
DFS/BFS 알고리즘 정리는 (1)편으로
📌 "깊이/너비 우선 탐색을 사용해 원하는 답을 찾아보세요."
출제빈도 : 높음
평균점수 : 낮음
코드
프로그래머스 고득점 Kit - 깊이/너비 우선 탐색(DFS/BFS) 문제목록
1. 타겟 넘버 (Lv. 2)
-
BFS 사용코드

-
DFS 사용코드
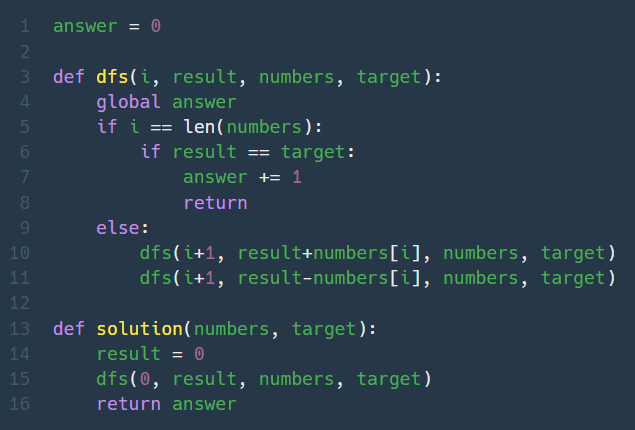
아직 문제풀이 감이 안와서 아이디어 생각은 했는데, 코드로 옮기지를 못하겠어서 다른 사람들 풀이를 봤다. 