모멘텀, 평균으로 되돌아온다고 보면 리버전 전략을 선택
-
컨셉: A가 높게 나타나는 주식은 앞으로도 A가 높게 나타날 것이다!
- 수익률 모멘텀 (A: 수익률)
- 거래량 모멘텀 (A: 거래량)
- etc
-
예시
- 함수 코드

- 실행 결과
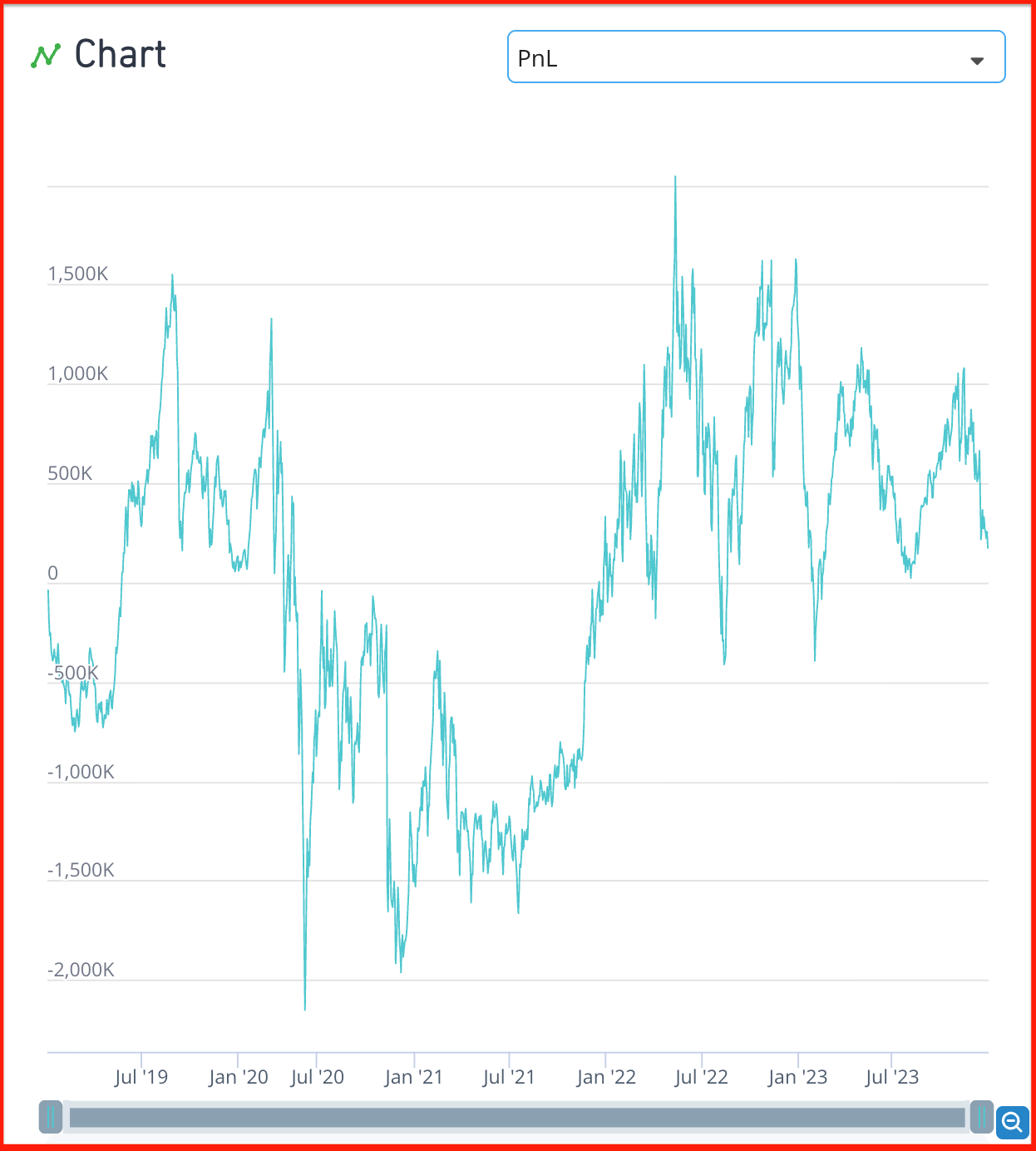
- 개선 방법
- a) ts_delay()를 한번 더 씌워서 최근 5일 데이터 무시할 수 있도록 함

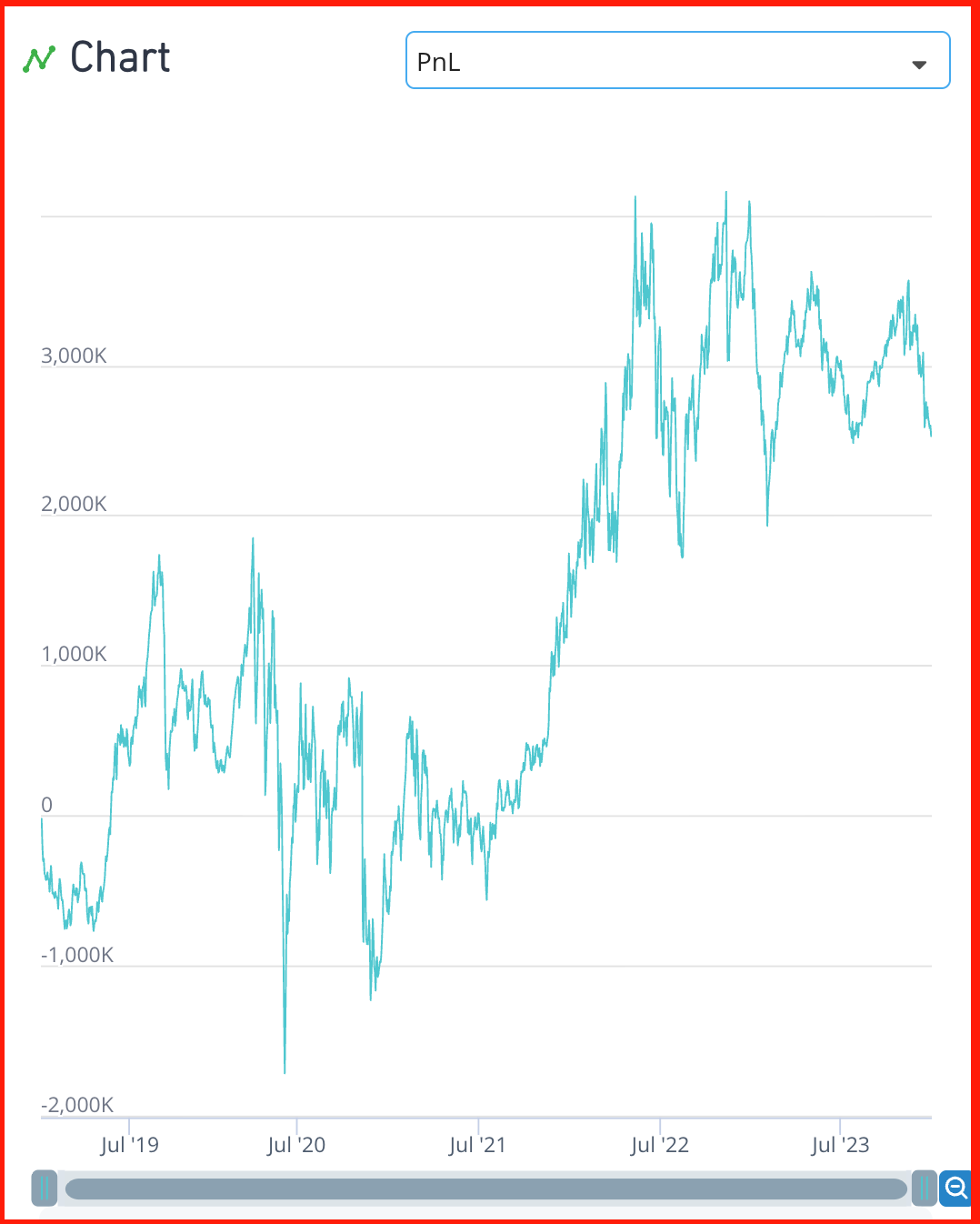
