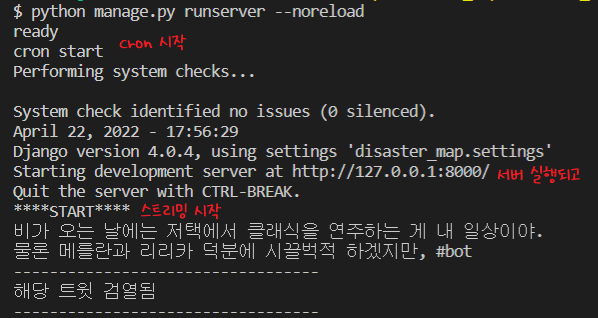
트윗 검열하기
트윗을 스트리밍하는데 너무 보기 싫은 드러운 트윗들이 많이 올라와서 테스트 중에 많이 보이는 그지같은 키워드를 중심으로 저장 단계에서 제외를 했다.
# retrieve.py
ew = ["보기", "싫은", "드러운", "트윗에", "포함된", "단어들", "#도", "따로", ... ]
def exceptWord(txt):
for word in txt.split():
if word in ew:
print("해당 트윗 검열됨")
print('----------------------------------')
return False
return True
def search_tweets(queries):
twids = [] # id_str (아이디)
times = [] # created_at (생성시간)
texts = [] # text (텍스트)
users = [] # user name (유저 이름)
stream = twitter_api.GetStreamFilter(track=queries)
delay = 60 * 1 # 60 seconds * 1 minutes
close_time = time.time() + delay
# 1분동안 트윗 데이터 모으기
for tweets in stream:
if removeRT(tweets['text']) and exceptWord(tweets['text']):
print(tweets['text'])
print('----------------------------------')
times.append(utc2kst(tweets['created_at']))
texts.append(tweets['text'])
twids.append(tweets['id_str'])
users.append(tweets['user']['name'])
if time.time() >= close_time:
break
# 1분동안 트윗 데이터 모은 후 모두 반환
print("out")
return twids, times, texts, users그냥 txt라고만 쓰면 한글자씩 자르는데 .split() 메소드로 자르면 띄어쓰기를 기준으로 자른다. 굳이 이런거에 형태소로까지 나누고 싶지 않은데다가 이런 트윗들은 대부분 패턴이 똑같아서 이정도로만 걸러도 충분할 것 같다.

서버 실행하자마자 스트리밍 시작하기
지난번에 BEMS 서버에서 날씨 정보 불러오는 작업했던거를 바탕으로 트윗 스트리밍도 서버 시작하자마자 돌아가는 것으로 변경했다.
# apps.py
from django.apps import AppConfig
class ApiConfig(AppConfig):
default_auto_field = 'django.db.models.BigAutoField'
name = 'api'
def ready(self):
from .models import Tweet, DisasterTag, Mark
from .main import cron_tweet
print("ready")
cron_tweet()# main.py
queries = queries_typhoon + queries_downpour + queries_snow + queries_forestfire + queries_earthquake + queries_coldwave + queries_heatwave + queries_dust
def job():
print("****START****")
# 트윗 가져오기 (retrieve)
twids, times, texts, users = search_tweets(queries) # 추출
twids, times, texts, users = remove_duplicates(twids, times, texts, users) # 중복제거
if len(texts) > 0: # 분석할 트윗이 존재
# 트윗 분류하기 (classify)
disasters, regions = classify_tweets(texts)
print(texts)
print(disasters)
print(regions)
for twid, time, text, user, disaster, region in zip(twids, times, texts, users, disasters, regions):
if disaster != "None" and region != "None":
tag_d = DisasterTag.objects.get(name=disaster)
mark = Mark.objects.get(region_name=region)
tweet = Tweet(
twid=twid,
time=time,
text=text,
user=user,
disaster_tag=tag_d,
location=mark
)
tweet.save()
else: # 잘못 들어온 트윗은 저장X
pass
else: # 트윗 없음
pass
print("************************")
def cron_tweet():
print("cron start")
sched = BackgroundScheduler()
sched.add_job(job, 'interval', seconds=60, id='cron_tweet')
sched.start()지난번에 개고생하면서 한 덕에 이번에는 쉽게 쉽게 끝냈다. retrieve에서 스트리밍하는 시간이랑 main에서 나머지 분류 작업도 하는 시간 때문에 무한루프 while문을 유지하려고 했는데 이러면 영원히 서버가 시작하지를 못해서 스케줄러로 변경할 수 밖에 없었다.
문제점
interval을 60초로 설정해서 60초마다 잘 불러오는거 같긴 한데 문제가 몇개 있다.
- 프로세스가 2개씩 실행된다.
- 제일 첫 시작도 60초를 기다려야 실행이 된다.