이 문제는 BFS와 DFS로 모두 풀 수 있었는데, BFS가 훨씬 간단했다.
- BFS 풀이
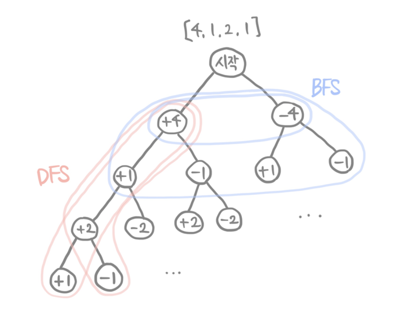
각각의 depth에서 나올 수 있는 모든 연산결과를 구한 다음, 트리의 가장 마지막 줄에 나온 연산결과들 중 target과 같은 값이 몇개 있는지 세면 답이다.
- DFS 풀이
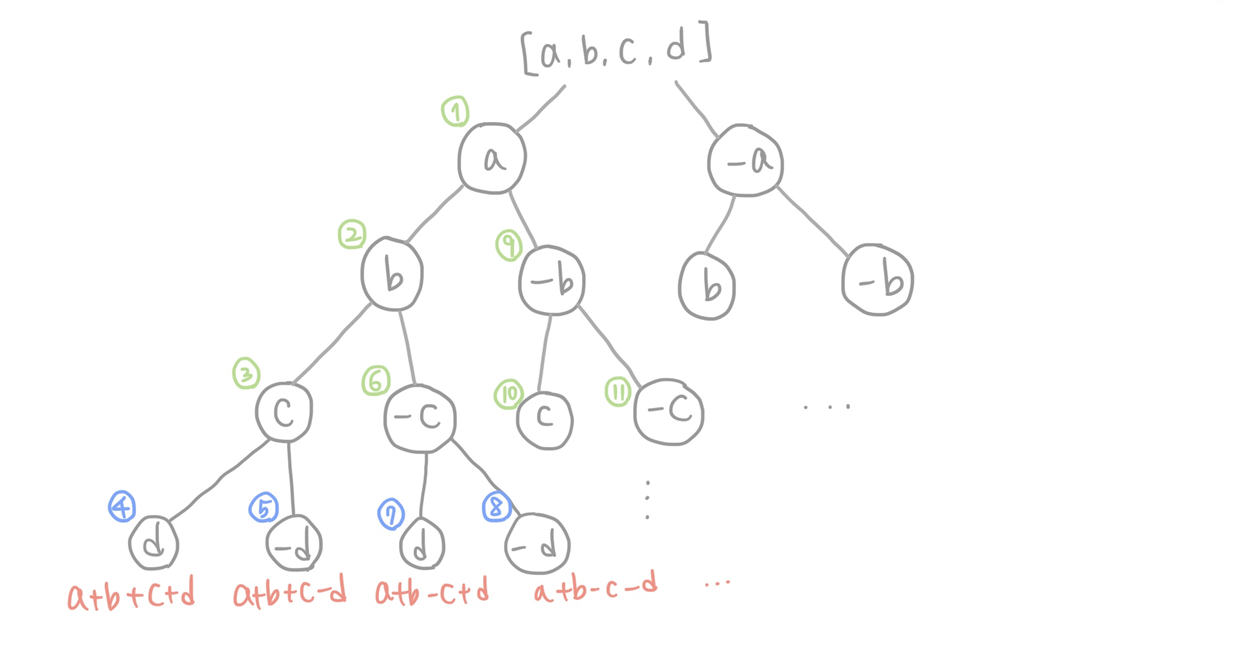