- b) 단기 리버전 신호가 지배하지 못하도록 counting 전략을 도입

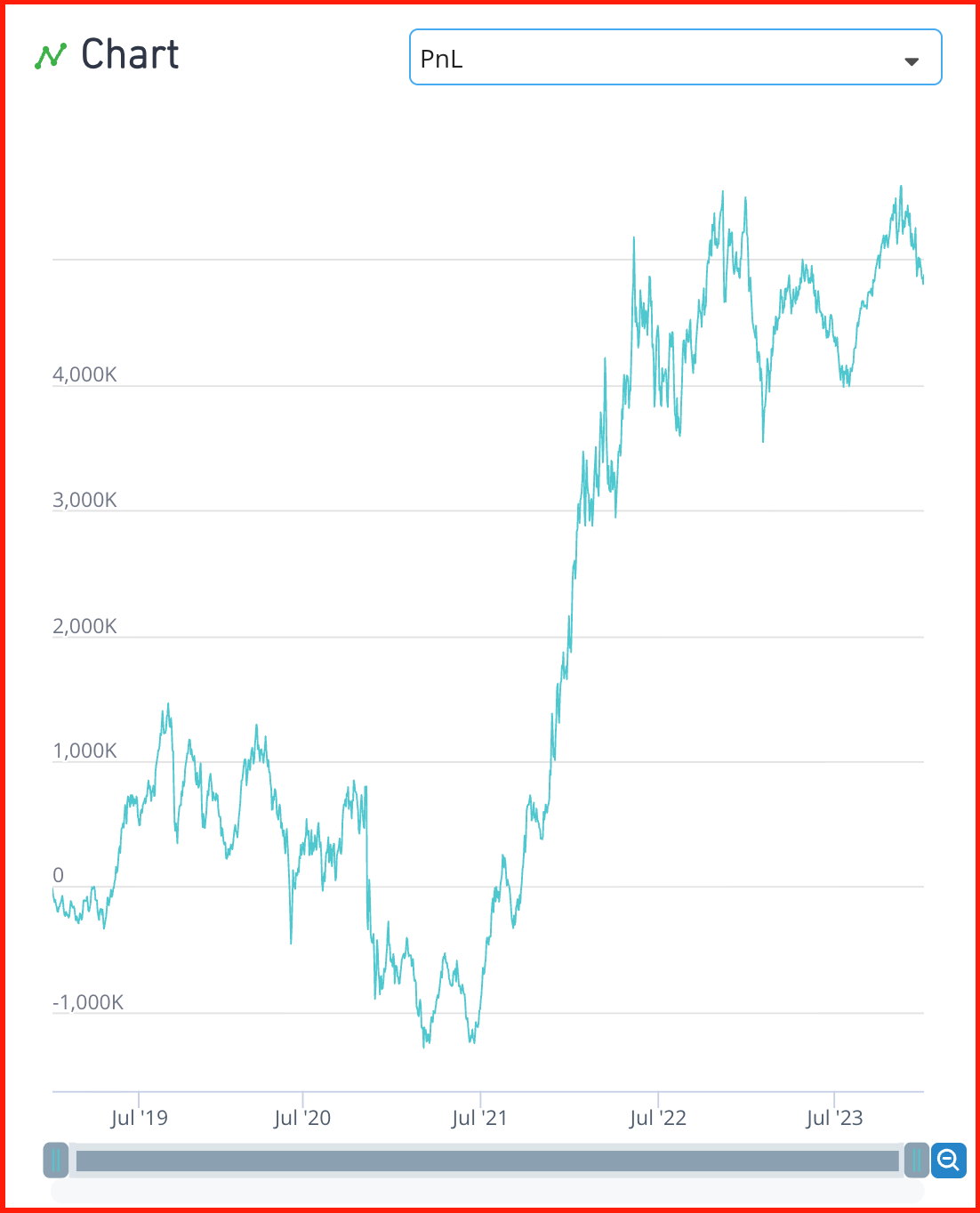
- a) ts_delay()를 한번 더 씌워서 최근 5일 데이터 무시할 수 있도록 함
- 함수 코드
-
Tips
- trade_when()
exit 조건을 -1로 설정하면, 진입조건만 설정하고 청산은 안하겠다는 의미임. 모멘텀은 장기 효과이기 때문에, 손실이 나더라도 포지션을 유지하는 것이 유리한 경우가 많음! - Neutralization