- 트윗을 스트리밍하는 60초랑 스케줄러를 실행하는 주기인 60초랑 살짝 안맞아서
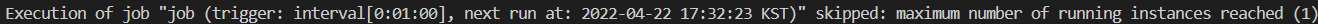
이런 오류가 뜬다.
1번은 런서버를 돌릴 때 python manage.py runserver --noreload 로 돌리면 되고 나머지 해결은 좀 나중에 해야징.
확인하기
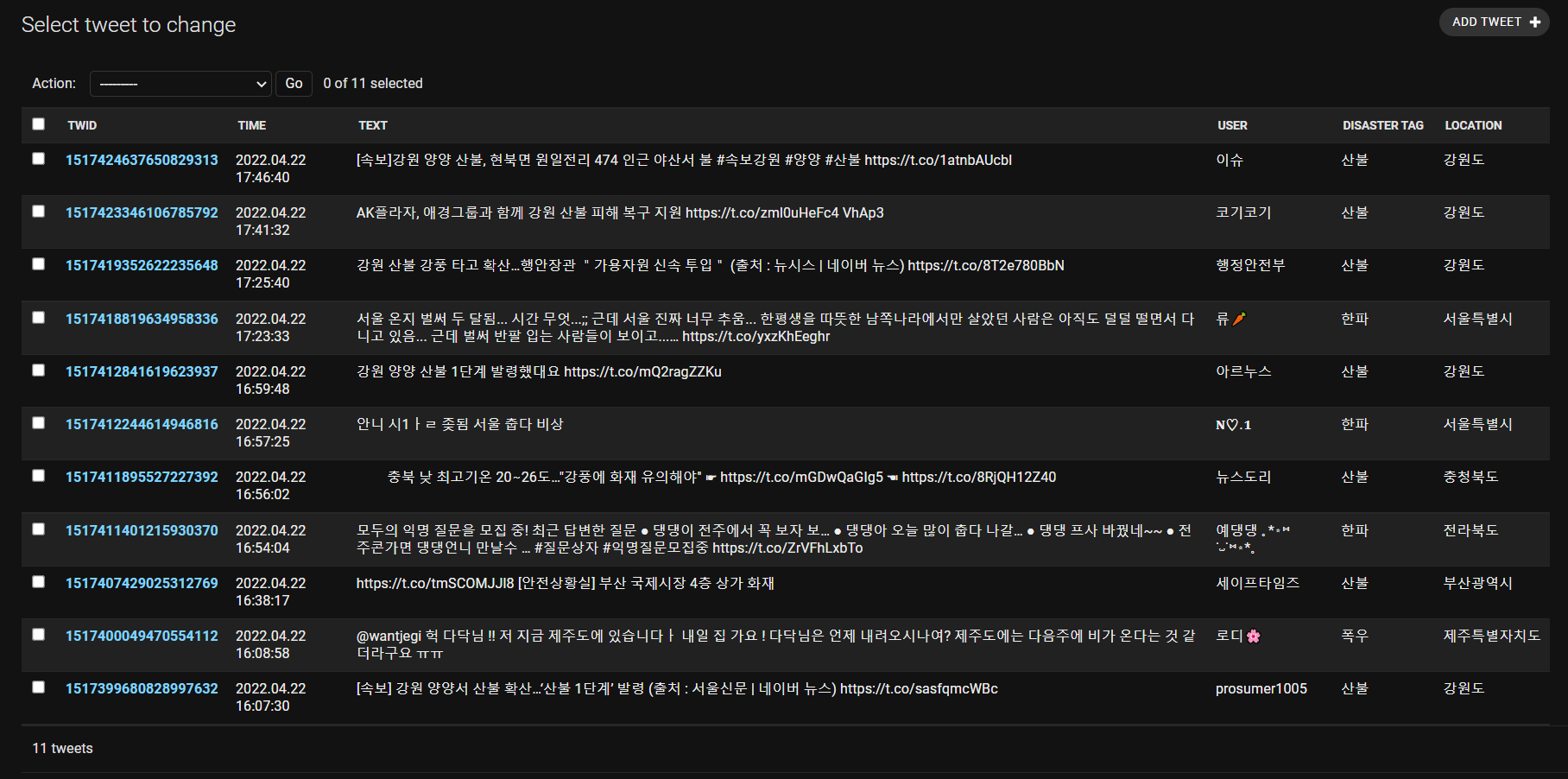
이제 런서버를 돌리면 자동으로 스트리밍 돌려서 트윗을 받아오고 분류해서 디비에 저장하는거까지 알아서 해준다! 그래서 트윗에 초과요청 보내는 오류는 이제 안뜨는 것..? 같다.