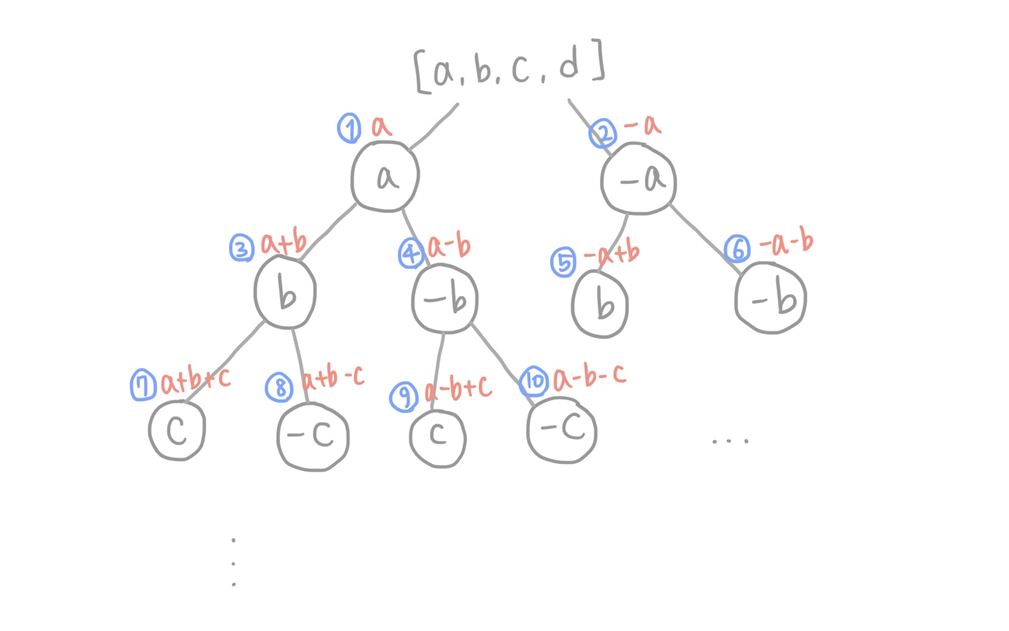
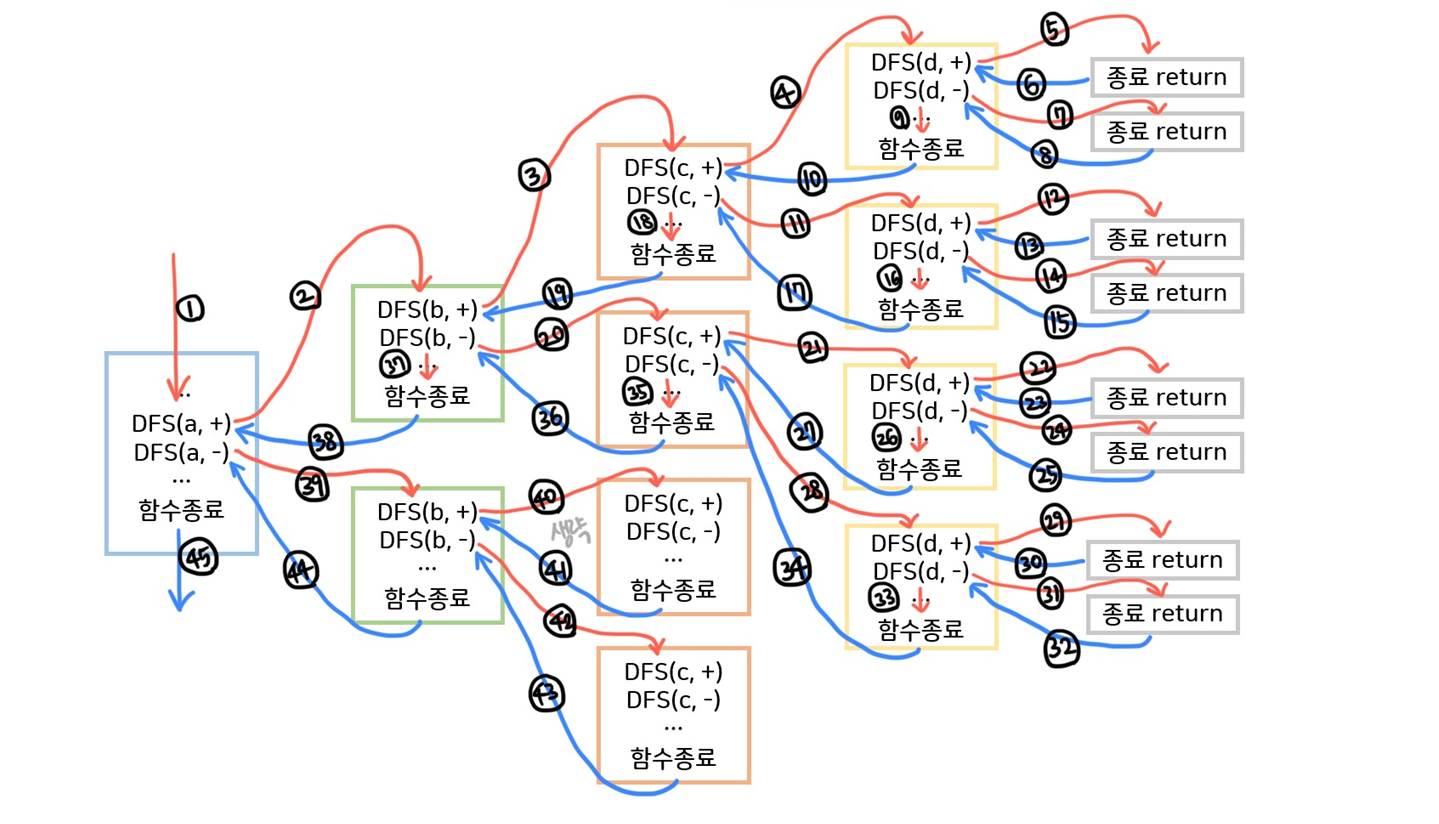
재귀를 통해 다음 연산으로 타고타고 들어가서 현재의 탐색 깊이가 트리의 끝이면 탐색을 종료하고, 합이 target이라면 답의 개수를 1 늘린다. 현재의 탐색 깊이가 트리의 끝이지만 합이 target이 아니라면 무시하고 다음 연산을 진행한다.
재귀함수의 호출 순서는 다음과 같이 이루어진다.