시장에서는 보통 돈이 개별 종목 하나씩 들어가기보다 “AI → 반도체 → 2차전지”처럼 섹터 단위로 몰리면서 전체가 같이 오르는 흐름이 더 크게 나타남. 이때 모멘텀 전략 사실상 “어느 산업이 지금 돈을 받고 있는가”를 맞추는 게임이 됨. 그런데 sector neutralize를 해버리면 반도체가 아무리 강해도 그 안에서 삼성전자/하이닉스 상대 순위만 보게 되니까 “반도체 자체가 강하다”는 가장 중요한 신호가 제거됨. 따라서, 너무 강한 중립화는 지양할 것!
- trade_when()
4-2) Reversion
-
컨셉: A가 높게 나타나는 주식은 이제 A가 낮게 나타날 것이다!
- 수익률 리버전 (A: 수익률)
- 거래량 리버전 (A: 거래량)
- etc
-
예시
- 함수 코드
-
실행 결과
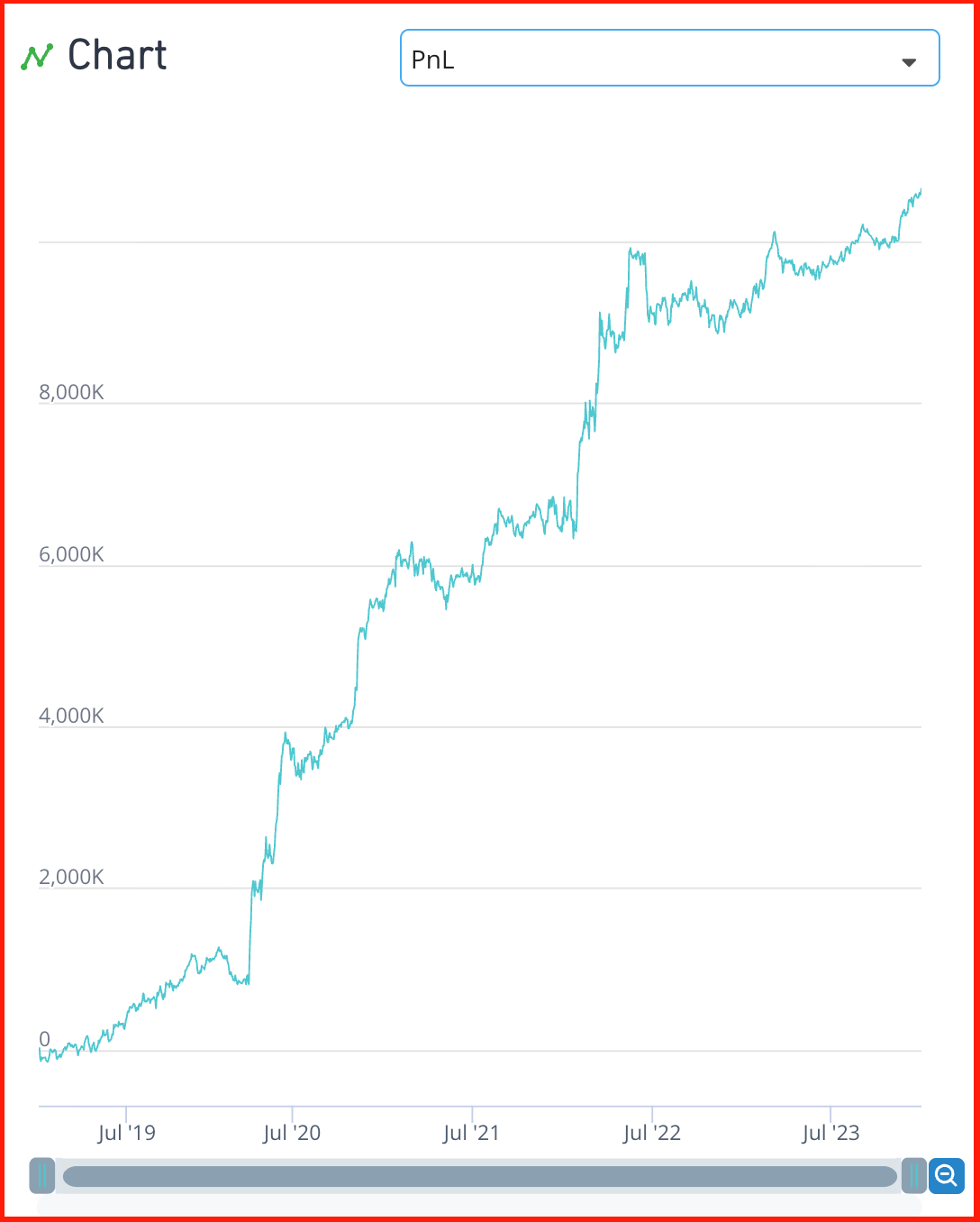
-
개선 방법
언뜻 PNL graph만 보면 좋아보이지만(실제로 좋은 건 맞음), 문제는 Turnover가 85%정도로 매우 높게 나타나서 제출 불가능한 형태.- ts_mean()을 통해서 시간축으로 과거 5일의 평균값을 사용함

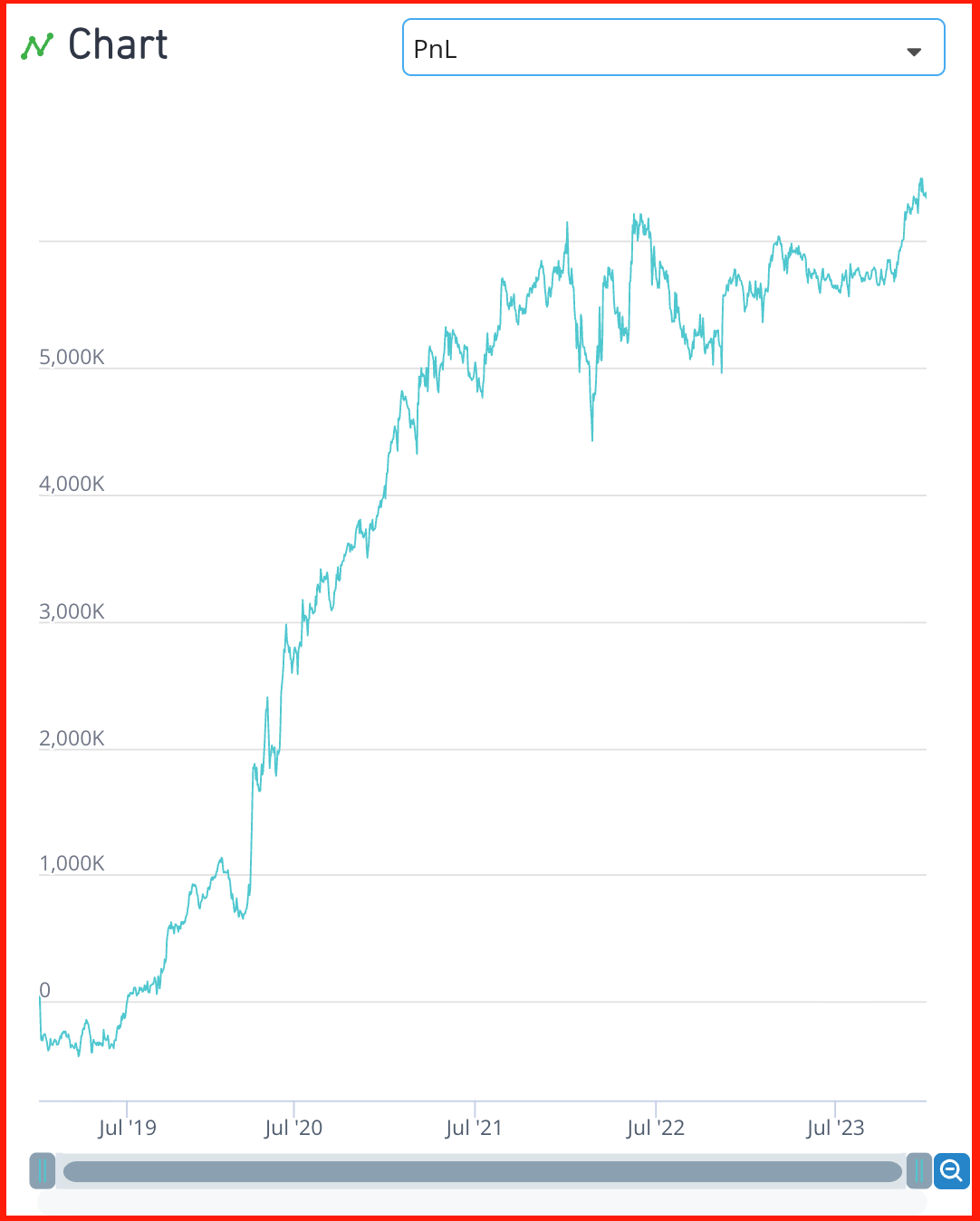