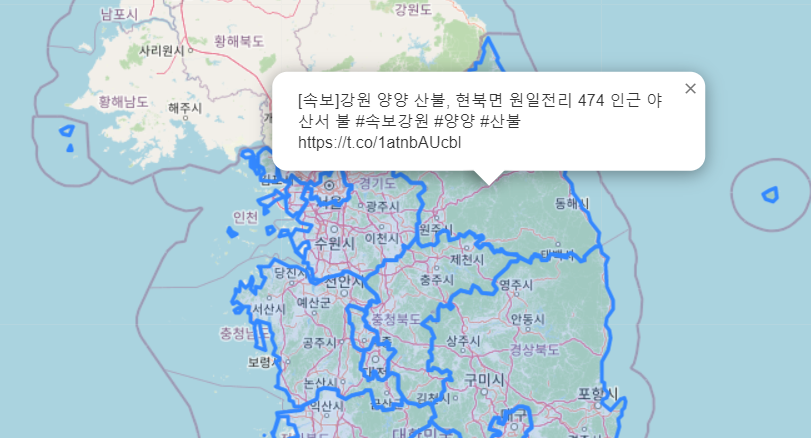
지도 첫화면 조절하기
# static/map.js
map.
locate()
.on("locationfound", (e) => map.setView([36, 127.5], 1))
.on("locationerror", () => map.setView([36, 127.5], 11));setView([위도, 경도], 확대정도) 인 것 같아서 [36, 127.5]랑 1 정도로 중심 위도 경도를 옮기고 줌아웃을 해주면
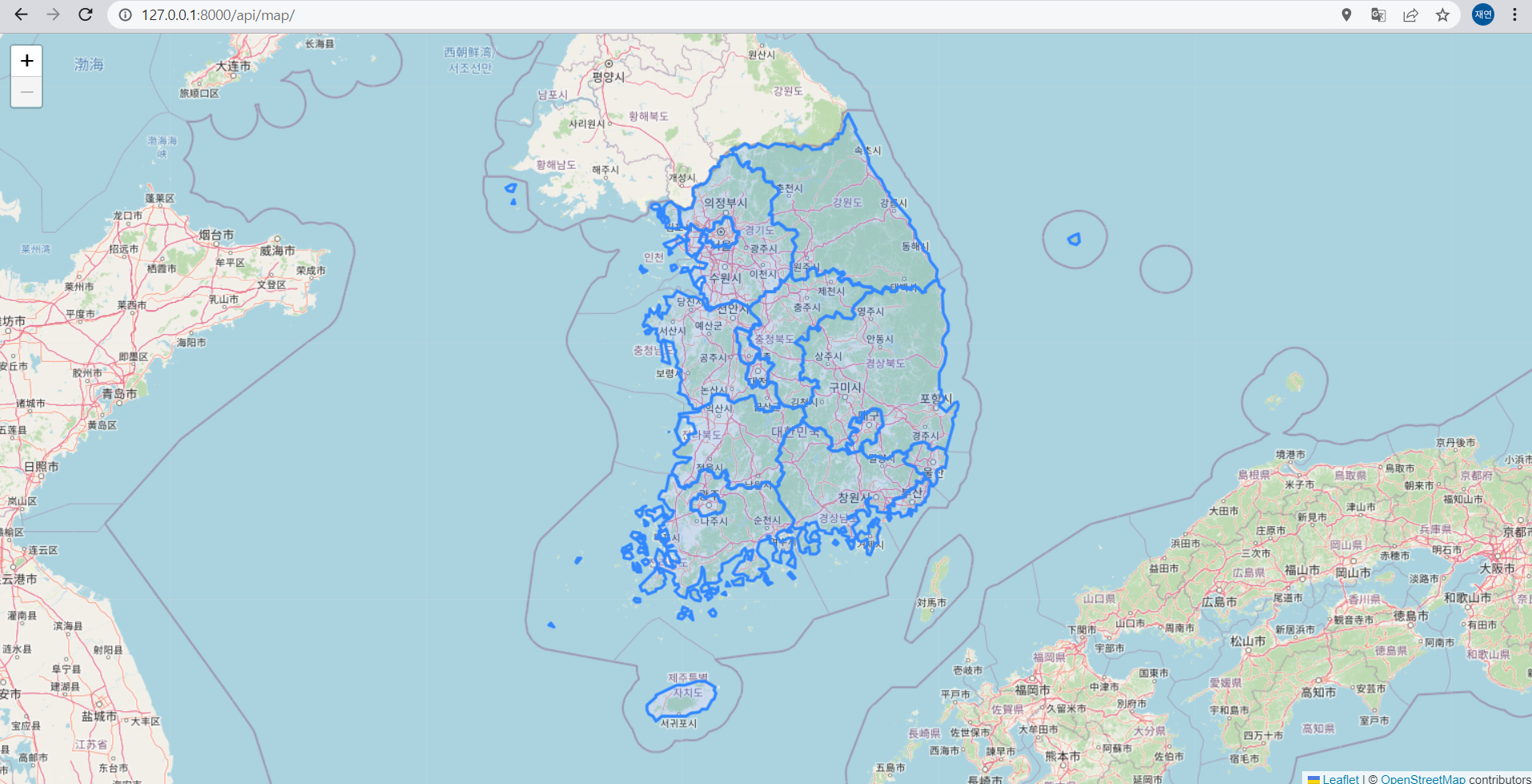
요만큼 나온다.