2. 네트워크 (Lv. 3)

내가 dfs를,, 무려 재귀로,, 풀다니 감격이야😭
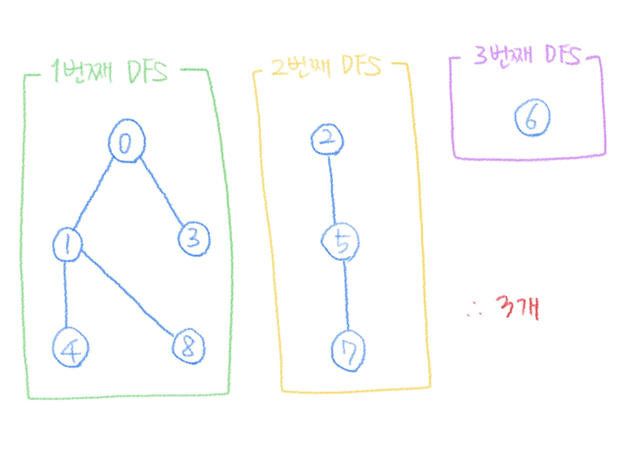
문제에서 탐색할 그래프가 아예 인접행렬로 주어졌다. 시작은 0부터 DFS 탐색을 실행하면서 이 노드와 이어져있는 모든 노드들을(=하나의 네트워크를 이루는 모든 컴퓨터들) 방문처리한다. DFS 탐색을 종료했는데도 아직 방문하지 않은 노드들이 있다면, 이는 다른 네트워크가 또 있다는 뜻이므로 아직 방문하지 않은 노드를 하나 골라 앞의 과정을 반복한다. 모든 노드들을 방문했을때, DFS 실행 횟수가 네트워크의 수이다.
3. 게임 맵 최단거리 (Lv. 2)


최단거리를 찾는 문제이고, 답이 없는 문제일 수 있으므로 BFS를 사용했다.
routes[i]는 총i칸 이동했을때 내 캐릭터가 존재할 수 있는 모든 칸들을 의미한다.- 따라서
i칸 이동한 내 캐릭터가i+1번째에 갈 수 있는 칸들은routes[i+1]에 기록된다.

현재칸에서 상하좌우로 이동할 수 있는 모든 칸을 다음 인덱스에 추가한다. 이때, 이동한 칸이 맵의 범위를 벗어나거나, 벽이거나, 왔던 길을 되돌아가는 경우이거나, 중복된 값이라면 추가하지 않는다. 이 과정을 반복해서 가능한 모든 경로들을 탐색하다가 목표노드 (n-1, m-1)가 발견되면, 이때까지 지나온 칸들의 개수를 반환한다. 그런데 목표노드를 찾지 못했는데 다음에 갈 노드가 더이상 없다면, 이는 답이 없는 경우이므로 탐색을 종료하고 -1을 반환한다.
코드가 자꾸 무한루프에 빠져서, 지나온 길로 되돌아가는 경로는 제외하기 위해 "바로 이전에 해당 노드를 방문했었는지"를 저장해두려고 + 트리로 치면 depth가 몇인지 인덱스로 확인하려고 deque의 popleft를 쓰지 않고 2차원배열 구조를 유지했다.
정확도는 다 맞는데 효율성테스트를 하나도 통과 못하다가 통과한 결정적인 코드는 10~12번째줄에 있는 중복값 제거였다.
🤔 처음 풀어본 BFS 문제라 좀 비효율적으로 코드가 길어졌는데, 다음에 푼다면
deque를 사용하고 방문여부는visited를 활용해서 풀어볼 것이다.