 IS Summary에서 확인할 수 있듯, Turnover가 36.97%로 대폭 감소하였음! 여기서 사용한 방식은 Turnover를 줄이기 위한 하나의 예시이고 너무나도 많은 테크닉들이 존재한다는 것을 기억하자!
IS Summary에서 확인할 수 있듯, Turnover가 36.97%로 대폭 감소하였음! 여기서 사용한 방식은 Turnover를 줄이기 위한 하나의 예시이고 너무나도 많은 테크닉들이 존재한다는 것을 기억하자!
- ts_mean()을 통해서 시간축으로 과거 5일의 평균값을 사용함
- 함수 코드
4-3) 관측 시간에 따른 두 전략의 효과 차이
- 단기(1개월 미만): Reversion 효과가 더 강하게 나타나는 측면이 존재함 (최근의 급락은 노이즈다 라는 관점)
- 중기(분기~1년): Momentum 효과가 더 강하게 나타남.
- 장기(1년 초과): Reversion 효과가 다시 강해짐 (결국은 일정 수준으로 우상향하면서 수렴하는 그래프)
중기와 장기는 어느 정도 끄덕끄덕하고 넘길 수 있는데 단기는 조금 더 상세하게 살펴볼 필요가 있어보임. 1~4주 정도의 구간은 시장·데이터·전략에 따라 reversal과 momentum이 섞여 나타나는 "Transition Zone"이라서 명확한 스타일이 없음.