오늘까지 한거
(트윗에 location 매칭하는거랑 핀에 트윗 띄우는 거는 내가 안했다)
서울
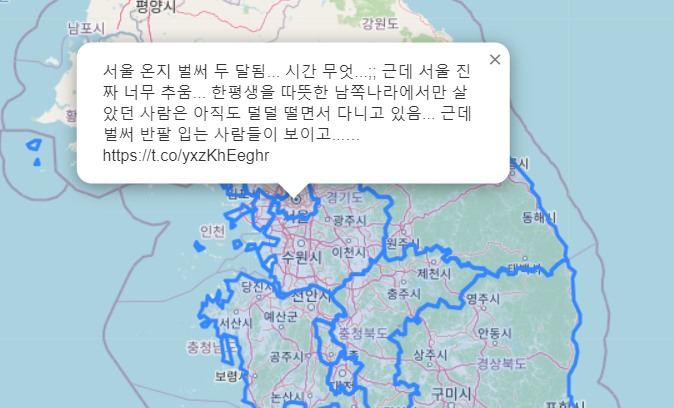
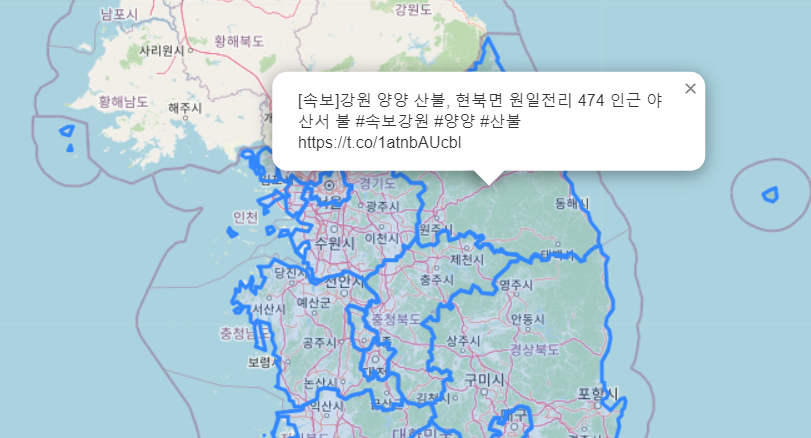
강원도
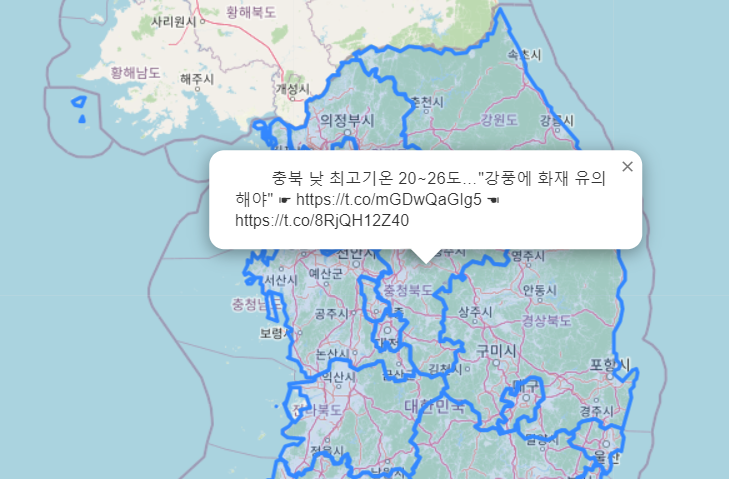
충청북도
부산

제주도
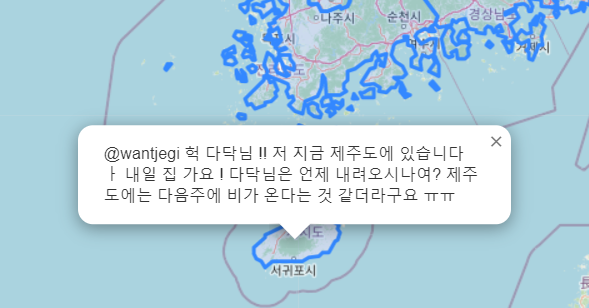
트윗 띄우는거만 살짝 손보면(시간, 사용자, 자연재해 종류, 태그 보이기 & 여러개 보이기) 얼추 끝날 거 같다.