4. 단어 변환 (Lv. 3)

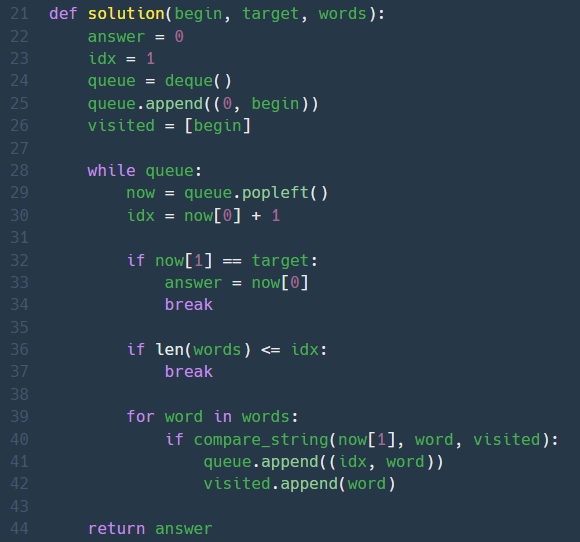
3. 게임 맵 최단거리 문제를 풀면서 부족했던 부분들을 보완해서 풀려고 노력했다. 우선 이 문제도 '가장 짧은 변환 과정', 즉 최단거리를 구하는 문제이므로 BFS로 풀었다.
deque사용- 현재 노드를
popleft로 가져옴- depth를 표현하기 위해 큐 안의 노드를 튜플형태
(depth, word)로 저장- 이미 방문한 노드는 이후에 다른 경로를 통해 재방문하려고 해도 그 경로는 이미 최단경로가 아니게 되므로 재방문할 필요 없음,
visited활용
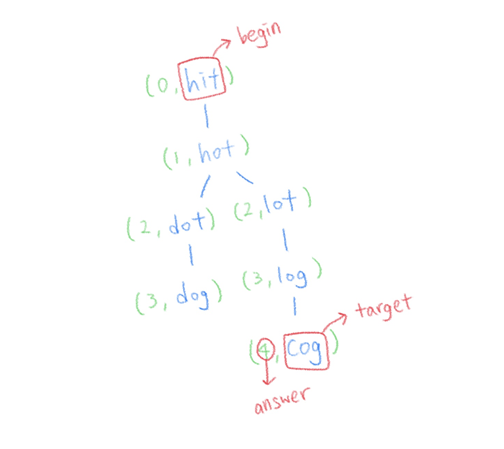
현재노드(단어)를 now라고 할때, words 중에 now에서 알파벳 하나만 변형해서 만들 수 있고, 아직 큐에 추가하지 않았던 단어를 골라 큐에 추가한다. 추가할때, 튜플에 포함시킬 depth는 now의 depth에 1을 더한 값이다. (ex. depth=2에서 추가한 단어는 depth=3) 이 과정을 반복하다가 target을 발견하면 해당 노드의 depth를 반환한다. 그런데 words에 있는 모든 단어를 순회했는데도 target을 발견하지 못했다면 이는 답이 없는 경우이므로 0을 반환한다.
5. 여행경로 (Lv. 3)
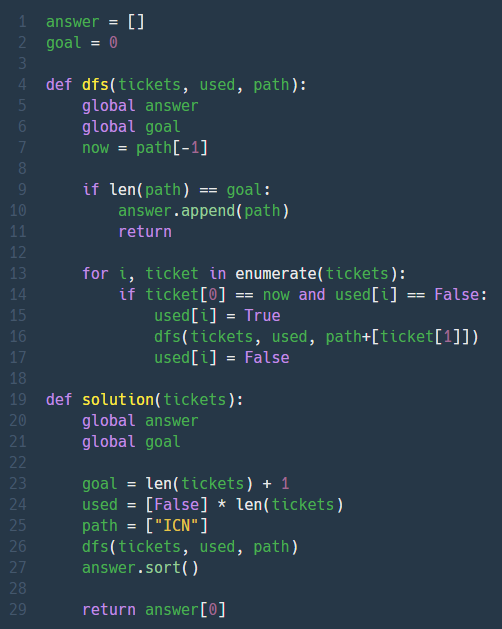
정답률이 50프로 밑으로 내려가면 어김없이 못푸는 나란 빡대가리... 에휴
일단 문제풀이방법은, 모든 노드를 지나 깊게 파고 들어가는 DFS를 사용해서 아래와 같이 가능한 모든 여행경로를 구해야 한다.