따라서 lookback 구간을 한 달 이내로 설정하는 경우에는 특정 이론에 고정하기보다 실험적으로 결정하는 경우가 많음. 예를 들어 5일 수익률 평균을 기준으로 종목을 정렬하면 단기 노이즈에 대한 반작용이 강하게 나타나 평균회귀 전략이 효과적으로 작동하는 경향이 있지만, 약 10일 수준의 애매한 구간에서는 모멘텀과 리버전 효과가 혼재되기 때문에 두 접근을 모두 테스트한 후 성과를 비교해 선택하는 것이 합리적일 수 있음.
5) 기술적 지표
3)에서 널리 알려져 있는 지표를 사용할 수 있다고 배웠는데, 대표적인 지표들에 대해서 살펴보자!
5-1) RSI (Relative Strength Index)
가격 상승과 하락의 강도를 기반으로 현재 자산이 과매수(overbought)인지 과매도(oversold)인지 판단하는 모멘텀 지표로, 최근 상승폭과 하락폭의 비율을 이용해 계산되며 일반적으로 값이 높을수록 상승 압력이 강하고, 낮을수록 하락 압력이 강한 상태를 의미함.
5-2) Bollinger Bands
이동평균을 중심으로 표준편차를 이용해 상단 밴드와 하단 밴드를 설정하는 변동성 기반 지표로, 가격이 밴드 상단에 가까울수록 과열 상태, 하단에 가까울수록 과매도 상태로 해석하며 변동성이 커질수록 밴드 폭이 넓어지는 특징을 가짐.
5-3) MACD (Moving Average Convergence Divergence)
단기 이동평균과 장기 이동평균 간의 차이를 활용하여 추세의 방향성과 강도를 판단하는 지표로, 두 이동평균 간의 수렴과 확산을 통해 상승 추세와 하락 추세 전환 시점을 포착하는 데 사용됨.
5-4) CLV (Close Location Value)
종가가 당일 가격 범위(고가–저가) 내에서 어느 위치에 있는지를 나타내는 지표로, 장 마감 시점의 시장 심리를 해석하는 데 활용됨.
-
수식
CLV = ((Close - Low) - (High - Close)) / (High - Low) -
범위: [-1, 1]
-
해석
CLV가 1에 가까울수록 종가가 고가 근처에 위치하여 매수 압력이 강한 상태를 의미하며, -1에 가까울수록 종가가 저가 근처에 위치하여 매도 압력이 강한 상태를 의미함. -
활용
CLV가 낮을 때(≈ -1)는 반등 가능성을 반영하여 매수(Long), CLV가 높을 때(≈ 1)는 하락 가능성을 반영하여 매도(Short) 포지션을 취하는 평균회귀(reversion) 전략에 적합함. 거래량과 결합할 경우(CL V × volume 등) 자금 흐름까지 반영한 더 강한 신호를 만들 수 있음.
🤷🏻♂️ 오늘은 두 가지 전략을 소개하고 각각 구체적인 예시까지 살펴보았는데, 첫번째 전략은 💬에 대한 💬전략이고, 두번째 전략은 💬에 대한 💬전략입니다. 빈 칸에 들어갈 키워드는 각각 무엇일까요?
Hint: 4-1), 4-2) 섹션의 컨셉 내용 다시 읽어보세요

2개의 댓글

- MACD에서 단기 이동평균과 장기 이동평균 간의 차이를 활용하여 추세의 방향성과 강도를 판단한다고 했는데, 단기 이동평균이랑 장기 이동평균은 사용자 주관에 따라서 결정하는 건지 궁금합니다
- MACD에서 두 이동평균 간의 수렴과 확산을 통해 상승 추세와 하락 추세 전환 시점을 포착한다고 나와 있는데, 수렴과 확산을 판단하는 기준(ex 크로스)이 궁금합니다

해당일에 다른 참가자들이 제출한 알파와의 성과 비교에 기반한 점수가 turnover 과 관계가 있는지 궁금합니다.
(많은 참가자가 마지막 날에 알파를 제출할 경우, BRAIN 플랫폼 시뮬레이션 속도가 평소보다 느려질 가능성이 있습니다.)