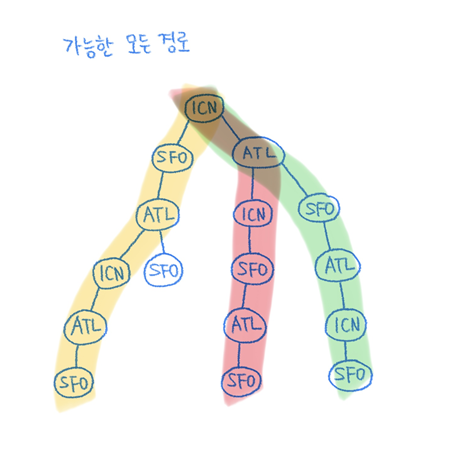
그런데 문제는 동일한 티켓으로 나올 수 있는 모든 경로를 구해야해서, 방문여부를 도대체 어떻게 저장해야하냐는 것이다. (이쪽경로에서 사용했는데 저쪽경로에서도 사용해야함, 한번 방문했다고 끝이 아님) 실제로 어떻게 처리해야할지 모르겠어서 제일 막혔던 부분이 이 부분이었다.
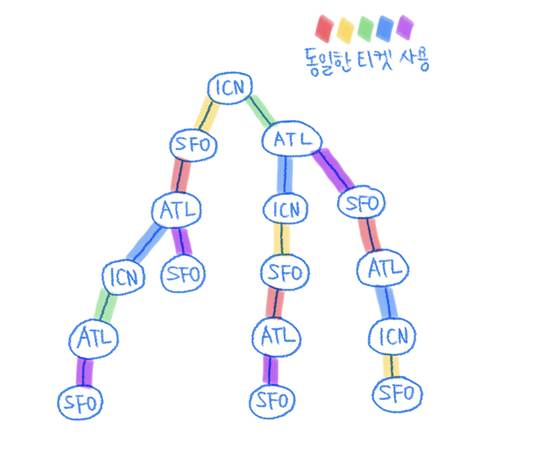
그래서 다른 사람들 코드를 보니, dfs 재귀호출이 끝나면 사용처리했던 티켓을 다시 복구하는 형식이었다.
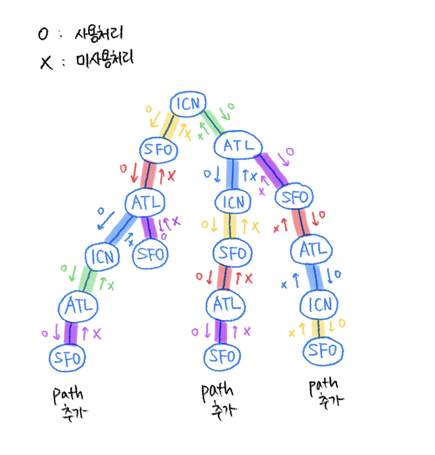
코드로는 이 부분인데,
for i, ticket in enumerate(tickets):
if ticket[0] == now and used[i] == False:
used[i] = True
dfs(tickets, used, path+[ticket[1]])
used[i] = False대체 어떻게 동작하는지 이해가 안가서 하나하나 그려보았다.
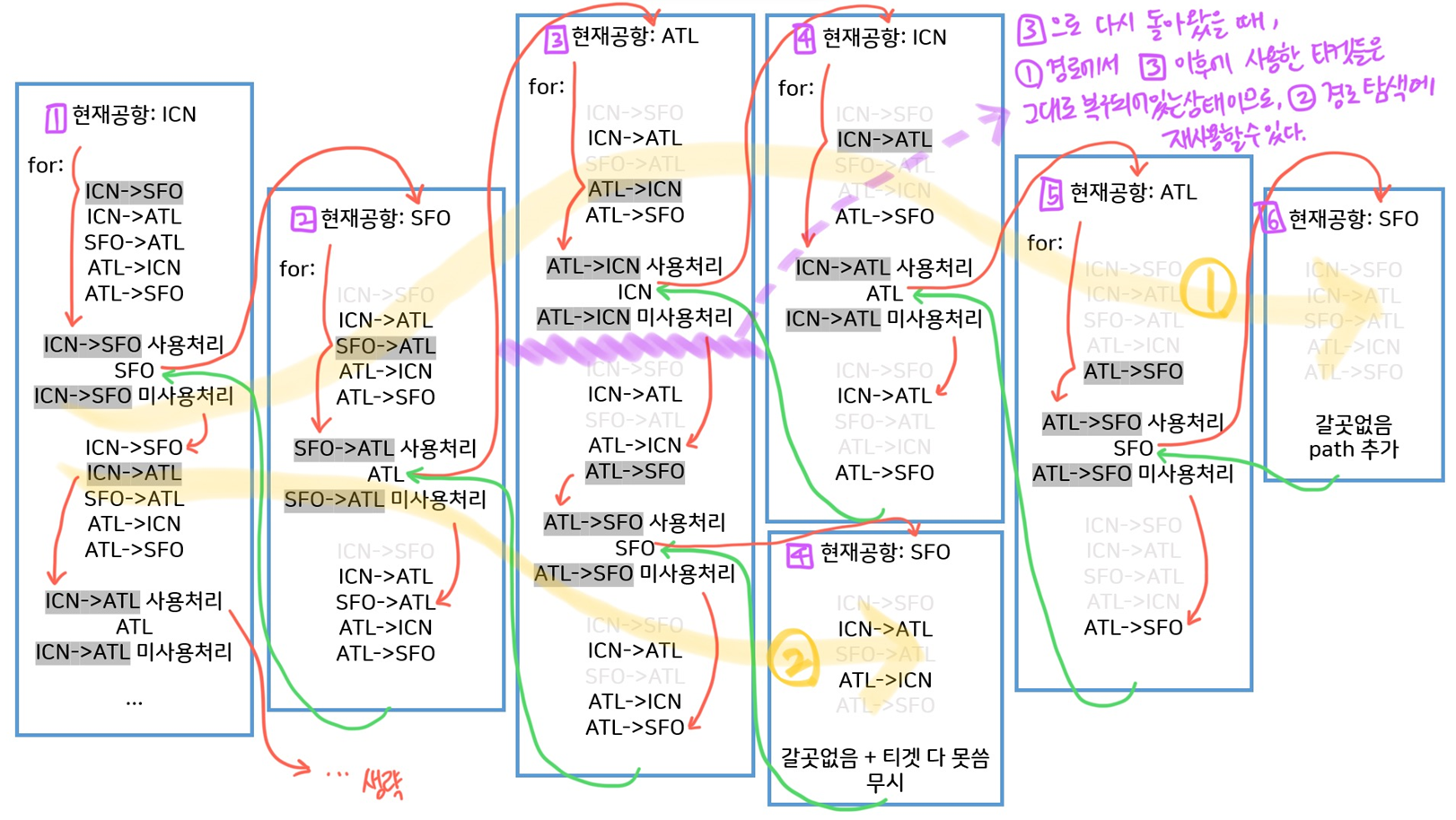
그러니까 dfs 재귀호출이 끝나고 돌아올때, 즉 하나의 경로 탐색이 끝나고 돌아올때, 방금 사용처리했던 티켓을 다시 복구하면서 돌아오면, 현재차례에서 어느 경로를 먼저 탐색했는지에 상관없이(=먼저 진행한 탐색 중에 어느 티켓을 썼는지에 상관없이) 진입 가능한 모든 갈래에서 사용할 수 있는 티켓이 항상 동일하다는 것이다.
쉽게 말해 현재공항에서 다음공항으로 갈 수 있는 경우의 수가 2가지이고 남아있는 티켓은 a,b,c,d,e일때, 첫번째 경로를 탐색하고 돌아와도 현재공항에서 사용할 수 있는 티켓은 a,b,c,d,e, 이어서 두번째 경로를 탐색하고 돌아와도 현재공항에서 사용할 수 있는 티켓은 a,b,c,d,e라는 것이다.
다시 생각해보면 현재공항에서 사용할 수 있는 티켓이 항상 동일해야 for문으로 사용가능한 티켓을 찾을때 값이 꼬이지 않고 똑바로 나오기도 한다. for문은 tickets를 기준으로 도는데 tickets이 바뀌진 않으니까 모든 티켓을 똑같은 순서대로 차례대로 확인하는건 똑같지만, 사용여부가 해당차례에선 dfs를 돌기 전이든 dfs를 돌고난 후든 똑같아야 제대로 값이 나올 것이기 때문이다.
겨우겨우 이해하긴 했는데 솔직히 진짜 너무 복잡하다...
(보류) 6. 아이템 줍기 (Lv. 3)
(보류) 7. 퍼즐 조각 채우기 (Lv. 3)
: 진짜 얘네는 풀다가 열불나 디질거 같아서 그냥 패스 (이미 6번 풀다가 씅질 더러워져서 7번은 쳐다도 보기 싫어짐) 나중에 풀든 말든 할거고 지금은 안할거다

느낀점
- 공통
- 아이디어도 잘 생각나고 구현도 잘되거나, 아이디어는 생각났는데 구현이 어렵거나, DFS/BFS의 탈을 쓴 더럽게 노가다성인 구현문제이거나
visited는 웬만하면 항상 같이 병행해야 중복방문을 막고 우후죽순 늘어나는 트리를 가지치기할 수 있다.- DFS/BFS가 '그래프'를 탐색하는 문제이긴 하지만, 그렇다고 해서 코드에서 굳이 '그래프'를 따로 표현할 필요는 없다. 문제에서 주어진 데이터를 토대로 활용해서 탐색 중에 그래프를 만들어가는 느낌?
depth관리도 해야한다. (그래프 노드 안에서 튜플로 관리하는게 제일 편한듯)
- DFS & 재귀
- 모든 지점을 지나는 경로 찾기 = DFS
- 코드를 올바르게 썼다면 "재귀호출의 순서"가 "DFS 탐색 순서"와 같다는 점을 항상 유의 (재귀호출 순서를 맞추기 위해
visited등의 DFS를 위한 코드가 아닌 다른 추가코드를 더 쓸 필요가 없어야한다는 얘기) - 원함수 하나에서 2개 이상의 재귀함수가 호출되는 경우에, 여러개의 재귀가 동시에 호출되는게 아니고, 첫번째 재귀호출로 빠질때 원함수 진행은 거기서 잠시 일시정지된다. 그리고 재귀호출을 끝내고 돌아오면, 원함수 진행은 멈춰있던 부분부터 다시 시작된다.
- 탐색을 끝마치고 해를 도출할때, 필요에 따라 전역변수에 값을 추가하는 방법을 활용한다.
visited와 같이 재귀 내에서 값이 계속 바뀌고 이를 매번의 탐색에 반영해야하는경우, 파라미터로 그때그때 바뀐값을 받아와서 관리한다. (재귀가 끝나고 돌아올때 이 값을 반환하지는 않는다는 점 유의, 원함수에서는 변화가 없다)
- BFS
- 최단경로 찾기 = BFS
- 최단경로, 혹은 가장 짧은 거리를 찾는 문제가 많다보니 좌표공간을 활용하는 문제가 많고, 이에 따라 2차원배열로 좌표공간을 표현해서 문제를 푸는 방법도 많다.

정말 좋은 글 감사합니다!